RoboTwin 2.0:一个可扩展的、强领域随机化的数据生成器,用于双臂机器人操作
关键词:#具身智能 #双臂机器人 #benchmark
- 论文题目:RoboTwin 2.0: A Scalable Data Generator and Benchmark with Strong Domain Randomization for Robust Bimanual Robotic Manipulation
- arXiv:2506.18088
- 单位:SJTU & HKU & 上海 AI Lab & D-Robotics & SZU
- https://robotwin-platform.github.io/
- 更多论文每日解读关注 v 公众号:https://mp.weixin.qq.com/s/p7udBkQ7EvgLyeNXe9mNrg

论文速读
- 研究问题 :基于仿真的数据合成已成为增强现实世界机器人操作的强大范式。然而,现有的合成数据集在鲁棒的双臂操作方面仍显不足,主要面临两个挑战:(1)缺乏针对新任务的高效、可扩展的数据生成方法;(2) 仿真环境过于简化, 无法捕捉现实世界的复杂性。
- 研究方法 :本文提出了 RoboTwin 2.0 ,一个可扩展的仿真框架, 能够自动生成大规模、多样且真实的数据, 并提供统一的双臂操作评估协议。通过 MLLM 驱动的自动任务代码生成与 simulation-in-the-loop feedback(包含 VLM 感知诊断)来产出"专家级"轨迹;并在五大维度的强域随机化(domain randomization)下生成大规模、多样化数据,以显著提升策略在未见环境中的鲁棒性与泛化。

RoboTwin 2.0 的 pipeline
本文提出了RoboTwin 2.0,一个可扩展的仿真框架,用于生成多样化、高保真度的专家数据,以支持鲁棒的双臂操作。
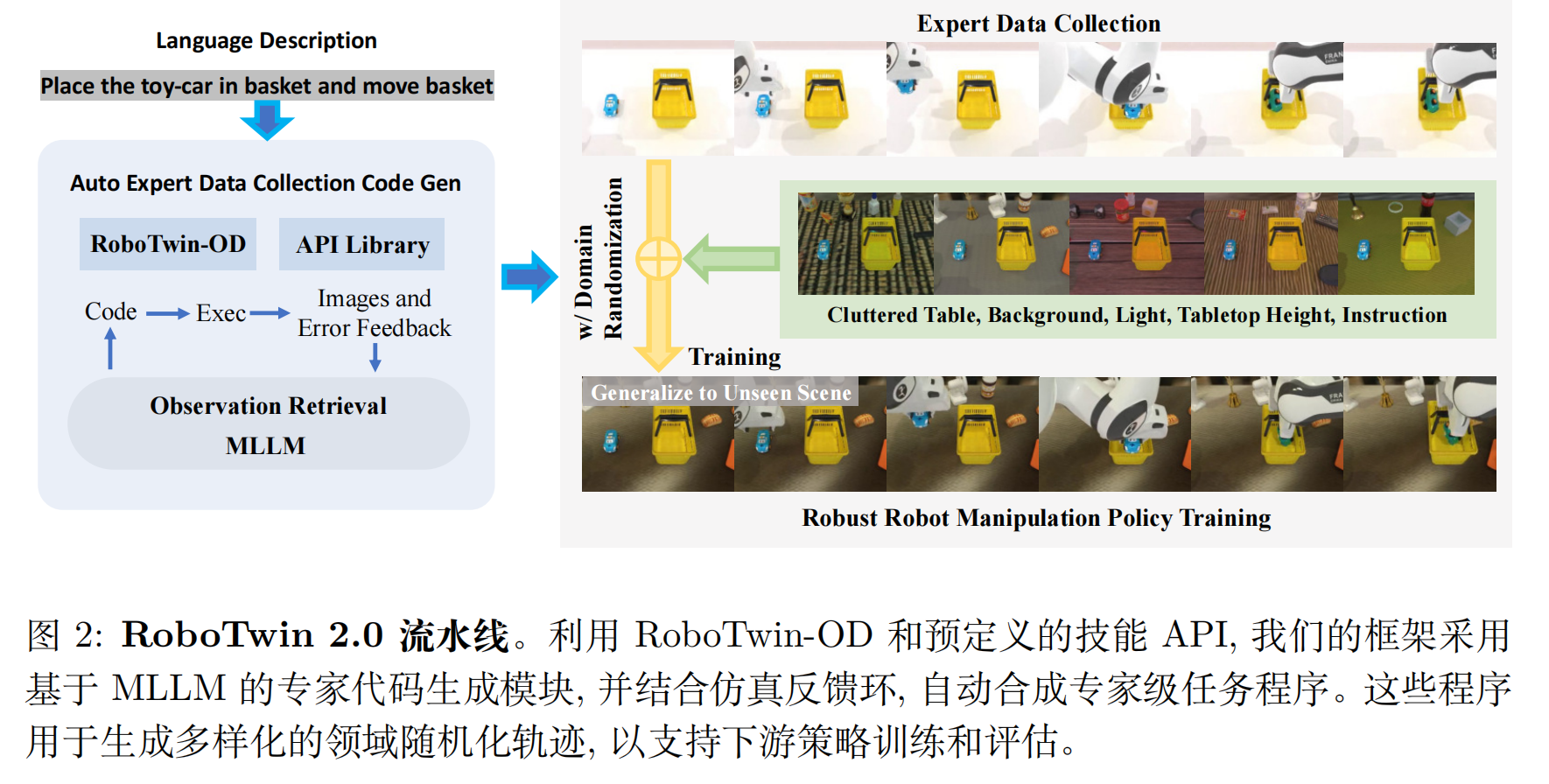
1)自动化专家数据生成流程
近期语言模型的进展展示了其生成复杂机器人任务中间表示的能力------如文本计划、API 调用或可执行代码。基于这一基础,我们提出了一种自动化专家数据生成流水线 ,该流水线将程序化代码合成与多模态执行反馈相结合,以生成高质量的操作程序。如下图所示,该系统通过一个闭环架构运行, 该架构包含两个 AI 智能体:代码生成智能体 和 VLM 观察者。通过在模拟环境中执行和监控代码, 观察者系统地检测执行失败并提出修正建议, 使代码生成智能体能够迭代优化任务程序。这一反馈环促进了在最少人工监督下生成鲁棒、自我改进的专家数据。
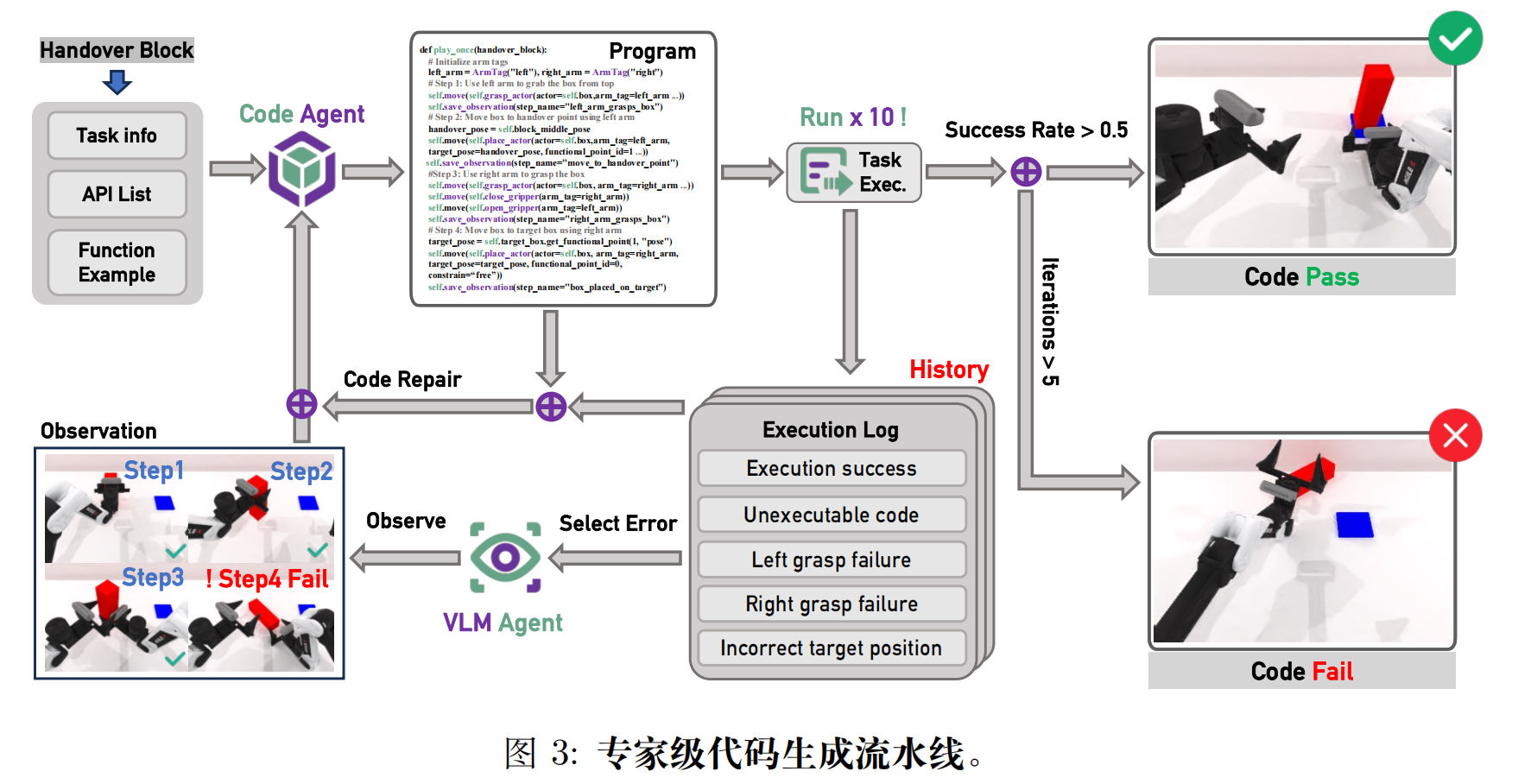
该流水线的成果是一系列强大、自动合成的程序, 它们为下游训练与评估生成高质量专家轨迹。
2)领域随机化实现鲁棒机器人操作
为提高策略对现实环境变化的鲁棒性 , 我们在五个关键维度上应用了领域随机化 :(1) 任务无关物体的杂乱摆放,(2) 背景纹理,(3) 光照条件,(4) 桌面高度, 以及 (5) 多样化的语言指令。这种系统化的多样化丰富了训练数据分布, 并显著提升了对未见场景的泛化能力。

3)体感感知抓取适配
由于自由度和运动结构的不同, 机械臂在执行相同任务时表现出不同的可达工作空间和优选操作策略。例如, 在抓取罐子时,Franka 机械臂通常倾向于采用自顶向下的方式, 而自由度较低的 Piper 机械臂则更适合侧面抓取。因此,Franka 使用自顶向下抓取成功完成的任务, 在用 Piper 执行时可能需要采用侧面方式, 如下图所示。
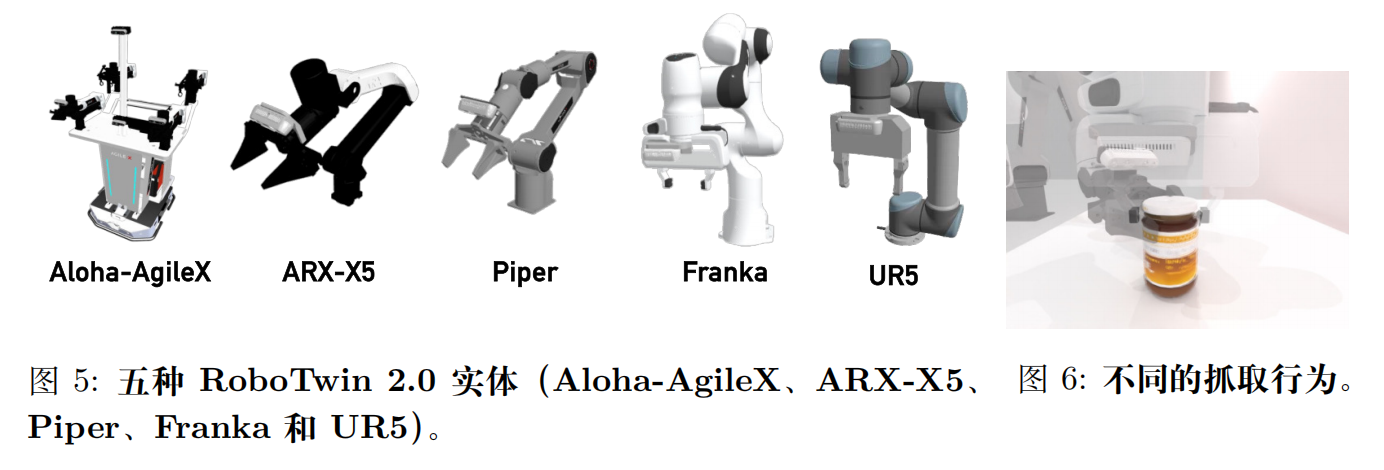
为应对这些具体实现中的差异, 我们为每个物体标注了一系列涵盖多种抓取轴线和接近方向的多样化操作候选方案。这确保了数据集既能捕捉操作多样性, 又能体现机器人特有的偏好。具体而言, 针对每个物体, 我们通过融入首选操作方向、随机姿态扰动及并行运动规划尝试来生成候选抓取方案。此外, 我们还向手臂可达性更高的方向引入角度扰动, 进一步拓展了可行操作姿态的空间。
实验
数据生成
-
构建了一个大规模的对象数据集 RoboTwin-OD,包含 731 个实例,涵盖 147 个类别。每个对象都标注了丰富的语义和操作相关标签。
-
基于 RoboTwin-OD 和预定义的技能 API,生成了 50 多个双臂协作操作任务,并在五个不同的双臂机器人平台上收集了超过 100,000 条双臂操作轨迹。
实验设置
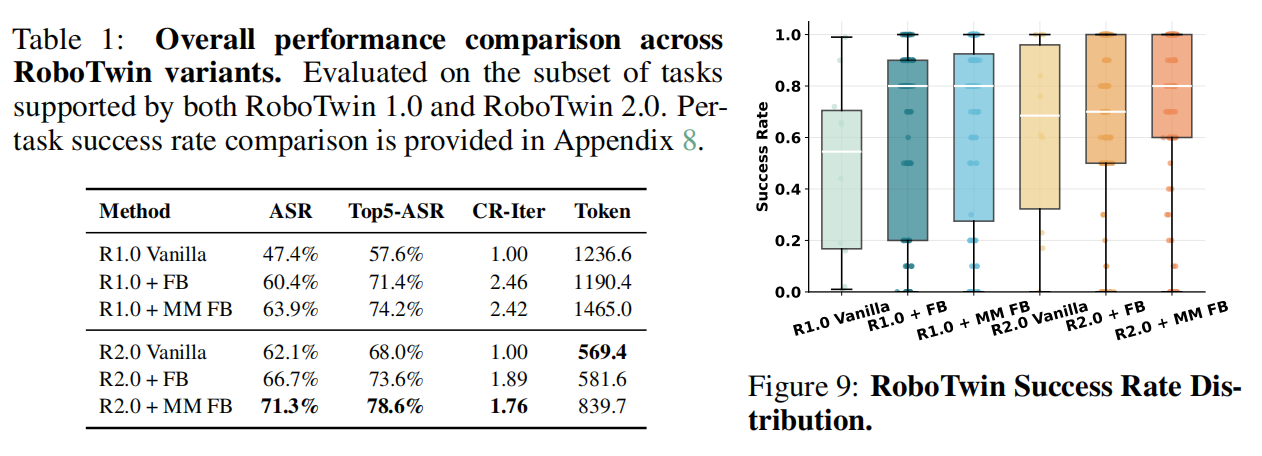
1. 自动化专家代码生成
评估了自动化专家代码生成系统的性能,使用了 10 个机器人操作任务,每个任务都指定了自然语言指令。
每个任务均以自然语言指令指定, 对于每个系统变体, 代码生成智能体生成 10 个候选程序, 每个程序执行 10 次以考虑动力学、控制和感知中的随机性。任务级成功率定义为所有候选程序所有执行的平均成功率。
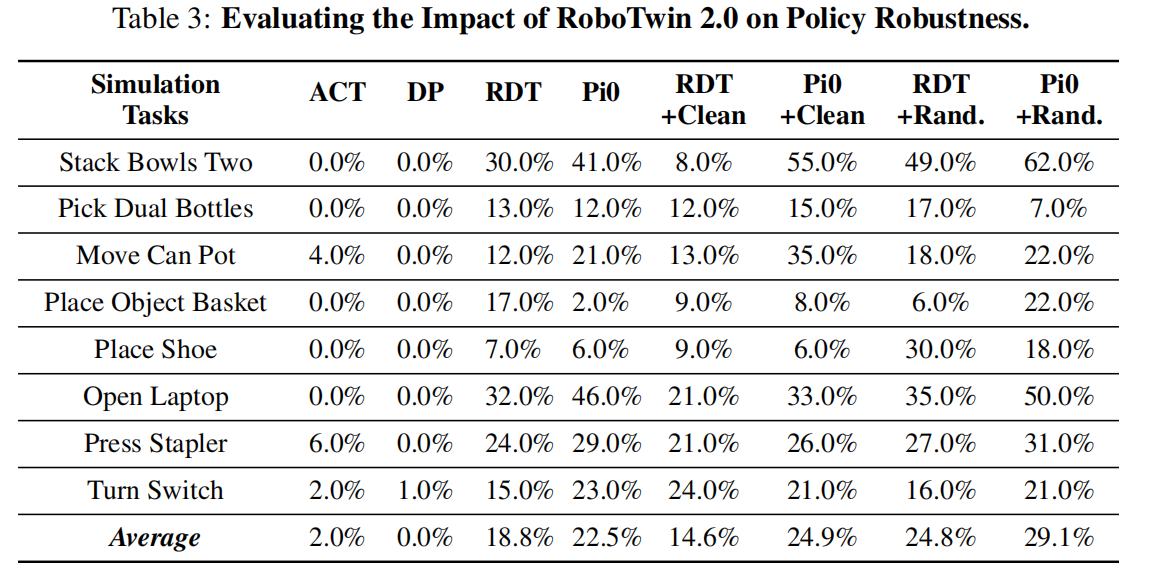
2. 领域随机化对策略鲁棒性的影响
评估了领域随机化对策略鲁棒性的影响,通过在 32 个任务上预训练模型,并在五个未见任务上进行微调。
使用 RoboTwin 2.0 数据进行预训练的模型在未见任务上表现出显著更好的泛化能力,RDT 和 Pi0 分别实现了 31.9% 和 29.3% 的相对改进。
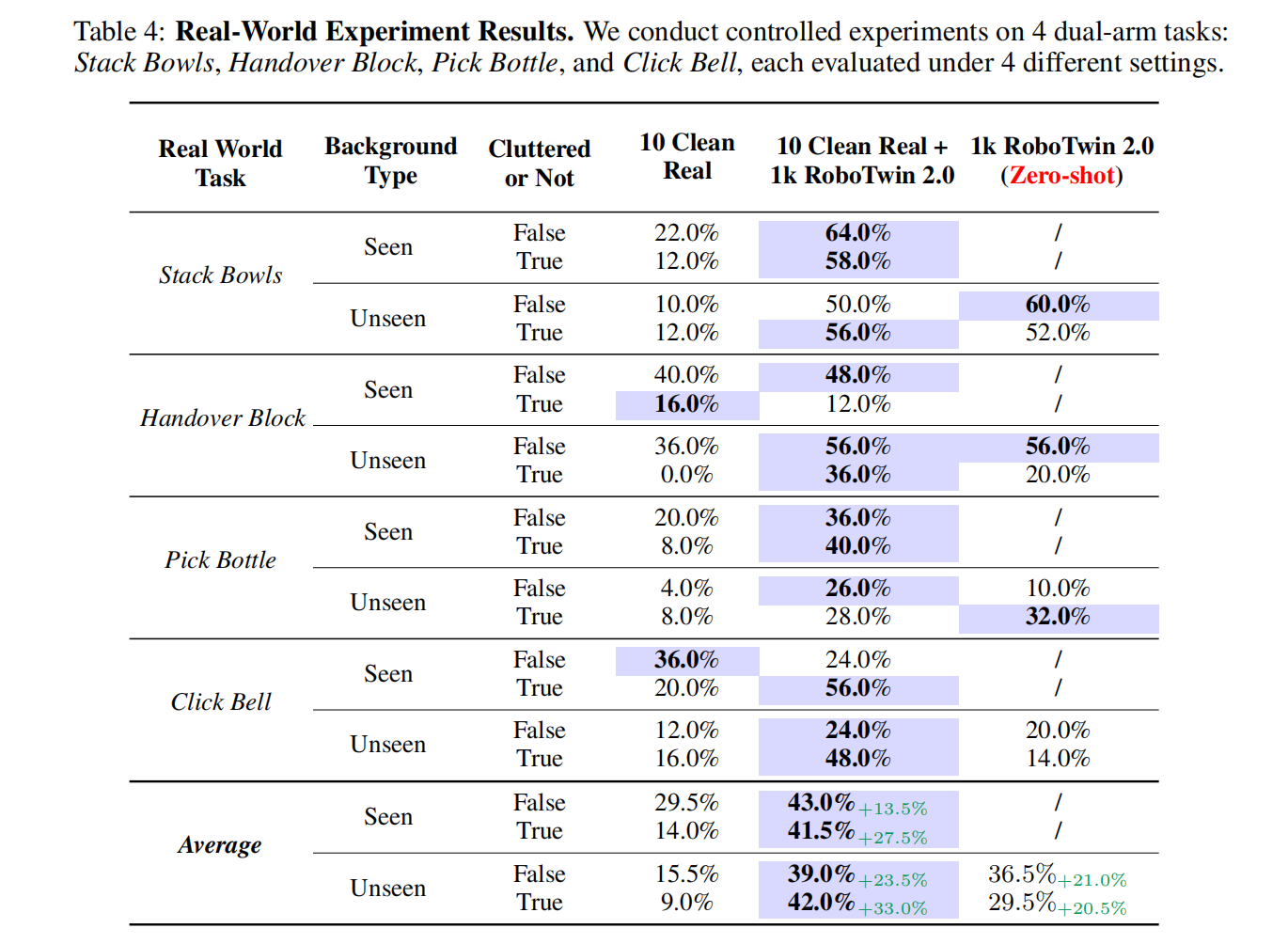
3. 现实世界策略鲁棒性
评估了 RoboTwin 2.0 在增强现实世界策略鲁棒性方面的效果,使用了四种双臂任务,并在不同的测试配置下进行评估。
在现实世界任务中,结合 RoboTwin 2.0 的策略在少量真实演示和大量合成轨迹的训练下,表现出更高的鲁棒性。特别是在视觉复杂场景中,性能提升更为显著。
总结
本文提出了 RoboTwin 2.0,一个可扩展的仿真框架,通过集成 MLLM-based 任务生成、本体适应行为合成和全面的领域随机化,解决了现有合成数据生成方法的局限性。实验结果表明,RoboTwin 2.0 在提高策略对杂乱环境的鲁棒性、对未见任务的泛化能力以及跨本体操作方面具有显著效果。该框架为鲁棒的双臂操作提供了统一的基准和可扩展的仿真到现实管道,未来的工作将重点放在现实世界部署和多对象任务复杂性上。