一、汇总对比
以 10 秒、48,000 Hz 采样率的音频数据为例,输入数据的维度为 (480000,),各种算法输出维度如下 。
| 算法 | 输出数据维度 | 时间帧数 (T) | 特征维度 (F) | 说明 |
|---|---|---|---|---|
| 短时傅里叶变换 (STFT) | (1025, 938) |
938 |
1025 |
n_fft=2048,hop_length=512 |
| 梅尔频谱 (Mel Spectrogram) | (128, 938) |
938 |
128 |
n_mels=128,n_fft=2048 ,hop_length=512 |
| MuQ | 13 x (1, 250, 1024) |
250 |
1024 |
音频会被重采样到 24000Hz,输出包含 13 层隐藏状态 |
| MERT-v1-95M | (13, 749, 768) |
749 |
768 |
音频会被重采样到 24000Hz,输出包含 13 层隐藏状态 |
| MERT-v1-330M | (25, 749, 1024) |
749 |
1024 |
音频会被重采样到 24000Hz,输出包含 25 层隐藏状态 |
| MusicFM25Hz | (13, 250, 1024) |
250 |
1024 |
音频会被重采样到 24000Hz,输出包含 13 层隐藏状态 |
二、STFT(短时傅里叶变换)
2.1 原理
短时傅里叶变换(Short-Time Fourier Transform, STFT)是传统傅里叶变换的扩展,它解决了时频分辨率权衡 这一核心问题。与全局傅里叶变换只能提供整个信号的频率信息不同,STFT通过加窗滑动的方式,实现了信号在时间和频率维度上的联合分析。
STFT的数学定义如下:
STFT(t,f)=∫−∞∞x(τ)w(τ−t)e−j2πfτdτSTFT(t, f) = \int_{-\infty}^{\infty} x(\tau)w(\tau-t)e^{-j2\pi f\tau}d\tauSTFT(t,f)=∫−∞∞x(τ)w(τ−t)e−j2πfτdτ
其中:
- x(t)x(t)x(t):原始时域信号
- w(t)w(t)w(t):窗函数(如汉明窗、汉宁窗)
- ttt:时间中心点
- fff:频率分量
离散形式的STFT(实际计算中使用):
STFTm,k=∑n=0N−1xnwn−me−j2πkn/NSTFTm, k = \sum_{n=0}^{N-1} xnwn-me^{-j2\pi kn/N}STFTm,k=n=0∑N−1xnwn−me−j2πkn/N
2.2 计算过程
-
信号分帧:
- 帧长(N_FFT) :决定频率分辨率
- 较长帧长 → 频率分辨率高,时间分辨率低
- 较短帧长 → 时间分辨率高,频率分辨率低
- 帧移(Hop Length) :决定时间分辨率
- 较小帧移 → 时间分辨率高,计算量大
- 较大帧移 → 时间分辨率低,计算量小
- 帧长(N_FFT) :决定频率分辨率
-
应用窗口函数:
- 对每一帧应用窗口函数(如汉明窗、汉宁窗),以减少边缘效应。
-
傅里叶变换:
- 对每一帧应用快速傅里叶变换(FFT),将时域信号转换为频域信号。
-
构建频谱矩阵:
- 将每一帧的 FFT 结果组合成一个频谱矩阵,行表示频率,列表示时间。
2.3 输入和输出维度
- 输入信号
y:- 原始音频信号:一维数组
(n_samples,) - 示例:48kHz采样率10秒音频 →
(480000,)
- 原始音频信号:一维数组
- 输出结果
D:- 类型:二维复数 NumPy 数组。
- 维度:
(n_freq, n_frames),其中:n_freq = n_fft // 2 + 1,表示频率bins的数量。n_frames = 1 + (len(y) - n_fft) // hop_length,表示时间帧的数量。
STFT输出为复数矩阵:
- 实部:余弦分量强度
- 虚部:正弦分量强度
- 幅度谱 :实部2+虚部2\sqrt{实部^2 + 虚部^2}实部2+虚部2 ,表示能量分布
- 相位谱 :arctan(虚部/实部)\arctan(虚部/实部)arctan(虚部/实部),表示波形位置
2.4 可视化
python
import librosa
import numpy as np
import matplotlib.pyplot as plt
# 加载音频文件,统一采样率至48kHz
file_path = 'test.wav' # 替换为您的音频文件路径
wav, sr = librosa.load(file_path, sr=48000, mono=True)
print(f"输入数据维度: {wav.shape}")
# 计算短时傅里叶变换 (STFT)
n_fft = 2048 # FFT窗口大小
hop_length = 512 # 每次移动的样本数
stft = librosa.stft(wav, n_fft=n_fft, hop_length=hop_length)
# 将幅度转换为分贝
stft_db = librosa.amplitude_to_db(np.abs(stft))
print(f"输出频谱维度: {stft_db.shape}")
# 可视化 STFT 结果
plt.figure(figsize=(15, 7))
librosa.display.specshow(stft_db, sr=sr, hop_length=hop_length, x_axis='time', y_axis='log', cmap='inferno')
plt.colorbar(format='%+2.0f dB')
plt.title('STFT Magnitude (dB)')
plt.xlabel('Time (s)')
plt.ylabel('Frequency (Hz)')
plt.tight_layout()
plt.show()
python
输入数据维度: (480000,)
输出频谱维度: (1025, 938)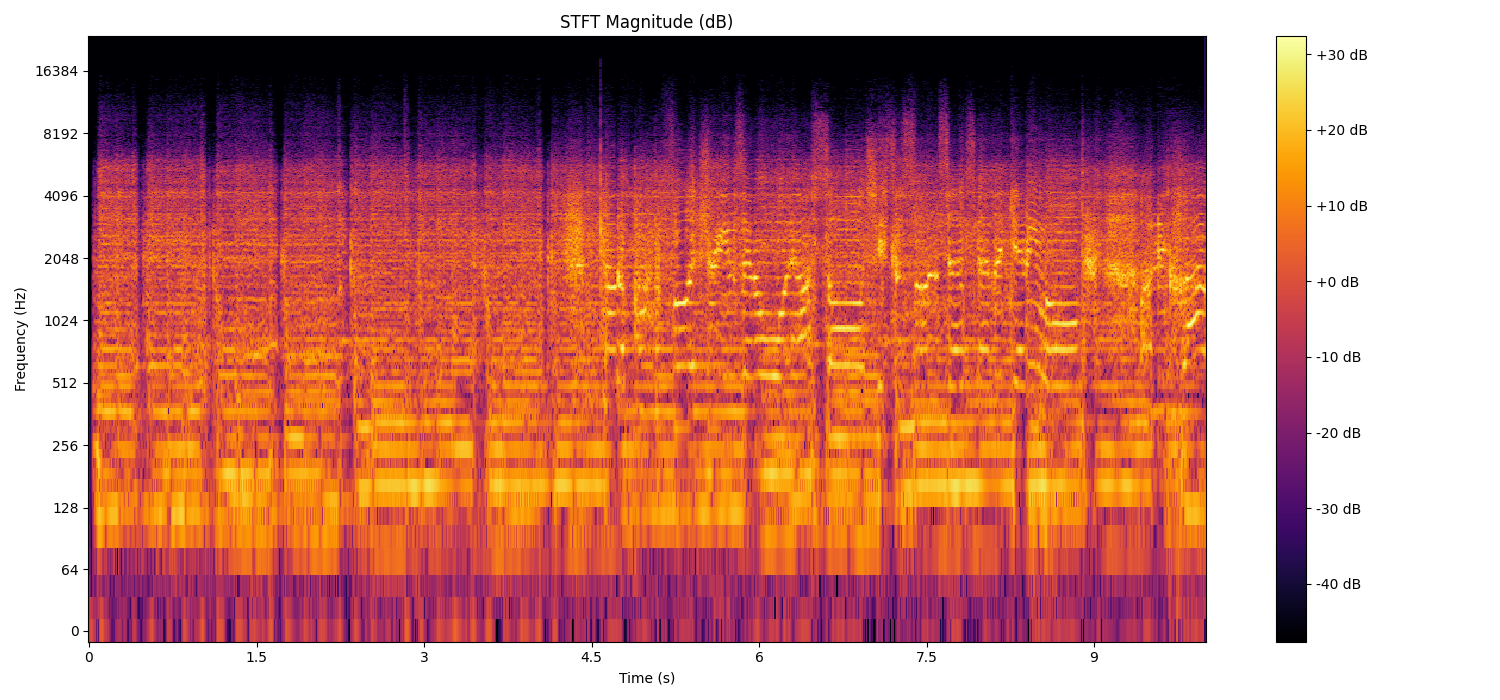
三、梅尔频谱
梅尔频谱是一种基于人耳听觉特性的音频特征表示方法,通过将线性频率转换为梅尔刻度来模拟人类听觉系统对频率的感知。
3.1 梅尔刻度原理
梅尔刻度是一种非线性频率尺度,反映人耳对频率变化的感知特性:低频分辨率高,高频分辨率低。
线性频率fff到梅尔频率fmf_mfm的转换公式:
fm=2595⋅log10(1+f700)f_m = 2595 \cdot \log_{10}(1 + \frac{f}{700})fm=2595⋅log10(1+700f)
特性:
- 低频段:梅尔刻度变化缓慢,分辨率高
- 高频段:梅尔刻度变化迅速,分辨率低
- 符合人耳对音高的感知特性
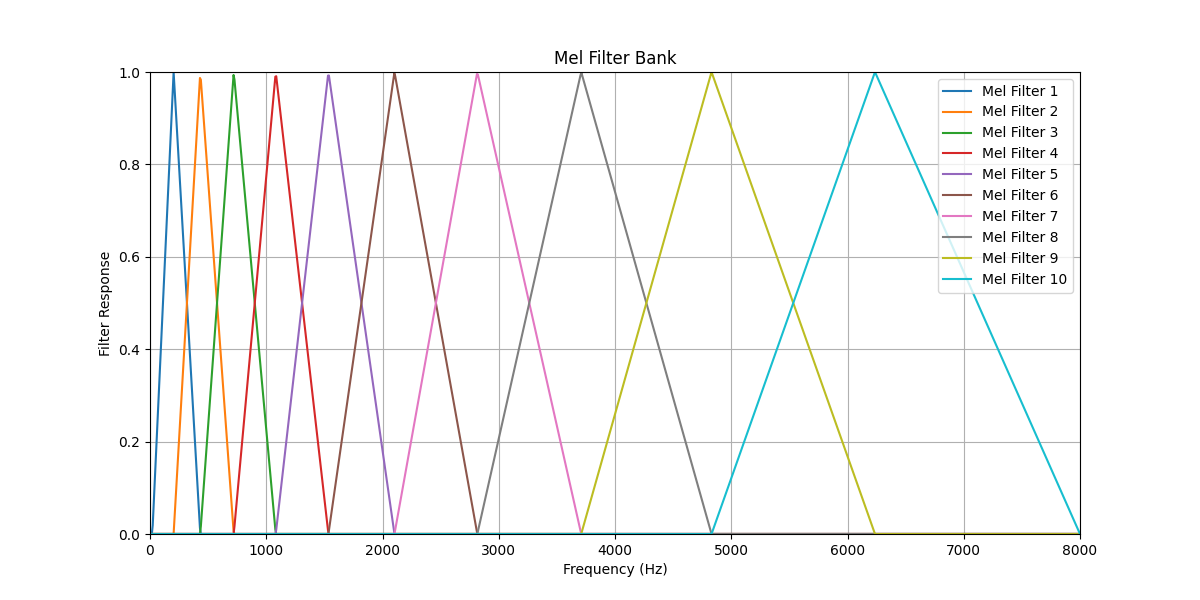
3.2 梅尔滤波器组设计
梅尔滤波器组由一组重叠的三角带通滤波器构成,在梅尔刻度上均匀分布。
-
确定频率范围:
- 最小频率:fminf_{min}fmin(通常0Hz)
- 最大频率:fmaxf_{max}fmax(通常采样率的一半)
-
转换为梅尔刻度 :
melmin=2595⋅log10(1+fmin700)mel_{min} = 2595 \cdot \log_{10}(1 + \frac{f_{min}}{700})melmin=2595⋅log10(1+700fmin)
melmax=2595⋅log10(1+fmax700)mel_{max} = 2595 \cdot \log_{10}(1 + \frac{f_{max}}{700})melmax=2595⋅log10(1+700fmax) -
在梅尔刻度上均匀分布 :
meli=melmin+i⋅(melmax−melmin)N+1(i=0,1,...,N+1)mel_i = mel_{min} + \frac{i \cdot (mel_{max} - mel_{min})}{N+1} \quad (i=0,1,...,N+1)meli=melmin+N+1i⋅(melmax−melmin)(i=0,1,...,N+1)其中NNN为滤波器数量
-
转换回线性频率 :
fi=700⋅(10meli/2595−1)f_i = 700 \cdot (10^{mel_i/2595} - 1)fi=700⋅(10meli/2595−1) -
构建三角滤波器 :
对于每个滤波器Hk(f)H_k(f)Hk(f):
Hk(f)={0,f<fk−1f−fk−1fk−fk−1,fk−1≤f<fkfk+1−ffk+1−fk,fk≤f<fk+10,f≥fk+1H_k(f) = \begin{cases} 0, & f < f_{k-1} \\ \frac{f - f_{k-1}}{f_k - f_{k-1}}, & f_{k-1} \leq f < f_k \\ \frac{f_{k+1} - f}{f_{k+1} - f_k}, & f_k \leq f < f_{k+1} \\ 0, & f \geq f_{k+1} \end{cases}Hk(f)=⎩ ⎨ ⎧0,fk−fk−1f−fk−1,fk+1−fkfk+1−f,0,f<fk−1fk−1≤f<fkfk≤f<fk+1f≥fk+1
3.3 梅尔频谱计算流程
-
计算STFT频谱:
- 输入:时域信号x(t)x(t)x(t)
- 输出:复数频谱X(t,f)X(t,f)X(t,f)
-
计算功率谱 :
P(t,f)=∣X(t,f)∣2P(t,f) = |X(t,f)|^2P(t,f)=∣X(t,f)∣2 -
应用梅尔滤波器组 :
M(t,m)=∑fHm(f)⋅P(t,f)M(t,m) = \sum_f H_m(f) \cdot P(t,f)M(t,m)=f∑Hm(f)⋅P(t,f)其中mmm为梅尔频带索引
-
对数压缩 (可选):
Mlog(t,m)=log(M(t,m)+ϵ)M_{log}(t,m) = \log(M(t,m) + \epsilon)Mlog(t,m)=log(M(t,m)+ϵ)
3.4 输入和输出维度
-
输入维度:
- 原始音频信号:一维数组
(n_samples,) - 示例:48kHz采样率10秒音频 →
(480000,)
- 原始音频信号:一维数组
-
输出维度:
- 梅尔频谱矩阵:二维数组
(n_mels, n_frames) - 其中
n_mels为梅尔滤波器数量(通常64-128),n_frames = 1 + (len(y) - n_fft) // hop_length,表示时间帧的数量。
- 梅尔频谱矩阵:二维数组
3.5 可视化
python
import librosa
import numpy as np
import matplotlib.pyplot as plt
import librosa.display
# Load the audio file and set the sample rate to 48kHz
file_path = 'test.wav' # Replace with your audio file path
wav, sr = librosa.load(file_path, sr=48000, mono=True)
print(f"Input data dimensions: {wav.shape}")
# Calculate the Mel spectrogram
n_fft = 2048 # FFT window size
hop_length = 512 # Number of samples to move each time
n_mels = 128 # Number of Mel bands
mel_spectrogram = librosa.feature.melspectrogram(y=wav, sr=sr, n_fft=n_fft, hop_length=hop_length, n_mels=n_mels)
# Convert amplitude to decibels
mel_spectrogram_db = librosa.amplitude_to_db(mel_spectrogram, ref=np.max)
print(f"Output Mel spectrogram dimensions: {mel_spectrogram_db.shape}")
# Visualize the Mel spectrogram
plt.figure(figsize=(15, 7))
librosa.display.specshow(mel_spectrogram_db, sr=sr, hop_length=hop_length, x_axis='time', y_axis='mel', cmap='inferno')
plt.colorbar(format='%+2.0f dB')
plt.title('Mel Spectrogram (dB)')
plt.xlabel('Time (s)')
plt.ylabel('Mel Frequency (Mel)') # Updated label for clarity
plt.tight_layout()
plt.show()
python
Input data dimensions: (480000,)
Output Mel spectrogram dimensions: (128, 938)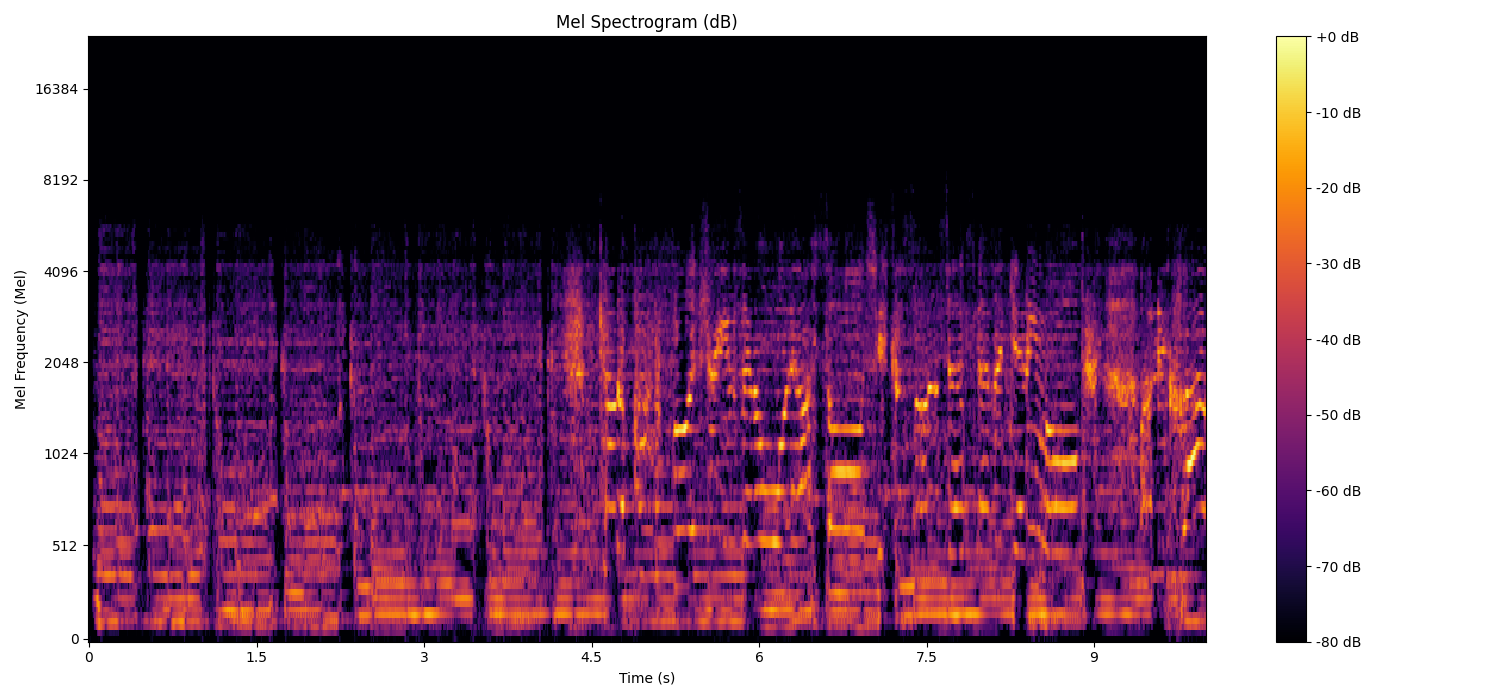
四、MUQ模型
MuQ(Music Understanding with Mel Quantization)是一种基于自监督学习的音乐表示模型,通过梅尔残差向量量化(Mel-RVQ)提取音频特征。该模型的核心创新在于使用预训练的Mel-RVQ作为目标生成器,通过残差量化机制将梅尔频谱转换为离散令牌,然后通过Conformer编码器学习这些令牌的上下文表示,最终输出丰富的音频特征。这些特征同时捕获音乐的语义和声学信息,适用于多种音乐信息检索和理解任务。
4.1 特征提取详细流程
-
音频预处理与梅尔频谱提取:MuQ首先将原始音频信号转换为梅尔频谱,这是一种符合人耳听觉特性的时频表示。预处理步骤包括:
- 音频加载:统一采样率为24kHz,确保与预训练模型兼容
- 梅尔频谱计算:通过短时傅里叶变换(STFT)和梅尔刻度滤波得到128维梅尔频谱
- 帧处理:使用帧长2048(n_fft)和帧移512(hop_length),对于10秒音频产生约938个时间帧
-
Mel-RVQ目标生成:预训练的Mel-RVQ对梅尔频谱进行残差向量量化,生成离散标记作为自监督学习目标。
- 初始残差 :r(1)=xr^{(1)} = xr(1)=x(梅尔频谱)
- 逐步量化 :对于每个码本步骤n=1n = 1n=1到NNN(通常N=8N=8N=8):
- 投影:z(n)=MP(n)(r(n))z^{(n)} = M_P^{(n)}(r^{(n)})z(n)=MP(n)(r(n))
- 量化:τ(n)=argmink∥z(n)−Qk(n)∥2\tau^{(n)} = \arg\min_k \| z^{(n)} - Q_k^{(n)} \|_2τ(n)=argmink∥z(n)−Qk(n)∥2
- 残差更新:r(n+1)=r(n)−MD(n)(Qτ(n)(n))r^{(n+1)} = r^{(n)} - M_D^{(n)}(Q_{\tau^{(n)}}^{(n)})r(n+1)=r(n)−MD(n)(Qτ(n)(n))
- 输出 :生成N个标记序列τ(1),τ(2),...,τ(N)\tau^{(1)}, \tau^{(2)}, \ldots, \tau^{(N)}τ(1),τ(2),...,τ(N)作为目标
-
Conformer编码与特征学习:MuQ使用12层Conformer编码器处理梅尔频谱,学习令牌的上下文表示。Conformer结合卷积和自注意力机制,能有效捕获音频的局部和全局特征:
- 输入:部分掩码的梅尔频谱(掩码概率p=0.6)
- 编码:通过Conformer层进行上下文学习
- 预测:使用N个线性层预测对应的目标令牌
- 损失:交叉熵损失 between预测和目标令牌
-
特征输出与提取:模型输出包含多个隐藏状态,提供不同层级的特征表示:
- 最后一层隐藏状态 (output.last_hidden_state):高级语义特征,形状为
[batch_size, sequence_length, feature_dim] - 所有隐藏状态
(output.hidden_states):包含13层输出(1个嵌入层+12个Conformer层),每层形状相同
4.2 特征提取代码
python
import torch
import librosa
from muq import MuQ
device = 'mps' # 使用 Apple Silicon GPU 进行计算
wav, sr = librosa.load("test.wav", sr=24000) # 加载音频文件,采样率设置为 24kHz
wavs = torch.tensor(wav).unsqueeze(0).to(device) # 将音频数据转换为张量并添加批次维度,移动到 GPU
# 这将自动从 Hugging Face 获取检查点
muq = MuQ.from_pretrained("OpenMuQ/MuQ-large-msd-iter") # 加载预训练的 MuQ 模型
muq = muq.to(device).eval() # 将模型移动到 GPU 并设置为评估模式
with torch.no_grad(): # 禁用梯度计算以提高推理效率
output = muq(wavs, output_hidden_states=True) # 进行前向传播,获取输出和隐藏状态
# 打印隐藏层的总数
print('Total number of layers: ', len(output.hidden_states))
# 打印最后一层输出的特征形状
print('Feature shape: ', output.last_hidden_state.shape)
# 打印 output 的完整形状
print('Output shape: ', {
'last_hidden_state': output.last_hidden_state.shape,
'hidden_states': [state.shape for state in output.hidden_states]
})
# 分析输出
print("\nAnalysis of output:")
print(f"Last hidden state shape: {output.last_hidden_state.shape}")
print(f"Number of hidden states: {len(output.hidden_states)}")
for i, hidden_state in enumerate(output.hidden_states):
print(f"Shape of hidden state {i}: {hidden_state.shape}")
python
Total number of layers: 13
Output shape: {'last_hidden_state': torch.Size([1, 250, 1024]), 'hidden_states': [torch.Size([1, 250, 1024]), torch.Size([1, 250, 1024]), torch.Size([1, 250, 1024]), torch.Size([1, 250, 1024]), torch.Size([1, 250, 1024]), torch.Size([1, 250, 1024]), torch.Size([1, 250, 1024]), torch.Size([1, 250, 1024]), torch.Size([1, 250, 1024]), torch.Size([1, 250, 1024]), torch.Size([1, 250, 1024]), torch.Size([1, 250, 1024]), torch.Size([1, 250, 1024])]}
Analysis of output:
Last hidden state shape: torch.Size([1, 250, 1024])
Number of hidden states: 13
Shape of hidden state 0: torch.Size([1, 250, 1024])
Shape of hidden state 1: torch.Size([1, 250, 1024])
Shape of hidden state 2: torch.Size([1, 250, 1024])
Shape of hidden state 3: torch.Size([1, 250, 1024])
Shape of hidden state 4: torch.Size([1, 250, 1024])
Shape of hidden state 5: torch.Size([1, 250, 1024])
Shape of hidden state 6: torch.Size([1, 250, 1024])
Shape of hidden state 7: torch.Size([1, 250, 1024])
Shape of hidden state 8: torch.Size([1, 250, 1024])
Shape of hidden state 9: torch.Size([1, 250, 1024])
Shape of hidden state 10: torch.Size([1, 250, 1024])
Shape of hidden state 11: torch.Size([1, 250, 1024])
Shape of hidden state 12: torch.Size([1, 250, 1024])4.3 输出特征详细分析
MuQ输出特征为三维张量,形状为 [batch_size, sequence_length, feature_dim]:
- batch_size:批处理大小,通常为1(单个音频)
- sequence_length:时间步数(250),对应10秒音频的时间帧
- feature_dim :
特征维度(1024),每个时间步的特征向量维度
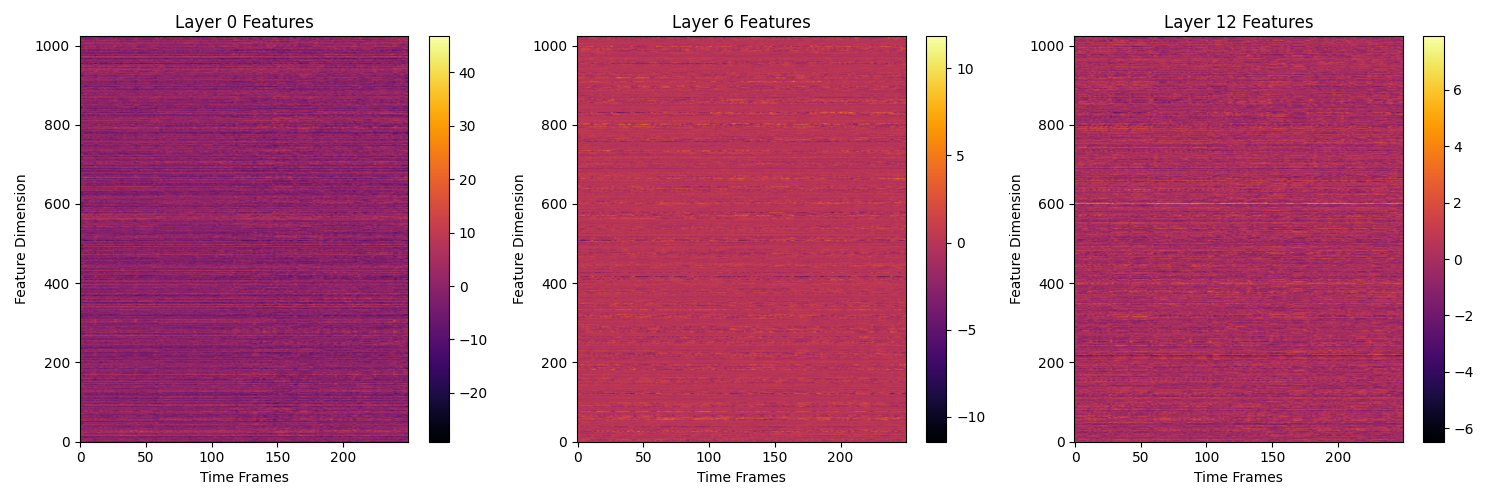
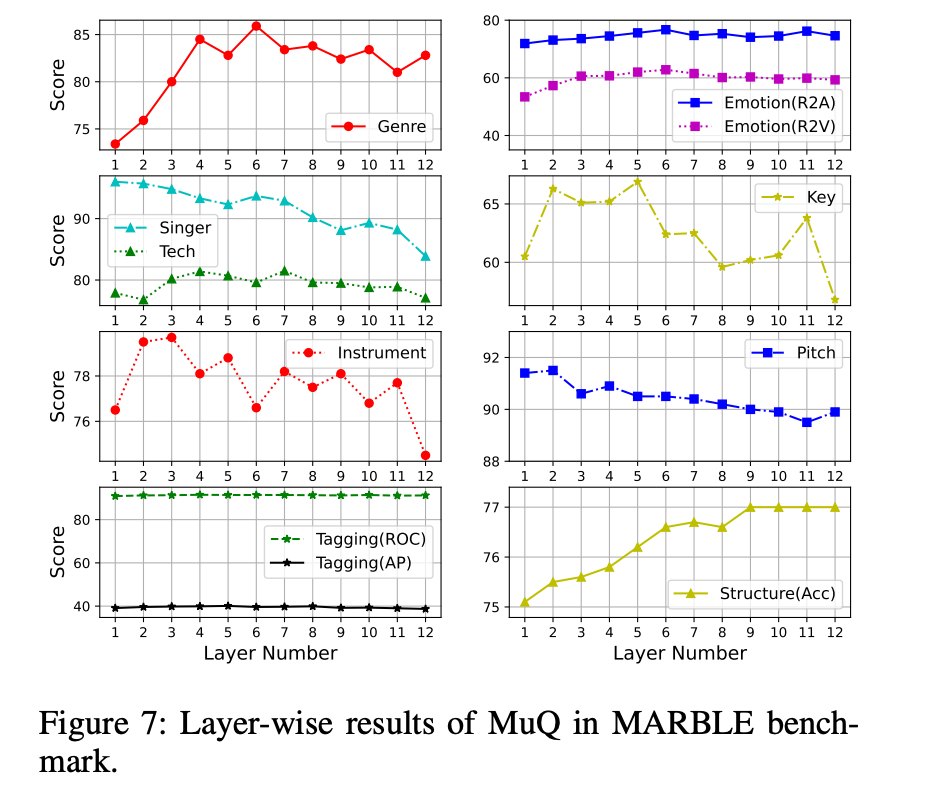
MuQ的13层隐藏状态提供多尺度特征表示:
- 底层(0-3层):捕获低级声学特征(音色、音高、频谱细节)
- 中层(4-8层):提取中级音乐特征(旋律、节奏、和声)
- 高层(9-12层):编码高级语义信息(流派、情感、结构)
各层特征在不同任务中的性能表现:
4.4 特征可视化
python
import torch
import librosa
import matplotlib.pyplot as plt
from muq import MuQ
device = 'mps' # 使用 Apple Silicon GPU 进行计算
wav, sr = librosa.load("test.wav", sr=24000) # 加载音频文件,采样率设置为 24kHz
wavs = torch.tensor(wav).unsqueeze(0).to(device) # 将音频数据转换为张量并添加批次维度,移动到 GPU
# 这将自动从 Hugging Face 获取检查点
muq = MuQ.from_pretrained("OpenMuQ/MuQ-large-msd-iter") # 加载预训练的 MuQ 模型
muq = muq.to(device).eval() # 将模型移动到 GPU 并设置为评估模式
with torch.no_grad(): # 禁用梯度计算以提高推理效率
output = muq(wavs, output_hidden_states=True) # 进行前向传播,获取输出和隐藏状态
# 创建子图
selected_layers = [0, 6, 12] # 选择要绘制的层
num_selected_layers = len(selected_layers)
rows = 1
cols = num_selected_layers
fig, axes = plt.subplots(rows, cols, figsize=(15, 5)) # 创建 1 行 3 列的子图
# 绘制每一层的特征图
for idx, layer in enumerate(selected_layers):
hidden_state = output.hidden_states[layer] # 获取指定层的隐藏状态
feature_map = hidden_state.squeeze(0).cpu().numpy() # 移动到 CPU 并转换为 NumPy 数组
# 转换为 dB 表示
feature_map_db = 20 * torch.log10(torch.tensor(feature_map) + 1e-10).numpy() # 添加小常数以避免对数计算中的问题
ax = axes[idx] # 计算当前子图的位置
im = ax.imshow(feature_map_db.T, aspect='auto', origin='lower', cmap='inferno') # 转置特征图
ax.set_title(f'Hidden State {layer} (dB)')
ax.set_xlabel('Time Frames (250)')
ax.set_ylabel('Feature Points (1024)')
ax.set_xticks(range(0, 250, 25))
ax.set_xticklabels(range(0, 250, 25))
ax.set_yticks(range(0, 1024, 128))
ax.set_yticklabels(range(0, 1024, 128))
# 添加每个子图的颜色条
cbar = fig.colorbar(im, ax=ax, orientation='vertical', fraction=0.02, pad=0.04)
cbar.set_label('Feature Value (dB)')
plt.tight_layout() # 自动调整子图间距
plt.show()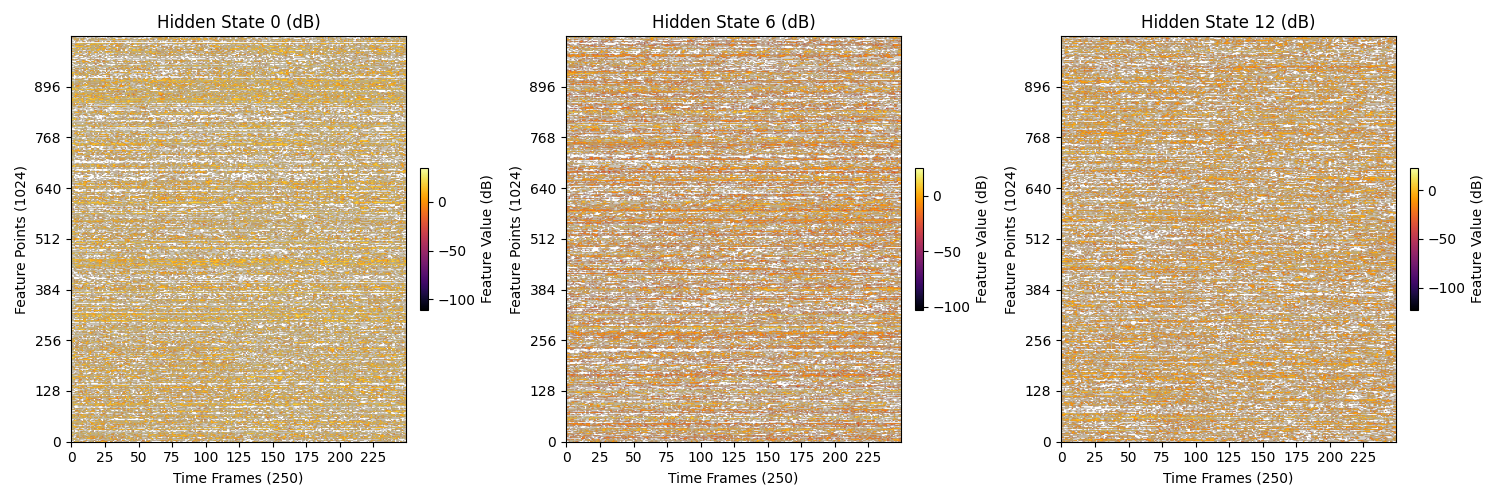
五、 MERT 模型
MERT(Music undERstanding Transformer)采用双教师引导的自监督学习架构,通过融合声学特征和音乐特征实现高效的音乐表示学习。其核心创新在于同时使用RVQ-VAE作为声学教师和CQT作为音乐教师,为掩码语言建模提供多维度伪标签。
5.1 特征提取
MERT的特征提取流程通过多教师监督 、层级特征编码 和任务自适应选择三个核心机制,实现了对音乐音频的深度理解。其提取的特征兼具:
- 声学精确性:RVQ-VAE保障底层声学细节
- 音乐语义性:CQT注入音乐领域知识
- 多尺度适应性:不同层级支持不同粒度任务
- 计算高效性:轻量架构支持实时应用
5.2 特征提取代码
python
import librosa
import torch
from transformers import Wav2Vec2FeatureExtractor, AutoModel
# 加载模型和处理器
model = AutoModel.from_pretrained("m-a-p/MERT-v1-95M", trust_remote_code=True)
processor = Wav2Vec2FeatureExtractor.from_pretrained("m-a-p/MERT-v1-95M", trust_remote_code=True)
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
def process_custom_audio(audio_path):
"""
处理自定义音频文件的主要函数
"""
# 使用librosa加载音频文件,直接指定采样率为24000Hz
audio, original_sr = librosa.load(audio_path, sr=24000, mono=True)
# 转换为PyTorch张量
audio_tensor = torch.from_numpy(audio).float()
# 使用处理器预处理音频
inputs = processor(
audio_tensor,
sampling_rate=24000, # 直接使用24000Hz
return_tensors="pt",
padding=True
)
# 移动到设备
inputs = {k: v.to(device) for k, v in inputs.items()}
# 提取特征
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True)
# 处理所有隐藏状态
all_layer_hidden_states = torch.stack(outputs.hidden_states).squeeze()
# 打印每一层的特征形状
for i, hidden_state in enumerate(outputs.hidden_states):
print(f"Layer {i} shape: {hidden_state.shape}")
return {
"all_layer_states": all_layer_hidden_states
}
# 使用示例
if __name__ == "__main__":
# 替换为您自己的音频文件路径
custom_audio_path = "test.wav"
try:
features = process_custom_audio(custom_audio_path)
print("特征提取成功!")
print(f"所有层特征形状: {features['all_layer_states'].shape}")
except Exception as e:
print(f"处理音频时出错: {e}")
python
Layer 0 shape: torch.Size([1, 749, 768])
Layer 1 shape: torch.Size([1, 749, 768])
Layer 2 shape: torch.Size([1, 749, 768])
Layer 3 shape: torch.Size([1, 749, 768])
Layer 4 shape: torch.Size([1, 749, 768])
Layer 5 shape: torch.Size([1, 749, 768])
Layer 6 shape: torch.Size([1, 749, 768])
Layer 7 shape: torch.Size([1, 749, 768])
Layer 8 shape: torch.Size([1, 749, 768])
Layer 9 shape: torch.Size([1, 749, 768])
Layer 10 shape: torch.Size([1, 749, 768])
Layer 11 shape: torch.Size([1, 749, 768])
Layer 12 shape: torch.Size([1, 749, 768])
特征提取成功!
所有层特征形状: torch.Size([13, 749, 768])5.3 输出特征详细分析
-
音频输入:
- 维度 :输入音频信号通常为一维数组,形状为
(n_samples,),其中n_samples是音频样本的总数。 - 示例 :对于 48 kHz 采样率的 10 秒音频,输入维度为
(480000,)。如果音频经过重采样,例如从 48 kHz 重采样到 24 kHz,音频样本数将减少到(240000,)。
- 维度 :输入音频信号通常为一维数组,形状为
-
模型输出:
- MERT 模型的输出包括多个隐藏状态,通常以张量的形式返回。
- 维度 :输出的隐藏状态的维度为
(L, T, F),其中:L表示模型的层数。T表示时间帧的数量,取决于输入音频的长度和处理器的设置。F表示每个时间帧的特征向量维度。
| 模型名称 | 层数 (L) | 时间帧数 (T) | 特征维度 (F) | 输出维度 |
|---|---|---|---|---|
| MERT-v1-95M | 13 | 749 | 768 | (13, 749, 768) |
| MERT-v1-330M | 25 | 749 | 1024 | (25, 749, 1024) |
5.4 特征可视化
python
import librosa
import torch
import matplotlib.pyplot as plt
from transformers import Wav2Vec2FeatureExtractor, AutoModel
# 加载模型和处理器
model = AutoModel.from_pretrained("m-a-p/MERT-v1-95M", trust_remote_code=True)
processor = Wav2Vec2FeatureExtractor.from_pretrained("m-a-p/MERT-v1-95M", trust_remote_code=True)
# 设置设备
device = torch.device("mps" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
def process_custom_audio(audio_path):
"""
处理自定义音频文件的主要函数
"""
# 使用librosa加载音频文件,直接指定采样率为24000Hz
audio, original_sr = librosa.load(audio_path, sr=24000, mono=True)
# 转换为PyTorch张量
audio_tensor = torch.from_numpy(audio).float()
# 使用处理器预处理音频
inputs = processor(
audio_tensor,
sampling_rate=24000, # 直接使用24000Hz
return_tensors="pt",
padding=True
)
# 移动到设备
inputs = {k: v.to(device) for k, v in inputs.items()}
# 提取特征
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True)
# 处理所有隐藏状态
all_layer_hidden_states = torch.stack(outputs.hidden_states).squeeze()
return {
"all_layer_states": all_layer_hidden_states
}
def visualize_layers(hidden_states):
"""
可视化指定层的特征
"""
layers_to_visualize = [0, 6, 12] # 要可视化的层
plt.figure(figsize=(15, 5))
for i, layer in enumerate(layers_to_visualize):
# 获取特定层的特征
layer_features = hidden_states[layer].cpu().numpy() # 转换为 NumPy 数组
# 绘制特征图,横坐标为时间帧,纵坐标为特征维度
plt.subplot(1, len(layers_to_visualize), i + 1)
plt.imshow(layer_features.T, aspect='auto', origin='lower', cmap='inferno')
plt.title(f'Layer {layer} Features')
plt.colorbar()
plt.xlabel('Time Frames')
plt.ylabel('Feature Dimension')
plt.tight_layout()
plt.show()
# 使用示例
if __name__ == "__main__":
# 替换为您自己的音频文件路径
custom_audio_path = "test.wav"
try:
features = process_custom_audio(custom_audio_path)
print("特征提取成功!")
print(f"所有层特征形状: {features['all_layer_states'].shape}")
# 可视化特征
visualize_layers(features['all_layer_states'])
except Exception as e:
print(f"处理音频时出错: {e}")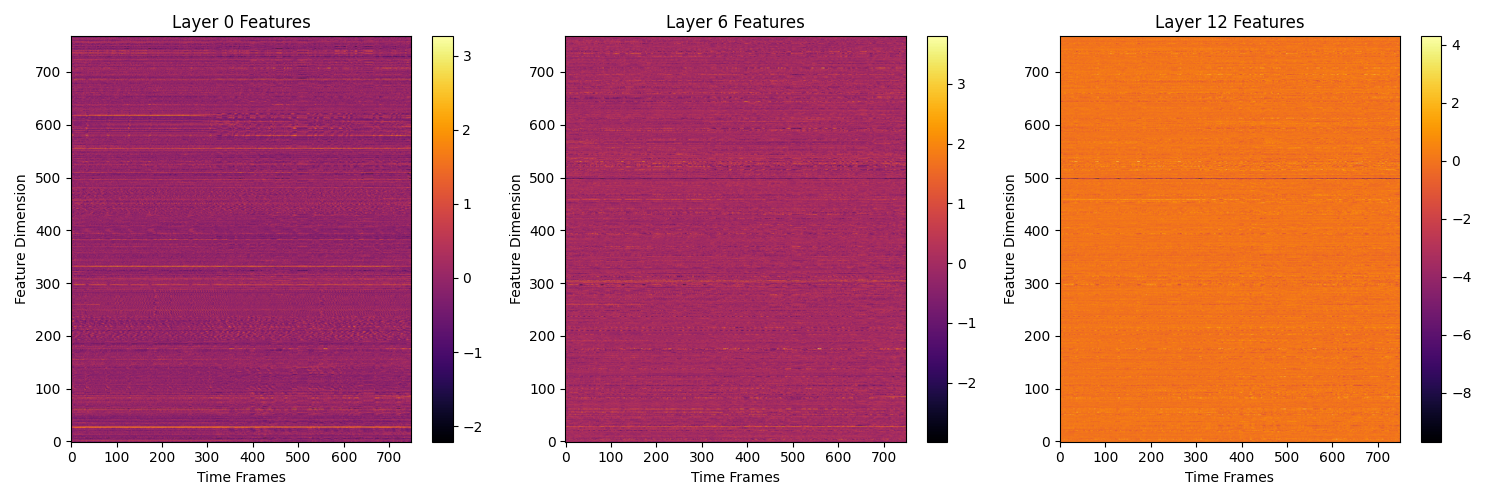
六、 MusicFM 模型
6.1 特征提取
六、MusicFM 模型
6.1 特征提取
MusicFM 是一种基于自监督学习的音乐基础模型,专门设计用于从原始音频中提取多层次音乐表示。其核心特征提取机制基于掩码标记建模(Masked Token Modeling)范式,通过预测被掩码的音频片段来学习丰富的上下文感知表示。
模型采用 Transformer 架构的变体(Conformer 或 BERT-style 编码器)作为骨干网络,通过随机标记化技术将连续音频信号转换为离散标记序列。这一过程无需额外的表示学习阶段,直接从原始音频中学习具有音乐语义的特征表示。
输入预处理流程
- 音频加载:支持 WAV、MP3、FLAC 等多种格式,自动统一为 24kHz 采样率的单声道音频
- 重采样处理:如果原始采样率不等于目标采样率(24kHz),使用 Librosa 进行高质量重采样
- 标准化:对音频振幅进行峰值归一化,确保数值稳定性
- 张量转换:将 NumPy 数组转换为 PyTorch 张量,并添加批处理维度(从 (n_samples,) 到 (1, n_samples))
特征提取过程
python
# 核心提取步骤(基于6.2节代码)
wav, sr = librosa.load("test.wav", sr=24000) # 加载和重采样
wav = torch.from_numpy(wav).float().unsqueeze(0) # 转换为张量并添加批处理维度
logits, hidden_emb = musicfm.get_predictions(wav) # 获取预测结果输出特征结构
模型输出包含两个主要组件:
- Logits:原始预测输出,用于掩码标记重建任务
- 隐藏状态(Hidden States) :13层Transformer编码器的中间表示,每层提供不同抽象级别的特征:
- 底层(1-4层):捕获低层声学特征(音色、瞬态响应)
- 中层(5-8层):编码音乐语法(音符、节奏模式)
- 高层(9-13层):表征高级语义信息(和声进行、音乐结构)
每层隐藏状态的维度为 [1, 250, 1024],分别对应:
- 批次大小:1(单样本处理)
- 时间帧数:250(对应10秒音频,时间分辨率为25Hz)
- 特征维度:1024(每个时间点的特征向量长度)
6.2 特征提取代码
python
HOME_PATH = "/Users/bytedance/Desktop/codes/ASAE" # path where you cloned musicfm
import os
import sys
import librosa
import torch
sys.path.append(HOME_PATH)
from musicfm.model.musicfm_25hz import MusicFM25Hz
# 加载音频文件,采样率设置为 24kHz
wav, sr = librosa.load("test.wav", sr=24000)
# 将音频数据转换为 PyTorch 张量并添加批处理维度
wav = torch.from_numpy(wav).float().unsqueeze(0) # 添加批处理维度
# load MusicFM
musicfm = MusicFM25Hz(
is_flash=False,
stat_path=os.path.join(HOME_PATH, "musicfm", "data", "msd_stats.json"),
model_path=os.path.join(HOME_PATH, "musicfm", "data", "pretrained_msd.pt"),
)
# to MPS (for Apple Silicon)
if torch.backends.mps.is_available():
wav = wav.to("mps") # 将张量移动到 MPS 设备
musicfm = musicfm.to("mps") # 将模型移动到 MPS 设备
else:
print("MPS is not available. Please check your PyTorch installation.")
# get embeddings
musicfm.eval()
logits, hidden_emb = musicfm.get_predictions(wav)
# 打印 hidden_emb 的类型和内容
print(f"Type of hidden_emb: {type(hidden_emb)}") # 打印 hidden_emb 的类型
print(f"Length of hidden_emb: {len(hidden_emb)}") # 打印 hidden_emb 的长度
# 打印每一层的形状
for i, emb in enumerate(hidden_emb):
print(f"Shape of hidden state for layer {i}: {emb.shape}") # 打印每一层的形状
python
Type of hidden_emb: <class 'tuple'>
Length of hidden_emb: 13
Shape of hidden state for layer 0: torch.Size([1, 250, 1024])
Shape of hidden state for layer 1: torch.Size([1, 250, 1024])
Shape of hidden state for layer 2: torch.Size([1, 250, 1024])
Shape of hidden state for layer 3: torch.Size([1, 250, 1024])
Shape of hidden state for layer 4: torch.Size([1, 250, 1024])
Shape of hidden state for layer 5: torch.Size([1, 250, 1024])
Shape of hidden state for layer 6: torch.Size([1, 250, 1024])
Shape of hidden state for layer 7: torch.Size([1, 250, 1024])
Shape of hidden state for layer 8: torch.Size([1, 250, 1024])
Shape of hidden state for layer 9: torch.Size([1, 250, 1024])
Shape of hidden state for layer 10: torch.Size([1, 250, 1024])
Shape of hidden state for layer 11: torch.Size([1, 250, 1024])
Shape of hidden state for layer 12: torch.Size([1, 250, 1024])6.3 输出特征详细分析
-
音频输入:
- 维度 :输入音频信号通常为一维数组,形状为
(n_samples,),其中n_samples是音频样本的总数。 - 示例 :对于 48 kHz 采样率的 10 秒音频,输入维度为
(480000,)。如果音频经过重采样,例如从 48 kHz 重采样到 24 kHz,音频样本数将减少到(240000,)。
- 维度 :输入音频信号通常为一维数组,形状为
-
模型输出:
- MusicFM 模型的输出包括多个隐藏状态,通常以张量的形式返回。
- 维度 :输出的隐藏状态的维度为
(L, T, F),其中:L表示模型的层数,此处为 13T表示时间帧的数量,取决于输入音频的长度和处理器的设置,此处为 250。F表示每个时间帧的特征向量维度,此处为1024。
6.4 特征可视化
python
HOME_PATH = "/Users/bytedance/Desktop/codes/ASAE" # path where you cloned musicfm
import os
import sys
import librosa
import torch
import matplotlib.pyplot as plt
sys.path.append(HOME_PATH)
from musicfm.model.musicfm_25hz import MusicFM25Hz
# 加载音频文件,采样率设置为 24kHz
wav, sr = librosa.load("test.wav", sr=24000)
# 将音频数据转换为 PyTorch 张量并添加批处理维度
wav = torch.from_numpy(wav).float().unsqueeze(0) # 添加批处理维度
# load MusicFM
musicfm = MusicFM25Hz(
is_flash=False,
stat_path=os.path.join(HOME_PATH, "musicfm", "data", "msd_stats.json"),
model_path=os.path.join(HOME_PATH, "musicfm", "data", "pretrained_msd.pt"),
)
# to MPS (for Apple Silicon)
if torch.backends.mps.is_available():
wav = wav.to("mps") # 将张量移动到 MPS 设备
musicfm = musicfm.to("mps") # 将模型移动到 MPS 设备
else:
print("MPS is not available. Please check your PyTorch installation.")
# get embeddings
musicfm.eval()
logits, hidden_emb = musicfm.get_predictions(wav)
# 可视化第 0、6、12 层的特征图
layers_to_visualize = [0, 6, 12]
plt.figure(figsize=(15, 5))
for i, layer in enumerate(layers_to_visualize):
# 获取特定层的特征
layer_features = hidden_emb[layer].cpu().detach().numpy() # 转换为 NumPy 数组
# 绘制特征图,横坐标为时间帧,纵坐标为特征维度
plt.subplot(1, len(layers_to_visualize), i + 1)
plt.imshow(layer_features[0].T, aspect='auto', origin='lower', cmap='inferno') # 转置以适应绘图
plt.title(f'Layer {layer} Features')
plt.colorbar()
plt.xlabel('Time Frames')
plt.ylabel('Feature Dimension')
plt.tight_layout()
plt.show()