背景需求:
将教师培训十三五证书(结业证书,已完成)和十四五证书(表格形式,没有结束)合并成PDF

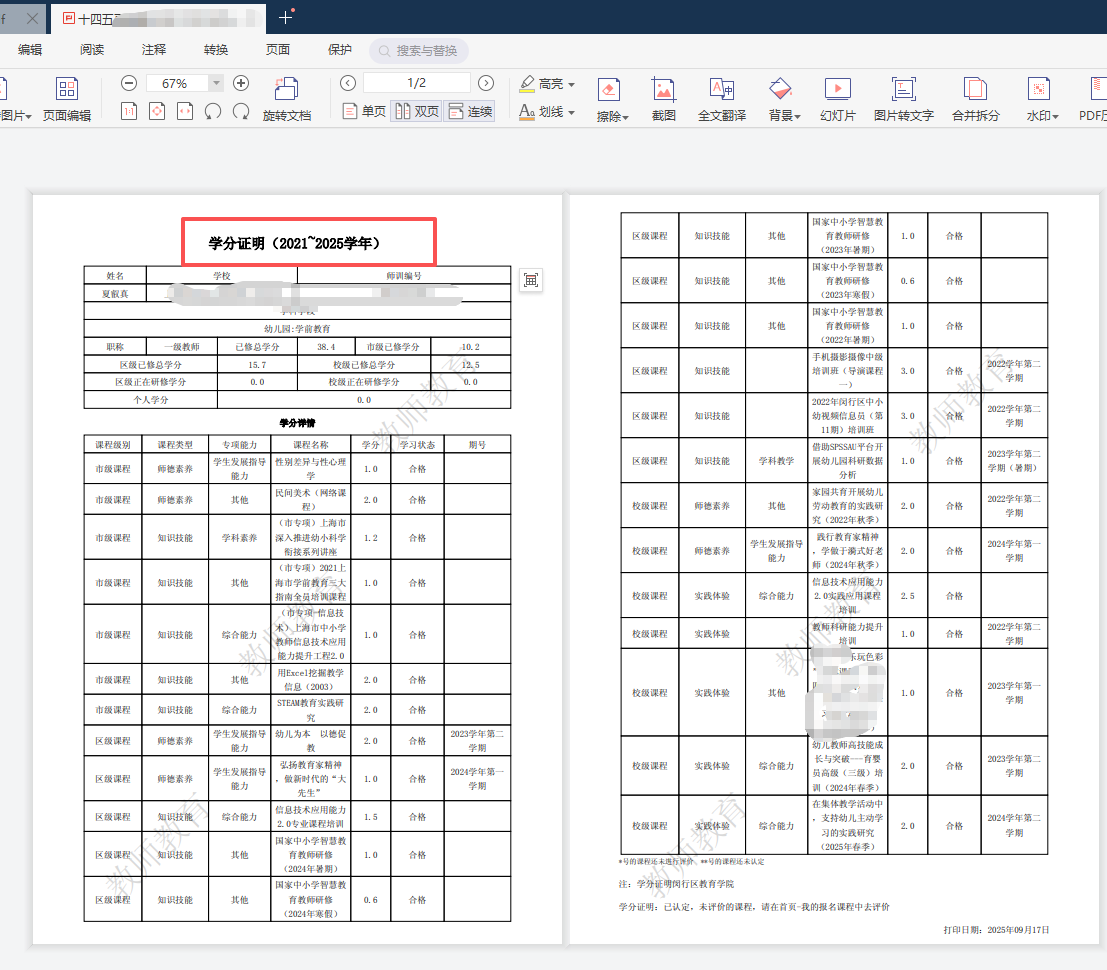
两个证明下载时都是PDF
python
'''
职称04 ,PDF与PDF合并(学分)
deepseek,阿夏
20250920
'''
import os
from PyPDF2 import PdfMerger
from pathlib import Path
def merge_all_pdfs_in_folder(folder_path, output_filename="merged.pdf"):
"""
合并指定文件夹中的所有PDF文件
Args:
folder_path (str): 文件夹路径
output_filename (str): 输出文件名
"""
if not os.path.exists(folder_path):
print(f"文件夹不存在: {folder_path}")
return
# 获取文件夹中的所有PDF文件
pdf_files = []
for file in Path(folder_path).iterdir():
if file.suffix.lower() == '.pdf' and file.is_file():
pdf_files.append(str(file))
if not pdf_files:
print("文件夹中没有找到PDF文件!")
return
# 按文件名排序
pdf_files.sort()
print(f"找到 {len(pdf_files)} 个PDF文件:")
for pdf_file in pdf_files:
print(f" - {os.path.basename(pdf_file)}")
# 合并PDF
try:
merger = PdfMerger()
for pdf_file in pdf_files:
merger.append(pdf_file)
# 确保输出路径正确
output_path = os.path.join(folder_path, output_filename)
merger.write(output_path)
merger.close()
print(f"PDF合并完成!输出文件: {output_path}")
except Exception as e:
print(f"合并PDF时出错: {e}")
# 使用示例
if __name__ == "__main__":
path=r'E:\03教师职务培训证书原件扫描件(十三五证书)'
folder_path = path+r"\十四五打印盖章"
output_pdf = path+r"\十三五结业证书+十四五证明.pdf"
merge_all_pdfs_in_folder(folder_path, output_pdf)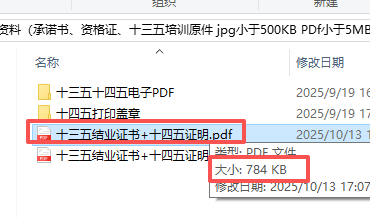
做出来的是合并PDF

但是我想起来上一次做职称资料的时候,十四五的证明是要去教育局师训部盖章的。

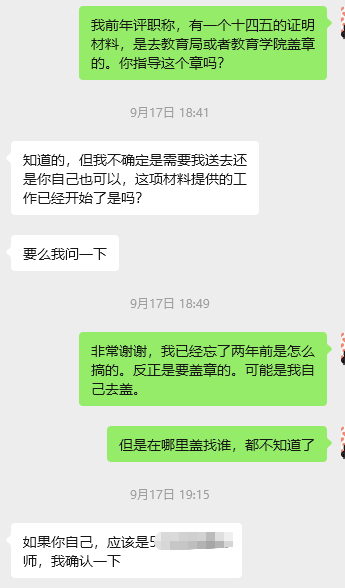
果然要盖章。
我把十四五的PDF打印出来,两张纸,送到教育局盖章证明已经培训过。
然后把这两张打印纸扫描成图片。

所以现在我需要把1个PDF和两个jpg图片合并成一个PDF。
用deepseek写代码,同时注意把PDF和图片名称排序,PDF是001,图片是002、003。
python
'''
职称04 ,图片与PDF合并
deepseek,阿夏
20250920
'''
import os
import sys
from PIL import Image
from PyPDF2 import PdfMerger, PdfReader
def convert_images_to_pdf(image_folder):
"""
将文件夹中的所有图片转换为PDF文件,保持原始方向
"""
# 支持的图片格式
image_extensions = ('.png', '.jpg', '.jpeg', '.bmp', '.gif', '.tiff', '.webp')
# 获取所有图片文件
image_files = [f for f in os.listdir(image_folder)
if f.lower().endswith(image_extensions)]
if not image_files:
print("未找到图片文件")
return None
# 按文件名排序
image_files.sort()
# 转换图片为PDF
pdf_pages = []
for img_file in image_files:
try:
img_path = os.path.join(image_folder, img_file)
image = Image.open(img_path)
# 转换为RGB模式(针对RGBA等模式)
if image.mode != 'RGB':
image = image.convert('RGB')
# 创建临时PDF文件,保持原始方向
temp_pdf_path = os.path.join(image_folder, f"temp_{img_file}.pdf")
image.save(temp_pdf_path, "PDF", resolution=100.0)
pdf_pages.append(temp_pdf_path)
print(f"已转换图片: {img_file}")
except Exception as e:
print(f"转换图片 {img_file} 时出错: {str(e)}")
return pdf_pages
def merge_pdfs(pdf_list, output_path):
"""
合并多个PDF文件
"""
merger = PdfMerger()
for pdf in pdf_list:
try:
# 检查文件是否存在且有效
with open(pdf, 'rb') as f:
reader = PdfReader(f)
if len(reader.pages) > 0:
merger.append(pdf)
print(f"已添加: {os.path.basename(pdf)}")
except Exception as e:
print(f"添加 {pdf} 时出错: {str(e)}")
# 写入合并后的PDF
merger.write(output_path)
merger.close()
print(f"已生成合并后的PDF: {output_path}")
def main(folder_path, output_pdf_path):
"""
主函数:处理文件夹中的图片和PDF文件
"""
# 检查文件夹是否存在
if not os.path.exists(folder_path):
print(f"错误:文件夹 '{folder_path}' 不存在")
return
# 获取所有PDF文件(不包括由图片生成的临时PDF)
pdf_files = [os.path.join(folder_path, f) for f in os.listdir(folder_path)
if f.lower().endswith('.pdf') and not f.startswith('temp_')]
pdf_files.sort()
# 转换图片为PDF
temp_image_pdfs = convert_images_to_pdf(folder_path)
# 合并所有PDF(先PDF后图片)
all_pdfs = []
if pdf_files:
all_pdfs.extend(pdf_files) # 先添加原始PDF
if temp_image_pdfs:
all_pdfs.extend(temp_image_pdfs) # 再添加图片转换的PDF
if not all_pdfs:
print("未找到可处理的图片或PDF文件")
return
# 合并PDF
merge_pdfs(all_pdfs, output_pdf_path)
# 清理临时文件
if temp_image_pdfs:
for temp_pdf in temp_image_pdfs:
try:
os.remove(temp_pdf)
except:
pass
print("处理完成!")
if __name__ == "__main__":
# 设置默认文件夹和输出路径
folder_path = r"\03教师职务培训证书原件扫描件(十三五证书)\十四五打印盖章" # 要处理的文件夹
output_pdf_path = os.path.join(folder_path[:-7], "十三五结业证书+十四五证明.pdf") # 输出PDF文件名
# 如果提供了命令行参数,使用它们
if len(sys.argv) > 1:
folder_path = sys.argv[1]
if len(sys.argv) > 2:
output_pdf_path = sys.argv[2]
main(folder_path, output_pdf_path)
扫描图片大,所以所以大小和PDF差不多