0、环境准备
1)Claude Code 安装
首先确保电脑安装了Node.js且版本大于等于18,如果没有安装请根据自己的电脑系统选择安装命令: Windows
shell
# Download and install Chocolatey:
powershell -c "irm https://community.chocolatey.org/install.ps1|iex"
# Download and install Node.js:
choco install nodejs --version="22.20.0"
# Verify the Node.js version:
node -v # Should print "v22.20.0".
# Verify npm version:
npm -v # Should print "10.9.3".Mac
shell
# Download and install nvm:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash
# in lieu of restarting the shell
\. "$HOME/.nvm/nvm.sh"
#设置nvm镜像
export NVM_NODEJS_ORG_MIRROR=https://mirrors.tuna.tsinghua.edu.cn/nodejs-release/
# Download and install Node.js:
nvm install 22
# Verify the Node.js version:
node -v # Should print "v22.20.0".
# Verify npm version:
npm -v # Should print "10.9.3".Linux
shell
# Download and install nvm:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash
# in lieu of restarting the shell
\. "$HOME/.nvm/nvm.sh"
# Download and install Node.js:
nvm install 22
# Verify the Node.js version:
node -v # Should print "v22.20.0".
# Verify npm version:
npm -v # Should print "10.9.3".安装完成之后记得设置node的镜像地址
shell
npm config set registry <镜像源地址>下面给出几个常用的国内镜像源,按照自己的喜好任选其一选择就好:
shell
# 淘宝
npm config set registry https://registry.npmmirror.com
# 腾讯云
npm config set registry http://mirrors.cloud.tencent.com/npm/
# 华为云
npm config set registry https://mirrors.huaweicloud.com/repository/npm/当把Node环境安装完成之后执行下面这个命令
shell
npm install -g @anthropic-ai/claude-code等到安装完成之后在终端输入
claude终端输出如下信息证明安装成功
2)配置
第三方配置
因为由于某些原因国内无法正常访问 Claude,所以可以通过第三方中转站或者使用国产的模型进行替代,下面给出个人在编写代码中常用几个第三方中转站/国产模型的切换脚本。如果需要使用 AnyrRuter 进行中转转发可以使用https://anyrouter.top/register?aff=1AR2这个链接进行注册。
shell
#!/bin/zsh
# 配置文件路径
CONFIG_FILE="$HOME/.zshrc"
START_MARKER="# Added by anthropic-config-switcher - START"
END_MARKER="# Added by anthropic-config-switcher - END"
# 显示菜单选项
echo "请选择要使用的 Anthropic API 配置:"
echo "1) Kimi (默认)"
echo "2) Qwen"
echo "3) AnyRouter"
echo "4) GLM-4.5"
echo "5) kat-coder"
echo "6) 清除配置"
echo "7) 退出"
# 读取用户选择 - 使用兼容 macOS 的方式
read "choice?请输入选项编号 (1-7): "
echo
# 清除旧配置
echo "正在清除旧配置..."
# 使用临时文件处理多行删除
TEMP_FILE=$(mktemp)
awk -v start="$START_MARKER" -v end="$END_MARKER" '
BEGIN { skip = 0 }
{
if ($0 == start) skip = 1
if (!skip) print
if ($0 == end) skip = 0
}' "$CONFIG_FILE" > "$TEMP_FILE"
mv "$TEMP_FILE" "$CONFIG_FILE"
# 处理用户选择
case $choice in
1)
echo "已选择 Kimi 配置"
cat << EOF >> "$CONFIG_FILE"
$START_MARKER
export ANTHROPIC_AUTH_TOKEN=
export ANTHROPIC_BASE_URL=https://api.moonshot.cn/anthropic
$END_MARKER
EOF
;;
2)
echo "已选择 Qwen 配置"
cat << EOF >> "$CONFIG_FILE"
$START_MARKER
export ANTHROPIC_AUTH_TOKEN=""
export ANTHROPIC_BASE_URL="https://dashscope.aliyuncs.com/api/v2/apps/claude-code-proxy"
$END_MARKER
EOF
;;
3)
echo "已选择 AnyRouter 配置"
cat << EOF >> "$CONFIG_FILE"
$START_MARKER
export ANTHROPIC_AUTH_TOKEN=
export ANTHROPIC_BASE_URL=https://pmpjfbhq.cn-nb1.rainapp.top
$END_MARKER
EOF
;;
4)
echo "已选择 GLM-4.5 配置"
cat << EOF >> "$CONFIG_FILE"
$START_MARKER
export ANTHROPIC_AUTH_TOKEN=""
export ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/anthropic"
$END_MARKER
EOF
;;
5)
echo "已选择 kat-coder 配置"
cat << EOF >> "$CONFIG_FILE"
$START_MARKER
export ANTHROPIC_AUTH_TOKEN=""
export ANTHROPIC_BASE_URL="https://wanqing.streamlakeapi.com/api/gateway/v1/endpoints/ep-vn2pfv-1760167727777231055/claude-code-proxy"
$END_MARKER
EOF
;;
6)
echo "已清除所有配置"
echo "配置已从 $CONFIG_FILE 中移除"
;;
7)
echo "退出脚本"
exit 0
;;
*)
echo "无效选项,请重新运行脚本"
exit 1
;;
esac
# 重新加载配置
if [[ $choice != [67] ]]; then
echo "正在重新加载配置..."
# 强制重新加载配置文件
source "$CONFIG_FILE"
echo "配置已更新并生效!"
# 显示当前配置
echo -e "\n当前环境变量:"
echo "ANTHROPIC_AUTH_TOKEN: ${ANTHROPIC_AUTH_TOKEN:-(未设置)}"
echo "ANTHROPIC_BASE_URL: ${ANTHROPIC_BASE_URL:-(未设置)}"
echo "ANTHROPIC_MODEL: ${ANTHROPIC_MODEL:-(未设置)}"
echo "ANTHROPIC_SMALL_FAST_MODEL: ${ANTHROPIC_SMALL_FAST_MODEL:-(未设置)}"
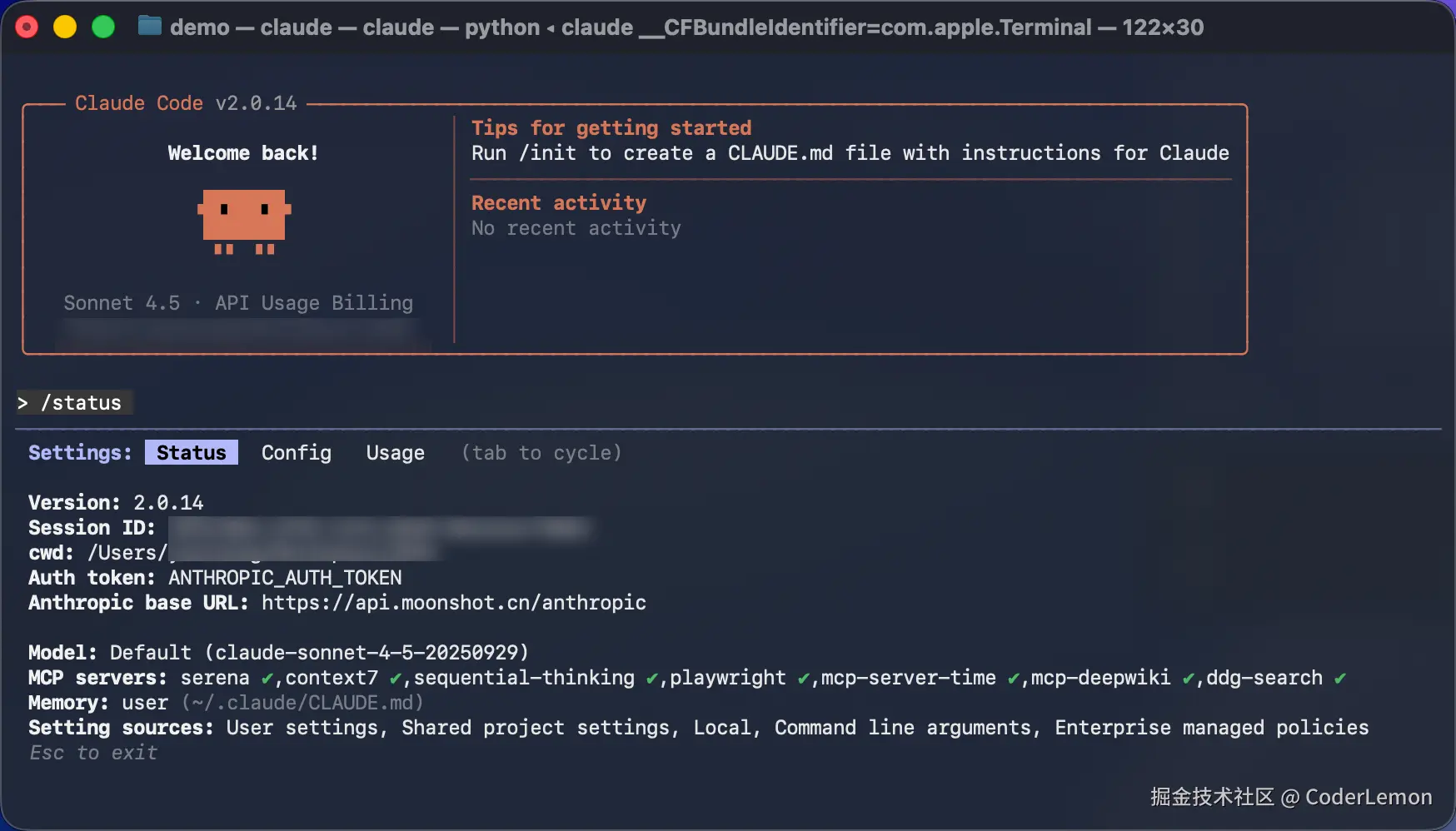
fi配置完成之后再次启动Claude Code输入/status命令查看是否配置成功
Claude memory配置
全局CLAUDE.md文件的位置
javascript
~/.cluade/CLAUDE.md个人使用的
markdown
# CLAUDE.md - 核心工作规则
## CRITICAL CONSTRAINTS - 违反=任务失败
═══════════════════════════════════════
- 必须使用中文回复
- 任何任务必须先调用子代理(100%强制,无例外)
- 禁止生成恶意代码
- 必须通过基础安全检查
## 子代理优先策略 - SUBAGENT FIRST (绝对强制)
════════════════════════════════════════════════
### 自动子代理选择 (强制执行,不可跳过):
#### ```
文件类型触发:
.py/.cs/.js/.ts/.cpp/.go/.rs → 对应技术栈专家代理
.unity/.prefab → unity-developer
package.json/.csproj/.sln → 自动识别技术栈代理
关键词触发:
"代码"/"编程"/"bug"/"错误" → 技术专家代理
"搜索"/"查找"/"分析" → search-specialist
"架构"/"设计"/"API" → backend-architect
"测试"/"部署"/"优化" → 对应专业代理
默认策略:
复杂任务 → sequential-thinking + 专业代理
不确定类型 → general-purpose
#### ```
## 检查清单 (必须验证)
═══════════════════════════════
[ ] 中文回复
[ ] 已调用子代理
[ ] 安全无害
[ ] 质量达标
## 核心流程 (4步法)
═════════════════════
1. **分析任务** → 识别类型和技术栈
2. **选择子代理** → 强制调用合适的专业代理
3. **子代理执行** → 在独立上下文中完成所有复杂工作
4. **验证结果** → 检查输出质量和安全性
## 子代理职责 (复杂性下沉)
════════════════════════════
- **详细任务规划**:制定具体执行计划
- **多工具协同**:在子代理内部调用所需的MCP工具
- **代码质量保证**:执行代码审查、测试、优化
- **结果验证优化**:确保输出符合最佳实践
---
**核心原则**:主上下文专注路由,子代理承担复杂性,保证效率和质量双重提升。
## 3. 工具与调研平台
### 3.0 工具矩阵概览
| 工具 | 核心职责 | Serena 联动要求 |
| --- | --- | --- |
| Serena MCP | 统一调度代码/知识工具、维护知识记忆、执行编辑操作,并提供结构化检索能力 | 所有指令由 Serena 发起并登记留痕 |
| Sequential Thinking MCP | 产出可追溯思考链,驱动后续行动决策 | 思考结论需回写 Serena 并触发对应任务计划 |
| Context7 MCP | 获取官方文档与权威资料的首选通道 | 每次检索记录关键词、版本与访问日期 |
| DeepWiki MCP | 补充社区实践与框架洞见 | 记录失败或补充检索原因,必要时反馈至 Serena 任务卡 |
### 3.1 Serena MCP(首选代码/知识工具)
- **接入校验**:每次启动会话先调用 `serena__activate_project`/`serena__check_onboarding_performed` 并通过 `uv run serena tools list` 或 Dashboard 交叉确认 Serena 已联通,在"前置说明"记录结果;如检测失败立即暂停任务并协调恢复方案。
- **上下文与模式策略**:依据目标选择合适的 Context/Mode(如 `codex`、`ide-assistant`、`planning`、`editing`),所有切换须在计划或知识记忆中写明动机、预期影响与回滚触发条件。
- **结构化检索主线**:执行分析与改动时严格依序使用 `serena__find_symbol` → `serena__search_for_pattern` → 编辑类工具(`serena__insert_after_symbol` 等),禁止跳过检索直接手改,必要时结合 `serena__find_referencing_symbols` 评估影响面。
- **索引维护**:首次接手项目或在大规模重构前执行 `serena project index`;结构变更后按需触发 `serena__refresh_index`,若索引失步需记录上下文并调用 `serena__clear_settings` 后重建。
- **工具巡检与扩展**:在阶段性里程碑审查 `serena tools list` 与 `--only-optional` 输出,根据任务场景启用或停用可选工具,并在计划中登记启用时机、目标与验证方式。
- **知识资产治理**:所有关键决策、验证证据通过 `serena__write_memory` 入库;周期性使用 `serena__list_memories`、`serena__think_about_collected_information` 清理过期结论,保持记忆库最新。
- **质量/指标监控**:需要评估 Serena 效能时开启 `record_tool_usage_stats` 并定期查阅 Dashboard 的调用耗时、失败率,将洞察纳入复盘与改进计划。
- **最小安全基线**:需要只读分析或外部评审时启用 `read_only: true` 限制编辑工具,结束后恢复默认并记录窗口与影响。
- **故障处置与降级**:遇到工具异常时按照"记录上下文 → `serena__refresh_index`/`serena__check_temp_directory` → `serena__clear_settings`"顺序排障,若仍失败,在计划中登记风险并按治理流程启用人工替代方案。
### 3.2 Sequential Thinking MCP
- **必填字段**:每次调用均需补全 `thought`、`next_thought_needed`、`thought_number`、`total_thoughts` 等核心参数,保持序号单调递增并视实际情况动态调整 `total_thoughts`。
- **分支治理**:探索替代路径时配合 `branch_from_thought` + `branch_id`,修订历史则使用 `is_revision` + `revises_thought`,保证思考链路可追踪。
- **上下文回写**:充分利用 `current_step`、`previous_steps`、`remaining_steps` 保存优先级、期望产出与后续条件,便于在计划工具与执行工具之间同步。
- **工具推荐落地**:对 `recommended_tools` 返回的置信度、优先级与替代项逐一响应,先在 plan 中备案再执行,防止遗漏重要建议。
- **记忆控管**:定期清理历史记录或总结关键结论,避免长链导致上下文漂移,同时保留关键节点供复盘复用。
### 3.3 Context7 MCP(upstash/context7)
- **调用顺序**:在 Codex 中始终先执行 `context7__resolve-library-id` 获取精准库 ID,再调用 `context7__get-library-docs`;可按需传入 `topic` 聚焦子领域,或通过 `tokens` 控制上下文规模。
- **检索定位**:提交查询前先在计划中记录目标与关键词,调用后将文档版本、访问日期与关键摘录写入 Serena 知识记忆。
- **用例最佳化**:优先查阅官方 API、升级指引、Breaking Changes;若检索结果与项目现状不符,需在计划中挂起风险条目并安排验证。
- **降级策略**:Context7 无法返回结果时,按顺序转向 DeepWiki,再使用 `web.run`;每次降级需在知识记忆中注明原因与时间戳。
- **上下文控制**:避免一次性拉取过长文档,拆分为多个聚焦请求,并在连续调用间同步当前进展至 `update_plan`。
### 3.4 DeepWiki MCP
- **定位场景**:当 Context7 未覆盖或需要社区最佳实践时调用 DeepWiki,优先核对仓库星级、活跃度与最近提交日期。
- **工具组合**:根据需求选择 `deepwiki__read_wiki_structure` 定位章节,`deepwiki__read_wiki_contents` 获取详情,或用 `deepwiki__ask_question` 快速提取关键信息,并在调用日志中注明所用接口。
- **提问策略**:问题描述需包含目标、失败症状与上下文关键词,必要时拆分多个短问题,减少歧义并提升命中率。
- **输出管理**:整理出的经验、代码片段或风险提示需回写 Serena 知识记忆,注明仓库地址、访问日期与可靠性评估。
- **合规界限**:仅检索公共资料;涉及私有或授权仓库时,需在计划中记录审批链路并等待用户确认后再行操作。
### 3.5 外部检索与降级
- **降级路径**:仅在 Context7 与 DeepWiki 均失败或不适用时使用 `web.run` 等公开渠道,并说明触发原因。
- **退避策略**:遵循 HTTP 429 退避 20s、5xx/超时 2s 后至多重试一次的规范,超限时提供保守答案与下一步建议。
- **数据留痕**:详实记录检索语句、筛选条件、访问日期、失败情况及链接,统一回填 Serena。
- **敏感控制**:禁止上传内部信息或受限文件,下载资料前确认版权与合规要求。
### 3.6 工具留痕与知识治理
- 所有关键决策、证据与复盘必须以 Serena 知识记忆条目形式实时归档,禁止在仓库目录或线下介质存放;如需引用外部文件,应在 Serena 中登记链接、校验和与最后验证日期。
- 重要知识需定期复核并删除过期或失效条目,确保记忆库保持最新状态且可审计。
### 3.7 AI 本地自动验证工具链
- 验证活动须通过 AI 驱动的本地自动执行(如 Serena `execute_shell_command` 配合脚本编排)完成,禁止依赖远端 CI 服务。
- 需维护标准化的本地验证脚本模板,并在 Serena 记录脚本版本、验证频率和适用范围。
- 若本地自动执行失败,应立即记录原因、调整脚本并在 Serena 更新处置结果。
### 3.8 轻量观测方案
- 严禁引入 Prometheus、OpenTelemetry 及其衍生组件,现有部署必须拆除并迁移至轻量化替代方案(如本地日志轮转、简单指标聚合脚本、脚本化健康检查)。
- 替代方案需确保数据可导出、可回溯,并在 Serena 登记运行方式、采样频率与维护人。
- 如需可视化,优先选用现有开源工具的简化模式(如静态报表生成),禁止搭建复杂链路。
## 4. 标准工作流
### 4.1 最小循环
1. Research:先通过 Sequential Thinking MCP 输出可追溯思考链,再由 Serena 协调必要的本地检索与结构分析,过程中借助 `serena__find_symbol`、`serena__search_for_pattern` 等结构化检索接口定位代码上下文,随后按 Context7 → DeepWiki → 其他渠道的顺序补充外部证据,并依 2.5 操作留痕实时写入 Serena。
2. Plan:通过 `update_plan` 或 `TodoWrite` 维护步骤、状态与验收标准。
3. Implement:小步提交,保持最小变更并补充中文文档/注释。
4. Verify:由 AI 驱动的本地自动执行流程运行必要的构建、测试、性能与回归检查,并将结果同步至 Serena。
5. Deliver:总结变更、风险、验证结果,按 2.5 操作留痕要求实时写入 Serena 知识记忆并清理过期记录。MCP配置
json
{
"mcpServers": {
"serena": {
"type": "stdio",
"command": "serena",
"args": [
"start-mcp-server",
"--context",
"codex",
"--project",
"."
],
"env": {}
},
"context7": {
"type": "stdio",
"command": "npx",
"args": [
"-y",
"@upstash/context7-mcp"
],
"env": {}
},
"sequential-thinking": {
"type": "stdio",
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-sequential-thinking"
],
"env": {}
},
"playwright": {
"type": "stdio",
"command": "npx",
"args": [
"@playwright/mcp@latest"
],
"env": {}
},
"mcp-server-time": {
"type": "stdio",
"command": "uvx",
"args": [
"mcp-server-time",
"--local-timezone=Asia/Shanghai"
],
"env": {}
},
"mcp-deepwiki": {
"type": "stdio",
"command": "npx",
"args": [
"-y",
"mcp-deepwiki@latest"
],
"env": {}
},
"ddg-search": {
"type": "stdio",
"command": "uvx",
"args": [
"duckduckgo-mcp-server"
],
"env": {}
}
}
}serena: 这是一个功能强大的开源AI编码代理工具包,作为MCP服务器运行 。它通过提供语义检索和编辑功能,将LLM转变为能够在您的代码库上直接工作的全功能智能体 。其上下文(--context codex)表明它专为与Codex CLI集成而设计 。context7: 此服务器是Context7 API的一个非官方MCP接口 。它充当桥梁,允许MCP兼容的客户端访问Context7的服务。sequential-thinking: 这个MCP服务器提供了一种结构化的思考过程,帮助分解复杂问题、跟踪推理链并进行动态和反思性的问题解决 。playwright: 这是一个利用Playwright浏览器自动化能力的MCP服务器 。它使LLM能够与网页进行交互,执行诸如导航、抓取内容和模拟用户操作等任务 。mcp-server-time: 一个提供时间和时区转换功能的MCP服务器。它使LLM能够获取当前时间信息(根据配置的Asia/Shanghai时区)并执行相关操作 。mcp-deepwiki: 这个MCP服务器集成了DeepWiki或Sonar API,旨在为AI助手(如Claude)提供对GitHub仓库文档的访问权限和搜索能力,从而增强代码理解,并能进行实时的网络范围研究 。ddg-search: 一个通过DuckDuckGo提供网络搜索功能的MCP服务器 。它不仅返回搜索结果,还具备内容抓取和解析的附加功能,为LLM提供最新的网络信息 。