集中式架构、分布式架构与微服务架构全面解析
- 一、架构演进背景与发展动因
-
- [1.1 集中式架构的局限](#1.1 集中式架构的局限)
- [1.2 向分布式架构演进:解决"扩展与解耦"问题](#1.2 向分布式架构演进:解决“扩展与解耦”问题)
- [1.3 迈向微服务架构:解决"自治与敏捷"问题](#1.3 迈向微服务架构:解决“自治与敏捷”问题)
- [二、集中式架构(Monolithic Architecture)](#二、集中式架构(Monolithic Architecture))
-
- [2.1 概念](#2.1 概念)
- [2.2 典型场景与示例分析](#2.2 典型场景与示例分析)
- [2.3 架构示意](#2.3 架构示意)
- [2.4 技术栈示例](#2.4 技术栈示例)
- [2.5 优缺点分析](#2.5 优缺点分析)
- [2.6 典型优化策略](#2.6 典型优化策略)
- [三、分布式架构(Distributed Architecture)](#三、分布式架构(Distributed Architecture))
-
- [3.1 概念](#3.1 概念)
- [3.2 典型场景与示例分析](#3.2 典型场景与示例分析)
- [3.3 架构示意](#3.3 架构示意)
- [3.4 技术栈示例](#3.4 技术栈示例)
- [3.5 优缺点分析](#3.5 优缺点分析)
- [3.6 典型优化策略](#3.6 典型优化策略)
- [四、微服务架构(Microservices Architecture)](#四、微服务架构(Microservices Architecture))
-
- [4.1 概念](#4.1 概念)
- [4.2 典型场景与示例分析](#4.2 典型场景与示例分析)
- [4.3 架构示意](#4.3 架构示意)
- [4.4 技术栈示例](#4.4 技术栈示例)
- [4.5 优缺点分析](#4.5 优缺点分析)
- [4.6 典型优化策略](#4.6 典型优化策略)
- 五、三种架构对比表
- 六、总结与架构选择建议
-
- [6.1 架构演进的核心逻辑](#6.1 架构演进的核心逻辑)
- [6.2 从集中到分布式再到微服务的必然性](#6.2 从集中到分布式再到微服务的必然性)
- [6.3 架构演进路径](#6.3 架构演进路径)
- [6.4 架构选择](#6.4 架构选择)
- [6.5 实践建议](#6.5 实践建议)
在现代企业级软件系统中,架构的选择直接影响系统的可扩展性、可靠性、运维成本以及团队协作效率。
本文将对集中式架构(Monolithic) 、分布式架构(Distributed) 、微服务架构(Microservices) 进行系统分析,结合具体业务场景,详细阐述架构特点、技术栈、优缺点及适用场景。
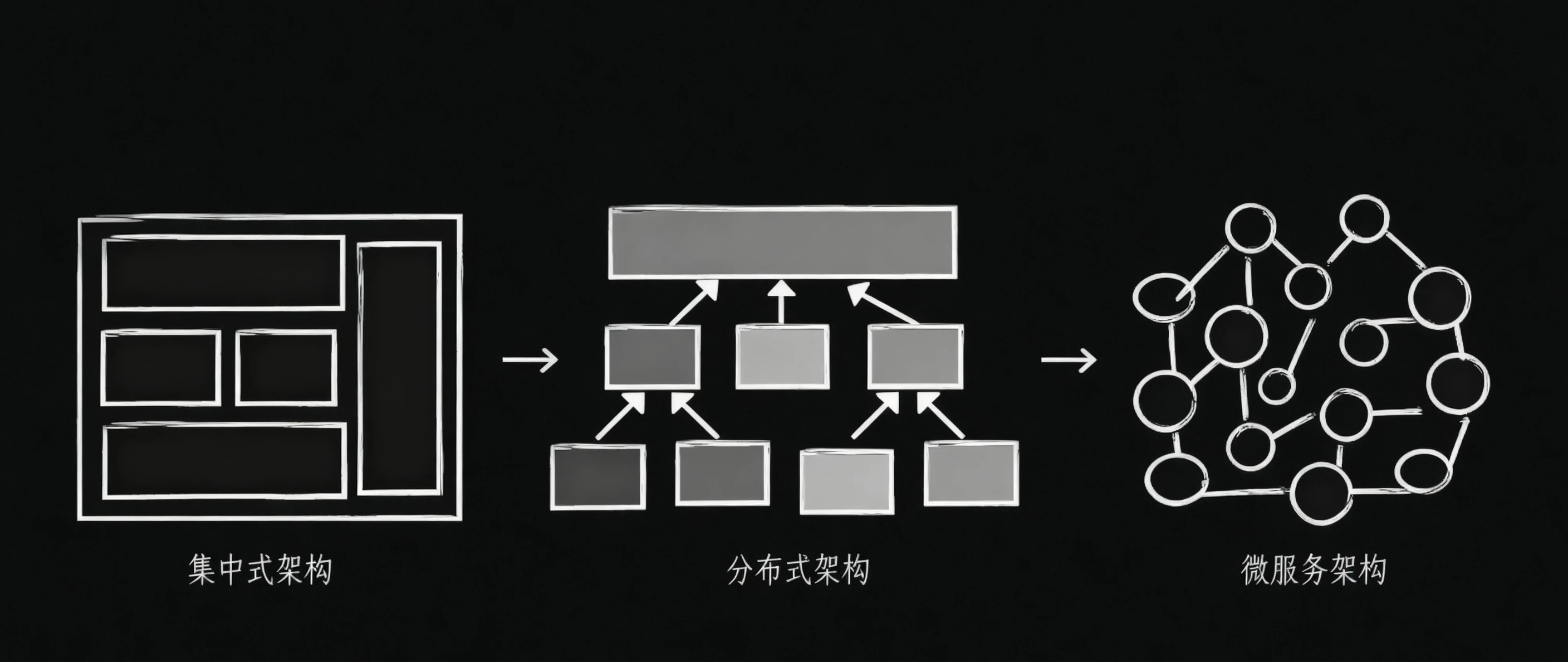
一、架构演进背景与发展动因
在软件系统的发展历程中,架构模式的演进本质上是对"规模、复杂度与效率"的持续平衡。
随着业务规模扩大、用户量增长、团队协作复杂化,传统的集中式架构逐渐难以满足系统的高并发、高可用和快速迭代需求,于是演化出了分布式与微服务架构。
1.1 集中式架构的局限
在早期系统中,集中式(单体)架构最为常见。它将所有功能模块集中在一个应用中,开发部署简单 、上手成本低,非常适合中小型业务。
但随着系统功能增多和访问量增加,集中式架构会暴露出以下问题:
-
无法针对热点模块单独扩展,整体扩容成本高
-
模块耦合严重,修改一个模块可能影响整个系统
-
团队协作困难,多人并行开发冲突频繁
-
部署周期长,单次发布风险高
这些问题直接限制了系统的可扩展性和迭代速度。
1.2 向分布式架构演进:解决"扩展与解耦"问题
为了解决单体架构的扩展瓶颈,企业开始采用分布式架构:
将系统按业务功能拆分为多个可独立运行的模块或服务,部署在不同服务器上,通过网络通信协作完成业务流程。
核心目标:实现模块解耦与独立扩展。
分布式架构的优势:
-
各模块可独立部署与扩容,资源利用率更高
-
故障隔离能力增强,单模块故障不影响全局
-
支持团队并行开发与交付
然而,分布式系统也带来了新的挑战:
-
服务间通信复杂(同步/异步)
-
跨模块数据一致性难以保证
-
系统运维、监控成本上升
于是,业界开始进一步思考:如何在分布式的基础上实现更高自治性、更灵活的服务治理?
1.3 迈向微服务架构:解决"自治与敏捷"问题
微服务架构是分布式架构的自然进化。
它将系统进一步细化为围绕单一业务能力构建的独立服务,每个服务可使用不同技术栈,拥有独立数据库,自主开发、独立部署、独立扩展。
核心目标:实现业务快速迭代与系统高可用。
微服务架构解决了传统分布式的部分痛点:
-
服务自治:每个微服务完全独立,可自由扩展或替换
-
弹性伸缩:结合容器化与编排技术(Kubernetes),实现自动伸缩
-
技术栈多样化:不同服务可使用最适合的语言与框架
-
敏捷交付:支持持续集成与持续部署(CI/CD)
但同时也带来了新的复杂性:
-
分布式事务与数据一致性问题更加突出
-
运维体系(监控、日志、链路追踪)复杂度高
-
服务数量庞大,治理成本上升
因此,微服务架构通常与DevOps、容器化、自动化运维体系结合使用,才能充分发挥其优势。
二、集中式架构(Monolithic Architecture)
2.1 概念
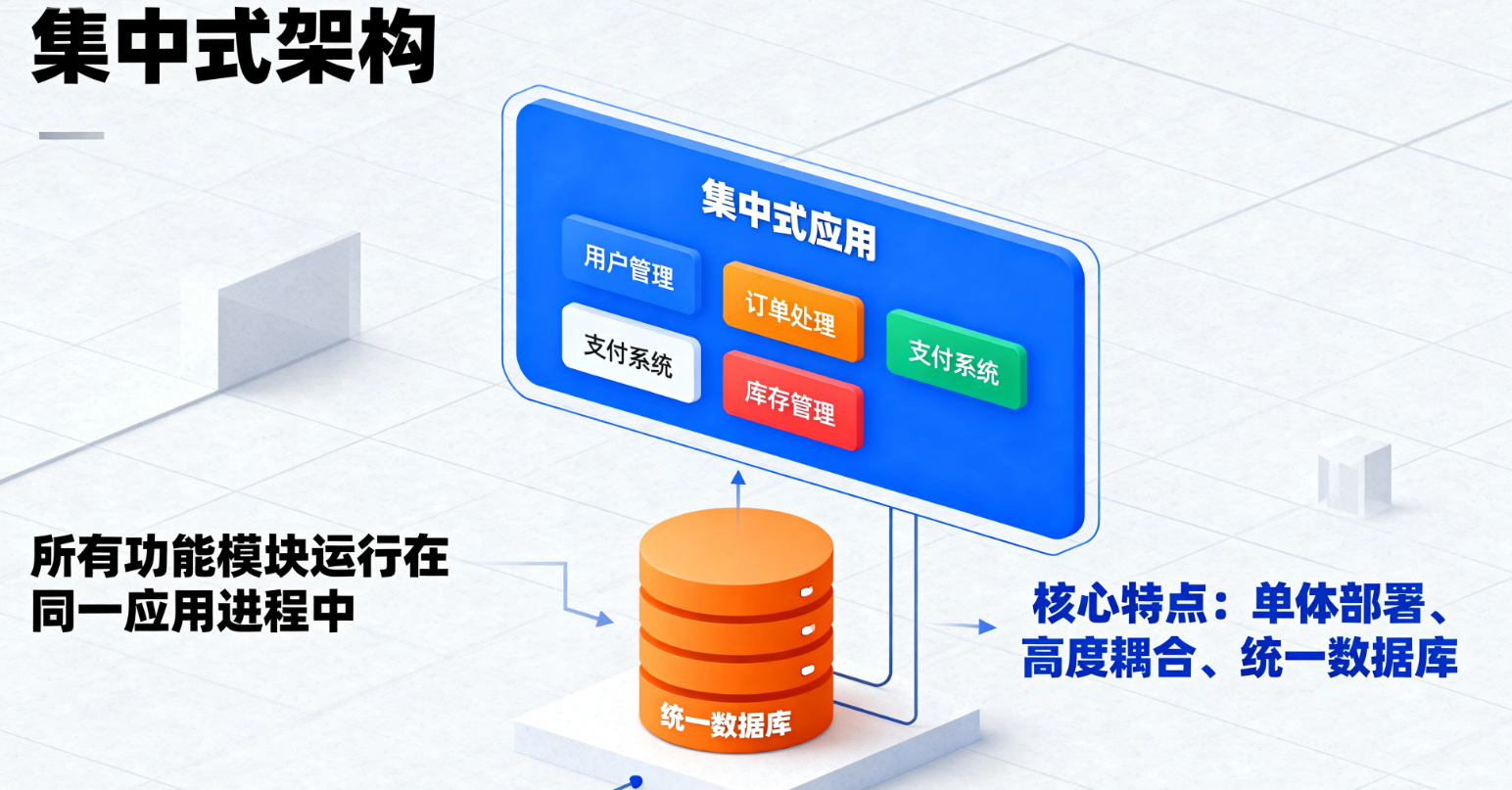
集中式架构是指系统的所有功能模块运行在同一个应用进程中 ,共享同一套数据库和部署单元。模块间高度耦合,通常统一部署和运维,适合系统规模较小、业务逻辑简单的场景。
核心特点:
-
单体部署:应用整体打包上线,所有模块统一更新
-
高度耦合:模块间直接调用函数或方法,数据共享方便
-
统一数据库:所有业务模块操作同一个数据库,事务管理简单
2.2 典型场景与示例分析
场景示例:中小型企业内部管理系统(OA系统、CRM系统)
业务背景:
-
员工人数 50~500,业务流程简单:请假、报销、审批、报表统计
-
系统迭代周期长,更新频率低
-
开发团队规模小(1~5人),不具备复杂运维能力
模块划分:
| 模块 | 功能描述 |
|---|---|
| 用户管理 | 员工信息维护、账号管理 |
| 权限管理 | 角色权限控制 |
| 审批流程 | 请假、报销流程 |
| 报表统计 | 生成业务数据报表 |
| 系统配置 | 参数配置、日志管理 |
业务特性分析:
-
用户请求量中等:日活用户量低,峰值不高
-
模块耦合高:功能紧密依赖,但变化不频繁
-
部署成本低:单体应用即可完成所有功能上线
-
运维压力可控:无需复杂的分布式部署、监控和运维
2.3 架构示意
+---------------------------------+
| 单体应用系统 |
|---------------------------------|
| 用户管理 | 权限管理 | 审批流程 |
| 报表统计 | 系统配置 | ... |
+---------------------------------+
|
单一数据库
|
Redis / Memcached示意分析:
-
所有模块共享同一数据库和缓存
-
内部调用不依赖网络,性能开销小
-
系统升级需整体重启,单模块变更会影响全局
2.4 技术栈示例
| 类别 | 技术栈示例 | 说明 |
|---|---|---|
| 编程语言 | Java(Spring Boot)、Python(Django/Flask)、PHP | 易上手、开发效率高 |
| 数据库 | MySQL、PostgreSQL、Oracle | 单数据库管理,事务处理简单 |
| 缓存 | Redis、Memcached | 提升查询性能,支持热点数据缓存 |
| Web服务器 | Tomcat、Nginx | 支持静态资源和反向代理 |
| 部署方式 | 单机部署或小型容器化部署 | 部署简单,适合小团队运维 |
2.5 优缺点分析
优点
-
开发简单:代码集中,模块间直接调用,易于理解和调试
-
部署方便:单包上线即可,无需复杂的服务编排
-
测试路径清晰:端到端测试覆盖整个系统,单体测试较简单
-
性能稳定:模块内部调用无网络延迟,数据库事务处理集中
缺点
-
扩展性差:无法针对热点模块独立扩展,遇到高并发瓶颈需整体扩容
-
模块耦合高:修改某模块可能影响全局,系统迭代难度随功能增加而增加
-
演进受限:系统变大后,团队协作和代码维护复杂度显著提升
-
技术栈单一:无法按模块优化或引入不同技术栈(如某模块用 Golang,高性能模块用 C++)
2.6 典型优化策略
为了缓解集中式架构的缺点,小型系统可采取以下优化措施:
-
模块化设计:通过包、模块或内部服务拆分,减少模块耦合
-
分层架构:典型的 MVC/三层架构,数据层、业务层、表现层分离
-
缓存优化:对热点数据使用 Redis/Memcached 提升性能
-
数据库分库分表(后期扩展):在系统增长时,为高负载模块独立数据库
三、分布式架构(Distributed Architecture)
3.1 概念
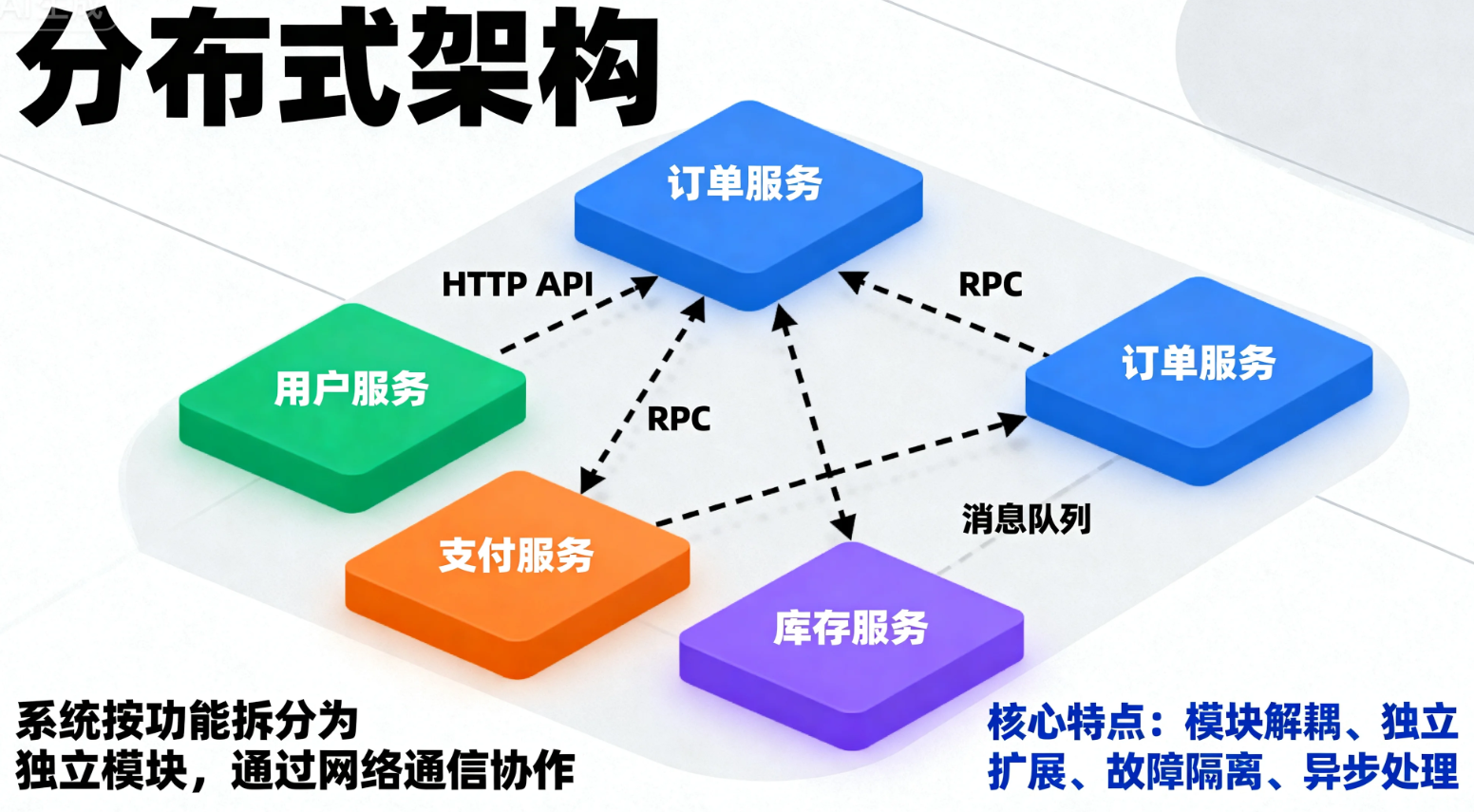
分布式架构将系统按功能拆分为独立模块或服务,各服务部署在不同服务器上,通过网络通信(HTTP API、RPC 或消息队列)协作完成业务逻辑。
核心特点:
-
模块解耦:服务独立,便于单独开发、测试和部署
-
独立扩展:不同模块可单独横向扩展,满足负载需求
-
故障隔离:单服务故障不会导致全局系统不可用
-
异步处理:支持消息队列和事件驱动,提高系统吞吐量
3.2 典型场景与示例分析
场景示例:中型电商订单系统
业务背景:
-
用户量每日 10 万,订单峰值期间可达 50 万
-
系统包含用户服务、订单服务、支付服务、库存服务
-
各模块负载不同,订单服务高峰压力大,支付服务需保证高可靠性
模块划分:
| 模块 | 功能描述 |
|---|---|
| 用户服务 | 用户注册、登录、账户信息管理 |
| 订单服务 | 下单、订单状态管理 |
| 支付服务 | 支付处理、支付结果回调 |
| 库存服务 | 库存锁定、更新、同步 |
| 商品服务 | 商品信息管理 |
业务特性分析:
-
高并发请求,需要模块独立扩展
-
模块间业务边界清晰,服务间通信需保证数据一致性
-
异步消息队列用于库存更新和支付通知,减轻高峰压力
3.3 架构示意
+----------------+ +----------------+ +----------------+
| 用户服务 | ---> | 订单服务 | ---> | 支付服务 |
| (User Service) | | (Order Service)| | (Payment) |
+----------------+ +----------------+ +----------------+
| | |
数据库1 数据库2 数据库3
| | |
Redis Redis Redis
服务通信方式:
- 同步:REST API / RPC
- 异步:Kafka / RabbitMQ示意分析:
-
每个服务拥有独立数据库和缓存,保证服务自治
-
订单服务高峰可通过增加实例扩展处理能力
-
消息队列解耦支付和库存更新,降低同步依赖
3.4 技术栈示例
| 类别 | 技术栈示例 | 说明 |
|---|---|---|
| 服务开发 | Java:Spring Cloud + Feign/Ribbon | 支持服务发现、负载均衡 |
| Python:FastAPI + Celery/Kombu | 异步任务处理 | |
| Golang:Gin + gRPC | 高性能服务通信 | |
| 通信协议 | REST API、gRPC、Thrift | 同步/异步多协议选择 |
| 消息队列 | Kafka、RabbitMQ、RocketMQ | 异步事件驱动,解耦服务 |
| 数据库 | MySQL、PostgreSQL、MongoDB | 服务独立数据库,支持横向扩展 |
| 缓存 | Redis Cluster、Memcached | 热点数据缓存 |
| 服务治理 | Eureka、Consul、etcd | 服务注册、发现和健康检查 |
| 配置管理 | Nacos、Spring Cloud Config | 动态配置管理 |
| 监控与追踪 | Prometheus、Grafana、Jaeger/Zipkin | 分布式链路追踪和性能监控 |
3.5 优缺点分析
优点
-
可横向扩展:根据模块负载不同独立扩展服务实例
-
故障隔离:单服务异常不会影响全局,提升可用性
-
团队协作高效:各模块独立开发、测试和部署
-
技术栈灵活:模块可选最适合的语言或框架
缺点
-
系统复杂度高:部署、运维和监控要求较高
-
数据一致性难:跨服务事务需额外处理(Saga、TCC 等模式)
-
网络通信开销:远程调用带来延迟和潜在失败
-
调试和测试复杂:需分布式链路追踪和模拟各服务
3.6 典型优化策略
-
服务拆分合理化:根据业务边界拆分服务,避免粒度过细导致管理成本高
-
消息队列异步解耦:库存、支付、通知等高并发模块使用异步消息处理
-
服务治理与监控:引入注册发现、熔断、限流和链路追踪
-
数据库优化:分库分表或读写分离,提高性能和可扩展性
-
容器化部署:使用 Docker/Kubernetes 管理服务实例,提升弹性扩展能力
四、微服务架构(Microservices Architecture)
4.1 概念
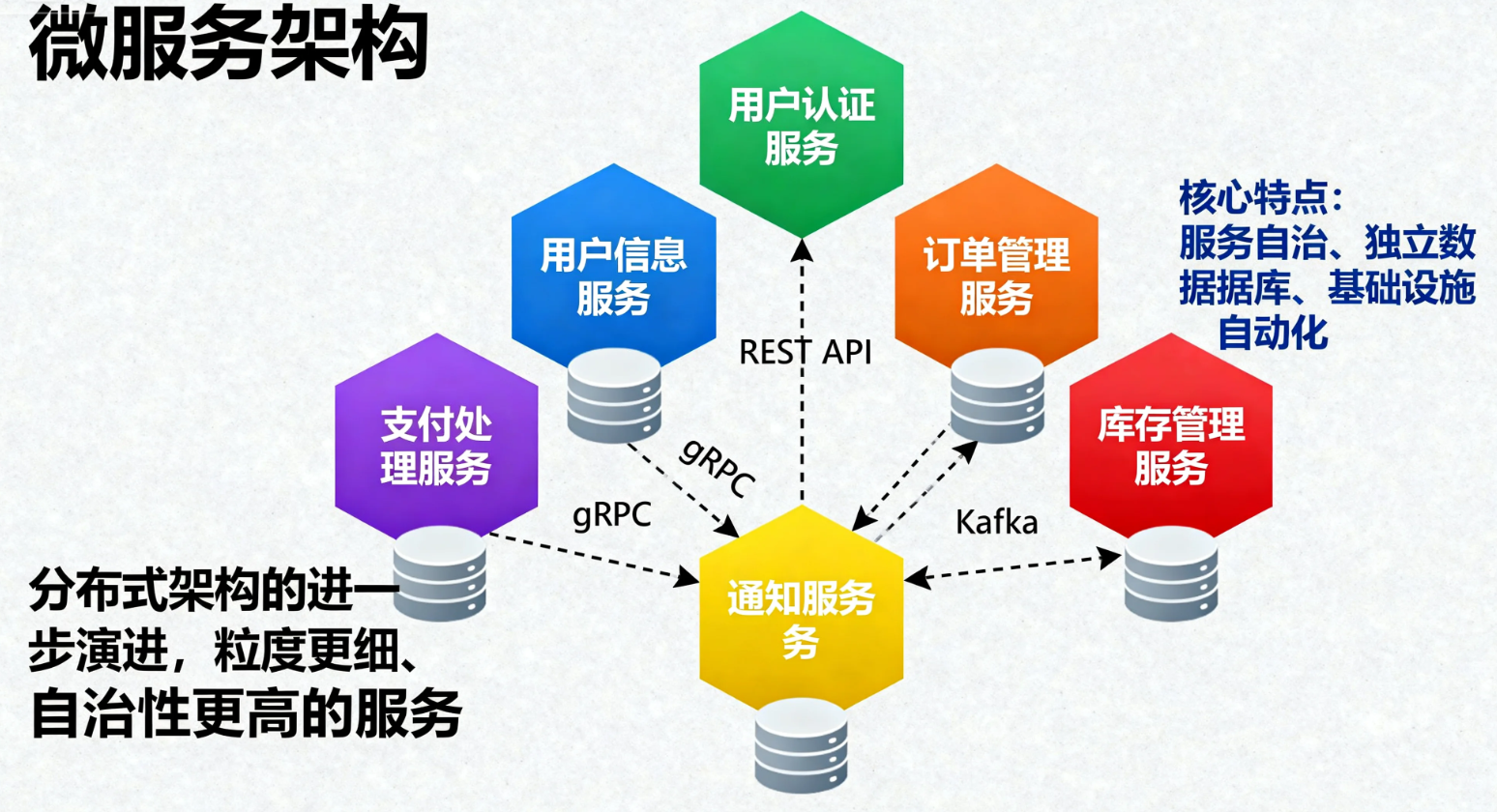
微服务架构是分布式架构的进一步演进,将系统拆分为粒度更细、自治性更高的服务。每个服务围绕单一业务功能构建,拥有独立数据库和技术栈。
核心特点:
-
服务自治:服务独立开发、部署、运维
-
独立数据库:每个服务管理自己的数据,保证数据隔离
-
基础设施自动化:自动化运维、服务注册发现、配置管理、监控、分布式追踪
4.2 典型场景与示例分析
场景示例:大型互联网电商系统
业务背景:
-
用户量千万级,订单量百万级
-
系统业务模块众多:用户、订单、支付、库存、推荐系统、搜索服务
-
各模块迭代频繁,技术栈可能多样化(Java、Golang、Python混合)
-
系统需高可用、高并发、弹性扩展
模块划分:
| 模块 | 功能描述 |
|---|---|
| 用户服务 | 用户注册、登录、账户信息、积分管理 |
| 订单服务 | 下单、订单状态管理、订单查询 |
| 支付服务 | 支付处理、回调、退款处理 |
| 库存服务 | 库存锁定、更新、同步 |
| 商品服务 | 商品信息管理、价格、库存查询 |
| 推荐系统 | 用户个性化推荐、活动策略 |
| 搜索服务 | 商品搜索、搜索优化、搜索缓存 |
| 通知服务 | 消息推送、邮件、短信通知 |
业务特性分析:
-
高并发访问,高峰流量动态变化
-
服务边界清晰,模块间独立部署
-
异步消息处理和事件驱动普遍(库存更新、支付回调、消息通知)
4.3 架构示意
+--------------------+
| API 网关 |
+--------------------+
/ | \
+----------------+ +----------------+ +----------------+
| 用户服务 | | 订单服务 | | 支付服务 |
+----------------+ +----------------+ +----------------+
| | |
Redis / DB DB / MQ DB / MQ
基础设施:
- 服务注册与发现:Eureka / Consul / etcd
- 配置中心:Nacos / Spring Cloud Config
- 消息队列:Kafka / RabbitMQ
- 分布式追踪:Jaeger / Zipkin
- 容器编排:Docker + Kubernetes
- API 网关:Spring Cloud Gateway / Kong示意分析:
-
API 网关统一入口,做路由、认证和限流
-
每个服务独立数据库和缓存,保证自治和高可用
-
消息队列和事件驱动实现异步解耦
-
容器化部署和自动扩缩容保证弹性和高并发处理能力
4.4 技术栈示例
| 类别 | 技术栈示例 | 说明 |
|---|---|---|
| 服务开发 | Java:Spring Boot + Spring Cloud | 支持服务治理、负载均衡、快速开发 |
| Python:FastAPI + Celery | 异步任务和消息处理 | |
| Golang:Gin + gRPC | 高性能、轻量级服务 | |
| 通信协议 | REST API、gRPC、GraphQL | 同步/异步多协议选择 |
| 数据库 | MySQL、PostgreSQL、MongoDB | 每服务独立数据库,支持分布式扩展 |
| 缓存 | Redis Cluster | 高可用分布式缓存 |
| 消息队列 | Kafka、RabbitMQ、Pulsar | 异步解耦,支持事件驱动 |
| 服务治理 | Eureka、Consul、etcd | 服务注册、发现、健康检查 |
| 配置中心 | Nacos、Spring Cloud Config | 动态配置管理 |
| 监控与追踪 | Prometheus、Grafana、ELK、Jaeger、Zipkin | 性能监控、日志、分布式链路追踪 |
| 容器化与编排 | Docker + Kubernetes | 弹性部署和自动扩缩容 |
| 安全 | OAuth2、JWT、API网关策略 | 统一认证、访问控制 |
4.5 优缺点分析
优点
-
弹性伸缩:服务可独立扩展,满足高并发需求
-
独立部署:快速迭代和发布,无需整体重启
-
故障隔离:单服务故障不会影响其他服务
-
技术栈自由:可针对不同服务选择最适合的语言和框架
缺点
-
运维复杂:需完善监控、日志、分布式追踪、健康检查
-
分布式事务复杂:跨服务事务需使用 Saga / TCC 等模式
-
网络通信开销大:远程调用带来延迟和性能优化需求
-
测试复杂:需要端到端自动化测试和服务 Mock
4.6 典型优化策略
-
服务拆分粒度合理:避免过细导致服务管理成本高,保持业务边界清晰
-
事件驱动与消息队列:异步处理支付、库存、通知等高并发业务
-
容器化和自动化运维:Docker + Kubernetes 实现弹性伸缩和快速部署
-
分布式监控和追踪:Prometheus + Grafana + Jaeger 实现全链路监控
-
数据管理优化:独立数据库、读写分离、分库分表,提高性能与扩展性
五、三种架构对比表
| 特性 | 集中式架构(Monolithic) | 分布式架构(Distributed) | 微服务架构(Microservices) |
|---|---|---|---|
| 部署方式 | 单体部署,整个应用一次上线 | 多服务独立部署,可按模块扩展 | 多服务独立部署,支持快速迭代和弹性扩展 |
| 模块耦合 | 高,模块间直接调用和共享数据库 | 中,模块独立但存在服务间依赖 | 低,服务自治、边界清晰,独立数据库 |
| 扩展性 | 差,需整体扩容 | 好,可针对高负载模块单独扩展 | 非常好,服务可独立水平/垂直扩展 |
| 运维复杂度 | 低,部署简单,运维压力小 | 中,需要服务治理和监控 | 高,需要监控、日志、分布式追踪、自动化运维 |
| 数据管理 | 单数据库,事务集中管理 | 可独立或共享数据库 | 每服务独立数据库为主,支持分布式事务或异步事件 |
| 技术栈自由度 | 低,整体技术栈统一 | 中,可为模块选用不同技术栈 | 高,服务可使用最适合的语言或框架 |
| 服务粒度 | 粗,功能模块集合 | 中,按业务模块拆分 | 细,按单一业务功能拆分服务 |
| 典型场景 | 小型企业系统、内部管理系统 | 中大型电商、金融核心系统 | 大型互联网系统、云原生应用 |
| 适合团队规模 | 小团队(1-5人) | 中等团队(5-20人) | 大团队/跨部门团队(20+人) |
| 主要挑战 | 扩展性差、迭代慢 | 数据一致性、服务间通信复杂 | 运维复杂、分布式事务、性能优化 |
六、总结与架构选择建议
6.1 架构演进的核心逻辑
| 阶段 | 主要目标 | 典型特征 | 解决的问题 | 新增的挑战 |
|---|---|---|---|---|
| 集中式架构 | 快速构建、简化部署 | 单体应用、共享数据库 | 开发效率、简单部署 | 扩展性与耦合度问题 |
| 分布式架构 | 模块解耦、水平扩展 | 模块化服务、独立部署 | 系统性能与可伸缩性 | 数据一致性、通信复杂度 |
| 微服务架构 | 服务自治、敏捷迭代 | 独立服务、自动化运维 | 持续交付与高可用 | 运维复杂度、分布式事务 |
6.2 从集中到分布式再到微服务的必然性
| 发展动因 | 解决方式 | 架构演进 |
|---|---|---|
| 系统复杂度增加 | 模块拆分 | 集中式 → 分布式 |
| 业务增长与负载提升 | 独立扩展 | 分布式 → 微服务 |
| 团队协作与敏捷开发需求 | 服务自治 + 自动化 | 微服务 + DevOps |
架构演进的目标不是"追新",而是"应需而变"。
选择架构应基于业务规模、团队能力与运维水平,循序渐进地从单体到分布式,再到微服务,实现系统可扩展性、可维护性与高可用性的平衡。
6.3 架构演进路径
-
单体→分布式:
-
对热点模块进行拆分(如订单、支付)
-
引入消息队列和异步处理
-
实现服务治理、配置管理和监控
-
-
分布式→微服务:
-
进一步拆分微粒度服务,确保每个服务围绕单一业务功能
-
独立数据库、事件驱动、分布式追踪
-
容器化部署和自动化运维(Docker + Kubernetes)
-
6.4 架构选择
| 系统规模 | 推荐架构 | 原因与实践建议 |
|---|---|---|
| 小型项目 | 集中式架构 | 开发周期短、团队小、部署简单;可快速实现 MVP(最小可行产品) |
| 中型系统 | 分布式架构 | 用户量和请求量增加,可按模块独立扩展,支持部分异步处理 |
| 大型、高并发系统 | 微服务架构 | 服务自治、弹性伸缩、快速迭代,高可用、高并发;支持跨团队协作和技术栈多样化 |
6.5 实践建议
-
评估业务规模与负载:根据用户量、交易量、功能复杂度选择合适架构
-
考虑团队能力:小团队适合单体,大团队适合微服务
-
逐步演进:从单体开始,先拆分关键模块,再向微服务演进,降低风险
-
技术与运维准备:分布式或微服务需完善监控、日志、追踪、消息队列和自动化部署体系