当科技巨头们竞相投入数亿美元开发大语言模型时,前特斯拉AI总监、OpenAI创始成员卡帕西却走上了一条截然不同的道路。
今天,AI大牛卡帕西发布了名为"nanochat"的全新开源项目,瞬间引爆整个社区。
截至目前,该项目在GitHub上获得了9000颗星。
卡帕西本人形容这是"最疯狂的代码之一",承诺仅用100美元 的成本和4小时的训练时间,就能帮助任何人从零开始构建属于自己的ChatGPT级别聊天机器人。

和此前创建的nanoGPT相比,nanochat代表着卡帕西从专注模型预训练到全栈解决方案的理念进化。
nanoGPT项目主要专注于模型预训练阶段。它是一种小型的GPT模型,具有更少的参数,可以借助其了解LLM的实现原理,掌握PyTorch和Transformers的使用,从而了解GPT模型的工作原理。
而nanochat则是一个完整的全栈解决方案。它将在单个代码库中实现了从数据准备、模型预训练、对齐微调到推理部署的完整流程,代码总量约8000行。
nanochat的设计理念在于,使用者只需启动一台云GPU服务器,运行单个脚本,大约4小时后就能在ChatGPT风格的网页界面中与自己训练的大语言模型对话。这种端到端的体验可以让许多初学者直观理解大模型构建的全过程。

要实现这一低成本目标,关键在于精细的技术设计和流程优化。nanochat使用全新的Rust实现训练分词器,在FineWeb数据集上预训练Transformer架构的大语言模型。项目包含了指令微调、强化学习训练以及高效的推理引擎。
具体来说,约100美元的成本对应在8张H100 GPU上训练4小时,能够产生一个可进行基础对话、创作简单故事和诗歌、回答简单问题的聊天机器人。如果将训练时间延长至约12小时,模型在CORE指标上的表现就能超越GPT-2。
如果进一步将预算提升到约1000美元,训练约41.6小时,模型能力会出现显著提升,能够解决基础的数学和代码问题,并通过多项选择题测试。
当然,nanochat的真正价值不仅在于低成本,更在于其教育意义。它完整呈现了构建聊天机器人的每一步流程,包括数据准备、分词器训练、模型预训练、对齐微调、强化学习以及最终的推理部署。
项目会自动生成Markdown格式的评分报告卡,以游戏化的方式总结展示整个训练过程。这种直观的反馈机制让学习者能够清楚了解每个阶段的学习成果和模型表现。
卡帕西明确表示,nanochat将成为他正在开发的LLM101n课程的压轴项目。这也解释了项目设计中浓厚的教育基因------不是为了生产最强大的模型,而是为了提供最清晰的学习路径。
一个有趣的细节是,卡帕西在开发过程中基本上是全手写代码,他曾经尝试使用Claude或Codex等AI编程助手,但效果非常糟糕。这可能是因为项目代码库的结构偏离了这些助手训练数据的分布。
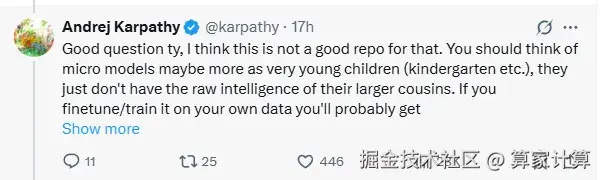
卡帕西也明确指出了项目的局限性。他将这些微型模型比作"幼儿园小朋友",认为它们不具备大型模型的原生智能。
要实现真正的个性化模型,可能需要准备原始数据,进行大量的合成数据生成和重写,然后使用当前较强的开源大模型进行微调,同时混入大量预训练数据以避免模型丢失通用智能能力。卡帕西坦言,这仍然属于研究范畴的课题。
nanochat的出现标志着大语言模型技术正在从尖端研究向普及教育转变。当科技巨头们专注于千亿美元参数规模、训练成本动辄数百万美元的模型时,nanochat反其道而行之,将门槛降低到普通开发者和学生可以承受的水平。
这种从小见大的方法不仅降低了学习门槛,也为理解大模型背后的核心原理提供了宝贵机会。对许多学习者而言,亲手训练一个小型模型远比使用API调用一个庞大模型更能带来洞察和理解。
未来,AI教育可能会变得更加平等和开放。更多开发者将通过这样的工具踏入AI领域,最终推动整个行业向前发展。