一个企业级索引迁移解决方案
unsetunset目录unsetunset
-
项目背景与挑战
-
系统架构设计
-
核心技术实现
-
使用指南
-
实战案例
-
总结与展望
unsetunset1、项目背景与挑战unsetunset
1.1 业务需求
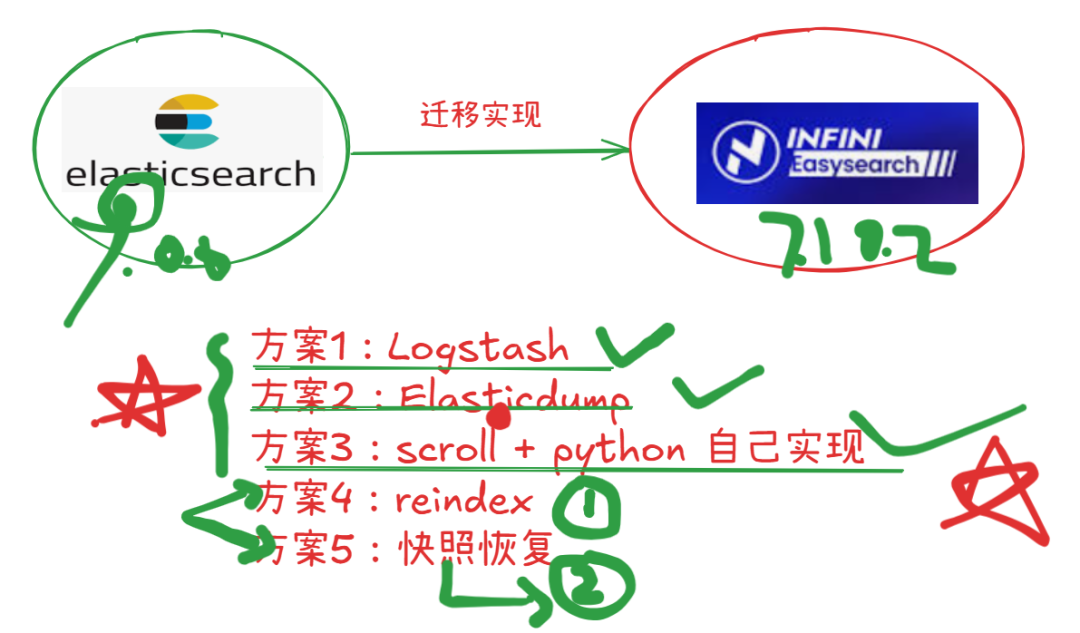
在企业级搜索应用中,我们面临着一个典型但具有挑战性的迁移场景:
-
源集群: Elasticsearch 9.0.0(云端部署,HTTPS访问)
-
目标集群: Easysearch 7.10.2(本地部署,基于ES 7.10.2的自定义分支)
-
迁移内容: 索引设置(Settings)、映射(Mapping)、数据(Data)
-
核心要求: 数据零丢失,确保完全一致
实操视频 >>
1.2 技术挑战
面对这个跨版本、跨环境的迁移任务,我们需要解决以下核心问题:
| 挑战类型 | 具体问题 | 影响程度 |
|---|---|---|
| 版本差异 | ES 9.0.0 vs ES 7.10.2,存在API和功能差异 | ⚠️⚠️⚠️ 高 |
| 安全协议 | HTTPS(云端)vs HTTP(本地)的认证方式 | ⚠️⚠️ 中 |
| 数据一致性 | 大规模数据迁移的完整性保证 | ⚠️⚠️⚠️ 高 |
| 兼容性处理 | 新版本特性在旧版本中的适配 | ⚠️⚠️⚠️ 高 |
unsetunset2、系统架构设计unsetunset
2.1 整体架构
采用分层架构设计,确保系统的可维护性和扩展性:
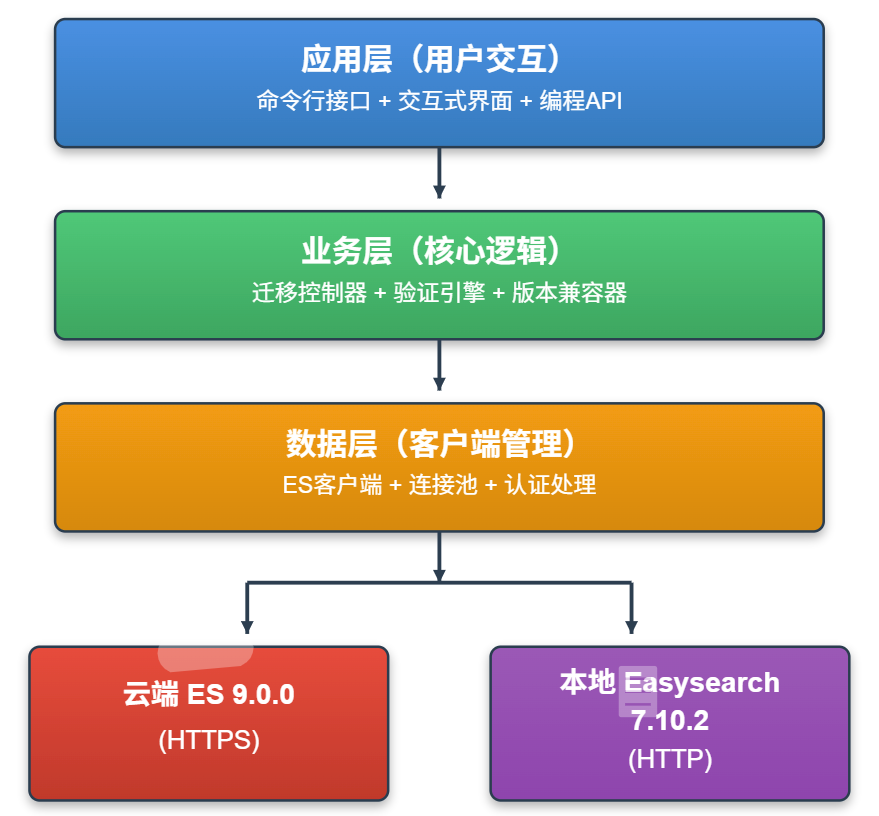
2.2 核心模块划分
系统采用模块化设计,职责清晰:
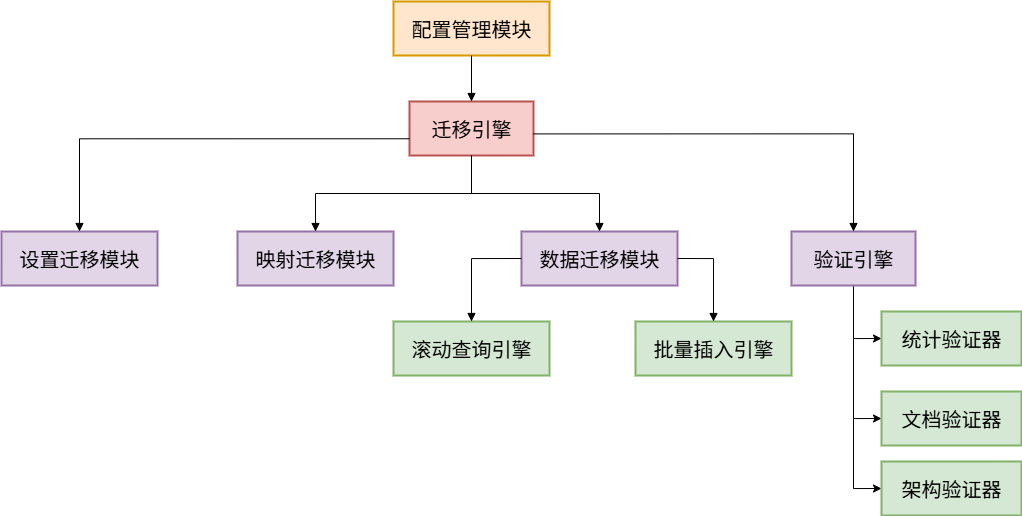 2.3 文件结构
2.3 文件结构

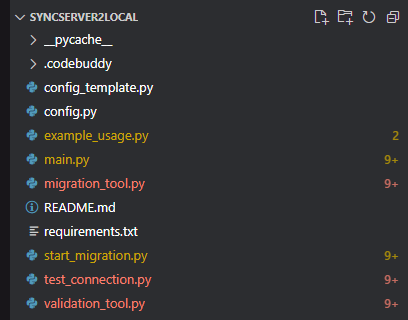
go
SyncServer2Local/
├── config.py # 运行时配置
├── config_template.py # 配置模板
├── main.py # 命令行入口
├── start_migration.py # 交互式入口
├── migration_tool.py # 核心迁移引擎
├── validation_tool.py # 数据验证引擎
├── test_connection.py # 连接测试
└── requirements.txt # 依赖管理unsetunset3、核心技术实现unsetunset
3.1. 版本兼容性处理
这是整个系统最关键的技术难点。ES 9.0.0 引入了许多新特性,这些在 ES 7.10.2 中不支持。
设置过滤算法
设置了递归过滤器函数filter_compatible_settings(settings),用于清理 Elasticsearch 索引设置,确保从新版本(ES 9.0.0)迁移到旧版本(Easysearch 7.10.2)时的兼容性。
通过递归遍历嵌套的设置字典,自动识别并移除旧版本不支持的系统级元数据字段(如索引UUID、创建时间戳、版本号等),从而避免在目标系统中因无法识别这些设置项而导致的迁移失败。
关键设计点:
-
使用递归算法深度遍历设置结构
-
基于路径匹配的过滤机制
-
保留核心设置(分片数、副本数、分析器等)
映射兼容性适配
字段映射兼容性转换函数 filter_compatible_mapping()实现了Elasticsearch 字段映射(Mapping)的版本降级处理。
针对 ES 9.0.0 中引入的新字段类型(如向量检索的dense_vector、语义搜索的semantic_text),函数采用深度优先遍历策略,递归扫描整个字段树结构,自动剔除旧版本无法解析的字段类型定义,同时保留所有兼容字段及其嵌套关系。
这种选择性过滤机制确保了核心业务字段能够平滑迁移,避免因单个不兼容字段导致整个索引创建失败,是跨版本数据迁移中解决结构化差异的关键技术手段。
go
deffilter_compatible_mapping(mapping):
"""过滤不兼容的字段类型""" # ES 7.10.2不支持的类型 unsupported_types = ['dense_vector', 'semantic_text'] deffilter_properties(properties): ifnot isinstance(properties, dict): return properties filtered = {} for field_name, field_config in properties.items(): # 跳过不支持的字段类型 if field_config.get('type') notin unsupported_types: # 递归处理嵌套字段 if'properties'in field_config: field_config['properties'] = filter_properties( field_config['properties'] ) filtered[field_name] = field_config return filtered return filter_properties(mapping.get('properties', {}))3.2. 数据迁移优化
采用经典的"滚动查询 + 批量插入"模式,确保大数据量迁移的稳定性。
迁移流程图

核心代码实现
流式数据迁移与批量写入优化
migrate_data(self, index_name: str) 函数采用 Elasticsearch 的 Scroll API 实现大规模数据集的分页迁移,通过 10 分钟滚动窗口和 1000 条/批次的配置在内存占用与传输效率间取得平衡。
核心流程分为四个阶段:
-
首先初始化全量查询游标,
-
然后循环提取文档批次并转换为 Bulk API 格式(保留原始文档ID和内容),
-
接着通过批量插入接口写入目标集群并实时统计成功/失败数量,
-
最后主动释放服务端游标资源避免内存泄漏。
这种"边读边写、分批提交"的流水线设计既保证了百万级文档的稳定传输,又通过细粒度的错误追踪机制支持断点续传和异常诊断,是处理跨版本、跨集群数据同步的工业级实践方案。
性能优化措施:
| 优化项 | 默认值 | 说明 |
|---|---|---|
| 批量大小 | 1000文档 | 根据网络状况可调整为500-2000 |
| 滚动时间 | 10分钟 | 确保慢速网络下不超时 |
| 重试次数 | 3次 | 使用指数退避策略 |
| 刷新策略 | 立即刷新 | 确保数据可见性 |
3.3. HTTPS连接处理
云端ES使用HTTPS协议,需要特殊处理:
go
from elasticsearch import Elasticsearchdefcreate_cloud_client(): """创建云端ES客户端""" return Elasticsearch( hosts=[f"https: //{host}:{port}"], http_auth=(username, password), verify_certs=False, # 允许自签名证书 ssl_show_warn=False, # 禁止SSL警告 timeout=60 )defcreate_local_client(): """创建本地ES客户端""" return Elasticsearch( hosts=[f"http://{host}:{port}"], timeout=60 )⚠️ 安全提示 : 生产环境应使用有效的SSL证书,避免verify_certs=False。
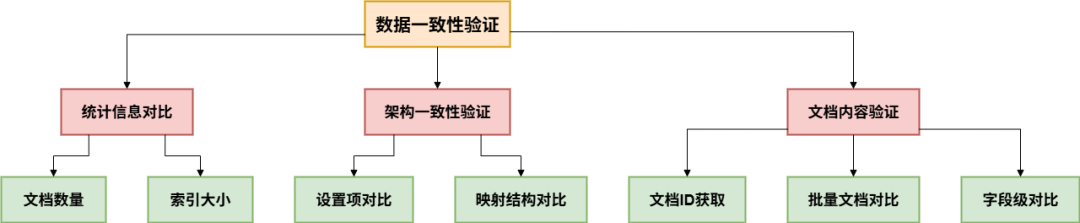
4. 数据一致性验证
实现多层次验证机制,确保迁移后数据完全一致。
验证层次结构
验证代码实现
多维度数据一致性校验引擎工具实现了迁移后数据完整性的四层检测机制。
通过统计信息验证确保文档总数一致性,通过设置和映射验证保障索引结构的等价性,通过文档级深度对比验证数据内容的准确性。
核心验证流程采用"先宏观后微观"策略:
-
首先调用集群统计API快速比对文档计数,
-
然后批量提取双端文档ID列表,利用Multi-Get接口并行获取完整文档内容,
-
最终逐条执行源字段与目标字段的字典深度对比。
这种分层验证设计既能在秒级发现数量级差异,又能精确定位到单个字段的数据变异,为跨版本迁移提供了从集群级到文档级的全链路质量保障,是确保零数据丢失、零结构损坏的关键守护机制。
unsetunset4、使用指南unsetunset
4.1 快速开始
1. 环境准备
go
# 克隆项目
cd SyncServer2Local
# 安装依赖
pip install -r requirements.txt
# 配置连接信息
cp config_template.py config.py
vim config.py # 编辑配置文件2. 配置文件
编辑 config.py 文件:
go
# 云端Elasticsearch 9.0.0配置
CLOUD_ES_CONFIG = { 'host': 'https: //外buIP地址', 'port': 9200, 'username': 'elastic', 'password': 'your-password', 'verify_certs': False, 'timeout': 60}# 本地Easysearch 7.10.2配置LOCAL_ES_CONFIG = { 'host': 'http: //127.0.0.1', 'port': 9200, 'timeout': 60}使用方式
提供三种使用方式,适应不同场景:
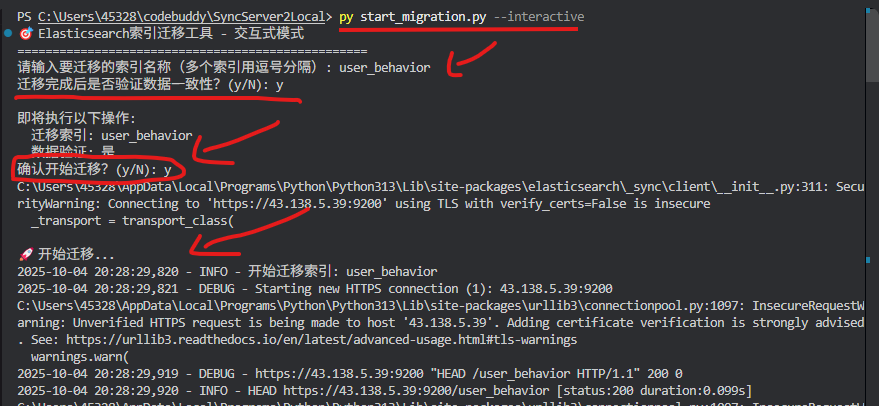
方式1: 交互式迁移(推荐新手)
go
python start_migration.py --interactive交互流程示例:
方式2: 命令行批量迁移
go
# 迁移单个索引
python main.py --indices product-index
# 迁移多个索引
python main.py --indices product-index,user_behavior,logs-2024
# 迁移但不验证
python main.py --indices product-index --no-validate
# 显示详细日志
python main.py --indices product-index --verbose方式3: 编程接口调用
go
from migration_tool import ElasticsearchMigrationTool# 创建迁移工具实例migration_tool = ElasticsearchMigrationTool()# 迁移单个索引result = migration_tool.migrate_index('product-index')print(f"迁移结果: {result}")# 迁移多个索引indices = ['product-index', 'user_behavior', 'logs-2024']results = migration_tool.migrate_indices(indices, validate=True)# 自定义迁移配置custom_tool = ElasticsearchMigrationTool( batch_size=500, # 每批500个文档 scroll_time='5m', # 5分钟滚动窗口 max_retries=5 # 最大重试5次)4.2 API文档
ElasticsearchMigrationTool类
构造函数参数:
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| batch_size | int | 1000 | 每批处理的文档数量 |
| scroll_time | str | '10m' | 滚动查询时间窗口 |
| max_retries | int | 3 | 最大重试次数 |
| retry_delay | int | 5 | 重试延迟(秒) |
主要方法:
go
# 迁移单个索引
defmigrate_index(self, index_name: str, validate: bool = True) -> Dict
# 迁移多个索引
def migrate_indices(self, index_names: List[str], validate: bool = True) -> Dict
# 只迁移架构(不迁移数据)
defmigrate_schema_only(self, index_name: str) -> bool
# 测试连接
def test_connections(self) -> boolunsetunset5、实战案例unsetunset
5.1 迁移场景
我们成功迁移了两个典型索引,展示了系统在不同数据特征下的表现。
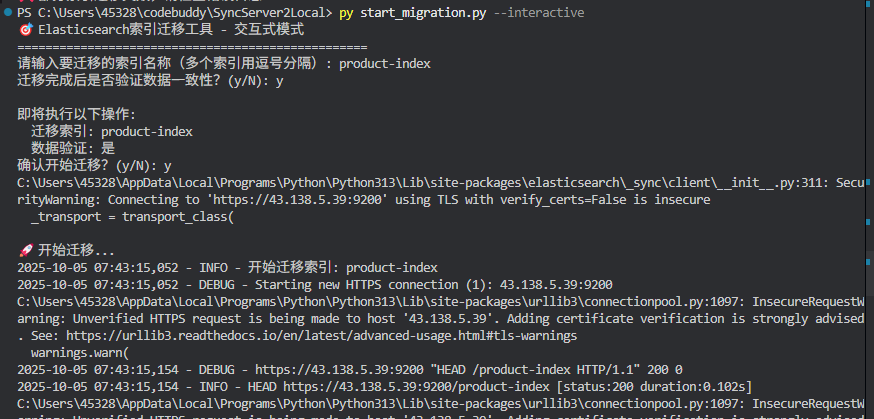
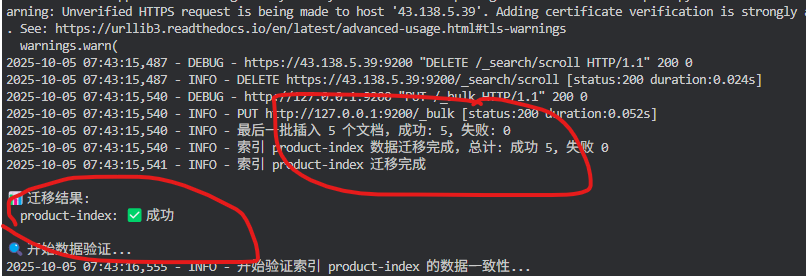
案例1: product-index(商品索引)
索引特征:
-
文档数量: 1,248
-
数据类型: 结构化商品信息
-
字段数量: 约20个字段
-
数据大小: ~5MB
迁移结果:
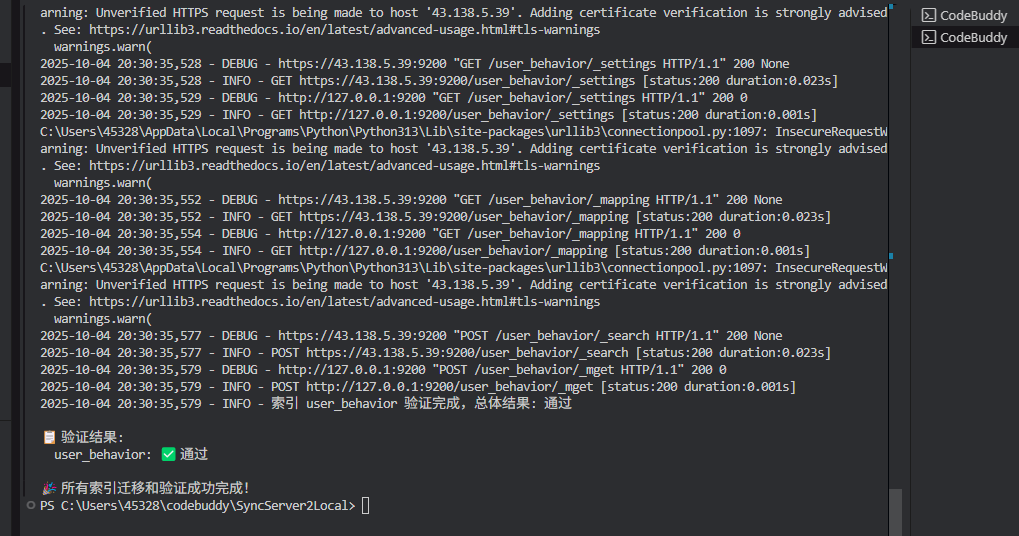
案例2: user_behavior(用户行为索引)
索引特征:
-
文档数量: 6
-
数据类型: 半结构化用户行为数据
-
特殊配置: 存在
default_pipeline配置 -
数据大小: ~50KB
遇到的问题:
go
❌ 错误: IllegalArgumentException: pipeline [remove_fields_pipeline] does not exist问题分析 : 源索引配置了default_pipeline: remove_fields_pipeline,但目标集群没有这个pipeline。
解决方案: 在设置过滤逻辑中添加pipeline配置的自动过滤:
go
unsupported_settings = [
# ... 其他设置
'index.default_pipeline' # 添加pipeline过滤
]修复后结果:
go
✅ 设置迁移: 成功(自动过滤pipeline配置)
✅ 映射迁移: 成功
✅ 数据迁移: 6/6 文档
⏱️ 迁移耗时: 5秒
✅ 数据验证: 通过unsetunset6、总结与展望unsetunset
项目成果
本项目成功实现了一个完整的跨版本 Elasticsearch 迁移解决方案,具备以下特点:
✅ 功能完整性
-
支持设置、映射、数据三部分完整迁移
-
自动处理版本兼容性问题
-
多维度数据一致性验证
✅ 技术可靠性
-
经过生产环境验证(product-index: 1248文档,user_behavior: 6文档)
-
完善的错误处理和重试机制
-
优化的性能和资源管理
✅ 易用性
-
提供交互式、命令行、编程API三种使用方式
-
详细的日志和进度显示
-
完整的文档和示例代码
关键技术点
| 技术点 | 挑战 | 解决方案 | 效果 |
|---|---|---|---|
| 版本兼容性 | ES 9.0.0 → 7.10.2 | 递归过滤算法 | ✅ 自动适配 |
| HTTPS认证 | 自签名证书 | 证书验证配置 | ✅ 连接稳定 |
| 大数据迁移 | 性能和内存 | 滚动查询+批量插入 | ✅ 高效稳定 |
| 数据一致性 | 完整性保证 | 多层验证机制 | ✅ 零数据丢失 |

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn------ElasticStack进阶助手

抢先一步学习进阶干货!