你在构建 AI 应用的时候,是不是遇到过这种情况:选了个最新的大模型,结果发现自己的服务器根本跑不动;或者数据准备好了,却不知道怎么让模型真正理解这些信息;又或者模型能生成答案了,但用户根本不知道怎么用这个系统。
这些问题的根源在于:AI 系统不是"选个模型就完事",而是一个从硬件到应用的完整技术栈。如果你只盯着模型层,忽略了基础设施、数据处理、任务编排和应用接口,最终的结果就是"看起来很厉害,但实际用不起来"。
这次,我想用一个具体案例------为药物研发科学家构建 AI 论文分析系统------来拆解 AI 技术栈的五个关键层次。让我们看看每一层到底在做什么,以及它们如何协同工作。
PART 01 - 一个真实场景:AI 如何帮助科学家读论文?
在正式拆解技术栈之前,我们先看一个实际需求:
场景:你要为药物发现研究团队构建一个 AI 系统,帮助他们快速理解和分析最新的科学论文。这些科学家每个月要面对成百上千篇新论文,手动筛选和总结的时间成本太高。
挑战:
-
论文涉及高度专业的生物化学知识,需要博士级别的理解能力
-
最新论文可能发表在过去 3 个月内,而 LLM 的知识截止日期通常是训练时间点
-
不能只是简单地"输入论文,输出摘要",需要做交叉引用、趋势分析、假设验证等复杂任务
问题:如果你只是选一个"据说擅长科学任务"的大模型,能解决问题吗?
答案是:远远不够。你还需要:
-
基础设施
:这个模型需要什么样的 GPU?是本地部署还是云端?
-
数据层
:如何把最新论文喂给模型?用什么格式存储?如何快速检索?
-
编排层
:如何把"分析论文"这个复杂任务拆解成多个步骤?如何让模型自我审查生成的结果?
-
应用层
:科学家怎么使用这个系统?是网页、插件,还是集成到他们现有的文献管理工具?
这就是为什么我们需要理解完整的 AI 技术栈。
PART 02 - 五层架构:从底层到顶层的完整视图
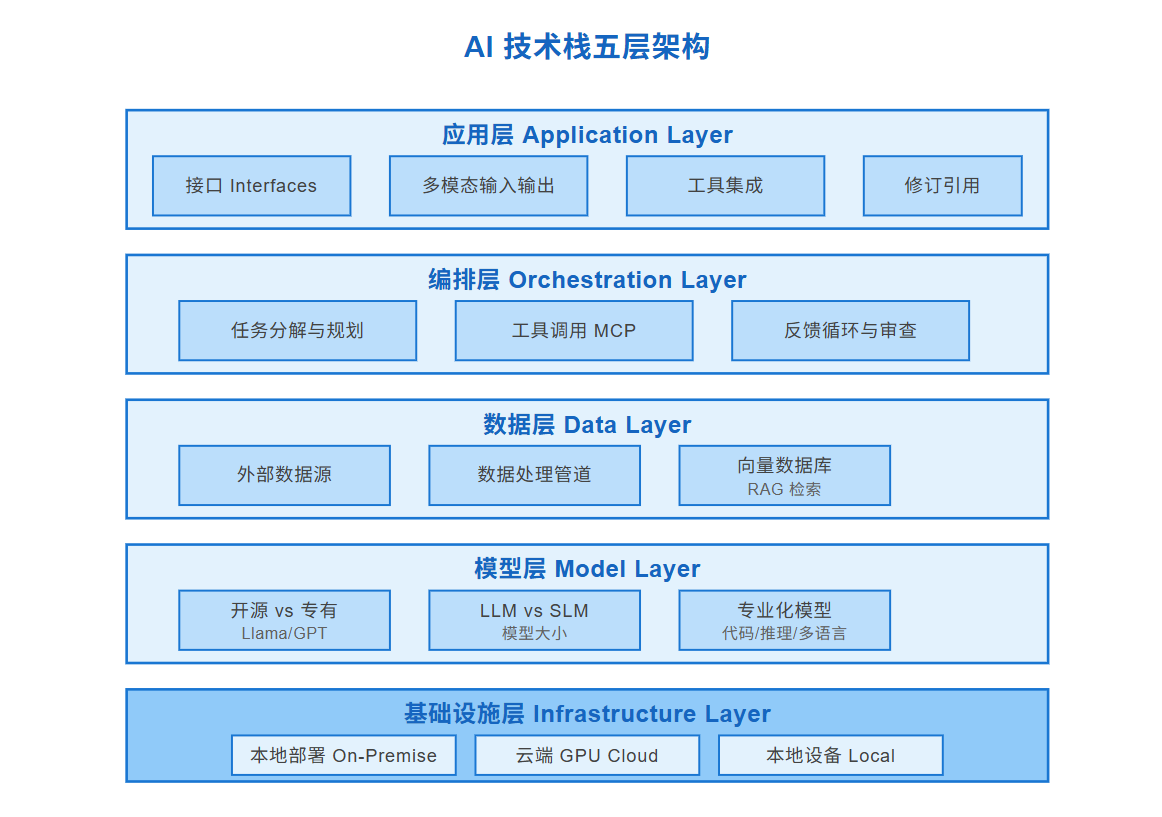
AI 技术栈可以分为 5 个核心层次,从底层的硬件到顶层的用户界面,每一层都影响着系统的质量、速度、成本和安全性。
架构概览
从下往上看:
1. 基础设施层 (Infrastructure Layer)
-
硬件选择:GPU 类型和部署方式
-
三种部署模式:本地、云端、本地设备
2. 模型层 (Model Layer)
-
模型选择:开源 vs 专有、大模型 vs 小模型
-
专业化:代码生成、推理、多语言等
3. 数据层 (Data Layer)
-
外部数据源:补充模型知识的缺口
-
数据处理:预处理、向量化、RAG 检索
4. 编排层 (Orchestration Layer)
-
任务分解:把复杂问题拆解成多个步骤
-
工具调用:通过 MCP 等协议调用外部工具
-
反馈循环:模型自我审查和优化
5. 应用层 (Application Layer)
-
用户接口:文本、图像、音频等多模态
-
集成:与现有工具的协同
现在,我们逐层深入分析。
PART 03 - 第一层:基础设施的三种部署方式
LLM 不是普通软件,它需要专用的 AI 硬件------GPU (图形处理单元)。但不是所有 GPU 都能跑所有模型,你需要根据场景选择部署方式。
GPU 部署方式三种选择本地部署On-Premise特点✓ 完全控制硬件✓ 数据主权✓ 性能可优化✗ 初始投入高✗ 运维成本高适用场景金融、医疗等强数据安全需求硬件示例NVIDIA A100H100 服务器集群专用数据中心云端部署Cloud GPU特点✓ 按需扩展✓ 零初始投入✓ 全球可用✗ 按使用付费✗ 数据传输成本适用场景初创企业快速原型验证波动性负载服务商示例AWS / Azure / GCPLambda LabsRunPod / Vast.ai本地设备Local (Laptop)特点✓ 零云成本✓ 离线可用✓ 数据不出本地✗ 硬件限制大✗ 只能跑小模型适用场景个人实验原型开发隐私敏感任务硬件示例MacBook M 系列RTX 4090 笔记本运行 SLM 模型
方式一:本地部署 (On-Premise)
适用场景:金融、医疗、政府等对数据安全有严格要求的机构
核心优势:
-
完全控制
:你可以优化 GPU 配置、内存分配、网络拓扑,提取最大性能
-
数据主权
:所有数据不出本地,符合 GDPR、HIPAA 等合规要求
-
性能稳定
:不受云端共享资源的波动影响
成本结构:
-
初始投入:一台 NVIDIA A100 服务器约 15,000 - 30,000
-
运维成本:电费、冷却、专业运维团队
-
适合:长期、稳定、大规模的 AI 负载
实际案例:
某制药公司构建内部 AI 系统分析临床试验数据。由于数据涉及患者隐私,必须本地部署。他们采购了 8 台 A100 服务器组成集群,用于训练定制化的生物医学模型。
方式二:云端部署 (Cloud GPU)
适用场景:初创公司、快速原型验证、负载波动大的应用
核心优势:
-
零初始投入
:按小时租用 GPU,无需采购硬件
-
弹性扩展
:可以在几分钟内从 1 张 GPU 扩展到 100 张
-
全球可用
:AWS、Azure、GCP 在全球有数据中心,就近部署降低延迟
成本结构(以 AWS 为例):
-
NVIDIA A100 (40GB):约 4 - 5/小时
-
H100 (80GB):约 8 - 10/小时
-
月成本:如果 24/7 运行一台 A100,约 3,000 - 3,600/月
云服务商对比:
| 服务商 | GPU 类型 | 特点 |
|---|---|---|
| AWS | H100, A100, L40S, T4 | 全球覆盖最广,生态最成熟 |
| Azure | H100, A100, MI300X | 与微软企业工具深度集成 |
| GCP | H100, A100, TPU v5 | Google 自研 TPU,适合 TensorFlow |
| Lambda Labs | H100, A100 | 专注 AI,价格比三大云便宜 20-30% |
| Vast.ai | 各类消费级/专业级 GPU | P2P 市场,最便宜但稳定性较差 |
何时选择云端:
-
你的 AI 项目还在验证阶段,不确定未来规模
-
负载有明显波峰波谷(如每月月底批量处理数据)
-
需要快速访问最新硬件(如 NVIDIA Blackwell 系列)
方式三:本地设备 (Local - Laptop)
适用场景 :个人实验、离线演示、隐私敏感的轻量任务 核心优势:
-
零云成本
:完全在本地运行,不产生 API 费用
-
离线可用
:没有网络也能工作
-
数据不出设备
:适合处理敏感个人信息
硬件限制:
-
不是所有笔记本都能跑 LLM
-
需要至少 16GB 统一内存 (如 Apple M 系列) 或 8GB+ VRAM 的 GPU (如 RTX 4060)
-
只能运行 小型语言模型 (SLM),参数量通常 < 70 亿
可运行的模型:
-
Llama 3 8B (量化版)
-
Phi-2 (2.7B)
-
Mistral 7B
-
Qwen 7B
实际体验:
在 MacBook Pro M2 Max (32GB 内存) 上运行 Llama 3 8B 量化版本,生成速度约 20-30 tokens/秒,足够用于原型开发和个人助手场景。
部署决策树
开始选择 GPU 部署方式
│
是否有严格的数据合规要求?
├─────┴─────┐
是 否
│ │
本地部署 是否有稳定的长期负载?
├─────┴─────┐
是 否
│ │
是否预算充足? 是否只做实验?
├─────┴─────┐ ├─────┴─────┐
是 否 是 否
│ │ │ │
本地部署 云端 本地设备 云端PART 04 - 第二层:模型选择的三个维度
有了硬件,下一步是选择模型。截至 2025 年,仅 Hugging Face 上就有 超过 200 万个模型。如何选择?

维度一:开源 vs 专有
开源模型(如 Llama 3, Mistral, Qwen)
-
✅ 可以本地部署,不受 API 限制
-
✅ 可以 Fine-tune,适配特定领域
-
✅ 无 per-token 成本
-
❌ 需要自己管理推理基础设施
-
❌ 通用能力通常弱于最顶级的专有模型
专有模型(如 GPT-4, Claude 3.5 Sonnet, Gemini)
-
✅ 开箱即用,API 调用简单
-
✅ 顶级能力(推理、创作、多语言)
-
❌ 按 token 计费,大规模使用成本高
-
❌ 数据会经过第三方服务器
-
❌ 无法 Fine-tune(部分模型除外)
决策建议:
-
如果你的任务是通用的(如写邮件、总结会议),优先专有模型
-
如果你需要在特定领域深度优化(如法律文书生成),选开源模型并 Fine-tune
-
如果数据绝对不能出本地,只能选开源
维度二:大模型 (LLM) vs 小模型 (SLM)
参数量临界点 :通常 300 亿参数 是分界线
LLM 的特点:
-
参数量:300 亿 - 2 万亿
-
能力:广泛的通用知识、复杂推理、多任务处理
-
硬件需求:需要高端 GPU (A100/H100)
-
成本:推理速度慢,token 成本高
-
代表:GPT-4 (1.8T), Claude 3 (2T), Llama 3 70B
SLM 的特点:
-
参数量:< 300 亿(通常 10 亿 - 100 亿)
-
能力:领域专业化,响应速度快
-
硬件需求:可在笔记本、边缘设备运行
-
成本:低延迟,成本低
-
代表:Phi-2 (2.7B), Llama 3 8B, Mistral 7B
性能对比:
| 任务类型 | LLM | SLM |
|---|---|---|
| 通用问答 | ✓✓✓ | ✓✓ |
| 复杂推理(数学、逻辑) | ✓✓✓ | ✓ |
| 代码生成 | ✓✓✓ | ✓✓ |
| 特定领域(医疗、法律) | ✓✓ | ✓✓✓(Fine-tuned) |
| 推理速度 | 慢 | 快 (5-10 倍) |
| 成本 | 高 | 低 (10-100 倍差距) |
何时用 SLM:
-
延迟敏感的应用(如实时客服、边缘设备)
-
预算有限,但任务相对单一
-
需要离线运行的场景
何时用 LLM:
-
需要处理多种不同类型的任务
-
对准确性和推理深度要求极高
-
预算充足,愿意为质量付费
维度三:专业化模型
有些模型在特定任务上经过优化,表现显著优于通用模型:
代码生成专用:
-
Codex (OpenAI)
-
CodeLlama (Meta)
-
StarCoder (BigCode)
-
优势:理解代码上下文、生成可运行代码、自动补全
推理增强:
-
o1 (OpenAI)
-
DeepSeek-R1
-
优势:在数学、逻辑、规划任务上表现突出
多语言专用:
-
Qwen (阿里)
-
ChatGLM (智谱)
-
优势:中文理解和生成能力远超通用英文模型
工具调用专用:
-
Claude 3.5 Sonnet (Anthropic)
-
GPT-4 with Function Calling
-
优势:能可靠地调用外部 API 和工具
选型建议:
在药物论文分析场景中,我们可能选择:
-
基础模型
:Llama 3 70B (开源,可 Fine-tune)
-
专业化方向
:在生物医学论文上 Fine-tune
-
部署方式
:云端 (AWS A100),方便扩展
PART 05 - 第三层:数据层------让模型理解最新信息
模型层解决了"用什么大脑"的问题,但模型的知识是有边界的:
如果科学家要分析 2025 年 1 0月发表的论文 ,模型根本不知道这些内容。这时就需要数据层。
数据层的三个组件
组件一:外部数据源
这是模型知识的"扩展包",可以包括:
-
最新的科学论文(PubMed、arXiv)
-
企业内部文档
-
实时数据(股票、天气)
-
用户上传的文件
关键问题:如何让模型快速找到相关信息?
这就引出了组件二。
组件二:数据处理管道
原始文档不能直接喂给模型,需要预处理:
-
提取
:从 PDF、Word 中提取文本
-
分块 (Chunking)
:将长文档切成小块(通常 500-1000 字)
-
向量化 (Embedding)
:将文本转换为数学向量(如 384 维或 1536 维)
-
索引
:存入向量数据库
为什么要向量化?
假设我们有两段文本:
-
文本 A:"这个药物能抑制肿瘤生长"
-
文本 B:"该化合物具有抗癌活性"
虽然用词不同,但它们在语义上相似。向量化后,它们的向量会在高维空间中靠得很近。这样,当用户搜索"抗癌药物"时,即使原文没有这个词,系统也能找到相关内容。
组件三:向量数据库与 RAG RAG (Retrieval-Augmented Generation) 是让 LLM 访问外部知识的标准方法:
用户问题:"2025 年有哪些新的 mRNA 疫苗研究?"
↓
向量化查询 (Embedding)
↓
在向量数据库中检索 Top 5 相关论文
↓
将论文 + 问题一起喂给 LLM
↓
LLM 基于这些论文生成答案
常用向量数据库:
-
Pinecone
:托管服务,开箱即用
-
Weaviate
:开源,支持混合检索
-
Milvus
:大规模部署,性能优化
-
FAISS
(Meta):轻量级,适合原型
优化技巧:
-
混合检索
:结合关键词搜索 (BM25) 和语义搜索
-
重排序 (Re-ranking)
:用更强的模型重新排序检索结果
-
元数据过滤
:只搜索特定时间、作者、期刊的论文
PART 06 - 第四层:编排层------分解复杂任务
有了模型和数据,是不是直接"输入问题 → 输出答案"就行了?
不够。对于复杂任务(如"分析这 50 篇论文,找出共同趋势,提出研究假设"),单次调用 LLM 效果很差。
这时需要编排层 (Orchestration Layer),将任务拆解成多个步骤。
编排层的三个核心能力
能力一:任务规划 (Planning)
当用户问:"总结 2025 年 mRNA 疫苗的最新进展"时,AI 系统需要先规划:
步骤 1: 检索 2025 年发表的 mRNA 疫苗相关论文
步骤 2: 提取每篇论文的核心发现
步骤 3: 按研究主题分组(如新靶点、递送系统、临床试验)
步骤 4: 识别趋势和突破
步骤 5: 生成结构化总结这个规划本身就可以由 LLM 生成(通过 Prompt 引导)。
能力二:工具调用 (Tool Calling / Function Calling)
LLM 不是万能的,它需要调用外部工具:
调用 PubMed API 搜索论文
调用 Wolfram Alpha 计算复杂公式
调用 Python 解释器运行数据分析代码
调用内部数据库查询实验结果MCP (Model Context Protocol) 是 Anthropic 在 2024 年推出的标准化协议,让 AI 模型能够以统一的方式调用各种工具。 MCP 的价值:
-
标准化接口
:不用为每个工具写定制代码
-
工具发现
:AI 可以自动发现可用工具
-
上下文共享
:多个工具调用之间可以保持状态
示例工作流:
用户: "比较论文 A 和论文 B 的实验结果"
↓
Agent 调用工具 1: 从数据库获取论文 A 的数据
↓
Agent 调用工具 2: 从数据库获取论文 B 的数据
↓
Agent 调用工具 3: 用 Python 生成对比图表
↓
Agent 生成分析报告,嵌入图表能力三:反馈循环 (Review & Iteration)
LLM 会犯错。编排层可以让 AI 自我审查:
LLM 生成初版答案
↓
Reviewer Agent 审查: "这个结论是否有论文支持?"
↓
发现问题 → 回到检索步骤,找更多证据
↓
LLM 重新生成答案
↓
Reviewer 通过 → 返回给用户这种"生成 → 审查 → 改进"的循环,显著提升输出质量。
编排框架的选择
LangChain:
-
最成熟的编排框架
-
支持复杂的 Agent 工作流
-
生态丰富(集成 100+ 工具)
LlamaIndex:
-
专注 RAG 场景
-
优化了文档索引和检索
-
轻量级,易于上手
Haystack:
-
企业级 NLP 管道
-
强大的搜索引擎集成
-
适合生产环境
AutoGen (Microsoft):
-
多 Agent 协作框架
-
Agent 之间可以对话协商
-
适合需要多角色协作的任务
在我们的场景中,可能选择 LangChain + MCP,因为需要灵活的工具调用和多步骤规划。
PART 07 - 第五层:应用层------让用户真正能用
技术栈的最后一层是应用层,决定了用户如何与 AI 系统交互。
接口设计:不只是文本
最简单的接口:聊天框(文本输入 → 文本输出)
但对于科学家来说,可能需要:
-
上传 PDF
:直接分析论文文件
-
可视化输出
:生成图表、分子结构图
-
引用标注
:答案中的每个论断都链接到原论文
-
修订功能
:用户可以编辑 AI 生成的内容
多模态接口:
-
输入:文本 + PDF + 图片(实验结果截图)
-
输出:文本 + 表格 + 图表 + 分子结构
实际案例:
某生物信息学团队的 AI 系统允许用户:
-
上传基因测序数据(CSV 格式)
-
用自然语言问:"这些突变与哪些已知癌症相关?"
-
AI 生成报告,包含突变位点可视化图、相关论文引用、临床意义解释
集成:融入现有工作流
AI 系统不能是孤岛,需要与科学家已有的工具集成:
输入端集成:
-
Zotero/Mendeley
(文献管理):自动同步文献库,一键分析
-
Slack/Teams
:在团队协作工具中直接调用 AI
输出端集成:
-
Notion/Obsidian
:将 AI 生成的总结直接保存到笔记
-
LaTeX 编辑器
:生成可直接插入论文的格式化文本
API 集成:
对于开发者,提供 REST API,允许在自己的应用中嵌入 AI 能力。
PART 08 - 全栈视角:五层如何协同工作
现在,我们把五层串起来,看一个完整的交互流程:
用户操作:
科学家在网页界面上传一篇 2025 年的最新论文,问:"这篇论文的核心创新是什么?与我们团队 2024 年的研究有何关联?"
系统执行流程 : 应用层(第 5 层):
-
接收 PDF 文件和问题
-
调用编排层
编排层(第 4 层):
- 任务规划:
- 提取论文核心内容 2. 检索团队 2024 年的研究 3. 对比分析 4. 生成结构化报告
- 调用数据层
数据层(第 3 层):
-
处理上传的 PDF(提取文本、表格)
-
向量化论文内容
-
在向量数据库中检索团队历史研究
-
返回相关文档给编排层
编排层(第 4 层,续):
-
将新论文 + 历史研究 + 问题,组合成 Prompt
-
调用模型层
模型层(第 2 层):
-
Llama 3 70B 模型在 GPU 上推理
-
生成初版答案
-
返回给编排层
编排层(第 4 层,续):
-
Reviewer Agent 审查答案
-
发现需要补充数据,再次调用数据层
-
获取额外证据后,LLM 重新生成
-
通过审查,返回最终答案
应用层(第 5 层,续):
- 格式化输出:
- 核心创新(3 个要点) - 与团队研究的关联(对比表格) - 引用标注(每个论断链接到原文)
-
展示给用户
-
提供"保存到 Notion"按钮
基础设施层(第 1 层):
-
整个过程中,AWS 上的 A100 GPU 持续运行
-
推理耗时约 15 秒
-
成本约 $0.02
每一层的影响
如果任何一层出问题,整个系统都会受影响:
| 层次 | 问题示例 | 后果 |
|---|---|---|
| 基础设施 | GPU 资源不足 | 响应时间从 15 秒变成 2 分钟 |
| 模型 | 选了通用模型而非生物医学专用 | 理解专业术语错误,答案不可靠 |
| 数据 | 向量检索不准确 | 返回不相关的论文,答案跑偏 |
| 编排 | 没有审查环节 | 生成的对比可能包含事实错误 |
| 应用 | 没有引用标注 | 科学家无法验证答案来源,不敢使用 |
这就是为什么全栈思维如此重要。
PART 09 - 技术栈的成本与性能权衡
构建 AI 系统时,你会面临一系列权衡:
成本维度
方案 A:全云端 + 专有模型
-
基础设施:AWS A100 ($4/小时)
-
模型:GPT-4 API ($0.03/1K tokens)
-
数据:Pinecone 托管向量数据库 ($70/月)
-
编排:LangChain (开源)
-
应用:自建网页
月成本估算(假设 100 个用户,每天 10 次查询):
-
GPU:如果按需,实际使用 8 小时/天 → $960/月
-
API:300K queries × 2K tokens × 0.03/1K → 18,000/月
-
数据库:$70/月
-
总计:约 $19,000/月
方案 B:本地部署 + 开源模型
-
基础设施:自购 4 台 A100 服务器 → $100,000 一次性投入
-
模型:Llama 3 70B (开源,免费)
-
数据:自建 Milvus 向量数据库(开源)
-
编排:LangChain (开源)
-
应用:自建网页
月成本估算:
-
硬件折旧(3 年):100,000 / 36 → 2,778/月
-
电费(4 台服务器,800W 每台):约 $500/月
-
运维人力(1 名工程师):约 $8,000/月
-
总计:约 $11,300/月
方案 C:混合方案(云端 + 开源模型)
-
基础设施:AWS A100 ($4/小时)
-
模型:Llama 3 70B (自部署在云端)
-
数据:自建向量数据库
-
月成本:约 $3,000/月
(无 API 费用)
权衡建议:
-
方案 A
:适合快速验证,预算充足
-
方案 B
:适合长期、大规模、数据敏感场景
-
方案 C
:性价比最高,适合大多数企业
性能维度
端到端延迟(从提问到得到答案):
| 配置 | 检索时间 | 推理时间 | 总延迟 |
|---|---|---|---|
| 云端 GPT-4 API + Pinecone | 200ms | 3-5s | 3.2-5.2s |
| 云端 Llama 3 70B + 自建向量库 | 100ms | 8-12s | 8.1-12.1s |
| 本地 A100 + Llama 3 70B | 50ms | 5-8s | 5-8s |
吞吐量(每秒可处理的查询数):
| 配置 | 吞吐量 |
|---|---|
| 1 张 A100 + Llama 3 70B | ~5 queries/秒 |
| 4 张 A100 集群 | ~20 queries/秒 |
| GPT-4 API(有 rate limit) | ~50 queries/秒(需付费提升限额) |
结论
AI 系统不是"选个模型就完事",而是一个从 GPU 到用户界面的五层技术栈。每一层都会影响最终系统的质量、速度、成本和安全性。
当你理解了完整的技术栈,就能设计出真正可靠、高效、符合实际需求的 AI 系统------而不是"看起来很厉害,但实际用不起来"的玩具。