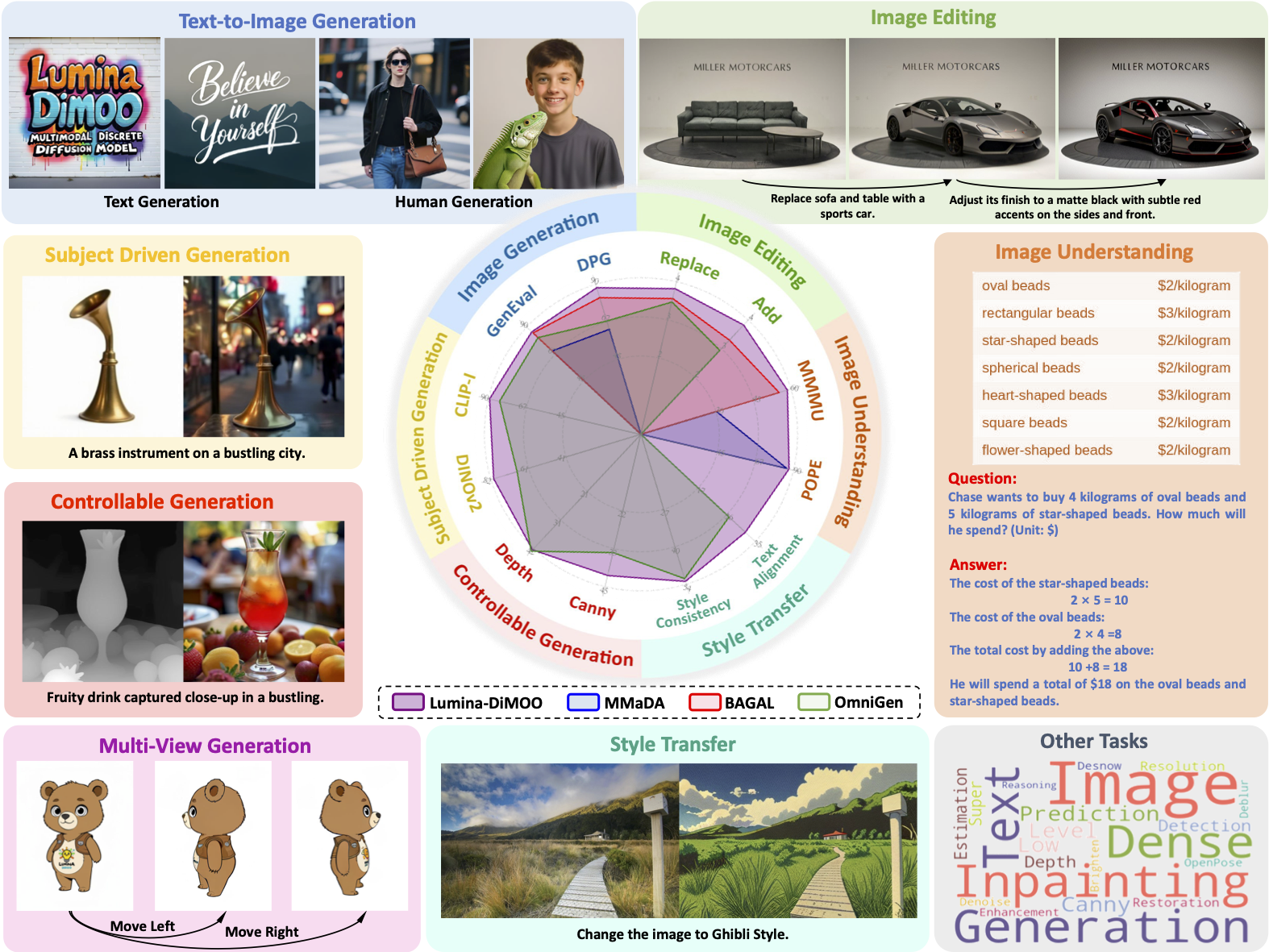
📚 简介
我们推出Lumina-DiMOO------一个实现无缝多模态生成与理解的全能基础模型。Lumina-DiMOO凭借四大创新突破脱颖而出:
-
统一的离散扩散架构:采用完全离散的扩散建模处理跨模态输入输出,这与先前统一模型形成显著差异。
-
全能多模态能力:支持广泛的多模态任务,包括文本到图像生成(支持任意高分辨率)、图像到图像生成(如图像编辑、主体驱动生成和图像修复等),以及高级图像理解。
-
更高采样效率:相比传统自回归或混合自回归-扩散范式,Lumina-DiMOO展现出卓越的采样效率。我们还设计了定制缓存方法,使采样速度进一步提升2倍。
-
顶尖性能表现:在多项基准测试中达到最先进水平,超越现有开源统一多模态模型,树立了领域新标杆。
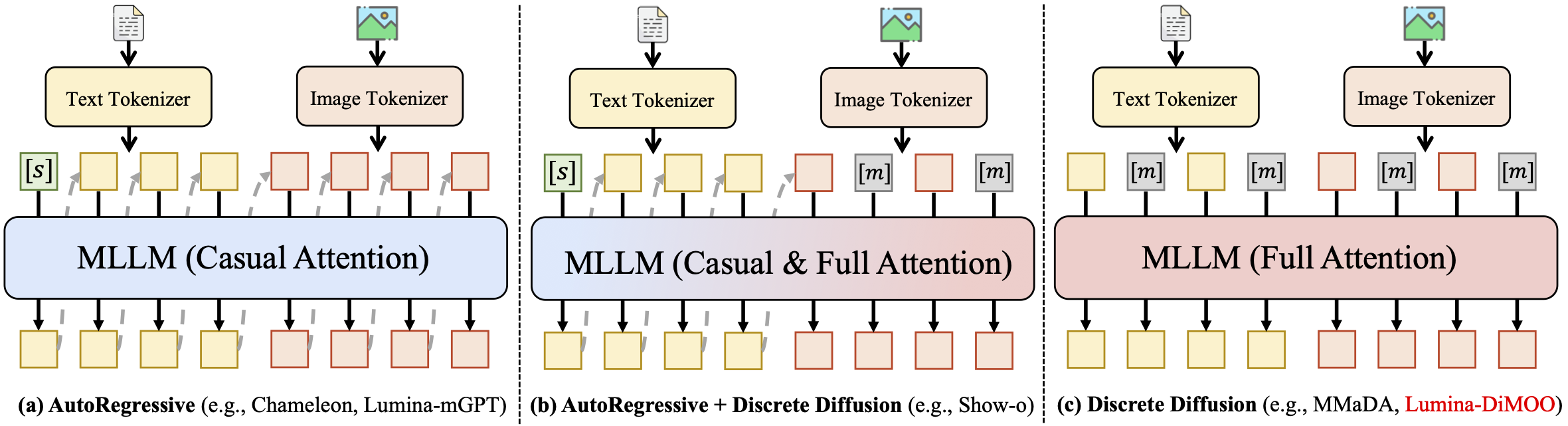
📽️ 定性结果
这里我们展示了与其他模型的部分生成效果对比。更多可视化结果请参见我们的项目主页。
文本到图像比较
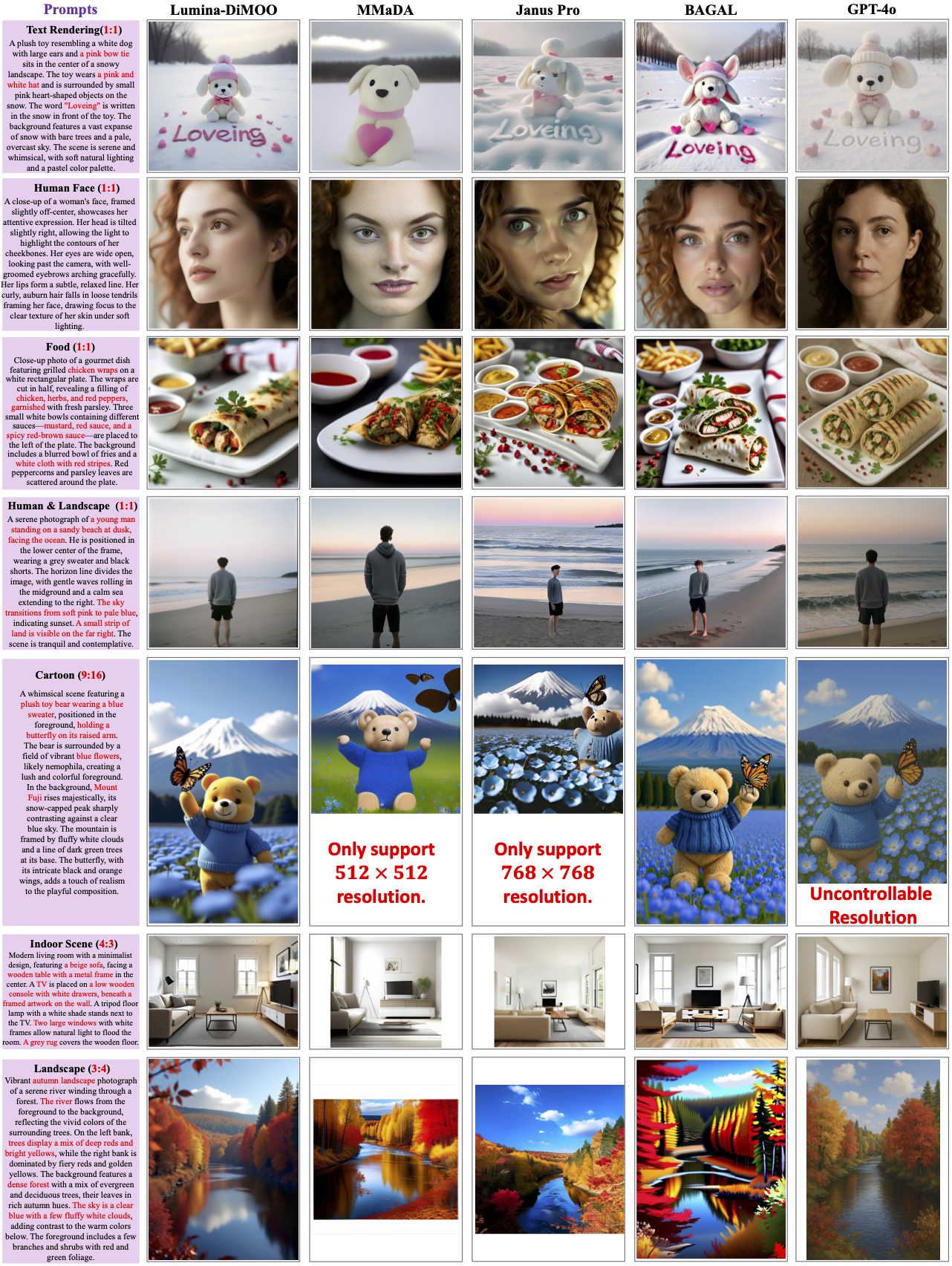
图片编辑对比

可控性与主题驱动生成对比

图像修复与外推

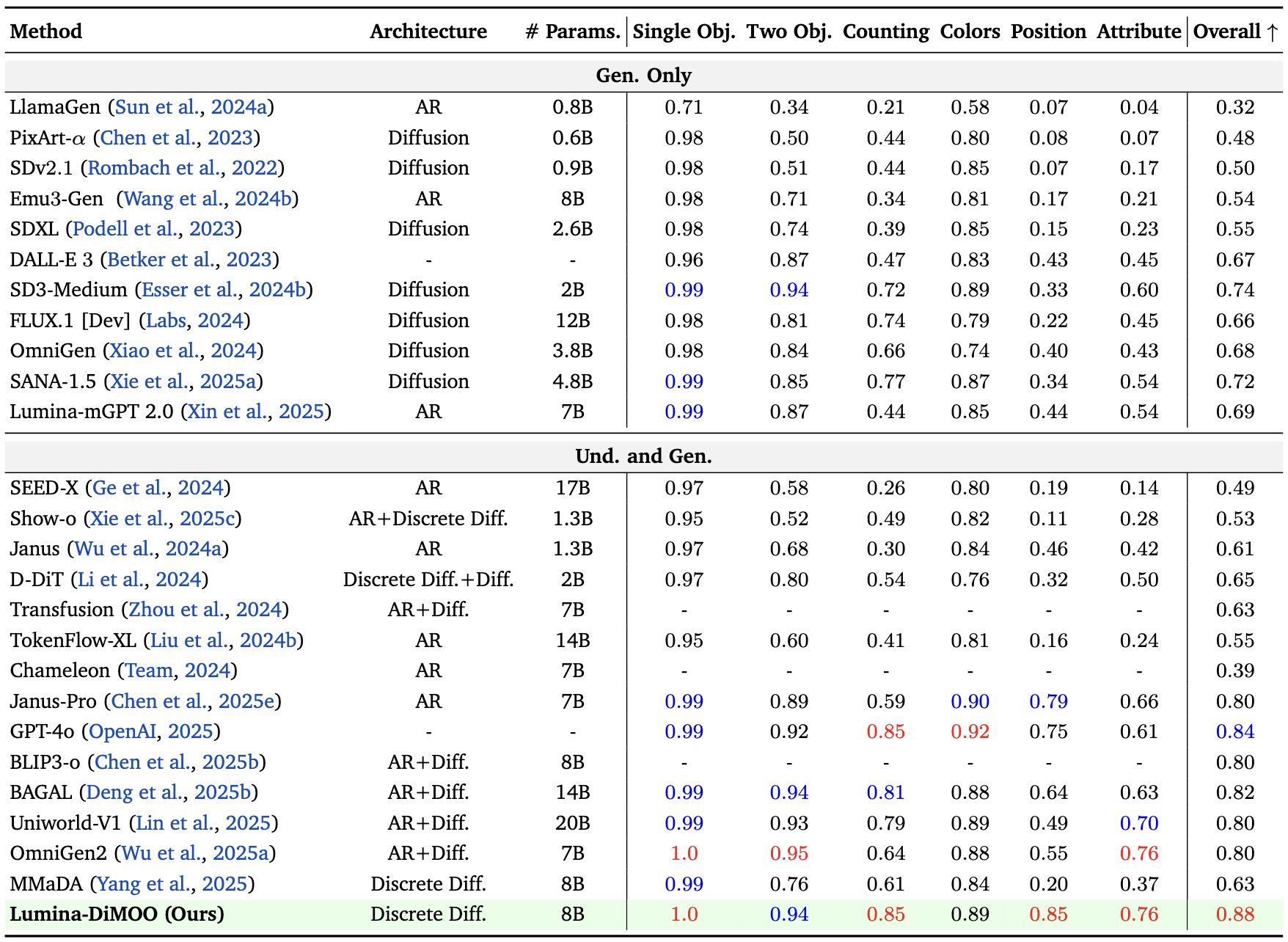
📊 量化表现
GenEval Benchmark
DPG Benchmark
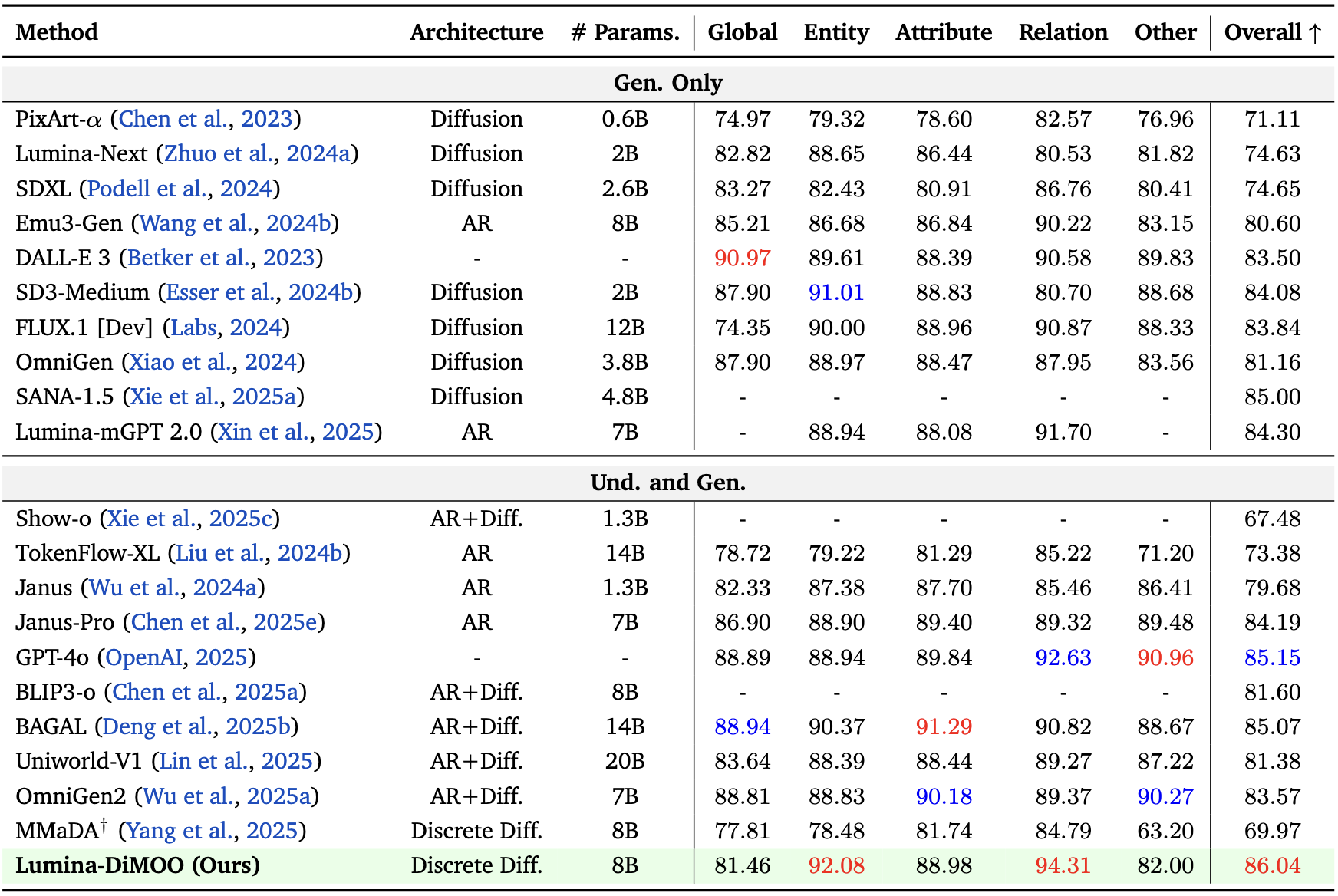
OneIG-EN Benchmark
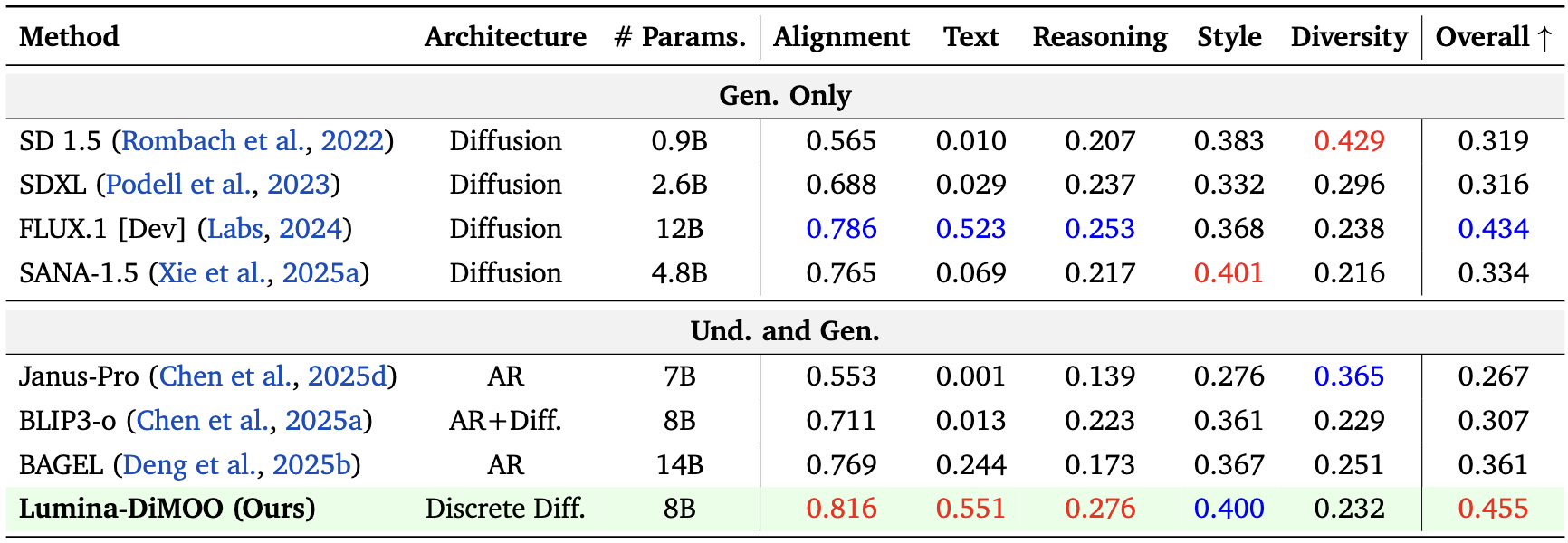
TIIF Benchmark
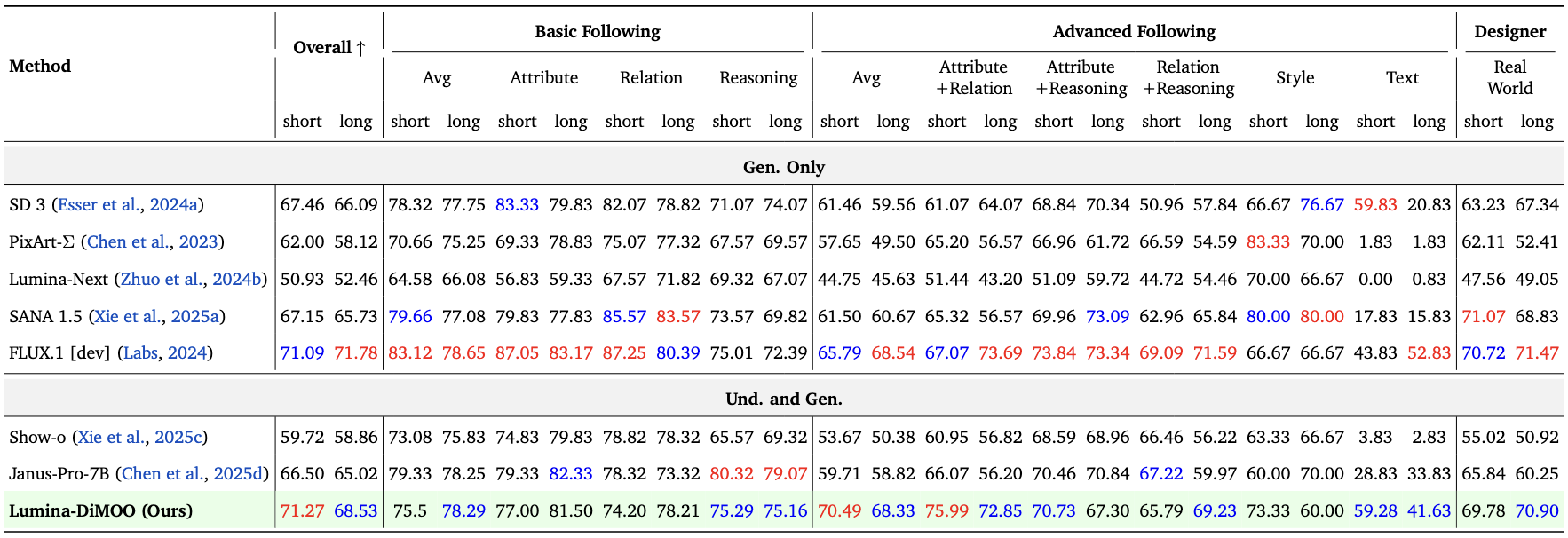
Image-to-Image Benchmark
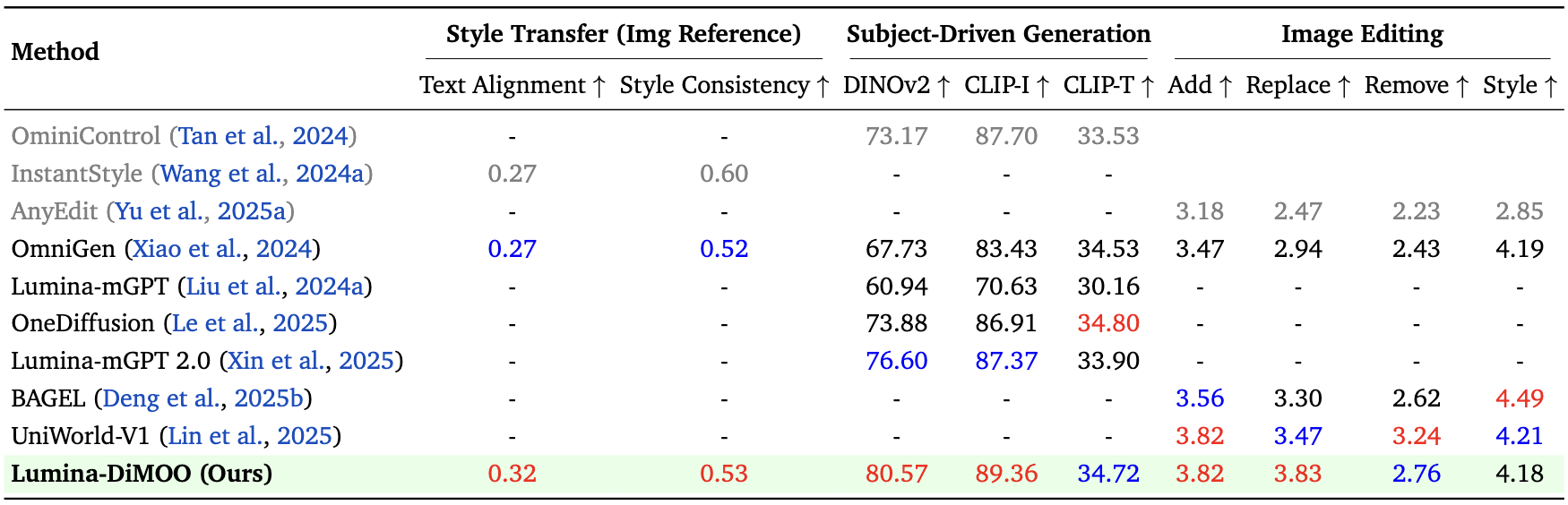
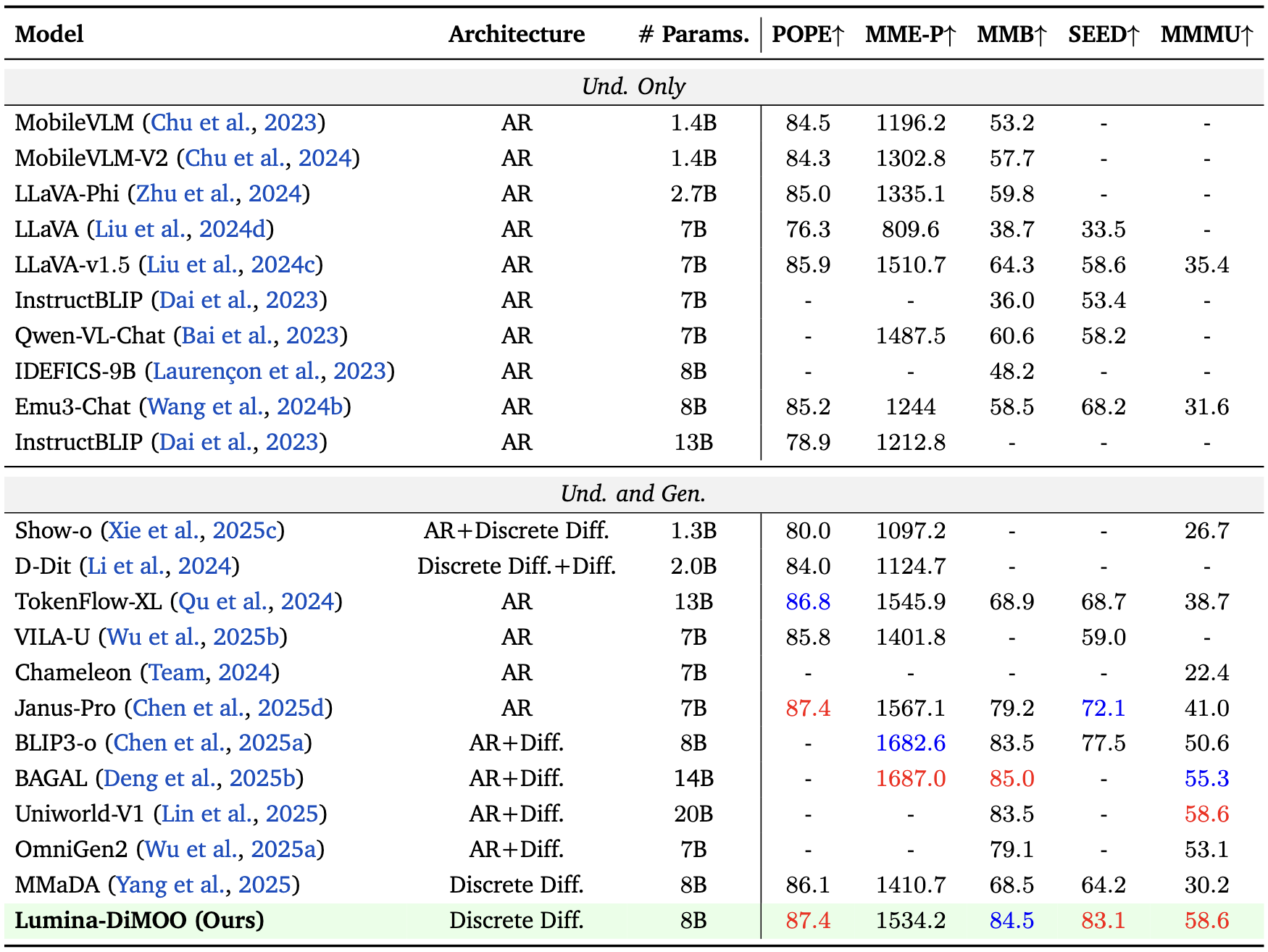
Image Understanding Benchmark
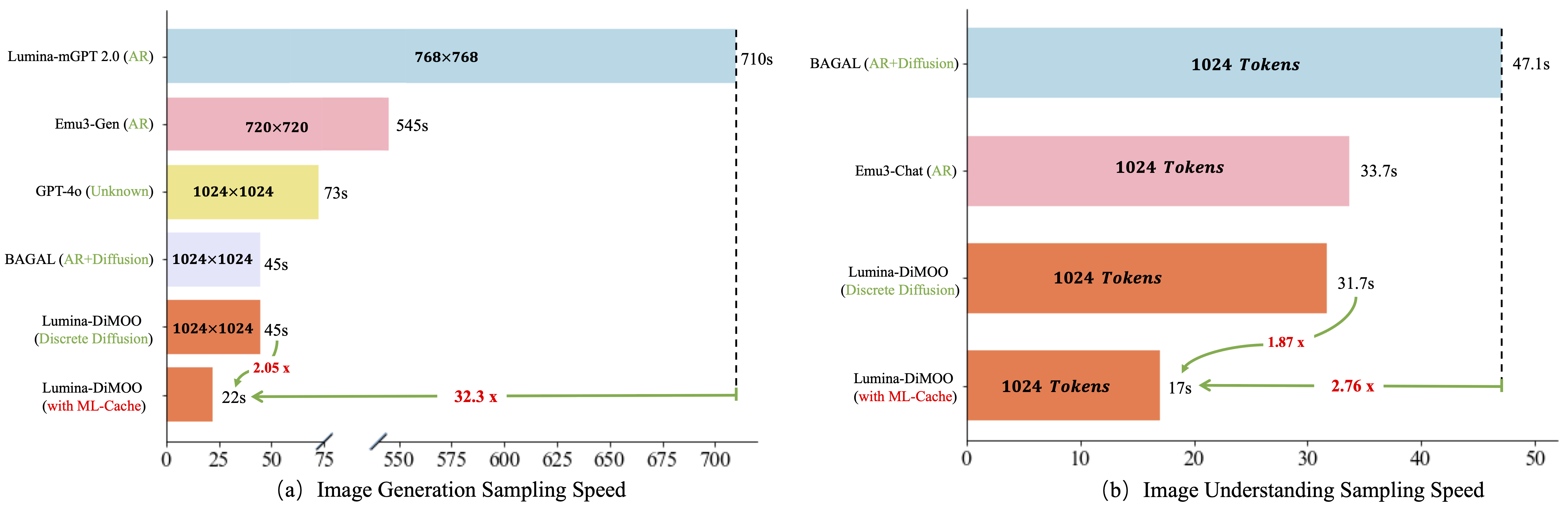
🚀 采样速度分析
-
由于文本生成是以块为单位进行的,与图像生成采用单一全局解码步骤不同,其速度受块数和步数的双重影响。因此,图像理解的速度提升不如图像生成显著。
-
Lumina-DiMOO 设置:图像生成采样64步;图像理解设置块长度为256,采样步数为128。
采样速度对比
📜 致谢
本工作还得到了MindSpeed MM的支持与实现,这是一个由华为计算产品线开发并维护的开源大规模多模态模型训练框架,专为分布式训练而设计。MindSpeed MM特别针对华为昇腾AI芯片进行了优化,为分布式训练提供全面支持,并适用于广泛的多模态任务。