什么是分布式
谈到分布式时首先要提到单机架构(应用程序+数据库),这样的两个服务器是部署在同一台主机上的,但随着用户量和访问量的增加,此时一台主机已经处理不了这样的数据量,此时就要将应用程序和数据库服务器分离到不同的主机上,所以当引入多台主机时,此时的系统就是分布式系统了。
但随着用户的进一步增加,就意味着需要应用程序可能会将CPU内存等资源耗尽,就需要对应用程序和数据库这样的结构进行修改,引用负载均衡,就是将应用服务器变为集群,由负载均衡来进行任务的发配,来提高处理的效率,引入更多应用服务器就表示有更多的CPU内存等资源。同时还有一个好处就是当集群中的服务器出现宕机的情况,此时集群中的其他服务器仍然可以进行承担服务,提高了系统的可用性。
应用服务器增加,但数据库服务器还是要承担一切,为了降低数据库服务器的压力就可以引入读写分离,将数据库分为主从,主服务器主要负责写功能,从服务器负责读功能。
为了解决数据库访问慢的问题,将数据库数据分为冷热数据,将数据库中经常被访问的热点数据放入缓存中(redis就是处于这样的位置),而相对"冷"的数据就放在硬盘中(仍然存放的是全量数据)。但是这里可能存在缓存服务器和硬盘服务器数据不能同步的问题。
应用服务器会出现内存CPU等资源耗尽问题,数据库服务器就也会出现这样的问题,当一个表或库中的数据量太大,此时就需要进行分库分表来解决。
总而言之,分布式其实就是一台主机的资源不够用,需要引入多台主机来进行分担任务,同时需要根据不同的情况分配不同主机的任务。
redis的特点
上面了解到redis其实就是一个在内存中存储数据的中间件。
在内存中存储:redis最核心的一个特点,MySQL是使用"表"这样的结构存储数据,redis则是使用"键值对"这样结构的非关系型数据库。
可编程的:redis可以通过一些简单的交互式命令进行操作,也可以通过脚本来进行操作。
可拓展的:redis可以除redis提供功能外,还可以通过C/C++,Rust等编程语言编写拓展(动态链接库,windows上dll可以供exe调用)。
持久化的:redis是把数据存储在内存中的,但内存中的数据是易失的,所以redis会把数据在硬盘上中备份一份,如果出现系统重启或进程退出的情况,下次就会重新去硬盘上加载数据
可以支持集群:一个redis支持的存储空间是有限的,所以就可以引入多个主机,在每个主机上安装redis节点。
高可用:redis支持主从这样的结构,主服务器挂了,从服务器就可以直接顶替,从服务器其实就是主服务器的备份。
访问速度快:
1.数据存放在内存中
2.redis中的核心功能都是比较简单逻辑,核心功能都是比较简单的数据结构
3.redis使用的是单线程模型,可以减少线程之间的竞争开销(多线程高效率的前提是CPU密集执行任务,使用多个线程可以充分利用cpu资源,但是redis进行得是简单的操作内存中的操作系统,引入多线程可能会触发加锁,降低效率)
redis的使用场景
提到数据存储会想到大的空间去存储,但是不妨一些场景需要比较快的访问速度,redis就可以作为数据库来进行存储数据.
redis可以作为缓存,存储比较"热"的数据.
redis可以作为一个消息队列.
redis存全量数据的场景是redis作为主要的数据库,每条数据都比较重要,作为缓存的场景是将redis作为一个辅助的角色.
redis的限制
redis是在内存中存储,所以不能够大规模存储数据.
在一些场景下,redis会更慢,例如是直接使用内存中的hashmap还是使用redis,这里如果使用redis时,会先通过网络操作内存,但是hashmap是直接操作内存.
好处是当重启服务时,存储的数据可以重新加载,而hashmap中的数据就直接没了.
redis客户端的介绍
redis和MySQL一样也是客户端-服务器结构的程序.
在Linux系统下下载redis,下载后需要使用rides-cli来打开redis的命令行客户端.

当然redis不止一个客户端,还有图形化客户端和基于redis提供的api自行开发的客户端(类似于MySQL中的JDBC).
redis的基本命令
redis中两个最基本的命令是 get 和 set
前面谈到redis是一个使用键值对存储数据的非关系型数据库,所以它的存储方式是类时于哈希表的,redis中使用key-value的形式进行存储,使用set存储键值对,使用get获取value.
使用set

使用get,当输入的key不存在时会返回nil

此外,redis是不区分大小写,并且字符串不需要使用引号,当然使用也是可以的.

redis的常见全局命令
一个易误解的点:redis可以支持多种数据结构,这里的数据结构不是指redis使用的"键值对",而是key是字符串,value则可以是各种数据结构.全局命令就是在任何一个数据结构中都可以使用的.
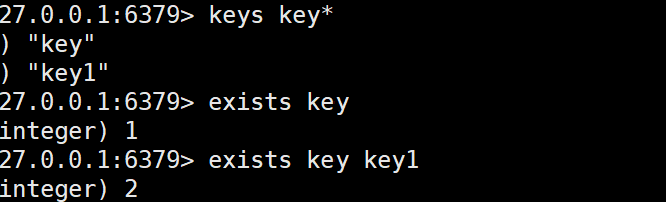
1)keys pattarn : 查询当前服务器上所有匹配的key,可以使用一些通配符来描述key的"模样",来找到key.
来自官方文档:

?表示只能有一个任意字符
*表示有0或任意个任意字符
ae表示只能匹配括号内中的字符
\^e表示除以外所有字符
a-b表示a~b所有字符
我们可以使用keys*查询当前redis中的所有key,但是这是十分危险的操作,很可能导致服务器宕机.
2)exists:表示查找key的个数,针对多个key返回个数.比如查找三个key,一个不存在两个存在,此时返回2.

简单的来说,exists表示的是当前的key存在的个数,这样的操作并不是害怕key重复,而为了在寻找多个key的时候更加方便.
这样的查找时间复杂度是O(1),而查找多个key时,此时就会时间复杂度就是O(n)这里的n等于查找key的个数.
上面的一次查找两个key和分两次查找两个key的写法有什么区别呢,redis是一个客户端-服务器形式的程序,当进行一次查询时,客户端和服务器实际上会通过网络进行通信,而分两次进行查找就会产生多次的网络通信,这样就会相较于直接操作内存会更快.
3)del
del是删除指定的key,这里的del是相比于mysql中的delete较安全的操作,这是因为redis是一般是作为一个缓存数据库来使用的.这里删除的可能只是一部分热点数据,而真正的全量数据是存储在MySQL中的.
4)expire
expire是给key设定过期时间,超过这个时间就会删除这个key
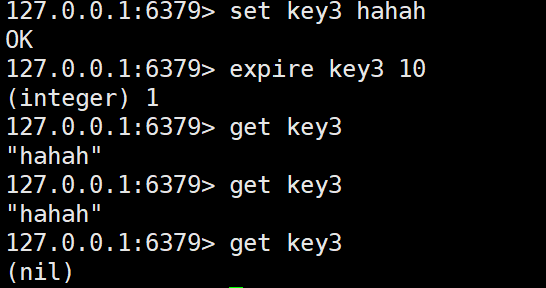
expire后面表示的是秒,还有一个pexpire使用的是毫秒.
5)ttl
表示还剩多久过期时间.
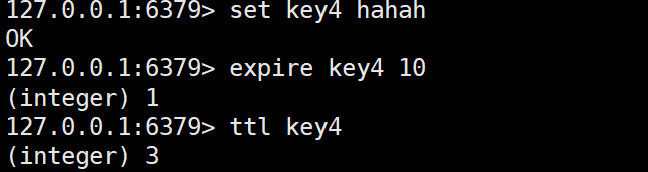
6)type
查看当前key的value的数据类型(数据结构类型)
不同的数据结构有不同的插入方法.
redis的过期策略(重)
redis是如何判断一个key是否过期,难道是遍历一遍库中的所有key?这样的操作慢且没效率.
这里使用了两种方式:惰性清理和定期清理
惰性清理表示的是如果当前key已经过期,此时还是放在库中.当需要这个key的时候再进行判断一下可以是否过期.
定期清理表示的是每次只抽取一部分,进行验证是否过期,抽取一部分是为了检查的速度足够快.这里规定时间是为了防止扫描key时间过长耽误正常的线程(redis是单线程模型).
但上面的这些操作可能并不能清理完全,redis还有内存清理机制.
redis的数据类型和编码方式
redis中的主要的数据类型有hash(哈希表),string(字符串),set(集合),zset(有序集合),list(列表)等.
但是这些数据类型的底层编码其实并非按照类型的名字进行的.例如hash底层并非按照哈希表严格进行的,而是在保证时间复杂度的前提下又优化增加了一些其他的编码方式.
hash : hashTable,ziplist
hashTable是redis中的哈希表的实现,和Java标准库中的hashTable不是同一物.
ziplist:当哈希表比较小时,redis就会将它压缩以减小占用内存.
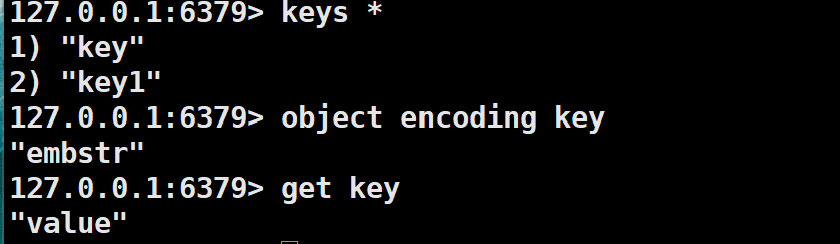
string : raw,int,embstr
raw是标准的字符串实现,Java中表示的是用byte数组实现的字符串.
int数据是数字的时候,此时就用int.
embstr表示当字符串比较短的时候使用.
list : linkedlist(链表),ziplist
set:hashTable,intset
set中都是整数就会优化成intset
zset:skipset,zipset
skipset(跳表)表示的是一个节点中有多个指针域,可以通过指针域进行查询,时间复杂度是O(logn).
我们可以通过object encoding key命令查看具体的key的具体的类型.
redis的单线程模型
redis使用的是单线程模型,但并不是说redis服务器中只有一个线程,其实redis有其他线程,但是都是用于网络IO,通过网卡读写到数据,然后将任务交给主线程,这个单线程指的是处理任务的线程只有一个.那么如果有多个客户端同时访问一个服务器,那么此时服务器就会采用串行执行的方法来执行任务,也就是会一个个执行任务.
redis为什么访问速度快?
1)redis相比于MySQL等访问硬盘的数据库,是直接访问内存的.
2)redis的核心任务是比较简单的,相较于mysql中的各种查询条件和约束
3)是单线程模型,因为redis的任务比较简单,任务处理快,所以使用单线程模型可以减少线程间的竞争,这样自然就减少了CPU开销.
4)在进行网络IO时,redis采用了epoll这样的IO多路复用机制(一个线程可以管理多个socket.当一个客户端与服务器建立连接时,服务器就需要分配一个socket给客户端,但是并不是所有socket都活跃,所以就让一个线程管理多个socket减少创建线程消耗的资源).