目录
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是Transformer的基本概念以及Transformer中encoder的基本架构。
Abstract
This article continues the study of Prof. Hung-yi Lee's 2025 Spring Machine Learning Course , focusing on the fundamental concepts of the Transformer and the basic architecture of its encoder.
1.Transformer基本概念
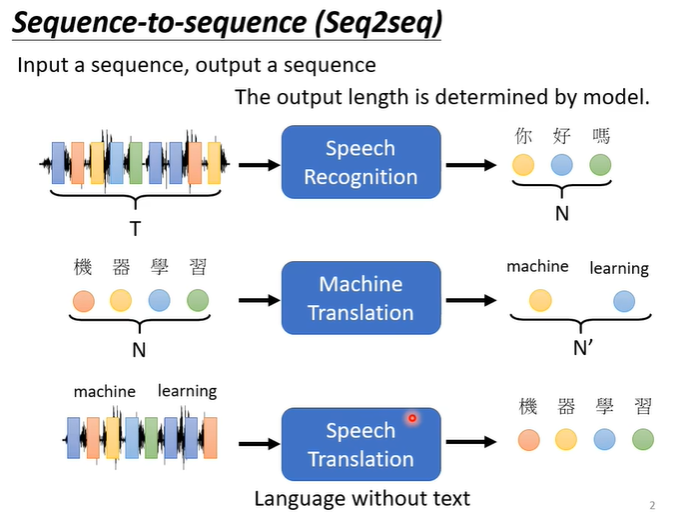
transformer实际上就是我们之前提到过的sequence to sequence的model,即输入一个句子输出一个句子,输入和输出的长度不固定,例如下图的语音识别,句子翻译,语音翻译等。
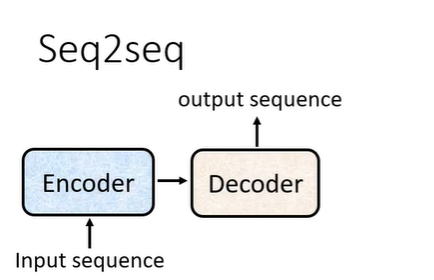
sequence to sequence的基本架构如下图,需要一个encoder处理输入,一个decoder处理输出。
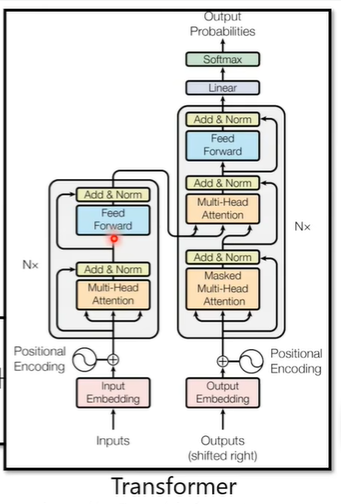
实际上与Transformer的架构相似,Transformer的架构如下图
2.Encoder
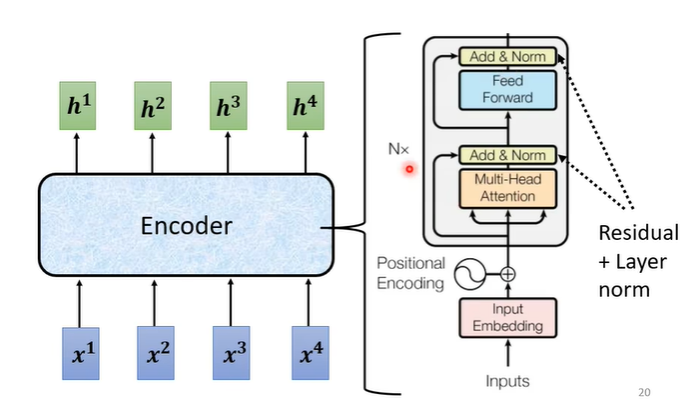
encoder实际上要做的事情就是给一排向量输出另一排向量。
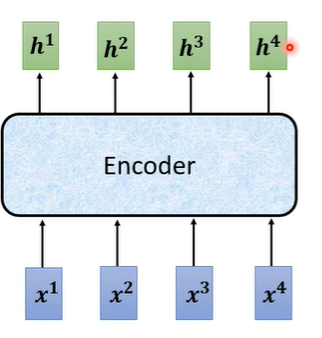
在encoder中会分成很多的block,输入一排向量给第一个block,第一个block输出给第二个block作为输入一直到最后一个block输出最终的向量。在transformer中一个block做的事情就是,先做一个self-attention考虑整个句子的资讯,输出另一排向量,再丢到fully connected的network中输出。
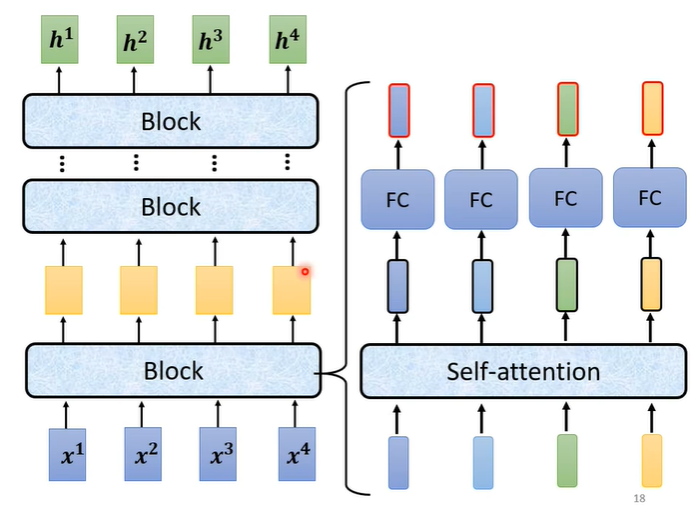
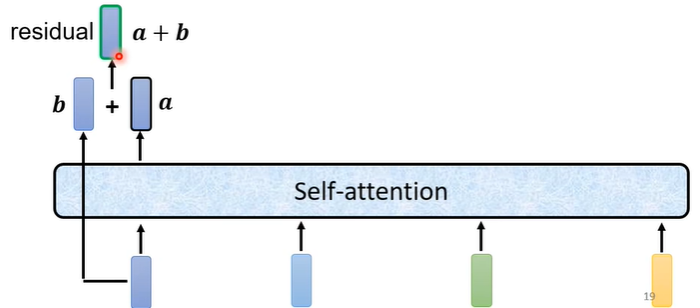
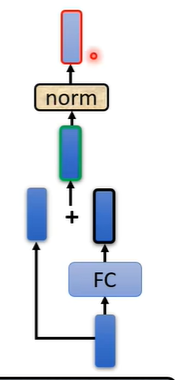
在原来的transformer中做的事情是更复杂的,在self-attention中加入了一个设计叫做residual connection,即输入self-attention的向量假设为b,输出的向量假设为a,在经过self-attention后将输入与输出合并起来,即a+b作为新的输出。
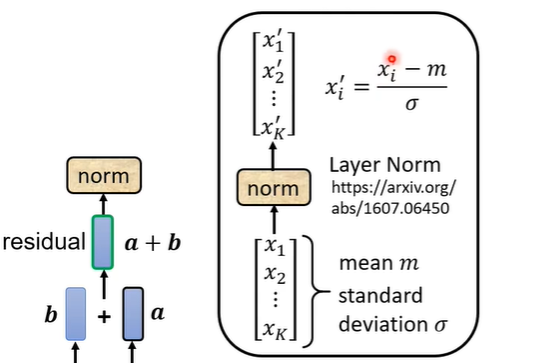
在得到residual的结果后进行normalization,用到的是layer normalization,它比batch normalization更简单,layer normalization就是输入一个向量输出一个向量,它计算输入向量均值和标准差,用向量中的每个数值减去均值后除标准差,最后得出的结果才是fully connected的输入。
在fully connected中同样也需要用residual,在得到residual的结果后也需要进行normalization。最后的输出才是block的输出。
transformer总体的encoder流程如下图右侧部分,输入可能还需要加入位置讯息(positional encoding),经过N个block输出最后的结果。