Transformer实战(22)------使用FLAIR进行语义相似性评估
-
- [0. 前言](#0. 前言)
- [1. 使用 FLAIR 进行语义相似性评估](#1. 使用 FLAIR 进行语义相似性评估)
- [2. 平均池化词嵌入](#2. 平均池化词嵌入)
- [3. 基于循环神经网络的文档嵌入](#3. 基于循环神经网络的文档嵌入)
- [4. 基于 Transformer 的 BERT 嵌入](#4. 基于 Transformer 的 BERT 嵌入)
- [4. Sentence-BERT 嵌入](#4. Sentence-BERT 嵌入)
- 系列链接
0. 前言
在自然语言处理中,句子表示的质量直接影响下游任务(如语义检索、文本聚类)的效果。在本节中,我们将通过 FLAIR 库对句子表示模型进行定性评估,该库极大地简化了获取文档嵌入的过程,系统评估四种主流句子嵌入方法------平均池化、循环神经网络编码、BERT 嵌入及 SBERT 嵌入,揭示其语义区分能力。
1. 使用 FLAIR 进行语义相似性评估
在开始之前,使用 pip 安装所需库:
shell
$ pip install flair为了进行定性评估,我们定义了一组相似的句子对和一组不相似的句子对(每组五对)。我们期望嵌入模型能够对相似句子对给出较高的分数,对不相似句子对给出较低的分数。这些句子对是从语义文本相似性 (Semantic Textual Similarity, STS) 基准数据集中提取的。对于相似的句子对,两个句子是完全等价的,且意义相同。
(1) 从 STS 数据集中随机选取相似度分数约为 5 的句子对:
python
import pandas as pd
similar=[("A black dog walking beside a pool.","A black dog is walking along the side of a pool."),
("A blonde woman looks for medical supplies for work in a suitcase. "," The blond woman is searching for medical supplies in a suitcase."),
("A doubly decker red bus driving down the road.","A red double decker bus driving down a street."),
("There is a black dog jumping into a swimming pool.","A black dog is leaping into a swimming pool."),
("The man used a sword to slice a plastic bottle. ","A man sliced a plastic bottle with a sword.")]
pd.DataFrame(similar, columns=["sen1", "sen2"])输出结果如下:

(1) 定义相似度分数约为 0 的不相似句子对,同样取自STS基准数据集:
python
import pandas as pd
dissimilar= [("A little girl and boy are reading books. ", "An older child is playing with a doll while gazing out the window."),
("Two horses standing in a field with trees in the background.", "A black and white bird on a body of water with grass in the background."),
("Two people are walking by the ocean." , "Two men in fleeces and hats looking at the camera."),
("A cat is pouncing on a trampoline.","A man is slicing a tomato."),
("A woman is riding on a horse.","A man is turning over tables in anger.")]
pd.DataFrame(dissimilar, columns=["sen1", "sen2"])输出结果如下:

(3) 定义 sim() 函数来评估嵌入模型,sim() 函数计算两个句子之间的余弦相似度:
python
import torch, numpy as np
def sim(s1,s2):
# cosine similarity function outputs in the range 0-1
s1=s1.embedding.unsqueeze(0)
s2=s2.embedding.unsqueeze(0)
sim=torch.cosine_similarity(s1,s2).item()
return np.round(sim,2)(4) 该节中使用的文档嵌入模型均为预训练模型。我们将把文档嵌入模型对象和句子对列表(相似或不相似)传递给 evaluate() 函数, evaluate() 函数会对句子嵌入进行编码,计算每对句子的相似度分数,并返回所有句子对的平均分数:
python
def evaluate(embeddings, myPairList):
# it evaluates embeddings for a given list of sentence pair
scores=[]
for s1, s2 in myPairList:
s1,s2=Sentence(s1), Sentence(s2)
embeddings.embed(s1)
embeddings.embed(s2)
score=sim(s1,s2)
scores.append(score)
return scores, np.round(np.mean(scores),2)接下来,评估句子嵌入模型的时候,首先从平均池化方法开始。
2. 平均池化词嵌入
平均池化词嵌入(也称文档池化)对句子中的所有词应用均值池化操作,即将所有词嵌入的平均值作为句子嵌入。
(1) 接下来,实例化基于GloVe 向量的文档池化嵌入。需要注意的是,虽然我们这里仅使用 GloVe 向量,但 FLAIR API 允许使用多种词嵌入:
python
from flair.data import Sentence
from flair.embeddings import WordEmbeddings, DocumentPoolEmbeddings
glove_embedding = WordEmbeddings('glove')
glove_pool_embeddings = DocumentPoolEmbeddings([glove_embedding])(2) 在相似句子对上评估 GloVe 池化模型:
python
evaluate(glove_pool_embeddings, similar)
# ([0.97, 0.99, 0.97, 0.99, 0.98], 0.98)可以看到,结果符合预期。但模型对不相似的句子对也给出了很高的分数,平均得分为 0.94,我们期望的分数应低于 0.4,得到这种情况的原因将在后续学习中解释:
python
evaluate(glove_pool_embeddings, dissimilar)
# ([0.94, 0.97, 0.94, 0.92, 0.93], 0.94)接下来,在相同问题上评估循环神经网络 (Recurrent Neural Network, RNN)嵌入。
3. 基于循环神经网络的文档嵌入
(1) 基于 GloVe 嵌入实例化一个门控循环单元 (Gated Recurrent Unit, GRU) 模型,其中 DocumentRNNEmbeddings 的默认模型是 GRU:
python
from flair.embeddings import WordEmbeddings, DocumentRNNEmbeddings
gru_embeddings = DocumentRNNEmbeddings([glove_embedding])(2) 执行评估方法:
python
evaluate(gru_embeddings, similar)
# ([0.99, 1.0, 0.97, 1.0, 0.9], 0.97)
evaluate(gru_embeddings, dissimilar)
# ([0.93, 1.0, 0.91, 0.88, 0.89], 0.92)同样,不相似句子对得到了很高的分数,这并不是我们期望的句子嵌入表现。
4. 基于 Transformer 的 BERT 嵌入
(1) 实例化一个 bert-base-uncased 模型,并对最后一层进行池化:
python
from flair.embeddings import TransformerDocumentEmbeddings
from flair.data import Sentence
bert_embeddings = TransformerDocumentEmbeddings('bert-base-uncased')(2) 执行评估:
python
evaluate(bert_embeddings, similar)
# ([0.85, 0.9, 0.96, 0.91, 0.89], 0.9)
evaluate(bert_embeddings, dissimilar)
# ([0.93, 0.94, 0.86, 0.93, 0.92], 0.92)可以看到,不相似句子对的得分甚至高于相似句子对的得分。
4. Sentence-BERT 嵌入
接下来,使用 Sentence-BERT (SBERT) 来区分相似句子对和不相似句子对。
(1) 首先,我们需要确保已经安装了 sentence-transformers 库:
shell
$ pip install sentence-transformers(2) SBERT 提供了多种预训练模型。我们选择 bert-base-nli-mean-tokens 模型进行评估:
python
from flair.data import Sentence
from flair.embeddings import SentenceTransformerDocumentEmbeddings
# init embedding
sbert_embeddings = SentenceTransformerDocumentEmbeddings('bert-base-nli-mean-tokens')(3) 评估模型:
python
evaluate(sbert_embeddings, similar)
# ([0.98, 0.95, 0.96, 0.99, 0.98], 0.97)
evaluate(sbert_embeddings, dissimilar)
# ([0.48, 0.41, 0.19, -0.05, 0.0], 0.21)可以看到,SBERT 模型能够得到更好的结果。该模型对不相似句子对给出了较低的相似度分数,这符合我们的预期。
(4) 接下来,我们进行一个更复杂的测试,将相互矛盾的句子传递给模型:
python
tricky_pairs=[("An elephant is bigger than a lion","A lion is bigger than an elephant") ,("the cat sat on the mat","the mat sat on the cat")]
evaluate(glove_pool_embeddings, tricky_pairs)
# ([1.0, 1.0], 1.0)
evaluate(gru_embeddings, tricky_pairs)
# ([0.85, 0.75], 0.8)
evaluate(bert_embeddings, tricky_pairs)
# ([1.0, 0.98], 0.99)
evaluate(sbert_embeddings, tricky_pairs)
# ([0.93, 0.97], 0.95)可以看到,得分非常高,因为句子相似度模型的工作原理类似于主题检测,衡量的是内容相似性。观察这些句子,虽然它们相互矛盾,但共享相同的内容。因此,模型产生了较高的相似度分数。由于 GloVe 嵌入方法对词汇进行平均池化,而不考虑单词顺序,因此它将两句话视为同义句。而 GRU 模型由于关注词序,因此生成的分数较低。即使是 SBERT 模型也未能产生有效的分数,这是由于 SBERT 模型中使用了基于内容相似性的监督方法。
(5) 要正确检测句子对的语义,包含三种类别------即中立 (Neutral)、矛盾 (Contradiction) 和蕴含 (Entailment),可以使用在 MultiNLI (Multi-Genre Natural Language Inference) 上微调的模型。使用 XLM-RoBERTa 模型,并在 XNLI (Cross-lingual Natural Language Inference) 数据集上微调,使用相同的句子对:
python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
nli_model = AutoModelForSequenceClassification.from_pretrained('joeddav/xlm-roberta-large-xnli')
tokenizer = AutoTokenizer.from_pretrained('joeddav/xlm-roberta-large-xnli')
import numpy as np
for permise, hypothesis in tricky_pairs:
x = tokenizer.encode(permise,
hypothesis,
return_tensors='pt',
truncation=True)
logits = nli_model(x)[0]
print(f"Permise: {permise}")
print(f"Hypothesis: {hypothesis}")
print("Top Class:")
print(nli_model.config.id2label[np.argmax(
logits[0].detach().numpy())])
print("Full softmax scores:")
for i in range(3):
print(nli_model.config.id2label[i],
logits.softmax(dim=1)[0][i].detach().numpy())
print("="*20)可以看到,模型输出了每个句子对的正确标签:
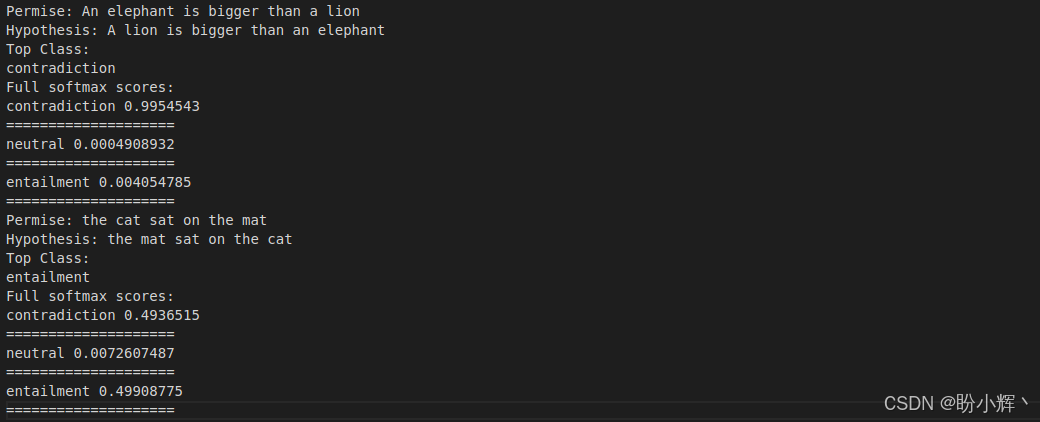
模型对于第一个示例表现成功,但对于第二个示例结果并不明确。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)