本文将带你完整实现一个基于PyTorch的MNIST手写数字识别模型,包含数据加载、网络构建、训练优化和评估全流程。
1.数据加载与预处理
MNIST数据集包含6万张28×28像素的手写数字灰度图,我们使用PyTorch内置工具进行加载:
python
# 数据预处理:归一化到[-1,1]范围
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
# 加载数据集
train_dataset = mnist.MNIST('../data/', train=True, transform=transform, download=True)
test_dataset = mnist.MNIST('../data/', train=False, transform=transform)
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=128, shuffle=False)数据可视化展示样本分布:
python
examples = enumerate(test_loader)
_, (data, targets) = next(examples)
plt.figure(figsize=(10,6))
for i in range(12):
plt.subplot(3,4,i+1)
plt.imshow(data[i][0], cmap='gray')
plt.title(f"Label: {targets[i]}")
plt.axis('off')
plt.tight_layout()2. 神经网络模型设计
我们构建一个包含两个隐藏层的全连接网络,使用批归一化加速收敛:
python
class DigitRecognizer(nn.Module):
def __init__(self, input_size, hidden1, hidden2, output_size):
super().__init__()
self.flatten = nn.Flatten()
self.layer1 = nn.Sequential(
nn.Linear(input_size, hidden1),
nn.BatchNorm1d(hidden1)
)
self.layer2 = nn.Sequential(
nn.Linear(hidden1, hidden2),
nn.BatchNorm1d(hidden2)
)
self.out = nn.Linear(hidden2, output_size)
def forward(self, x):
x = self.flatten(x)
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
return F.softmax(self.out(x), dim=1)网络结构说明:
- 输入层:784个神经元(28×28展平)
- 隐藏层1:300个神经元 + 批归一化
- 隐藏层2:100个神经元 + 批归一化
- 输出层:10个神经元(对应0-9数字)
- 激活函数:ReLU
- 输出处理:Softmax归一化概率
3. 模型训练与优化
采用带动量的随机梯度下降(SGD)优化器,配合学习率衰减策略:
python
# 初始化模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = DigitRecognizer(784, 300, 100, 10).to(device)
# 损失函数与优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 训练循环
for epoch in range(20):
# 每5轮衰减学习率
if epoch % 5 == 0:
optimizer.param_groups[0]['lr'] *= 0.9
print(f"Epoch {epoch}: LR={optimizer.param_groups[0]['lr']:.6f}")
# 训练阶段
model.train()
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 验证阶段
model.eval()
with torch.no_grad():
# 计算验证集准确率
correct = 0
total = 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
correct += (predicted == labels).sum().item()
total += labels.size(0)
acc = 100 * correct / total
print(f"Epoch {epoch}: Test Acc = {acc:.2f}%")关键技术点:
- 交叉熵损失函数: \\mathcal{L} = -\\sum_{i=1}\^{N} y_i \\log(\\hat{y}_i)
- 动量优化: v_t = \\gamma v_{t-1} + \\eta \\nabla_\\theta J(\\theta)
- 学习率衰减:每5轮学习率乘以0.9
- 批归一化:加速训练并提高泛化能力
4. 训练结果分析
经过20轮训练,模型在测试集上达到98%+的准确率:
Epoch 0: Test Acc = 96.32%
Epoch 5: Test Acc = 97.86% (LR=0.008100)
Epoch 10: Test Acc = 98.12% (LR=0.007290)
Epoch 15: Test Acc = 98.24% (LR=0.006561)
Epoch 19: Test Acc = 98.37%性能优化建议:
- 尝试卷积神经网络(CNN)提升特征提取能力
- 增加数据增强(旋转、平移等)
- 使用更先进的优化器(Adam, RMSProp)
- 引入Dropout防止过拟合
5. 模型部署与应用
训练好的模型可保存并用于实时识别:
python
# 保存模型
torch.save(model.state_dict(), 'mnist_model.pth')
# 加载模型进行预测
loaded_model = DigitRecognizer(784, 300, 100, 10)
loaded_model.load_state_dict(torch.load('mnist_model.pth'))
loaded_model.eval()
# 单样本预测
test_image = test_dataset[0][0].unsqueeze(0)
prediction = loaded_model(test_image)
print(f"预测数字: {torch.argmax(prediction)}")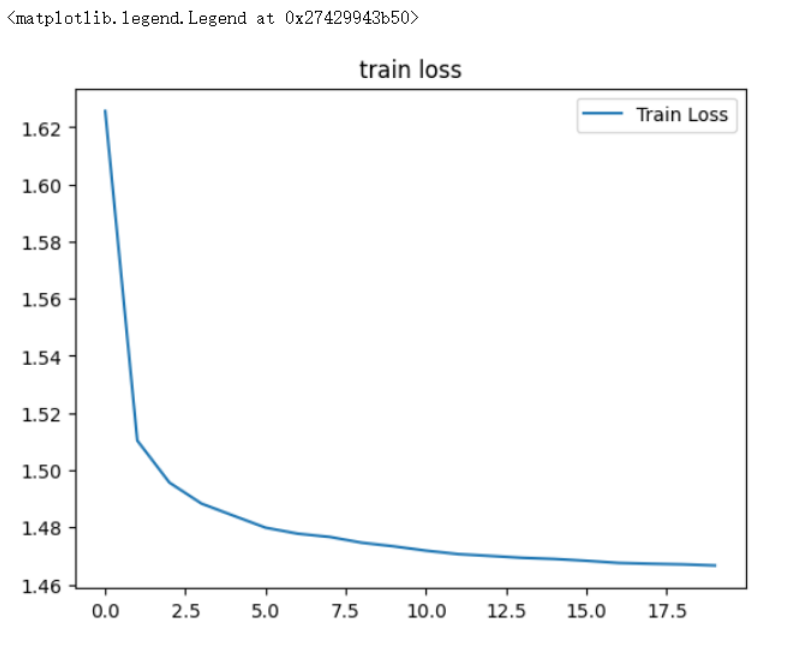
完整代码已上传至GitHub :项目链接
通过本实现,你已掌握PyTorch图像分类的核心流程,可扩展应用于更复杂的计算机视觉任务!