文章目录
- 每日一句正能量
- [第6章 Kafka分布式发布订阅消息系统](#第6章 Kafka分布式发布订阅消息系统)
- 章节概要
- [6.1 Kafka 概述](#6.1 Kafka 概述)
-
- [6.1.1 消息传递模式简介](#6.1.1 消息传递模式简介)
- [6.1.2 Kafka 简介](#6.1.2 Kafka 简介)

每日一句正能量
刻意去找的东西,往往是找不到的。天下万物的来和去,都有他的时间。
第6章 Kafka分布式发布订阅消息系统
章节概要
Kafka是一个高吞吐量的分布式发布订阅消息系统,它在实时计算系统中有着非常强大的功能。通常情况下,我们使用Kafka构建系统或应用程序之间的数据管道,用来转换或响应实时数据,使数据能够及时的进行业务计算,得出相应结果。本章将针对Kafka工作原理、Kafka集群部署以及Kafka的基本操作进行详细讲解。
6.1 Kafka 概述
6.1.1 消息传递模式简介
在大数据系统中,关于海量数据之间的传输方法是面临的首要困难,为了解决大数据集的传输困难,就必须要构建一个消息系统。
一个消息系统负责将数据从一个应用程序传递到另外一个应用程序中,应用程序只关注数据,无需关注数据在多个应用之间是如何传递的,分布式消息传递基于可靠的消息队列,在客户端应用和消息系统之间异步传递消息。消息系统有两种主要的消息传递模式,分别是点对点消息传递模式和发布订阅消息传递模式。
目前市面上有许多消息系统,例如Kafka、 RabbitMQ、 ActiveMQ等 ,Kafka是专门为分布式高吞吐星系统而设计开发的,它非常适合在海星数据集的应用程序中进行传递消息。消息传递一共有两种模式, 分别是点对点消息传递模式和发布订阅消息传递模式。接下来,将针对消息传递的两种模式进行详细讲解。
- 点对点消息传递模式
点对点消息传递模式(Point to point, P2P) 通常是一个基于拉取或者轮询的消息传递模式,其消息传递结构如图6-1所示。

图6-1点对点消息传递模式结构
在图6-1点对点消息传递模式结构中,消息是通过一个虚拟通道进行传输的,生产者发送一条数据,消息将持久化到一个队列中,此时将有一个或多个消费者会消费队列中数据,但是一条消息只能被消费一次,且消费后的消息会从消息队列中删除,因此,即使有多个消费者同时消费数据,数据都可以被有序处理。
- 发布订阅消息传递模式
发布订阅消息传递模式(Publish/Subscribe) 是一个基于推送的消息传送模式,其消息传递结构如图6-2所示。
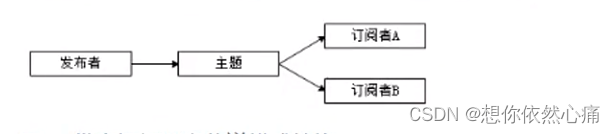
图6-2发布订阅消息传递模式结构
从图6-2可以看出,在发布订阅模式中,发布者用于发布消息,订阅者用于订阅消息, 发布订阅模式可以有多种不同的订阅者,发布者发布的消息会被持久化到一个主题中,这与点对点模式不同的是,订阅者可订阅一个或多个主题,订阅者可读取该主题中所有数据,同一条数据可被多个订阅者消费,数据被消费后也不会立即删除。
6.1.2 Kafka 简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,它由Scala和Java语言编写,是一个基于Zookeeper系统的分布式发布订阅消息系统,该项目的设计初衷是为实时数据提供-个统一、 高通量、 低等待的消息传递平台。
Apache Kafka作为分布式消息系统,它可以处理大量的数据,并能够将消息从一个端点传递到另外一个端点。
Kafka系统在大数据领域的应用中非常普遍,它能够在离线和实时两种大数据计算架构中处理数据,这得益于Kafka的众多优点,其优点具体如下。
- 解耦
Kafka具备消息系统的优点,只要生产者和消费者数据两端遵循接口约束,就可以自行扩展或修改数据处理的业务过程。 - 高吞吐量、低延迟
即使在非常廉价的机器上, Kafka也能做到每秒处理几十万条的消息,而它的延迟最低只
有几毫秒。 - 持久性
Kafka可以将消息直接持久化在普通磁盘上,且读写磁盘时的性能优异。 - 扩展性
Kafka集群支持热打展, Kafka集群启动运行后, 用户可以直接向集群添加新的Kafka服务。 - 容错性
Kafka会将数据备份到多台服务器节点中,即使Kafka集群中的某一台节点宕机,也不会影响整个系统的功能。 - 支持多种客户端语言
Kafka支持Java、 .NET、 PHP、 Python等多种语言。
在大数据计算系统的开发场景中,若需要对接外部数据源时,就可以使用Kafka系统,例如我们熟悉的日志收集系统和消息系统,Kafka读取日志系统中的数据,每得到一条数据,就可以及时的处理一条数据, 这就是常见的流式计算框架。
Kafka使用消费组(Consumer Group)的概念统一了点对点消息传递模式和发布订阅消息传递模式,当Kafka使用点对点模式时,它可以将处理工作任务平均分配给消费组中的消费者成员;当使用发布订阅模式时,它可以将消息广播给多个消费组。Kafka采用多个消费组结合多个消费者,既可以扩展消息处理的能力,也允许消息被多个消费组订阅。
转载自:https://blog.csdn.net/u014727709/article/details/144043043
欢迎 👍点赞✍评论⭐收藏,欢迎指正