
笔记整理:胡相锦,浙江大学硕士,研究方向为知识图谱与多模态学习
论文链接:https://aclanthology.org/2024.acl-long.132.pdf
发表会议:ACL 2024
1. 动机
基于知识的视觉问答旨在借助外部知识(如知识图谱)来回答与图像相关的问题。现有的方法已经尝试将大语言模型(LLMs)作为隐式知识引入,然而这些方法仍然面临一些挑战:其一:LLMs 存在幻觉,其二:多源知识(如图像、知识图谱与 LLMs)之间难以在复杂场景中实现对齐。
为了解决这些问题,作者提出了一种新颖的基于大语言模型的模态感知集成方法(MAIL),它可以运用多模态知识进行图像理解和知识推理:
1)提出了一种两阶段的提示策略,引导 LLMs 将图像表达为包含详细视觉信息的场景图。
2)通过将提及实体和外部知识链接,构建了一个耦合概念图。
3)设计了一种定制的伪孪生图中介融合机制(Pseudo-siamese Graph Medium Fusion)以实现充分的多模态融合。该方法利用两个图中共享的提及实体作为中介,实现紧密的跨模态信息交互,同时通过将融合限制在中介部分,最大限度地保留模态内部的深层学习能力。
2.方法
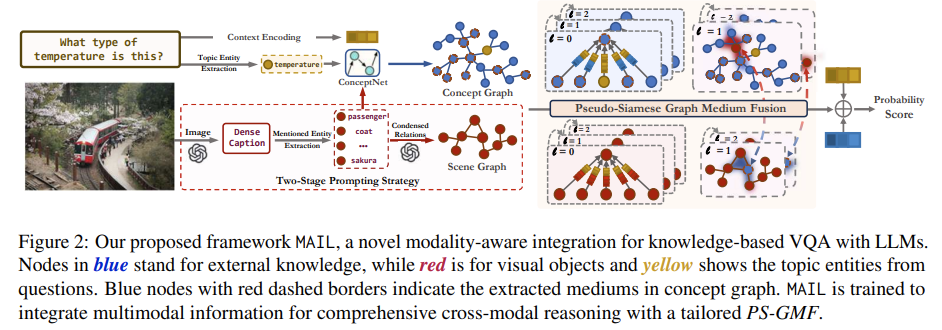
该方法首先利用大语言模型中的知识来进行耦合图的构建,随后引入伪孪生图中介融合机制,通过引入两个训练目标联合优化模型以实现准确预测。
2.1 场景图构建
1)密集图像字幕生成(Dense Caption Generation)
设计一个硬提示(hard prompt),使用视觉大语言模型
详尽地描绘图像中所有物体的外观以及它们之间的空间关系。所生成的描述如下:
将图像中识别出的视觉实体视为关键提及实体(mentioned entities),记作:
2)提示增强的三元组抽取(Prompt-enhanced Triple Extraction)
针对提取出的提及实体,采用 LLMs 提取三元组。定义 12 种关系:
并配合模板提示 LLMs 构建场景图:
2.2 概念图构建(Concept Graph Construction)
使用外部常识知识图谱构建概念图:
将每个提及实体
以及问题中的主题实体(topic entity)与 ConceptNet 中的知识进行链接,构建出的图记作
。它包含大量与
有关的文本描述、属性、类别与特性等知识,这些内容在图像中不存在,能为问题提供更丰富的知识推理背景。
2.3 伪孪生图中介融合(Pseudo-siamese Graph Medium Fusion)
作者将伪孪生网络(Pseudo-siamese Network, PSN)拓展到图结构,构建伪孪生图神经网络(Pseudo-siamese GNN, PSG)以学习耦合图的模态内信息。然而 PSG 本身并不能实现跨模态融合,因此进一步设计了一个图中介融合(Graph Medium Fusion, GMF)机制。
1)伪孪生图神经网络(PSG)
PSG 由两个结构相同但参数独立的图神经网络组成,它们共享相同的架构(如注意力机制、聚合函数、组合函数与激活函数),但不共享权重。为了能够优先关注与特定问题上下文相关的重要知识,作者提出了一种新颖的上下文感知消息传播方案来实例化 PSG,作者将 PSG 同时应用于场景图
和概念图
。

PSG 定义如 Table 1 所示,其详细定义如下:
2)图中介融合(Graph Medium Fusion)
为了实现跨模态学习,作者引入图中介融合,平衡两个难题:一方面,最大化模态间的融合,多模态信息相互协作;另一方面,保留每个模态固有的特征,避免模态之间相互引入噪声。
作者将
和
的共享实体集合:
视为中介节点(Medium),认为它们具有相似的嵌入。在每一层,交换
和
中相同中介节点的表示。具体来说,作者冻结了第一层的中介嵌入,以确保它们最初聚合了重要的单跳邻居信息。之后,相同中介的嵌入在当前层的消息传递后自动交换。
2.4 训练目标
1)答案导向的推理损失(Answer-targeted Inferential Loss)
使用二元交叉熵损失来优化最终预测结果:
2)最大均值差异损失(Maximum Mean Discrepancy, MMD)
作者认为同一中介节点在不同模态中应该具有相似的表示,采用 MMD 作为辅助对齐目标:
最终 MMD 损失定义如下:
3)联合优化(Joint Optimization)
为了防止
不区分地强制将两种模态的中介完全对齐,从而引入不必要的噪声而忽略不同模态的本质,作者引入
来平衡
的影响,最终训练损失定义如下:
3.实验
3.1 数据集
OK-VQA,FVQA
3.2 主实验
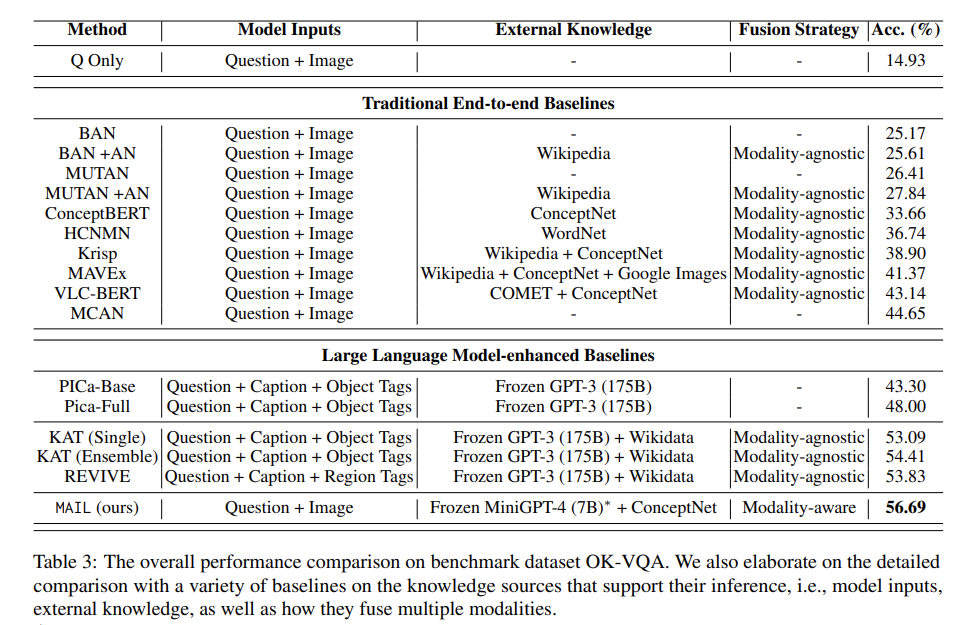
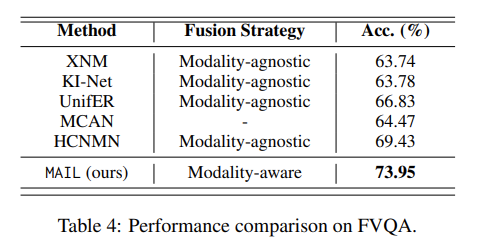
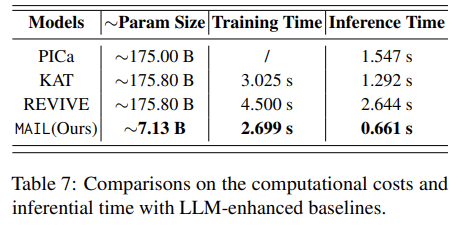
Table 3,Table 4 展示了 MAIL 在 OK-VQA、FVQA 数据集上和基线方法的对比。实验结果表明,MAIL 性能优于所有基线。与此同时,MAIL 资源利用高效,如 Table 7 所示,在所有大语言模型增强的基线模型中 MAIL 所需参数数量最少。
3.3 参数分析
1)图神经网络层数

层数过低时可能导致模态间融合不足,而层数过高可能导致过度融合进而削弱模态内的处理能力。如 Table 5 所示,最终图层为 3 层时 MAIL 达到最佳效果。
2)MMD 损失权重

为了在保留每个模态固有的特征的同时,促进跨模态融合,作者旨在寻找最合适的
来平衡
的影响。如 Table 6 所示,最终采用
。
3.4 消融实验
1)与 LLMs 的比较
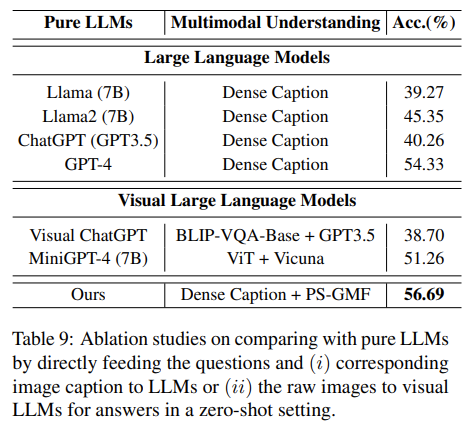
如 Table 9 所示,MAIL 优于最佳大语言模型 GPT-4 和视觉大语言模型 Visual ChatGPT、MiniGPT-4,这验证了 MAIL 的跨模态推理能力。
2)仅使用 PSG 进行推理
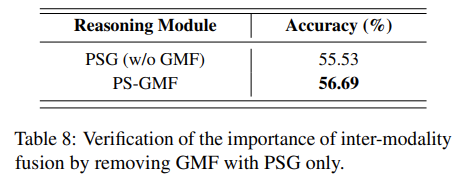
如 Table 8 所示,MAIL 在完整 PS-GMF 结构下性能优于 PSG-only 结构,验证了 GMF 对于促进有效的模态间交互的必要性。
4.总结
本文提出了一种面向基于知识的视觉问答的模态感知融合框架,能够实现图像、问题和外部知识之间的深度跨模态推理。该方法首先通过精心设计的提示挖掘大语言模型中的隐式知识构建耦合图(即场景图和概念图),然后使用伪孪生图中介融合机制,整合各种多模态信息,实现预测。MAIL 在两个基准数据集上取得了优势,同时推理时间比现有的最先进基线快 2 到 4 倍。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文 ,进入 OpenKG 网站。