【RabbitMQ】架构原理、消息丢失、重复消费、顺序消费、事务消息
- 1、RabbitMQ的架构是怎么样的?
-
- [1.1 RabbitMQ是怎么做消息分发的?](#1.1 RabbitMQ是怎么做消息分发的?)
- [1.2 RabbitMQ 是如何保证高可用的?](#1.2 RabbitMQ 是如何保证高可用的?)
- 2、消息丢失问题
-
- [2.1 如何保障消息一定能发送到RabbitMQ?](#2.1 如何保障消息一定能发送到RabbitMQ?)
- [2.2 RabbitMQ如何保证消息不丢?](#2.2 RabbitMQ如何保证消息不丢?)
- 3、重复消费问题
- 4、顺序消费问题
- 5、事务消息
-
- [5.1 介绍下RabbitMQ的事务机制](#5.1 介绍下RabbitMQ的事务机制)
- 6、延时消息
-
- [6.1 什么是RabbitMQ的死信队列?](#6.1 什么是RabbitMQ的死信队列?)
- [6.2 rabbitMQ如何实现延迟消息?](#6.2 rabbitMQ如何实现延迟消息?)
1、RabbitMQ的架构是怎么样的?
RabbitMQ是一个开源的消息中间件,用于在应用程序之间传递消息。它实现了AMQP(高级消息队列协议)并支持其他消息传递协议,例如STOMP(简单文本定向消息协议)和MQTT(物联网协议)。
整体架构大致如下:
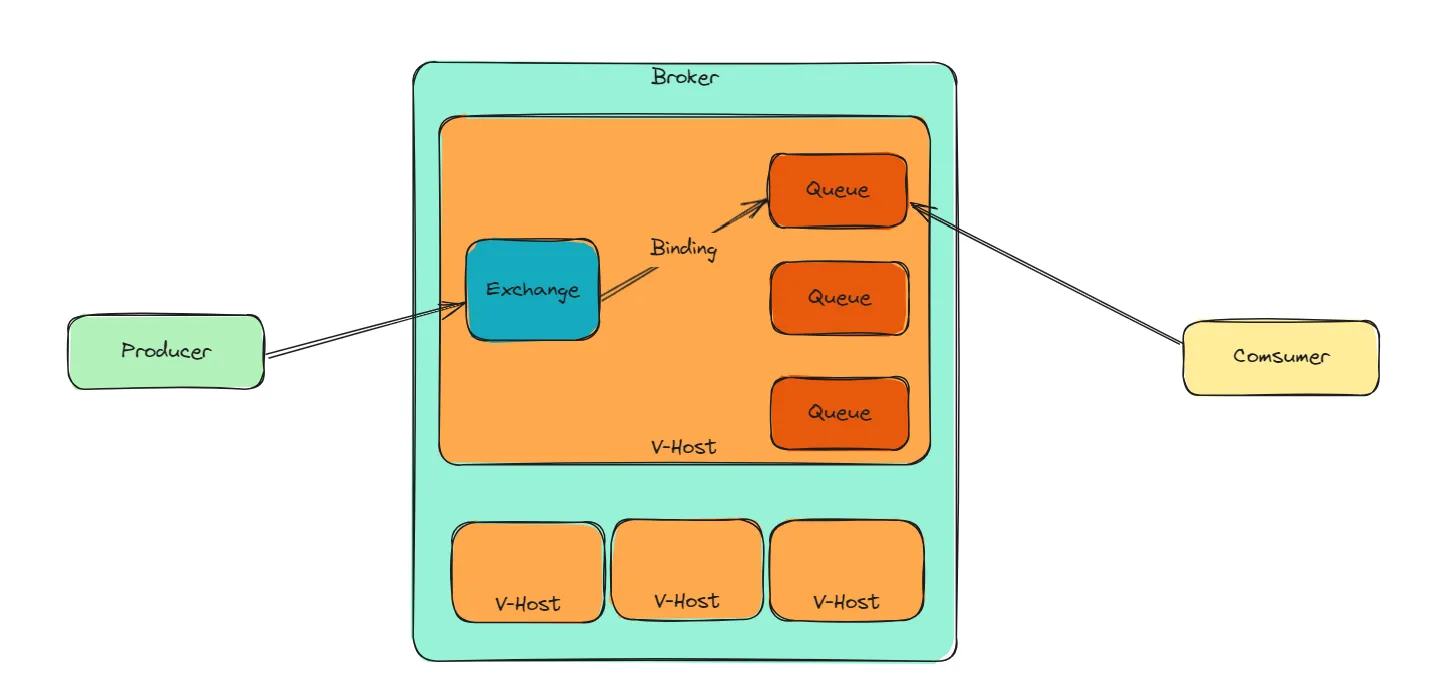
Producer(生产者):生产者是消息的发送方,负责将消息发布到RabbitMQ的交换器(Exchange)。
VHost:是RabbitMQ中虚拟主机的概念,类似于操作系统中的命名空间,用于将RabbitMQ的资源进行隔离和分组。每个VHost拥有自己的交换器、队列、绑定和权限设置,不同VHost之间的资源相互独立,互不干扰。VHost可以用于将不同的应用或服务进行隔离,以防止彼此之间的消息冲突和资源竞争。
Exchange(交换器):交换器是消息的接收和路由中心,它接收来自生产者的消息,并将消息路由到一个或多个与之绑定的队列(Queue)中。
Queue(队列):队列是消息的存储和消费地,它保存着未被消费的消息,等待消费者(Consumer)从队列中获取并处理消息。
Binding(绑定):绑定是交换器和队列之间的关联关系,它定义了交换器将消息路由到哪些队列中。
Consumer(消费者):消费者是消息的接收方,负责从队列中获取消息,并进行处理和消费。
1.1 RabbitMQ是怎么做消息分发的?
rabbitMQ一共有6种工作模式(消息分发方式)分别是简单模式、工作队列模式、发布订阅模式、路由模式、主题模式以及RPC模式。
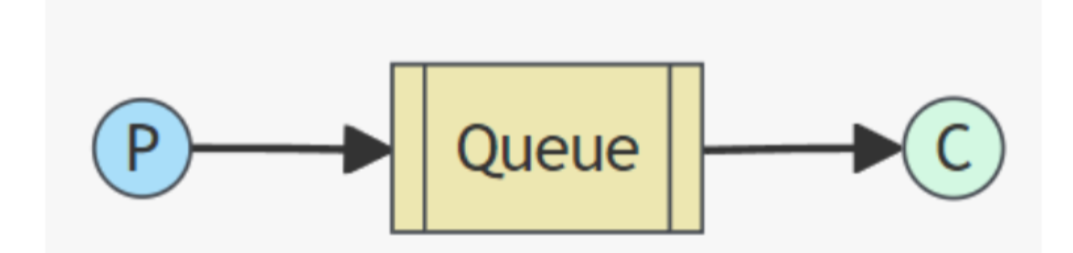
1、Simple(简单模式)
在简单模式中,一个生产者将消息发送到一个队列中,一个消费者从队列中获取并处理消息。这种模式适用于单个生产者和单个消费者的简单场景,消息的处理是同步的。
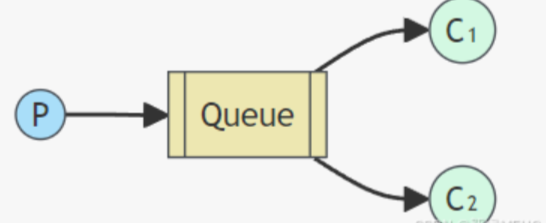
2、Work Queue(工作队列模式)
工作队列模式用于实现一个任务在多个消费者之间的并发处理。在工作队列模式中,一个生产者将消息发送到一个队列中,多个消费者从队列中获取并处理消息。每个消息只能被一个消费者处理。这种模式适用于多个消费者并发处理消息的情况,提高了系统的处理能力和吞吐量。
3、Publish/Subscribe(发布/订阅模式)
发布/订阅模式用于实现一条消息被多个消费者同时接收和处理。在发布/订阅模式中,一个生产者将消息发送到交换器(Exchange)中,交换器将消息广播到所有绑定的队列,每个队列对应一个消费者。这种模式适用于消息需要被多个消费者同时接收和处理的广播场景,如日志订阅和事件通知等。
4、Routing(路由模式)
路由模式用于实现根据消息的路由键(Routing Key)将消息路由到不同的队列中。在路由模式中,一个生产者将消息发送到交换器中,并指定消息的路由键,交换器根据路由键将消息路由到与之匹配的队列中。这种模式适用于根据不同的条件将消息发送到不同的队列中,以实现消息的筛选和分发。
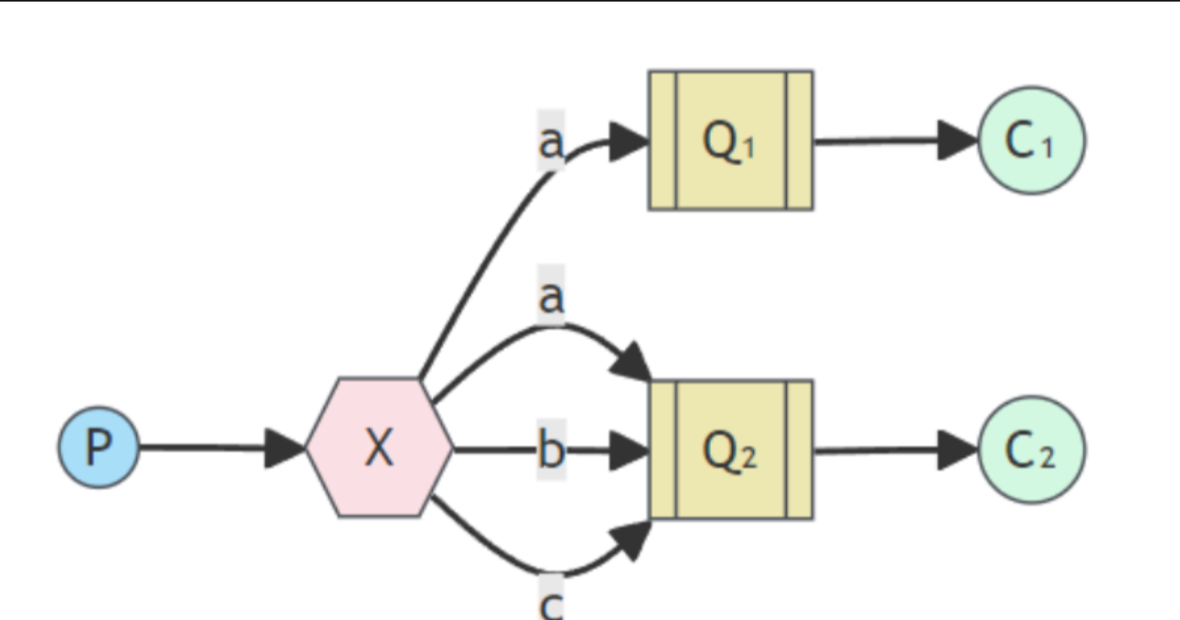
5、Topics(主题模式)
主题模式是一种更灵活的消息路由模式,它使用通配符匹配路由键,将消息路由到多个队列中。在主题模式中,一个生产者将消息发送到交换器中,并指定主题(Topic)作为路由键,交换器根据通配符匹配将消息路由到与之匹配的队列中。这种模式适用于消息的复杂路由需求,可以实现高度灵活的消息筛选和分发。
6、RPC通信模式
RPC模式是一种用于实现分布式系统中远程调用的工作模式。指的是通过rabbitMQ来实现一种RPC的能力。
1.2 RabbitMQ 是如何保证高可用的?
RabbitMQ可以通过多种方式来实现高可用性,以确保在硬件故障或其他不可预测的情况下,消息队列系统仍然能够正常运行。RabbitMQ有三种模式:单机模式、普通集群模式、镜像集群模式。
其中单机模式一般用于demo搭建,不适合在生产环境中使用。剩下的集群模式和镜像模式都可以帮助我们实现不同程度的高可用。
1、普通集群模式
普通集群模式,就是将 RabbitMQ 实例部署到多台服务器上,多个实例之间协同工作,共享队列和交换机的元数据,并通过内部通信协议来协调消息的传递和管理。
在这种模式下,我们创建的Queue,它的元数据(配置信息)会在集群中的所有实例间进行同步,但是队列中的消息只会存在于一个 RabbitMQ 实例上,而不会同步到其他队列。
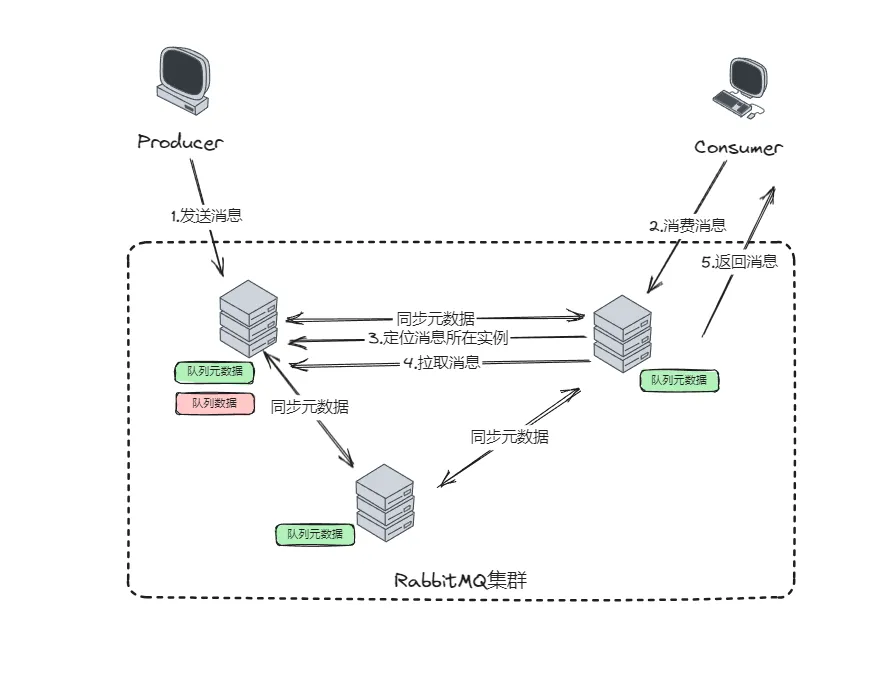
当我们消费消息的时候,如果消费者连接到了未保存消息的实例,那么那个实例会通过元数据定位到消息所在的实例,拉取数据过来发送给消费者进行消费。
消息的发送也是一样的,当发送者连接到了一个不保存消息的实例时,也会被转发到保存消息的实例上进行写操作。
这种集群模式下,每一个实例中的元数据是一样的,大家都是完整的数据。但是队列中的消息数据,在不同的实例上保存的是不一样的。这样通过增加实例的方式就可以提升整个集群的消息存储量,以及性能。
这种方式在高可用上有一定的帮助,不至于一个节点挂了就全都挂了。但是也还有缺点,至少这个实例上的数据是没办法被读写了。
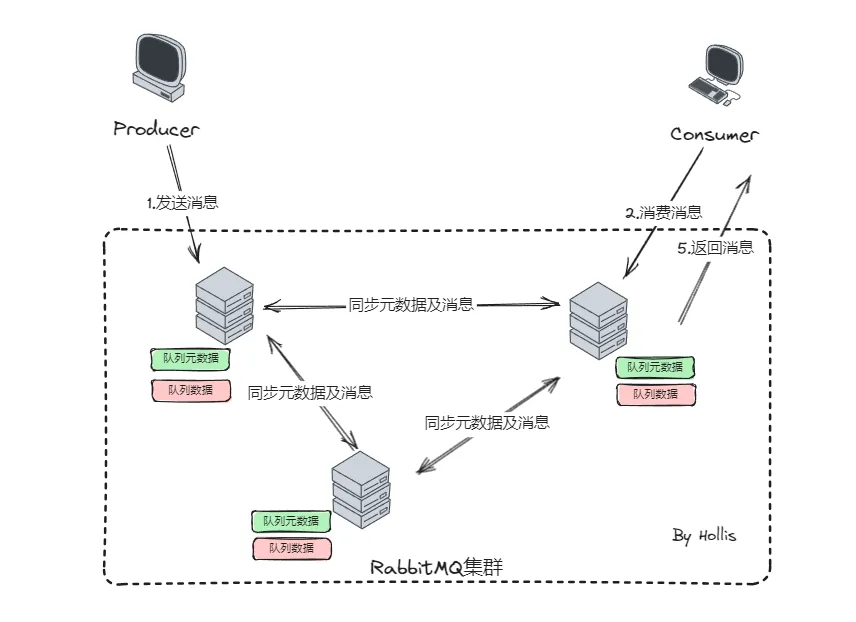
2、镜像模式
顾名思义,就是每一台RabbitMQ都像一个镜像一样,存储的内容都是一样的。这种模式下,Queue的元数据和消息数据不再是单独存储在某个实例上,而是集群中的所有实例上都存储一份。
这样每次在消息写入的时候,就需要在集群中的所有实例上都同步一份,这样即使有一台实例发生故障,剩余的实例也可以正常提供完整的数据和服务。
2、消息丢失问题
2.1 如何保障消息一定能发送到RabbitMQ?
作为消息发送方,如何保证给RabbitMQ发送的消息一定能发送成功,如何确保他一定能收到这个消息?
RabbitMQ的消息最终是存储在Queue上的,而在Queue之前还要经过Exchange,那么这个过程中就有两个地方可能导致消息丢失。第一个是Producer到Exchange的过程,第二个是Exchange到Queue的过程。
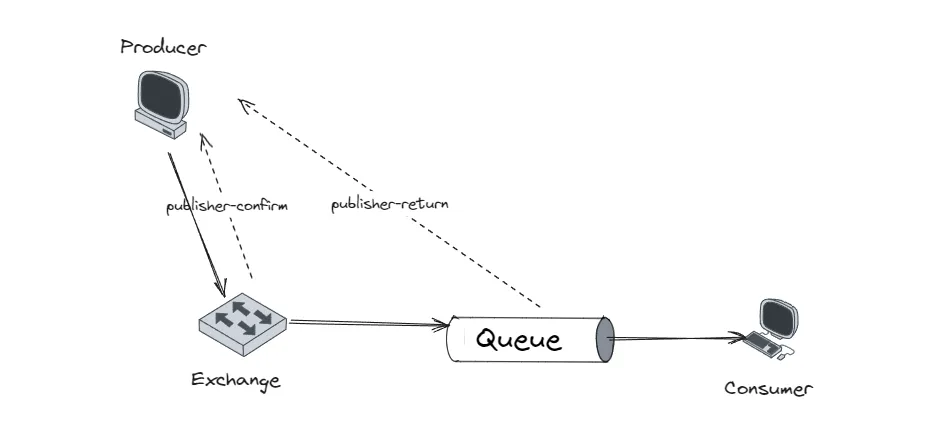
上面两个可能丢失的过程,都可以利用confirm机制,注册回调来监听是否成功。
Publisher Confirm是一种机制,用于确保消息已经被Exchange成功接收和处理。一旦消息成功到达Exchange并被处理,RabbitMQ会向消息生产者发送确认信号(ACK)。如果由于某种原因(例如,Exchange不存在或路由键不匹配)消息无法被处理,RabbitMQ会向消息生产者发送否认信号(NACK)。
java
// 启用Publisher Confirms
channel.confirmSelect();
// 设置Publisher Confirms回调
channel.addConfirmListener(new ConfirmListener() {
@Override
public void handleAck(long deliveryTag, boolean multiple) throws IOException {
System.out.println("Message confirmed with deliveryTag: " + deliveryTag);
// 在这里处理消息确认
}
@Override
public void handleNack(long deliveryTag, boolean multiple) throws IOException {
System.out.println("Message not confirmed with deliveryTag: " + deliveryTag);
// 在这里处理消息未确认
}
});Publisher Returns机制与Publisher Confirms类似,但用于处理在消息无法路由到任何队列时的情况。当RabbitMQ在无法路由消息时将消息返回给消息生产者,但是如果能正确路由,则不会返回消息。
java
// 启用Publisher Returns
channel.addReturnListener(new ReturnListener() {
@Override
public void handleReturn(int replyCode, String replyText, String exchange, String routingKey, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("Message returned with replyCode: " + replyCode);
// 在这里处理消息发送到Queue失败的返回
}
});通过以上方式,注册了两个回调监听,用于在消息发送到Exchange或者Queue失败时进行异常处理。通常可以在失败时进行报警或者重试来保障一定能发送成功。
2.2 RabbitMQ如何保证消息不丢?
上面介绍了如何确保RabbitMQ的发送者把消息能够投递给RabbitMQ的Exchange和Queue,那么,Queue又是如何保证消息能不丢的呢?
RabbitMQ在接收到消息后,默认并不会立即进行持久化,而是先把消息暂存在内存中,这时候如果MQ挂了,那么消息就会丢失。所以需要通过持久化机制来保证消息可以被持久化下来。
1、队列和交换机的持久化
在声明队列时,可以通过设置durable参数为true来创建一个持久化队列。持久化队列会在RabbitMQ服务器重启后保留,确保队列的元数据不会丢失。
在声明交换机时,也可以通过设置durable参数为true来创建一个持久化交换机。持久化交换机会在RabbitMQ服务器重启后保留,以确保交换机的元数据不会丢失。
绑定关系通常与队列和交换机相关联。当创建绑定关系时,还是可以设置durable参数为true,以创建一个持久化绑定。持久化绑定关系会在服务器重启后保留,以确保绑定关系不会丢失。
java
@Bean
public Queue TestQueue() {
// 第二个参数durable:是否持久化,默认是false
return new Queue("queue-name",true,true,false);
}
@Bean
public DirectExchange mainExchange() {
//第二个参数durable:是否持久化,默认是false
return new DirectExchange("main-exchange",true,false);
}2、持久化消息
生产者发送的消息可以通过设置消息的deliveryMode为2来创建持久化消息。持久化消息在发送到持久化队列后,将在服务器重启后保留,以确保消息不会丢失。
deliveryMode是一项用于设置消息传递模式的属性,用于指定消息的持久性级别:
1(非持久化):这是默认的传递模式。如果消息被设置为非持久化,RabbitMQ将尽力将消息传递给消费者,但不会将其写入磁盘,这意味着如果RabbitMQ服务器在消息传递之前崩溃或重启,消息可能会丢失。
2(持久化):如果消息被设置为持久化,RabbitMQ会将消息写入磁盘,以确保即使在RabbitMQ服务器重启时,消息也不会丢失。持久化消息对于重要的消息非常有用,以确保它们不会在传递过程中丢失。
3、消费者确认机制
有了持久化机制后,那么怎么保证消息在持久化下来之后一定能被消费者消费呢?这里就涉及到消息的消费确认机制。
在RabbitMQ中,消费者处理消息成功后可以向MQ发送ack回执,MQ收到ack回执后才会删除该消息,这样才能确保消息不会丢失。如果消费者在处理消息中出现了异常,那么就会返回nack回执,MQ收到回执之后就会重新投递一次消息,如果消费者一直都没有返回ACK/NACK的话,那么他也会在尝试重新投递。
4、无法做到100%不丢
虽然我们通过发送者端进行异步回调、MQ进行持久化、消费者做确认机制,但是也没办法保证100%不丢,因为MQ的持久化过程其实是异步的。即使我们开了持久化,也有可能在内存暂存成功后,异步持久化之前宕机了,那么这个消息就会丢失。
如果想要做到100%不丢失,就需要引入本地消息表,来通过轮询的方式来进行消息重投。
3、重复消费问题
RabbitMQ的消息消费是有确认机制的,正常情况下,消费者在消费消息消费成功后,会发送一个确认消息,消息队列接收到之后,就会将该消息从消息队列中删除,下次也就不会再投递了。
但是如果存在网络延迟的问题,导致确认消息没有发送到消息队列,导致消息重投了,是有可能的。所以,当我们使用MQ的时候,消费者端自己也需要做好幂等控制来防止消息被重复消费。
一般来说,处理这种幂等问题就是:一锁、二判、三更新。
4、顺序消费问题
根据路由键将消息路由到指定队列,队列对应多个消费者。通过 basicQos(1) 保证每个消费者一次只处理一条消息,做到顺序消费的同时,保证消费能力。
5、事务消息
5.1 介绍下RabbitMQ的事务机制
想要保证发送者一定能把消息发送给RabbitMQ,一种是通过confirm机制,另外一种就是通过事务机制。
RabbitMQ的事务机制,允许生产者将一组操作打包成一个原子事务单元,要么全部执行成功,要么全部失败。事务提供了一种确保消息完整性的方法,但需要谨慎使用,因为它们对性能有一定的影响。
因为事务机制是同步的,提交一个事务之后会阻塞在那儿,但是 confirm机制是异步的,发送一个消息之后就可以发送下一个消息,RabbitMQ 接收了之后会异步回调confirm接口通知这个消息接收到了。一般在生产者这块避免数据丢失,建议使用用 confirm 机制。
RabbitMQ是基于AMQP协议实现的,RabbitMQ中,事务是通过在通道(Channel)上启用的,与事务机制有关的方法有三个:
● txSelect():将当前channel设置成transaction模式。
● txCommit():提交事务。
● txRollback():回滚事务。
我们需要先通过txSelect开启事务,然后就可以发布消息给MQ了,如果txCommit提交成功了,则消息一定到达了RabbitMQ,如果在txCommit执行之前RabbitMQ实例异常崩溃或者抛出异常,那我们就可以捕获这个异常然后执行txRollback进行回滚事务。
所以, 通过事务机制,我们也能保证消息一定可以发送给RabbitMQ。
以下,是一个通过事务发送消息的方法示例:
java
import com.rabbitmq.client.*;
public class RabbitMQTransactionExample {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
// 启用事务
channel.txSelect();
String exchangeName = "my_exchange";
String routingKey = "my_routing_key";
try {
// 发送第一条消息
String message1 = "Transaction Message 1";
channel.basicPublish(exchangeName, routingKey, null, message1.getBytes());
// 发送第二条消息
String message2 = "Transaction Message 2";
channel.basicPublish(exchangeName, routingKey, null, message2.getBytes());
// 模拟一个错误
int x = 1 / 0;
// 提交事务(如果没有发生错误)
channel.txCommit();
System.out.println("Transaction committed.");
} catch (Exception e) {
// 发生错误,回滚事务
channel.txRollback();
System.err.println("Transaction rolled back.");
}
}
}
}6、延时消息
6.1 什么是RabbitMQ的死信队列?
RabbitMQ的死信队列(Dead Letter Queue,简称DLQ)是一种用于处理消息处理失败或无法路由的消息的机制。它允许将无法被正常消费的消息重新路由到另一个队列,以便稍后进行进一步的处理、分析或排查问题。
当消息队列里面的消息出现以下几种情况时,就可能会被称为"死信":
- 消息处理失败:当消费者由于代码错误、消息格式不正确、业务规则冲突等原因无法成功处理一条消息时,这条消息可以被标记为死信。
- 消息过期:在RabbitMQ中,消息可以设置过期时间。如果消息在规定的时间内没有被消费,它可以被认为是死信并被发送到死信队列。
- 消息被拒绝:当消费者明确拒绝一条消息时,它可以被标记为死信并发送到死信队列。拒绝消息的原因可能是消息无法处理,或者消费者认为消息不符合处理条件。
- 消息无法路由:当消息不能被路由到任何队列时,例如,没有匹配的绑定关系或路由键时,消息可以被发送到死信队列。
当消息变成"死信"之后,如果配置了死信队列,它将被发送到死信交换机,死信交换机将死信投递到一个队列上,这个队列就是死信队列。但是如果没有配置死信队列,那么这个消息将被丢弃。
RabbitMQ的死信队列其实有很多作用,比如我们可以借助他实现延迟消息,进而实现订单的到期关闭,超时关单等业务逻辑。
6.2 rabbitMQ如何实现延迟消息?
RabbitMQ中是可以实现延迟消息的,一般有两种方式,分别是通过死信队列以及通过延迟消息插件来实现。
1、死信队列
当RabbitMQ中的一条正常的消息,因为过了存活时间(TTL过期)、队列长度超限、被消费者拒绝等原因无法被消费时,就会变成Dead Message,即死信。
当一个消息变成死信之后,他就能被重新发送到死信队列中(其实是交换机-exchange)。
那么基于这样的机制,就可以实现延迟消息了。那就是我们给一个消息设定TTL,但是并不消费这个消息,等他过期,过期后就会进入到死信队列,然后我们再监听死信队列的消息消费就行了。
而且,RabbitMQ中的这个TTL是可以设置任意时长的,这相比于RocketMQ只支持一些固定的时长而显得更加灵活一些。
但是,死信队列的实现方式存在一个问题,那就是可能造成队头阻塞。RabbitMQ会定期扫描队列的头部,检查队首的消息是否过期。如果队首消息过期了,它会被放到死信队列中。然而,RabbitMQ不会逐个检查队列中的所有消息是否过期,而是仅检查队首消息。这样,如果队列的队头消息未过期,而它后面的消息已过期,这些后续消息将无法被单独移除,直到队头的消息被消费或过期。
因为队列是先进先出的,在普通队列中的消息,每次只会判断队头的消息是否过期,那么,如果队头的消息时间很长,一直都不过期,那么就会阻塞整个队列,这时候即使排在他后面的消息过期了,那么也会被一直阻塞。
基于RabbitMQ的死信队列,可以实现延迟消息,非常灵活的实现定时关单,并且借助RabbitMQ的集群扩展性,可以实现高可用,以及处理大并发量。他的缺点第一是可能存在消息阻塞的问题,还有就是方案比较复杂,不仅要依赖RabbitMQ,而且还需要声明很多队列出来,增加系统的复杂度。
2、RabbitMQ插件
其实,基于RabbitMQ的话,可以不用死信队列也能实现延迟消息,那就是基于rabbitmq_delayed_message_exchange插件,这种方案能够解决通过死信队列实现延迟消息出现的消息阻塞问题。但是该插件从RabbitMQ的3.6.12开始支持的,所以对版本有要求。
这个插件是官方出的,可以放心使用,安装并启用这个插件之后,就可以创建x-delayed-message类型的交换机了。
基于死信队列的方式,是消息先会投递到一个正常队列,在TTL过期后进入死信队列。但是基于插件的这种方式,消息并不会立即进入队列,而是先把他们保存在一个基于Erlang开发的Mnesia数据库中,然后通过一个定时器去查询需要被投递的消息,再把他们投递到x-delayed-message交换机中。
基于RabbitMQ插件的方式可以实现延迟消息,并且不存在消息阻塞的问题,但是因为是基于插件的,而这个插件支持的最大延长时间是(2^32)-1 毫秒,大约49天,超过这个时间就会被立即消费。
不过这个方案也有一定的限制,它将延迟消息存在于 Mnesia 表中,并且在当前节点上具有单个磁盘副本,存在丢失的可能。
目前该插件的当前设计并不真正适合包含大量延迟消息(例如数十万或数百万)的场景,详情参见 #/issues/72 另外该插件的一个可变性来源是依赖于 Erlang 计时器,在系统中使用了一定数量的长时间计时器之后,它们开始争用调度程序资源,并且时间漂移不断累积。
参考链接:
1、https://www.yuque.com/hollis666/wk6won/qh56y0u8fs2gom42
2、https://www.yuque.com/hollis666/wk6won/lllwvk