简介
数据标注的工具包括以下几种:
LabelImg:一款图形图像标注工具,用Python编写,并将Qt用于其图形界面。可以用于进行目标检测项目的标注工作,支持2D矩形框标注。
Labelme:一款开源的图像标注工具,由Visual Geometry Group开发。可以在线和离线使用,支持多边形分割、语义分割、2D框、线标注、点标注。
VIA-VGG Image Annotator (VIA):一款开源的图像标注工具,由Visual Geometry Group开发。可以在线和离线使用,支持多边形分割、语义分割、2D框、线标注、点标注。Version 3增加了对视频和音频的标注以及人脸标注。
RectLabel:一款目标检测标注工具,支持导出YOLO、KITTI、COCO JSON与CSV格式,读写Pascal VOC格式的XML文件。
VOTT:微软发布的一款基于JavaScript开发用于图像目标检测的标注工具,使用React+Redux进行开发,支持Windows和Linux平台运行。软件提供了基于CNTK训练的faster-rcnn模型进行自动标注然后人工矫正的方式,能大幅减轻标注所需的工作量。
OpenCV/CVAT:一款开源的计算机视觉库,提供了多种标注类型,包括多边形分割、语义分割、2D框、线标注、点标注等。同时支持视频标注和多种文件导出格式,如CVAT for video、CVAT for images、PASCAL VOC等。 LableBox:一款WEB模式下的标记工具,提供自定义注释API支持,纯JS + HTML支持。
我们这里主要介绍一下具Labelme
一、Labelme的安装
官网:https://github.com/wkentaro/labelme
使用pip命令进行下载
首先安装labelme所需要的依赖环境
python
pip install pyqt5
python
Pip install pillow安装labelme
python
pip install labelme指定版本加上镜像
python
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple labelme==5.0.1二、使用Labelme
在终端输入命令labelme启动,进行下面页面
上面工具栏可以打开图片或者打开文件夹进行标注,
给各个数据打上标签,默认保存为json格式文件
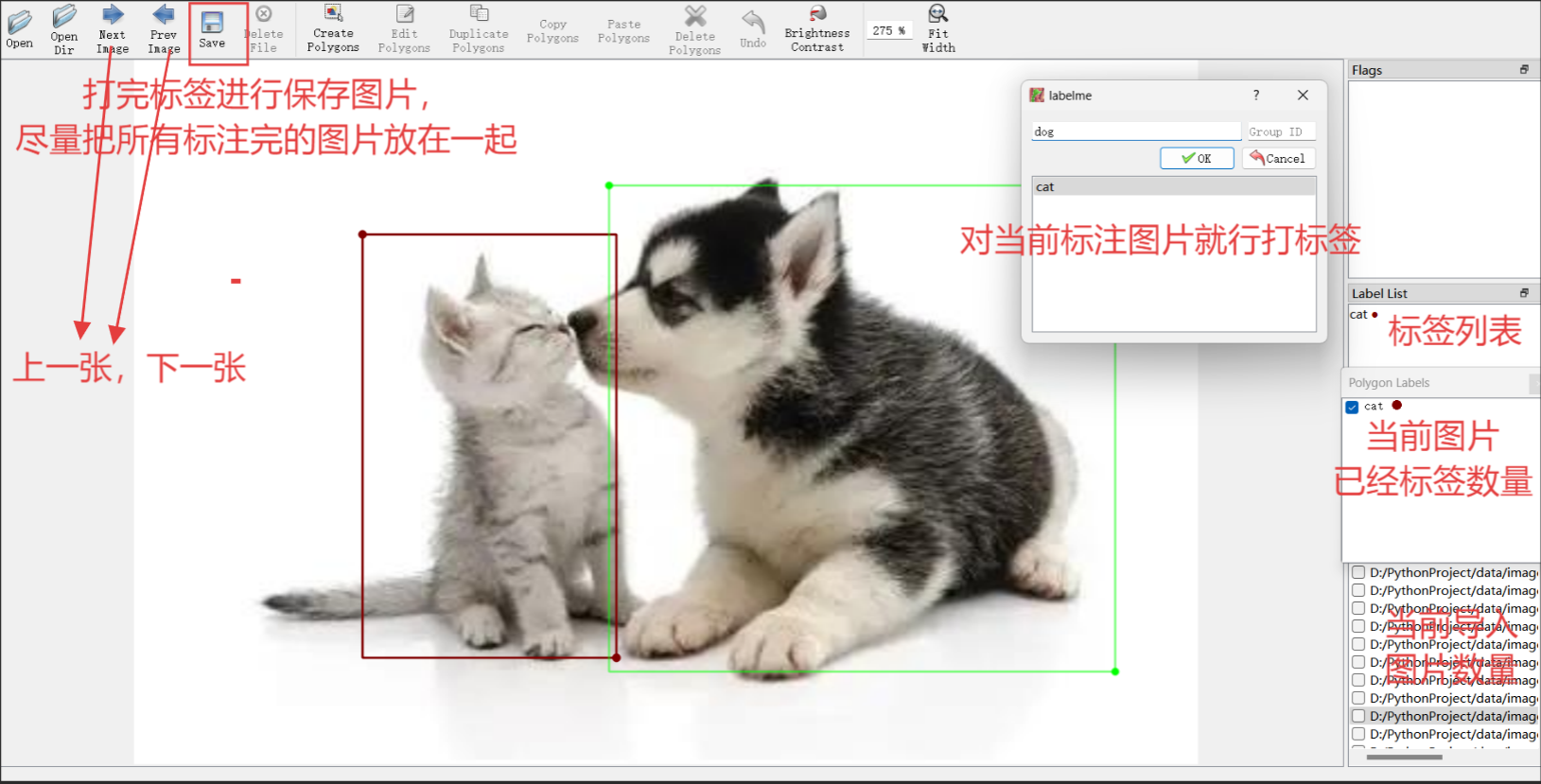
标注完之后点击save进行保存,注意:最好把标注完的json文件与原图存放在一个目录下,这样在后期查看的时候可以看到原图与标注区域的叠加,而不单单是原图。
json文件包含内容
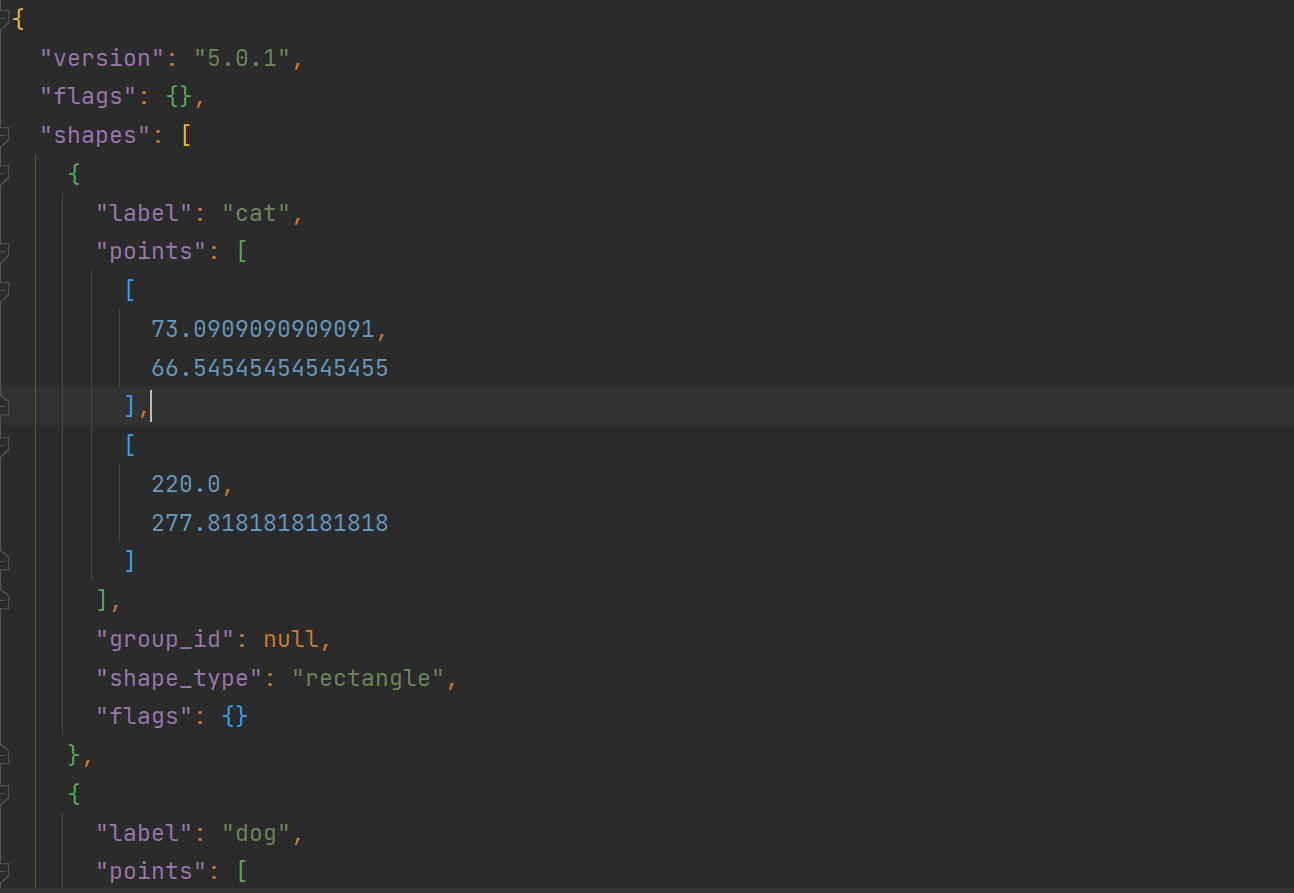
包含你在图片的标注标签的数量与标注框的位置信息
三、标签格式转换
- 格式差异说明
- labelme 标注格式:
x1,y1,x2,y2(目标检测的对角坐标格式) - YOLO-V3 标注格式:
Cx,Cy,W,H(相对位置,取值范围 0-1,即中心点横纵坐标、宽高的相对比例)
- labelme 标注格式:
- 转换工具
- 脚本文件:
json2yolo.py - 位置:在
utils文件夹中 - 功能:将 labelme 生成的 json 标签文件转换为 YOLO-V3 支持的格式
- 脚本文件:
- 文件路径
- json 文件路径(labelme 生成标签的文件夹):
...\PyTorch-YOLOv3\PyTorch-YOLOv3_myedit\data\label,包含dog.json、eagle.json、field.json、giraffe.json、herd_of_horses.json、messjon.json、person.json等文件 - 转换后输出路径:
data\custom\labels,生成对应名称的 txt 文件(如dog.txt、eagle.txt、field.txt等),txt 文件内是 YOLO 格式的标注数据(如field.txt中内容为相对坐标数值)
- json 文件路径(labelme 生成标签的文件夹):
- abelme 是常用的图像标注工具,输出的 json 文件记录目标的对角坐标(
x1,y1,x2,y2);而 YOLO-V3 模型训练需要的是目标中心点和宽高的相对比例(Cx,Cy,W,H,取值 0-1),因此需要格式转换。 - 通过
utils文件夹中的json2yolo.py脚本,将 labelme 生成的 json 文件(存放在指定label文件夹)转换为 YOLO 格式的 txt 文件,并输出到data\custom\labels路径下,最终 txt 文件中的数据可直接用于 YOLO-V3 模型的训练。