OpenCV计算机视觉实战(26)------OpenCV与机器学习
0. 前言
在计算机视觉领域中,传统机器学习算法依然扮演着不可替代的角色,尤其在中小型图像任务、资源受限设备或解释性分析场景中。与深度学习相比,这些方法具备更强的可控性和更低的计算开销。本文从三个经典应用切入,介绍图像处理中的机器学习技术:利用 K-Means 实现色彩量化压缩图像冗余,借助 SVM 完成图像分类并借助混淆矩阵进行误差分析,最后通过决策树实现手写数字识别并可视化模型决策依据。
1. K-Means 色彩量化
使用 K-Means 聚类,将一幅彩色图像中相似颜色合并为少量"代表色",既可用于图像压缩,也能作为后续分割与风格化的预处理。
1.1 实现过程
- 图像读取与预处理
- 用
cv2.imread加载彩色图像,得到h × w × 3的数组 - 将其重塑为
(h x w) × 3的二维数据,为聚类准备
- 用
K-Means聚类- 创建
KMeans(n_clusters=8)对象,fit_predict同时训练与分配每个像素的簇标签 - 聚类中心
cluster_centers_即为8种"代表色"
- 创建
- 重建量化图像
- 用每个像素的标签索引
palette,重构回原始分辨率 - 使用
astype(np.uint8)确保颜色格式正确
- 用每个像素的标签索引
- 可视化对比
- 原图与量化图并排显示,直观体会颜色压缩效果
python
import cv2
import numpy as np
from sklearn.cluster import KMeans
# 1. 读取图像并准备数据
img = cv2.imread('1.jpeg')
h, w = img.shape[:2]
pixels = img.reshape(-1, 3) # N×3 的像素矩阵
# 2. 用 K-Means 聚为 8 类颜色
n_colors = 8
kmeans = KMeans(n_clusters=n_colors)
labels = kmeans.fit_predict(pixels)
palette = kmeans.cluster_centers_.astype(np.uint8)
# 3. 重建量化图像
quantized = palette[labels].reshape(h, w, 3)
# 4. 显示
cv2.imshow('Original', img)
cv2.imshow('Quantized', quantized)
cv2.waitKey(0)
cv2.destroyAllWindows()
关键函数解析:
KMeans(n_clusters):创建聚类器,n_clusters控制量化色数fit_predict(X):在X(样本 × 特征)上执行K-Means,返回每个样本的簇索引cluster_centers_:训练完成后每个簇的中心坐标,对应量化后的颜色reshape:在聚类前后做数组形状变换,以适应OpenCV与scikit-learn接口
1.2 优化思路
Elbow方法自动选K
先计算不同K下的 簇内平方和 (inertia_),绘制折线图寻找"肘点"自动决定最优K- 颜色调色板可视化
将聚类中心绘制成条形色块,直观呈现量化后调色效果 - 加速聚类
对大分辨率图像可先随机抽样10%像素做聚类,再将中心应用于所有像素以加快速度
python
# Elbow 方法找最优 K
inertias = []
Ks = list(range(2,11))
for k in Ks:
km = KMeans(n_clusters=k).fit(pixels[np.random.choice(len(pixels), len(pixels)//10)])
inertias.append(km.inertia_)
plt.plot(Ks, inertias, '-o')
plt.title('Elbow Method')
plt.xlabel('K')
plt.ylabel('Inertia')
plt.show()
# 色板可视化
swatch = np.zeros((50, 50*n_colors, 3), dtype=np.uint8)
for i, color in enumerate(palette):
swatch[:, i*50:(i+1)*50] = color
plt.imshow(cv2.cvtColor(swatch, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()关键函数解析:
km.inertia_:KMeans聚类后的簇内平方和,用于评估聚类质量np.random.choice(..., size):随机抽样,加速大规模数据聚类
2. SVM 图像分类
使用支持向量机 (Support Vector Machine, SVM) 对手写数字图像进行分类,以 scikit-learn 自带的 digits 数据集为例,演示如何加载数据、训练线性 SVM 并评估分类效果。
2.1 实现过程
- 加载与理解数据
load_digits()提供1797张8×8灰度手写数字图像data为(1797,64),每行是展开后的像素向量
- 训练/测试集划分
- 用
train_test_split按70 / 30划分,保证评估的泛化性
- 用
SVM模型训练SVC(kernel='linear', C=1.0)表示线性核,C控制软间隔大小fit方法完成训练
- 评估与可视化
- 用
classification_report输出精度、召回率与F1-score - 随机挑选几张测试图,用
Matplotlib显示预测与真值对比
- 用
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, metrics
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
# 1. 加载数据集
digits = load_digits()
X = digits.data # 样本×64(8×8)
y = digits.target
# 2. 划分训练/测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0)
# 3. 创建并训练线性 SVM
clf = svm.SVC(kernel='linear', C=1.0)
clf.fit(X_train, y_train)
# 4. 在测试集上预测并评估
y_pred = clf.predict(X_test)
print(metrics.classification_report(y_test, y_pred))
# 5. 显示部分预测结果
fig, axes = plt.subplots(2, 5, figsize=(8,4))
for ax, img, true, pred in zip(axes.ravel(),
X_test.reshape(-1,8,8),
y_test, y_pred):
ax.imshow(img, cmap=plt.cm.gray_r)
ax.set_title(f'T:{true} P:{pred}')
ax.axis('off')
plt.show()
关键函数解析:
svm.SVC(kernel, C):创建支持向量机分类器fit(X, y)/predict(X):分别执行训练和预测metrics.classification_report():输出详细分类性能指标
2.2 优化思路
Grid Search交叉验证
用GridSearchCV在C、kernel、gamma上网格搜索,自动选出最优参数组合- 混淆矩阵热力图
评估分类器在各类上的表现,用seaborn绘制混淆矩阵热力图 - 标准化预处理
对像素特征先做StandardScaler标准化,再输入SVM,能加速收敛并提升性能
python
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import svm, metrics
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
# 1. 加载并标准化
digits = load_digits()
X, y = digits.data, digits.target
sc = StandardScaler().fit(X)
X = sc.transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 2. Grid Search
param_grid = {
'C': [0.1,1,10],
'kernel': ['linear','rbf'],
'gamma': ['scale','auto']
}
grid = GridSearchCV(svm.SVC(), param_grid, cv=5)
grid.fit(X_train, y_train)
print("Best params:", grid.best_params_)
# 3. 评估
y_pred = grid.predict(X_test)
cm = metrics.confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix'); plt.xlabel('Pred'); plt.ylabel('True'); plt.show()
print(metrics.classification_report(y_test, y_pred))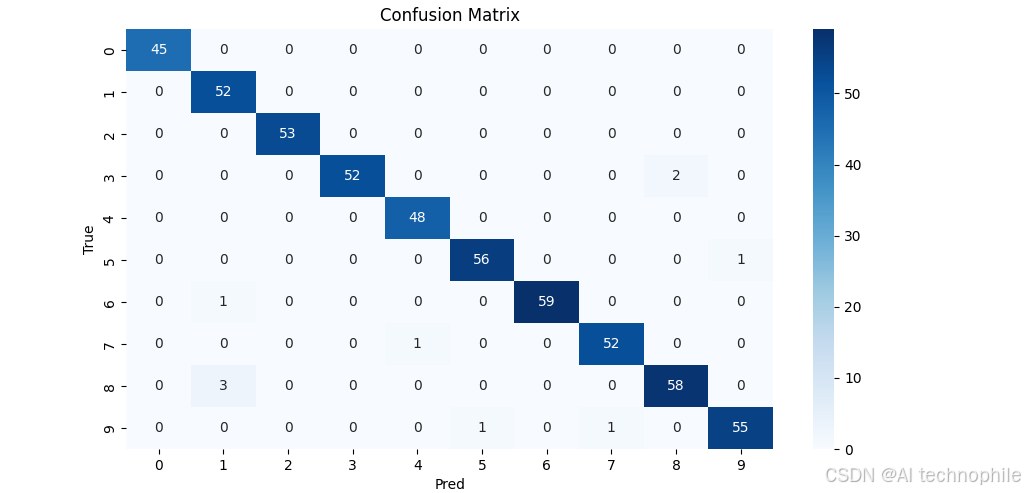
关键函数解析:
StandardScaler():将特征归一到零均值单位方差GridSearchCV(estimator, param_grid, cv):网格搜索 + 交叉验证,自动寻找最优超参数metrics.confusion_matrix() + seaborn.heatmap():生成并可视化混淆矩阵
3. 决策树数字识别
使用决策树 (Decision Tree) 对 digits 数据集进行分类,并对比 SVM 性能;展示如何设置最大深度、防止过拟合,并可视化树结构。
3.1 实现过程
- 模型参数设定
max_depth=10限制树深,防止过拟合min_samples_split=5保证每个内部节点至少有5个样本
- 训练与评估
fit对训练集建树predict在测试集上预测并用classification_report打分
- 树结构可视化
- 用
plot_tree绘制前两层,标注特征与类别,直观理解决策边界
- 用
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn import tree, metrics
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
# 1. 加载数据
digits = load_digits()
X, y = digits.data, digits.target
# 2. 划分数据
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42)
# 3. 创建并训练决策树
clf = tree.DecisionTreeClassifier(max_depth=10, min_samples_split=5)
clf.fit(X_train, y_train)
# 4. 预测与评估
y_pred = clf.predict(X_test)
print(metrics.classification_report(y_test, y_pred))
# 5. 可视化决策树
plt.figure(figsize=(12,8))
tree.plot_tree(clf, max_depth=2, feature_names=[f'p{i}' for i in range(64)],
class_names=[str(i) for i in digits.target_names],
filled=True, fontsize=6)
plt.show()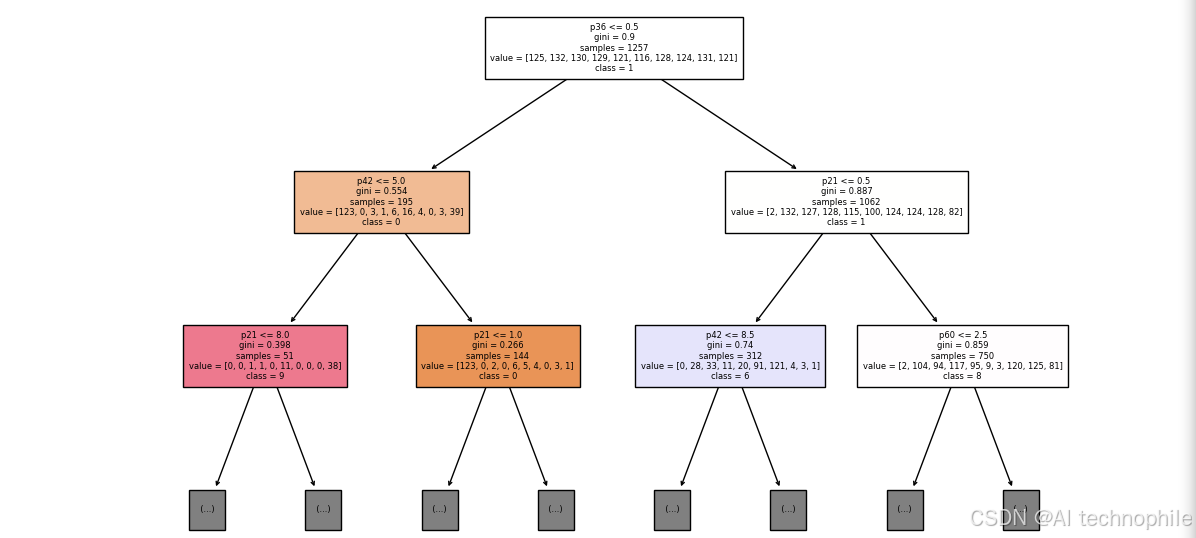
关键函数解析:
DecisionTreeClassifier(max_depth, min_samples_split):创建决策树分类器tree.plot_tree():可视化树结构,参数filled=True用颜色区分节点类别metrics.classification_report():对比SVM与决策树的性能差异
3.2 优化思路
- 后剪枝 (
Cost Complexity Pruning)
用ccp_alpha参数找到最优剪枝系数,防止过拟合 - 特征重要度可视化
绘制决策树对64个像素特征的重要度排名,帮助理解模型决策依据 - 与随机森林对比
训练RandomForestClassifier并对比准确度与特征重要度分布
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn import tree, metrics
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
digits = load_digits()
X, y = digits.data, digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 1. 决策树 + 剪枝
dt = tree.DecisionTreeClassifier(random_state=0)
path = dt.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas = path.ccp_alphas
# 交叉验证找最优 alpha
clfs = []
for alpha in ccp_alphas:
clf = tree.DecisionTreeClassifier(random_state=0, ccp_alpha=alpha)
clf.fit(X_train, y_train)
clfs.append(clf)
# 选最高测试准确度模型
scores = [clf.score(X_test, y_test) for clf in clfs]
best = clfs[np.argmax(scores)]
print("Best alpha:", best.ccp_alpha, "Accuracy:", max(scores))
# 2. 特征重要度
importances = best.feature_importances_
indices = np.argsort(importances)[::-1][:10]
plt.bar(range(10), importances[indices])
plt.xticks(range(10), [f'p{idx}' for idx in indices], rotation=45)
plt.title('Top 10 Feature Importances'); plt.show()
# 3. 随机森林对比
rf = RandomForestClassifier(n_estimators=100, random_state=0)
rf.fit(X_train, y_train)
print("RF Accuracy:", rf.score(X_test, y_test))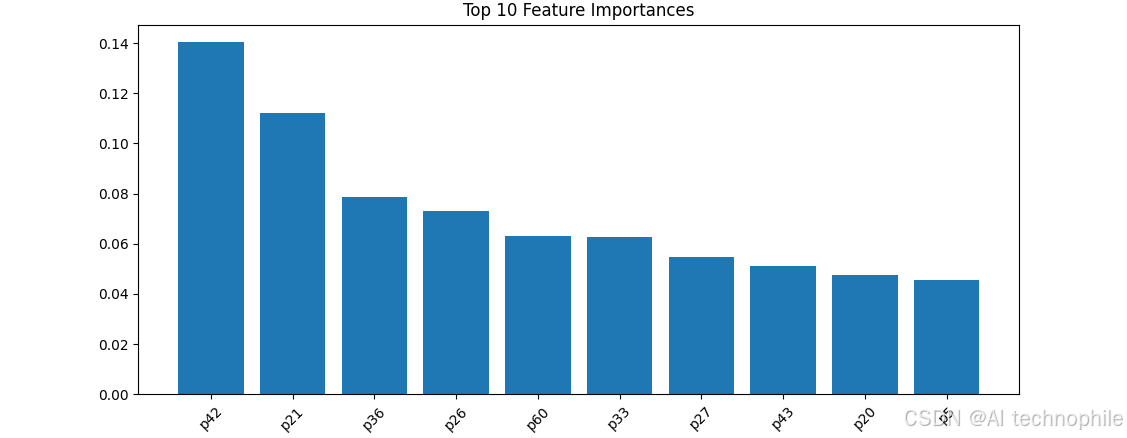
关键函数解析:
cost_complexity_pruning_path():计算一系列ccp_alpha值以供剪枝ccp_alpha:控制剪枝强度,越大树越小feature_importances_:各特征对模型决策贡献度
小结
通过本节的学习,我们完成了从图像数据提取到机器学习模型训练与评估的完整闭环。K-Means 帮助我们理解聚类在图像色彩空间的应用;SVM 通过强大的分类边界与调参机制展示了其在图像识别中的潜力;而决策树不仅可解释性强,还通过剪枝与特征重要度揭示了模型如何"看待"图像。
系列链接
OpenCV计算机视觉实战(1)------计算机视觉简介
OpenCV计算机视觉实战(2)------环境搭建与OpenCV简介
OpenCV计算机视觉实战(3)------计算机图像处理基础
OpenCV计算机视觉实战(4)------计算机视觉核心技术全解析
OpenCV计算机视觉实战(5)------图像基础操作全解析
OpenCV计算机视觉实战(6)------经典计算机视觉算法
OpenCV计算机视觉实战(7)------色彩空间详解
OpenCV计算机视觉实战(8)------图像滤波详解
OpenCV计算机视觉实战(9)------阈值化技术详解
OpenCV计算机视觉实战(10)------形态学操作详解
OpenCV计算机视觉实战(11)------边缘检测详解
OpenCV计算机视觉实战(12)------图像金字塔与特征缩放
OpenCV计算机视觉实战(13)------轮廓检测详解
OpenCV计算机视觉实战(14)------直方图均衡化
OpenCV计算机视觉实战(15)------霍夫变换详解
OpenCV计算机视觉实战(16)------图像分割技术
OpenCV计算机视觉实战(17)------特征点检测详解
OpenCV计算机视觉实战(18)------视频处理详解
OpenCV计算机视觉实战(19)------特征描述符详解
OpenCV计算机视觉实战(20)------光流法运动分析
OpenCV计算机视觉实战(21)------模板匹配详解
OpenCV计算机视觉实战(22)------图像拼接详解
OpenCV计算机视觉实战(23)------目标检测详解
OpenCV计算机视觉实战(24)------目标追踪算法
OpenCV计算机视觉实战(25)------立体视觉详解