本篇文章主要进行算法练习题讲解
1 串联所有单词的子串
链接:https://leetcode.cn/problems/substring-with-concatenation-of-all-words/description/
题目描述:
给定一个字符串
s和一个字符串数组words。words中所有字符串 长度相同。
s中的 串联子串 是指一个包含words中所有字符串以任意顺序排列连接起来的子串。
- 例如,如果
words = ["ab","cd","ef"], 那么"abcdef","abefcd","cdabef","cdefab","efabcd", 和"efcdab"都是串联子串。"acdbef"不是串联子串,因为他不是任何words排列的连接。返回所有串联子串在
s中的开始索引。你可以以 任意顺序 返回答案。示例 1:
输入:s = "barfoothefoobarman", words = ["foo","bar"] 输出:[0,9] 解释:因为 words.length == 2 同时 words[i].length == 3,连接的子字符串的长度必须为 6。 子串 "barfoo" 开始位置是 0。它是 words 中以 ["bar","foo"] 顺序排列的连接。 子串 "foobar" 开始位置是 9。它是 words 中以 ["foo","bar"] 顺序排列的连接。 输出顺序无关紧要。返回 [9,0] 也是可以的。示例 2:
输入:s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"] 输出:[] 解释:因为 words.length == 4 并且 words[i].length == 4,所以串联子串的长度必须为 16。 s 中没有子串长度为 16 并且等于 words 的任何顺序排列的连接。 所以我们返回一个空数组。示例 3:
输入:s = "barfoofoobarthefoobarman", words = ["bar","foo","the"] 输出:[6,9,12] 解释:因为 words.length == 3 并且 words[i].length == 3,所以串联子串的长度必须为 9。 子串 "foobarthe" 开始位置是 6。它是 words 中以 ["foo","bar","the"] 顺序排列的连接。 子串 "barthefoo" 开始位置是 9。它是 words 中以 ["bar","the","foo"] 顺序排列的连接。 子串 "thefoobar" 开始位置是 12。它是 words 中以 ["the","foo","bar"] 顺序排列的连接。提示:
1 <= s.length <= 1041 <= words.length <= 50001 <= words[i].length <= 30words[i]和s由小写英文字母组成
题目解析:
这道题目会给你一个字符串 s 和一个字符串数组 words,其中 words 中每一个字符串的长度都是相同的。这道题目是让你在 s 中找出所有 words 的串联子串的起始索引,其中串联子串是指由 words 中所有字符串任意组合而成的一个新的字符串,比如 words = "ab", "cd", "ef",那么 "abcdef"、"abefcd"、"cdabef"、"cdefab"、"efabcd"、"efcdab" 都是其串联子串。例如:s = "ababcdef cdab",words = "ab", "cd", "ef",返回 vector<int> = 2, 6
算法讲解:
这道题目其实与我们之前做过的一到题目 -- 找出字符串中的所有字母异位词 很像,那道题是在一个字符串 s 中找到另一个字符串 p 的所有字母异位词,异位词就是 p 字符串的所有字符随机组合而形成的字符串,这道题目由于 words 中每个字符串长度是一样的,如果我们将 words 中每一个字符串看成是字母 a, b, c,s 中每 words0.size() 个字符看成是一个字符,那么这道题就变成了找出字符串中的所有字母异位词题目了。比如示例1:s = "barfoothefoobarman",words = "foo", "bar",我们将 words 看成 words = 'a', 'b',那么 s = "bacabd",这就变成了上面的那一道题目。
所以这个题目的解法依然是采用哈希表 + 滑动窗口算法的解法,只不过与那一道题目有所区别:
(1) 哈希表的形式:之前那道题目因为是字符,我们用的是一个整数数组来作为哈希表统计有效字符的出现次数;但是这里是字符串,我们需要用到 STL 中的一个容器,那就是 unordered_map<string, int> 作为哈希表来统计有效字符串出现的次数(如果这个容器没学过,可以先跳过,后面学过了之后再做)。
(2) left 与 right 的移动:这里显然每次要移动 words 中一个字符串的长度,因为这里是将一个字符串作为一个单位移动的
(3) 滑动窗口执行的次数:这里滑动窗口应该执行 words 中每一个字符串的长度次,比如:s = "afoobarabcfoo", words = "foo", "bar",所以起始位置也可能从索引1开始;再比如:s = "abfoobarabcef", words = "foo", bar,起始位置也可能从索引 2 开始,但是再往后,如果从索引 3 开始,其实是与从索引 0 开始是一样的,只不过多一个单词而已。
代码:
cpp
class Solution
{
public:
vector<int> findSubstring(string s, vector<string>& words)
{
vector<int> v;
//首先利用 hash1 统计 words 中每个字符串出现的次数
unordered_map<string, int> hash1;
for (auto& str : words)
hash1[str]++;
int len = words[0].size();
//开始滑动窗口
//要进行 len 次
for (int i = 0; i < len; i++)
{
unordered_map<string, int> hash2;//利用 hash2 统计 s 字符串中子串的长度
int left = i, right = i;
int count = 0;//统计有效字符串数
while (right + len <= s.size())
{
//进窗口
string in = s.substr(right, len);
hash2[in]++;
if (hash1[in] >= hash2[in]) ++count;
//判断
while (right - left + 1 > words.size() * len)
{
//出窗口
string out = s.substr(left, len);
if (hash1[out] >= hash2[out]) --count;
hash2[out]--;
left += len;
}
//更新结果
if (count == words.size()) v.push_back(left);
right += len;
}
}
return v;
}
};2 最小覆盖子串
链接:https://leetcode.cn/problems/M1oyTv/
题目描述:
给定两个字符串
s和t。返回s中包含t的所有字符的最短子字符串。如果s中不存在符合条件的子字符串,则返回空字符串""。如果
s中存在多个符合条件的子字符串,返回任意一个。注意: 对于
t中重复字符,我们寻找的子字符串中该字符数量必须不少于t中该字符数量。示例 1:
输入:s = "ADOBECODEBANC", t = "ABC" 输出:"BANC" 解释:最短子字符串 "BANC" 包含了字符串 t 的所有字符 'A'、'B'、'C'示例 2:
输入:s = "a", t = "a" 输出:"a"示例 3:
输入:s = "a", t = "aa" 输出:"" 解释:t 中两个字符 'a' 均应包含在 s 的子串中,因此没有符合条件的子字符串,返回空字符串。提示:
1 <= s.length, t.length <= 105s和t由英文字母组成
题目解析:
这道题目会给你一个 s 字符串与 t 字符串,该题目要求你返回 s 字符串中包含了 t 字符串中所有字符的最短子串(t 中如果存在两个相同字符,那也算是两个字符),其中这个子串包含的 t 字符串中字符的个数可以多于 t 字符串中的字符个数,但是不是少于 t 字符串中的字符个数。比如:
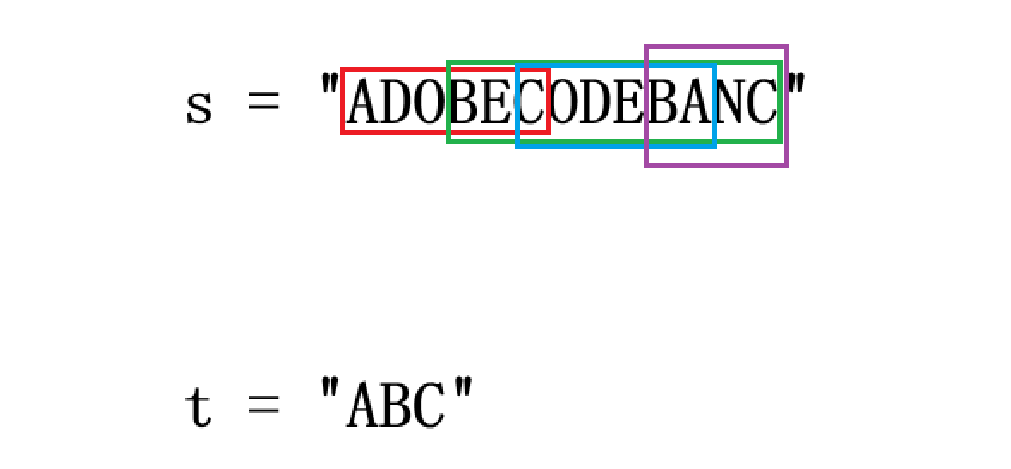
s 中满足条件的子串如图所示,显然最短的子串就是 "BANC",所以返回的字符串就是 "BANC"
算法讲解:
我们可以先利用暴力解法来解决问题:我们可以从第一个字符开始,然后依次向后找,直到该子串满足条件,我们就可以停止向后寻找;然后再从第二个字符开始,重复该过程,知道枚举到 s.size() - t.size() 位置,然后找到最短的子串就可以了,最后返回该子串,其中判断子串是否满足条件,我们依旧采用哈希表来记录字符出现的次数:
cpp
class Solution
{
public:
string minWindow(string s, string t)
{
if (s.size() < t.size()) return "";
//先利用 hash1 来记录 t 中字符串出现的次数
int hash1[128] = { 0 };
for (auto& ch : t) hash1[ch]++;
int start = 0, len = INT_MAX;//记录开始位置与长度
for (int i = 0; i <= s.size() - t.size(); i++)
{
//i 作为子串的左端点
int j = i;
int count = 0;//count 用来记录满足条件的字符数
int hash2[128] = { 0 };//hash2 来记录出现的字符数
while (j < s.size())
{
//j 作为子串的右端点
hash2[s[j]]++;
if (hash1[s[j]] >= hash2[s[j]]) ++count;
if (count == t.size()) break;
++j;
}
if (count == t.size())
if (j - i + 1 < len)
{
start = i;
len = j - i + 1;
}
}
if (len == INT_MAX) return "";
else return s.substr(start, len);
}
};显然,该算法的时间复杂度为 O(n^2)。
这个算法该怎么优化呢?在暴力解法中,我们是有一个 i 来指向左端点,j 来指向右端点,当 找到 j,i 向右移动开始枚举下一种情况时,j 需要再从 i 开始向后枚举,但是如果 i, j 区间的子串是满足条件的,我们可以直接通过 i 位置的字符来判断是否去掉了一个有效字符,如果没去掉,那么 i + 1, j 位置依然是一个有效区间,如果去掉了,那么 j 从 i +1 位置开始枚举的时候,依然会向后走到那个位置,因为 i, j 之间的有效字符是正好等于 t 中字符的个数的,如果去掉了一个,那么 j 依然会走到上次那个位置而且会继续向后走,所以我们可以不让 j 回到 i,而是根据 i 位置的字符来处理,就能得到最终结果,所以我们让 i, j 同向移动就可以解决问题了,所以我们采用滑动窗口的算法来解决问题:
(1) 定义 left = 0, right = 0, hash1128 = { 0 }, hash2128 = { 0 },hash1 用来记录 t 中有效字符的个数,hash2 用来记录 s 中有效字符的个数,count = 0,count 用来记录有效字符的个数
(2) 进窗口:hash2s\[right]++,如果 hash1s\[right] >= hash1s\[right],++count
(3) 判断:这里的判断比较难想,在暴力解法中,当 j 走到满足条件的位置时,我们才会停止枚举,所以我们这里的判断,就是当 left, right 的子串满足条件时,也就是 count == t.size() 时,才会出窗口,出窗口也很简单,如果 hash1s\[left] >= hash2s\[left],那就让 count--,再让hash2s\[left]--,然后 ++left
(4) 更新结果:由于是在满足条件时出窗口,所以我们更新结果是在判断里面进行的,由于更新结果是更新一个起始位置和一个子串的长度,所以在准备阶段还需要定义一个 start 与 len 来更新结果
代码:
cpp
class Solution
{
public:
string minWindow(string s, string t)
{
if (s.size() < t.size()) return "";
//先利用 hash1 来记录 t 中字符串出现的次数
int hash1[128] = { 0 };
for (auto& ch : t) hash1[ch]++;
int start = 0, len = INT_MAX;//记录开始位置与长度
int left = 0, right = 0, count = 0;
int hash2[128] = { 0 };//hash2 记录 s 子串中字符出现次数
while (right < s.size())
{
//进窗口
hash2[s[right]]++;
if (hash1[s[right]] >= hash2[s[right]]) ++count;
//判断
while (count >= t.size())
{
//更新结果
if (right - left + 1 < len)
{
len = right - left + 1;
start = left;
}
//出窗口
if (hash1[s[left]] >= hash2[s[left]]) --count;
hash2[s[left]]--;
++left;
}
++right;
}
return len == INT_MAX ? "" : s.substr(start, len);
}
};3 最接近的三数之和
链接:16. 最接近的三数之和 - 力扣(LeetCode)
题目描述:
给你一个长度为
n的整数数组nums和 一个目标值target。请你从nums中选出三个整数,使它们的和与target最接近。返回这三个数的和。
假定每组输入只存在恰好一个解。
示例 1:
输入:nums = [-1,2,1,-4], target = 1 输出:2 解释:与 target 最接近的和是 2 (-1 + 2 + 1 = 2)。示例 2:
输入:nums = [0,0,0], target = 1 输出:0 解释:与 target 最接近的和是 0(0 + 0 + 0 = 0)。提示:
3 <= nums.length <= 1000-1000 <= nums[i] <= 1000-104 <= target <= 104
题目解析:
这道题目与三数之和很像,只不过这个题目是寻找 nums 数组中三个数字和与 target 最接近的三个数字,并且返回这三个数字的和。比如:nums = **-1, 2, 1**, 4,target = 1,那么返回的就是2,因为加起来和与 1 最接近的三个数字就是-1, 1, 2,所以最终返回的结果就是这三个数字的和 2。
算法讲解:
由于这个题目与三数之和很像,所以我们依然选择与三数之和相同的解法:排序 + 双指针。首先我们会先对数组进行排序,然后我们固定第一个数 numsi,然后在剩下的区间i + 1, nums.size() - 1中选择两个数字 numsleft 与 numsright,如果三个数字的和正好等于 target,那么这这三个数字就是最优解,因为每组输入中仅存在一个解,所以直接返回 target 就可以了;当 numsi + numsleft + numsright > target 时,说明是三个数字大了,那么我们就 --right;如果 numsi + numsleft + numsright < target,此时说明三个数字小了,那么我们就 ++left,但是这道题目有一个特殊点,那就是找最接近的,我们需要寻找一种方法来更新最优解。
与 target 最接近的数字是用与 target 的距离来表示的,两个数字之间的距离在数学上是用绝对值来衡量的,所以我们这里采用绝对值来更新结果。比如:target = 8,而一个 sum = 7,另一个 sum = 10(这里的 sum 代表 numsi + numsleft + numsright),很显然 7 更接近 target,因为 abs(7 - 8) < abs(10 - 8)(abs 是求绝对值的库函数包含在 math.h 头文件下),所以在双指针在寻找两个数字的过程中,我们采用绝对值来更新结果:如果 abs(sum - target) < abs(best - target),我们更新 best = sum,其中 best 记录最优解。
当然这道题目也可以优化一点时间复杂度,就是跳过相同元素,这里就不再优化了,感兴趣可以自己写一下。
代码:
cpp
class Solution
{
public:
int threeSumClosest(vector<int>& nums, int target)
{
sort(nums.begin(), nums.end());
long long best = INT_MAX;
//固定第一个数字
for (int i = 0; i < nums.size() - 2; ++i)
{
int a = nums[i];
int left = i + 1, right = nums.size() - 1;
while (left < right)
{
int b = nums[left], c = nums[right];
long long sum = a + b + c;
if (sum == target) return target;
if (abs(sum - target) < abs(best - target)) best = sum;
if (a + b + c < target) ++left;
else --right;
}
}
return best;
}
};