机器学习
有监督学习
- 核心目标:建立一个模型(函数),来描述输入(X)和输出(Y)之间的映射关系
- 价值:对于新的输入,通过模型给出预测的输出
有监督学习的要点
1.需要一定数量的训练样本
理解:机器学习模型不是凭空变出知识的,它需要从大量的"例题"中学习规律。这些"例题"就是训练样本。样本越多、质量越高,模型通常能学得越好。
比喻:你不能只给小孩看一张猫的图片,就指望他能认识所有猫。你需要给他看很多不同品种、不同颜色、不同姿态的猫的图片,他才能抽象出"猫"的共同特征(比如尖耳朵、胡须、喵喵叫)。同样,你也需要给他看狗、兔子等其他动物的图片,他才能学会区分。
要点:
-
数据是燃料:没有数据,再好的算法也无法工作。
-
数量和质量并重:数据量太少,模型学到的规律不具普遍性,容易"以偏概全"(过拟合)。数据质量差(例如图片模糊、标签错误),模型就会"学坏"。
-
关键问题:你手头有足够多、有代表性的"例子"吗?
2.输入和输出之间有关联关系
理解:我们期望模型能从输入(X)中找出预测输出(Y)的线索。如果两者之间根本没有内在的、哪怕是隐藏很深的逻辑或统计关联,那么机器学习就是在做"无米之炊"。
比喻:你想教小孩根据动物的叫声来判断是什么动物。这里,"叫声"和"动物种类"之间是有强关联的(猫叫对应猫,狗吠对应狗)。这个任务是有可能学会的。但如果你让他根据"当天的天气"来猜"动物园里什么动物最开心",这两者之间几乎没有可靠的关联,小孩(或模型)就无法学习到有效的规律。
要点:
-
相关性不等于因果性:机器学习寻找的主要是统计关联,而不一定是严格的因果关系。例如,模型可能发现"冰淇淋销量高"和"溺水事件多"有关联,但其共同原因是"天气热"。
-
关键问题:你认为你提供的输入信息(X)中,是否真的包含可以帮助推断出结果(Y)的信号?
3.输入和输出可以数值化表示
理解:计算机本质上只懂得处理数字。因此,我们现实世界中的一切信息(图片、文字、声音、类别等)都需要被转换成数值或数值向量(即一系列数字),模型才能进行处理。
比喻:
-
输入数值化:一张猫的图片,在电脑里被表示成一个由红、绿、蓝三色通道数值组成的巨大矩阵(比如224x224x3个数字)。一段"喵"的叫声,被表示成一系列声波的振幅数字。
-
输出数值化:
-
如果是回归问题(预测价格):输出直接就是一个数字(如 100.5元)。
-
如果是分类问题 (识别猫狗):输出通常被数值化为一个概率向量,例如
[0.9, 0.1],表示"有90%的可能是猫,10%的可能是狗"。
-
要点:
-
特征工程:如何将原始数据有效地转化为有意义的数字,这个过程至关重要,直接影响到模型的性能。
-
关键问题:你有办法把你手头的数据(无论是文本、图片还是表格)转换成数字吗?
4.任务需要有预测价值
理解 :我们投入资源去构建一个模型,是为了让它能对新的、没见过的数据做出预测,从而辅助决策。如果一个问题没有未来应用场景,或者其规律瞬息万变,那么为其构建模型就失去了意义。
比喻 :我们费尽心思教小孩认识了很多动物,目的是什么?是为了下次带他去动物园时,他能指着一只从未见过的豹子说:"那看起来像一只大猫,但身上有斑点,可能很危险。" 这就是泛化能力------将学到的知识应用到新场景的能力。
反之,如果你只是让他背诵你教过的那些特定图片,而无法识别新的动物,那么这个"学习"就失去了价值。或者,如果动物世界的分类规则每天都在变,昨天两条腿的是狗,今天三条腿的才是狗,那之前学的也立刻作废了。
要点:
-
泛化是目标:模型的核心价值不在于完美复述训练数据,而在于对新数据的准确预测。
-
规律应稳定:数据背后的潜在规律应该在一段时间内是稳定的,否则模型会迅速失效。
-
关键问题:训练这个模型来解决的问题,在未来有实际的应用场景吗?其背后的规律是稳定的吗?
有监督学习在人工智能中的应用
-
文本分类任务
-
输入:文本 输出: 类别
-
关系:文本的内容决定了文本的类别
-
机器翻译任务
-
输入:A语种文本 输出:B语种文本
-
关系:A语种表达的 意思, 在B语种有对应的方式
-
图像识别任务
-
输入:图像 输出:类别
-
关系:图中的像素排列,决定了图像的内容
-
语音识别任务
-
输入:音频 输出:文本
-
关系:声音信号在特定语言中对应特定的文本
一般流程
训练数据->数据处理<->算法选择<->建模&评估<->算法调优->模型
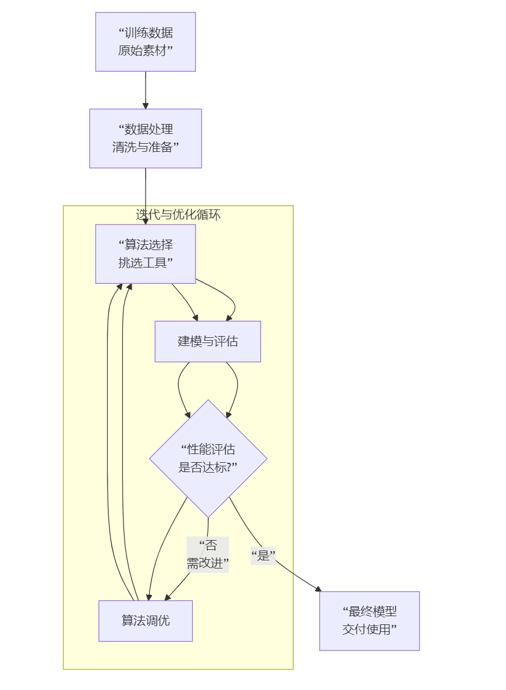
1. 训练数据
-
是什么 :这是模型的"学习资料",是带有"问题"和"标准答案"的数据集。通常分为特征 (输入,比如菜的"原料"、"火候")和标签(输出,比如菜的"最终口味")。
-
要点:数据量要足够,质量要高(不能全是发霉的面粉和错误的菜谱),否则"巧妇难为无米之炊"。
2. 数据处理
-
是什么:原始数据通常是脏乱、不完整的,不能直接使用。这个步骤包括:
-
数据清洗:处理缺失值、异常值、错误值。
-
特征工程:从原始数据中提取或构造对预测更有用的特征。这是非常关键的一步。
-
数据标准化/归一化:将数据scale到统一范围,让模型更好学习。
-
3. 算法选择
-
是什么:根据你要解决的问题(是预测价格?还是分类猫狗?)和数据特点,选择一个合适的机器学习算法。
-
分类问题:比如逻辑回归、决策树、SVM。
-
回归问题:比如线性回归、决策树回归。
-
复杂问题:比如神经网络、随机森林、梯度提升树。
-
注意流程图中的
<->:数据处理和算法选择是相互影响的。比如,你选择了神经网络,通常需要对数据进行归一化;你发现数据是图像,可能直接选择CNN(一种神经网络)。
4. 建模与评估
-
建模:将处理好的数据"喂"给选定的算法,让计算机进行训练,生成一个初步的模型。
-
评估 :用模型从未见过的测试集数据来检验它的真实水平。使用评估指标(如准确率、精确率、均方误差等)来量化性能。
-
关键 :必须使用新数据(测试集)评估,否则就像让大厨自己尝自己做的菜,缺乏客观性,无法知道他是否只记住了菜谱而不会灵活变通(过拟合)。
5. 算法调优
-
是什么:如果模型在测试集上表现不佳,我们需要返回去进行调整。
-
调什么:
-
超参数调优:调整算法的"旋钮",如学习率、树的深度、正则化强度等。
-
进一步的特征工程:构造更有效的特征,或剔除无效特征。
-
甚至重新选择算法。
-
-
注意流程图中的
<->:这正体现了机器学习项目是一个反复迭代、循环优化的过程。建模评估后,大概率会回到调优阶段,甚至可能重新选择算法或处理数据。
6. 模型 -
-
是什么 :当模型在测试集上的表现达到我们的预期标准后,这个训练好的、最终版的"程序"就是我们的模型。
-
交付:这个模型可以被集成到应用程序、网站或系统中,对新的、从未见过的数据进行预测,创造价值。
总结
这个流程不是一个线性的、一次就能成功的过程,而是一个以评估为导向的、螺旋上升的迭代循环 。核心思想就是:准备数据 -> 尝试学习 -> 客观评估 -> 发现问题 -> 回头优化 -> 再次尝试,直到得到一个令人满意的解决方案。
常用概念
1.训练集
用于模型训练的训练数据集合
2.验证集
对于每种任务一般都有多种算法可以选择,一般会使用验证集验证用于对比不同算法的效果差异
3.测试集
最终用于评判算法模型效果的数据集合
4.K折交叉验证
初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型数据的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果。
举例:我们假设K=5
-
第1轮 :用 Fold 1 作为 验证集 (考试卷),用 Fold 2,3,4,5 作为 训练集(复习资料),训练模型并得到一个分数 S1。
-
第2轮 :用 Fold 2 作为 验证集 ,用 Fold 1,3,4,5 作为 训练集,训练模型并得到一个分数 S2。
-
重复... 直到每一份数据都恰好当过一次验证集。
-
计算 :最终模型的性能得分 =
(S1 + S2 + ... + S5) / 5。
注意事项
K值的选择:最常用的是5或10。K太小(比如2),评估结果可能不稳定;K太大(比如和样本数一样,这叫"留一法"),计算成本会非常高。
数据需要随机打乱:在分折之前,必须将数据随机打乱,以确保每个折里的数据分布都是相似的。
不适用于时间序列数据:对于时间序列数据(比如股票价格),不能随机打乱,需要按时间顺序来划分,否则会"数据泄露"(用未来的数据预测过去)。
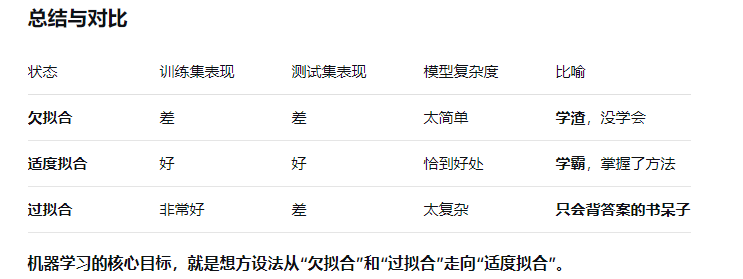
过拟合
模型失去了泛化能力。如果模型在训练和验证集上都是很好的表现,但是测试集上表现和差,一般认为发生了过拟合
欠拟合
模型没能建立起合理的输入输出之间的映射。当输入训练集中的样本时,预测结果与标注结果依然相差很大。
导数与梯度
导数
导数表示函数在曲线上的切线斜率,除了切线斜率,导数还表示在该点的变化率。
基本概念:
-
自变量数量: 只研究一元函数,即函数只有一个输入变量(例如 y=f(x)y=f(x))。
-
几何意义: 导数 f′(x0)f′(x0) 在几何上表示函数图像在点 (x0,f(x0))(x0,f(x0)) 处的切线斜率。
梯度
•梯度告诉我们函数向哪个方向增长最快,那么他的反方向,就是下降最快的方向
•梯度下降的目的是找到函数的极小值
•为什么要找到函数的极小值?
因为我们最终的目标是损失函数值最小.
他的核心思想是:导数在多元函数中的推广,它是一个向量,指向函数值增长最快的方向。
导数和梯度的对比
| 特征 | 导数 | 梯度 |
|---|---|---|
| 函数类型 | 一元函数 y=f(x)y=f(x) | 多元函数 y=f(x1,...,xn)y=f(x1,...,xn) |
| 是什么 | 一个标量(一个数值) | 一个向量(一组数值) |
| 几何意义 | 切线的斜率 | 指向增长最快的方向 |
| 数学构成 | 就是它本身 | 由所有偏导数构成 |
| 核心思想 | 瞬时变化率 | 方向性的瞬时变化率 |
Batch(批)
-
是什么?
-
由于计算机内存和算力的限制,我们很少将整个数据集一次性输入神经网络进行训练。相反,我们将数据分成若干个更小的、可管理的批次(Batches)。
-
批大小 指的是单个批次中包含的样本数量。例如,如果您的数据集有10,000张图片,设置
batch_size=100,那么每100张图片会组成一个批次,总共会有100个批次。
-
-
作用:
-
内存效率: 这是最主要的原因。一次性加载所有数据可能超出GPU/内存的容量,分批处理可以解决这个问题。
-
计算效率: 现代计算库(如PyTorch, TensorFlow)可以对批次数据进行高效的并行计算,大大加快训练速度。
-
引入噪声,有助于泛化: 与一次性使用全部数据(这相当于最速下降法)不同,小批量梯度下降法在每一步计算梯度时都只基于一小部分数据。这种梯度估计是带有噪声的,这种噪声反而有助于模型跳出尖锐的局部最小值,找到更平坦的、泛化能力更好的最小值。
-
-
相关概念:
-
批量梯度下降:
batch_size= 整个数据集大小。计算准确,但速度慢,内存消耗大。 -
随机梯度下降:
batch_size= 1。每次只用一个样本。噪声很大,收敛过程非常不稳定。 -
小批量梯度下降:
1 < batch_size < 整个数据集大小。这是实践中最常用的方法,在速度和稳定性之间取得了很好的平衡。
-
Epoch(周期)
-
是什么?
-
一个 Epoch 表示整个训练数据集 已经被神经网络完整地学习了一遍。
-
在一个Epoch中,你会使用所有的小批次(Batches)对模型进行一次完整的训练。
-
例子: 同样有10,000张图片,
batch_size=100。那么,1个 Epoch 就意味着模型已经处理了10,000 / 100 = 100个批次。
-
-
作用:
-
衡量训练进度: Epoch是训练过程中的一个基本计时单位。我们通常会设置模型要训练多少个Epoch(例如
epochs=50)。 -
让模型充分学习: 通常一个Epoch是不够的,模型需要多次、从不同角度(因为批次是随机打乱的)"浏览"整个数据集,才能逐渐学习到数据中隐藏的规律,并调整其权重。
-
决定训练何时停止: 训练过程通常会在完成指定数量的Epoch后停止,或者当模型在验证集上的性能不再提升时提前停止。
-
Batch 和 Epoch 的关系:一个经典的比喻
把学习过程想象成复习一本厚厚的备考书:
-
数据集 = 整本教科书。
-
Batch = 书中的一页或一小节。你一次只复习这一小节的内容。
-
Batch Size = 你一次复习多少页。比如你决定每次复习5页。
-
Iteration(迭代) = 你复习完一个批次(比如5页)就是一个迭代。这是模型权重一次更新的单位。
-
Epoch = 你把整本教科书从头到尾完整地复习了一遍。
过程是: 你不可能一次记住整本书,所以你把它分成很多个小节(Batches)来学习。每学完一个小节(一个Iteration),你就会做点笔记(更新模型权重)。当你把书里所有小节都学完一遍后,你就完成了一个Epoch。然后你可能会把书合上,打乱顺序,再开始第二个Epoch的复习,以加深理解和记忆。
数学关系:
一个Epoch中的迭代次数 = 总样本数 / Batch Size
总结与作用
| 术语 | 作用 | 通俗理解 |
|---|---|---|
| Batch(批) | 1. 内存管理 :使大规模数据集训练成为可能。 2. 加速计算 :利用硬件并行性。 3. 正则化效果:引入噪声,提升模型泛化能力。 | 学习的最小单位,像是一口一口地吃饭。 |
| Epoch(周期) | 1. 训练计量 :衡量模型看过全部数据的次数。 2. 充分学习 :确保模型有足够的机会从数据中学习。 3. 停止标志:决定训练循环的终点。 | 学习的完整轮次,像是把整本书读完一遍。 |
因此,Batch 和 Epoch 共同构成了深度学习训练的核心循环,它们协同工作,使得高效、有效地训练复杂模型成为可能。您需要根据具体任务和硬件条件来调整 batch_size 和 epochs 这两个关键的超参数。