聚类后的分析:推断簇的类型
知识点回顾:
- 推断簇含义的2个思路:先选特征和后选特征
- 通过可视化图形借助ai定义簇的含义
- 科研逻辑闭环:通过精度判断特征工程价值
知识点补充:
由AI辅助归纳
KMeans 的基本思路(算法过程)
- 随机选 K 个初始中心点
- 分配样本到最近的中心(按欧氏距离)
- 更新中心:计算每个簇的平均值作为新中心
- 重复步骤 2--3,直到中心不再变化(收敛)
最终得到:
- 每个样本所属的簇标签(
labels_); - 每个簇的中心点坐标(
cluster_centers_); - 聚类的总误差(
inertia_)。
Principal Component Analysis
( PCA主成分分析) 是一种降维算法,主要作用是:用尽量少的维度,保留尽可能多的数据信息。帮助你把高维聚类结果投影成低维图像方便看。
- 自动找到"信息量最大"的方向;
- 重新建立两个新的坐标轴;
- 让这两个轴尽可能解释原始数据的大部分方差信息。
题目跟练:
思路:最开始用全部特征来聚类,把其余特征作为 x,聚类得到的簇类别作为标签构建监督模型,进而根据重要性筛选特征,来确定要根据哪些特征赋予含义。
---使用于你想构造什么,目前还不清楚。
这里是把把 KMeans 聚类得到的簇标签(KMeans_Cluster)当作目标变量 y1,用来反向分析原始特征 X 哪些对区分这些簇最重要。再用SHAP来评判哪些特征的贡献值/重要性最大。
++shap_values++返回的是一个"贡献矩阵:每个样本的每个特征在预测目标值时贡献了多少(正向/负向)
python
# %%赋予簇实际意义
#此处思路:最开始用全部特征来聚类,把其余特征作为 x,聚类得到的簇类别作为标签构建监督模型,
# 进而根据重要性筛选特征,来确定要根据哪些特征赋予含义。---使用于你想构造什么,目前还不清楚。
print(X.columns)
#把 KMeans 聚类得到的簇标签(KMeans_Cluster)当作"目标变量 y",用来反向分析原始特征 X 哪些对区分这些簇最重要。
x1 = X.drop('KMeans_Cluster',axis=1) ## 删除聚类标签列
y1 = X['KMeans_Cluster']
#构建随机森林,用SHAP重要性来筛选
import shap
import numpy as np
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(x1,y1) # 训练模型,此时无需在意准确率 直接全部数据用来训练了
#shap.initjs()初始化 JavaScript 前端环境,让 SHAP 的交互式图(比如 summary_plot、force_plot)
# 能在 Jupyter Notebook / VS Code / JupyterLab 等环境中正常显示.
shap.initjs()
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(x1) # 这个计算耗时
print(shap_values.shape) #第一维是样本数,第二维是特征数,第三维是类别数
#shap_values返回的是一个"贡献矩阵:每个样本的每个特征在预测目标值时贡献了多少(正向/负向)
# %%
# --- 1. SHAP 特征重要性条形图 (Summary Plot - Bar) ---
#x1告诉你这些SHAP值对应的原始特征列是什么
#shap_values[:, :, 0] 的每一行代表的是一个特定样本每个特征对于类别0的贡献值(SHAP值)。
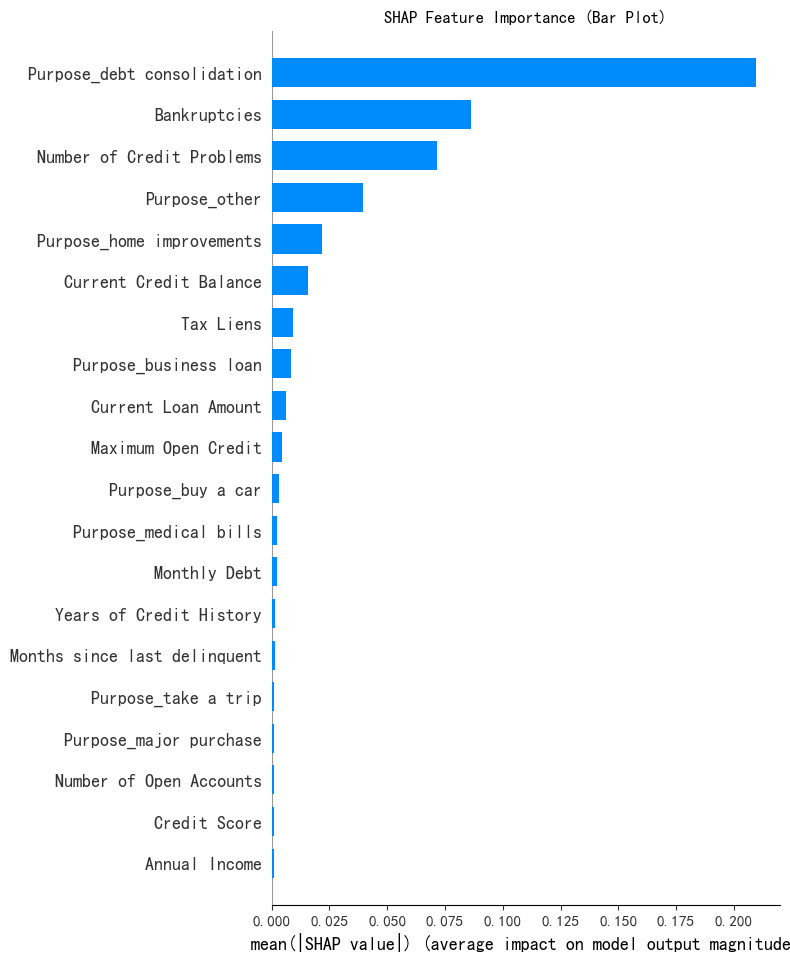
shap.summary_plot(shap_values[:,:,0],x1,plot_type="bar",show=False)
plt.title("SHAP Feature Importance (Bar Plot)")
plt.show()
#shap_values[:, :, 1] 的每一行代表的是一个特定样本每个特征对于类别1的贡献值
#shap.summary_plot(shap_values[:,:,1],x1,plot_type="bar",show=False)
#plt.title("SHAP Feature Importance (Bar Plot)")
#plt.show()此处shap_values:, :, 0 的每一行代表的是一个特定样本每个特征对于类别0的贡献值(SHAP值),输出的是对类别0来说'Purpose_debt consolidation', 'Bankruptcies', 'Number of Credit Problems', 'Purpose_other'这四个特征最重要。
注意:但是如果用shap_values:, :, 1会发现,对类别1来说,对应的重要性特征又不一样。同理,每个类别对应的重要性特征有区别。
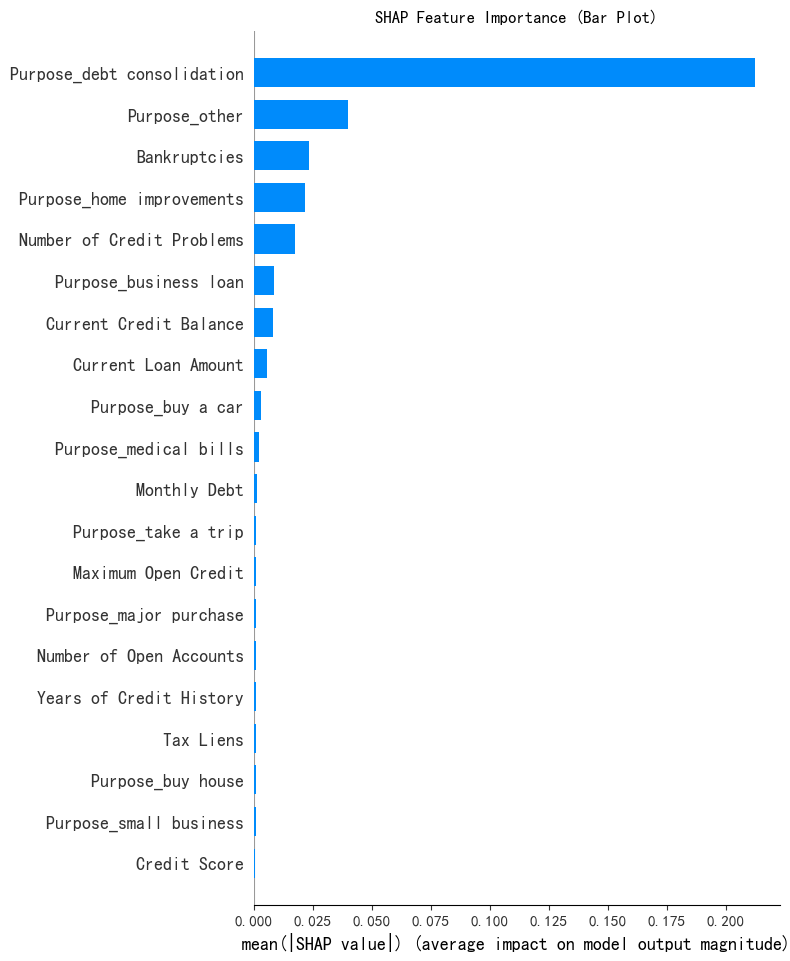
接下来还是对类别0的这几个特征来继续梳理:
注意:
- 画图时的参数。
- 判断离散或连续是为后续好看的图呈现效果。这里判断出离散型后续用直方图
python
# %%判断一下贡献值高的几个特征是离散型还是连续性
import pandas as pd
selected_features = ['Purpose_debt consolidation', 'Bankruptcies',
'Number of Credit Problems', 'Purpose_other']
for feature in selected_features:
unique_count = X[feature].nunique() #唯一值指的是在某一列或某个特征中,不重复出现的值
#连续型变量通常有很多唯一值,而离散型变量的唯一值较少
print(f'{feature}的唯一值数量是{unique_count}')
if unique_count < 10:
print(f"{feature}可能是离散变量")
else:
print(f"{feature}可能是连续变量")
import matplotlib.pyplot as plt
#总样本中的前四个重要性的特征分布图
#一次性创建一个画布(figure)和若干个子图(axes),
# fig, axes = plt.subplots(nrows行数(多少行图), ncols列数(每行多少张图), figsize=(宽, 高))
fig,axes = plt.subplots(2,2,figsize = (12,8))
#axes.flatten()把二维数组拍平成一维数组,方便用for循环遍历绘图
axes = axes.flatten()
#输出:[axes[0,0], axes[0,1], axes[1,0], axes[1,1]]
#循环画多图,用来快速画出多个特征的分布
#enumerate() 同时返回i:循环计数(从0开始);feature:当前特征名
for i,feature in enumerate(selected_features):
axes[i].hist(X[feature],bins=20) #绘制直方图,X[feature]取出DataFrame中对应列的数据;bins=20把数据划分成20个区间(柱子数量)
axes[i].set_title(f'Histogram of {feature}') #
axes[i].set_xlabel(feature)
axes[i].set_ylabel('Frequency')
plt.tight_layout()
plt.show()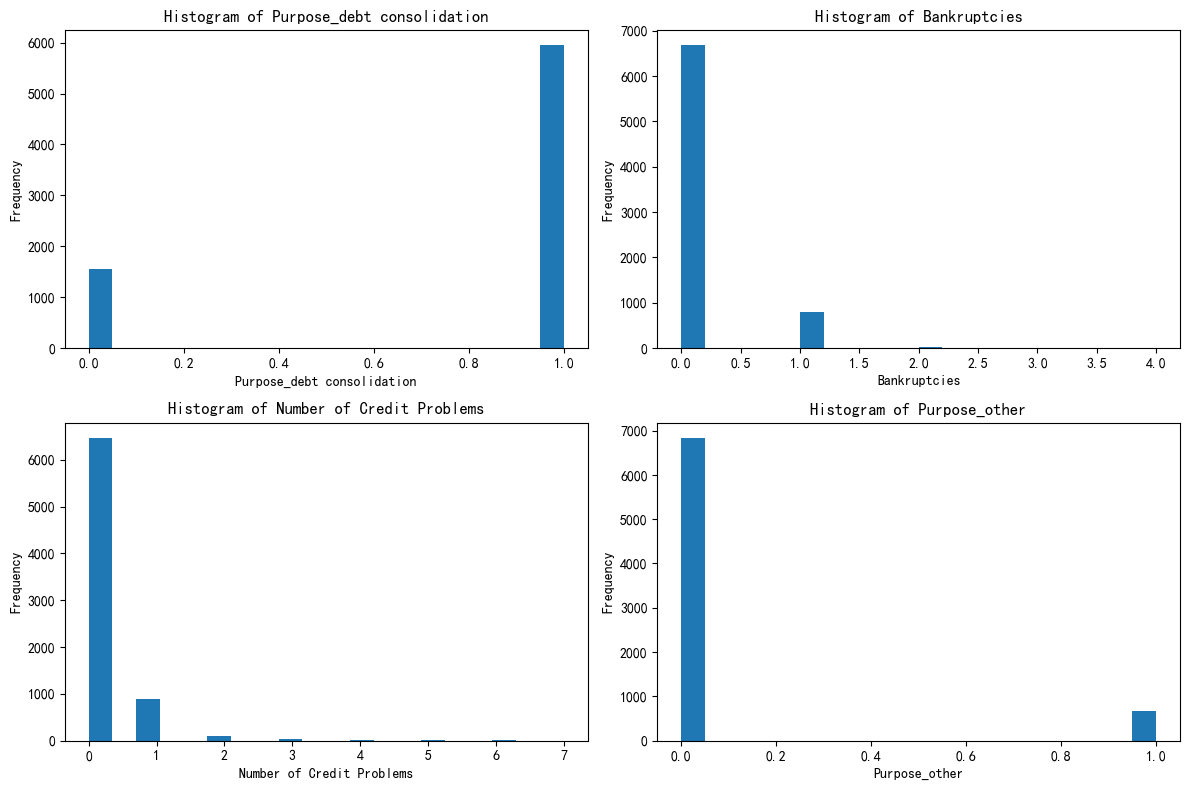
这个结果的解释:
Purpose_debt consolidation是一个 哑变量(Dummy variable),它的值只有 0 或 1,这是因为之前进行了One-Hot 编码。在原始数据中,这可能来自 "贷款目的" 这样的分类变量。大部分样本的 Purpose_debt consolidation=0。
Bankruptcies横轴是破产次数;绝大多数在 0,少部分在 1 或 2。大多数人没有破产记录;极少数人有 1~2 次破产经历。
Number of Credit Problems大部分样本是 0,少部分是 1,极个别是 2+,这个特征(信用问题数)也是高度偏斜的。大部分人信用良好,少数人问题多。
Purpose_other又是一个哑变量(0/1),所以:柱子只在 0 和 1
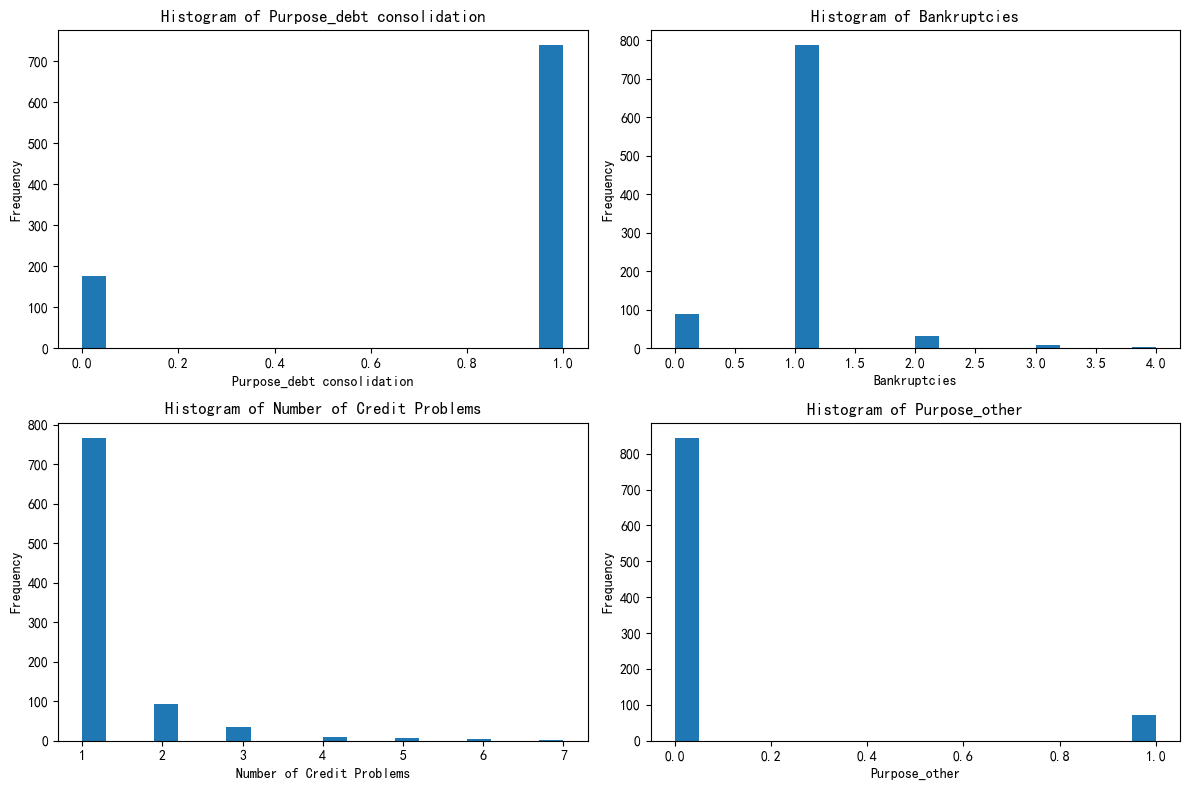
绘制出0,1,2每个簇的这四个特征的分布图
python
# %%绘制出每个簇的这四个特征的分布图
print(X['KMeans_Cluster'].value_counts)
#分别筛选出每个簇/每个类别的数据
X_Cluster0 = X[X['KMeans_Cluster'] == 0]
X_Cluster1 = X[X['KMeans_Cluster'] == 1]
X_Cluster2 = X[X['KMeans_Cluster'] == 2]
print(X_Cluster0,X_Cluster1,X_Cluster2)
#绘制簇0,1,2的分布图
#选总样本前四个重要特征的分布图
fig,axes = plt.subplots(2,2,figsize=(12,8))
axes = axes.flatten()
for i, feature in enumerate(selected_features):
axes[i].hist(X_Cluster0[feature], bins=20)
axes[i].set_title(f'Histogram of {feature}')
axes[i].set_xlabel(feature)
axes[i].set_ylabel('Frequency')
plt.tight_layout()
plt.show()
fig,axes = plt.subplots(2,2,figsize=(12,8))
axes = axes.flatten()
for i, feature in enumerate(selected_features):
axes[i].hist(X_Cluster1[feature], bins=20)
axes[i].set_title(f'Histogram of {feature}')
axes[i].set_xlabel(feature)
axes[i].set_ylabel('Frequency')
plt.tight_layout()
plt.show()
fig,axes = plt.subplots(2,2,figsize=(12,8))
axes = axes.flatten()
for i, feature in enumerate(selected_features):
axes[i].hist(X_Cluster2[feature], bins=20)
axes[i].set_title(f'Histogram of {feature}')
axes[i].set_xlabel(feature)
axes[i].set_ylabel('Frequency')
plt.tight_layout()
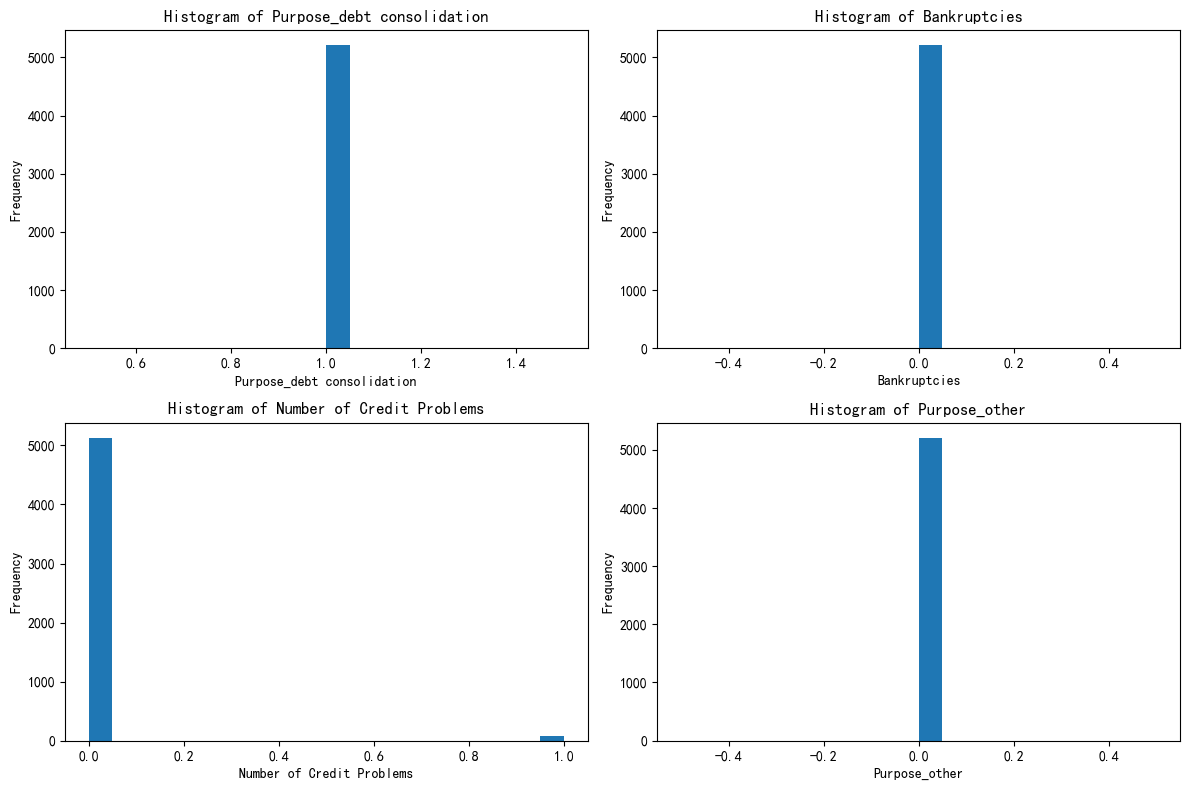
plt.show()簇0:优质信用稳健财务型
综合这四个特征:在债务合并用途上表现一致,几乎无破产记录,信用问题极少,资金用途集中且很少涉及特殊类别。
簇1:较稳健但信用有分化财务型
多数无债务合并需求,破产情况少见,但信用问题上存在个体差异,资金用途有一定分散性。整体财务状况相对稳定,但在信用和资金使用方向上不如第一个簇表现一致。
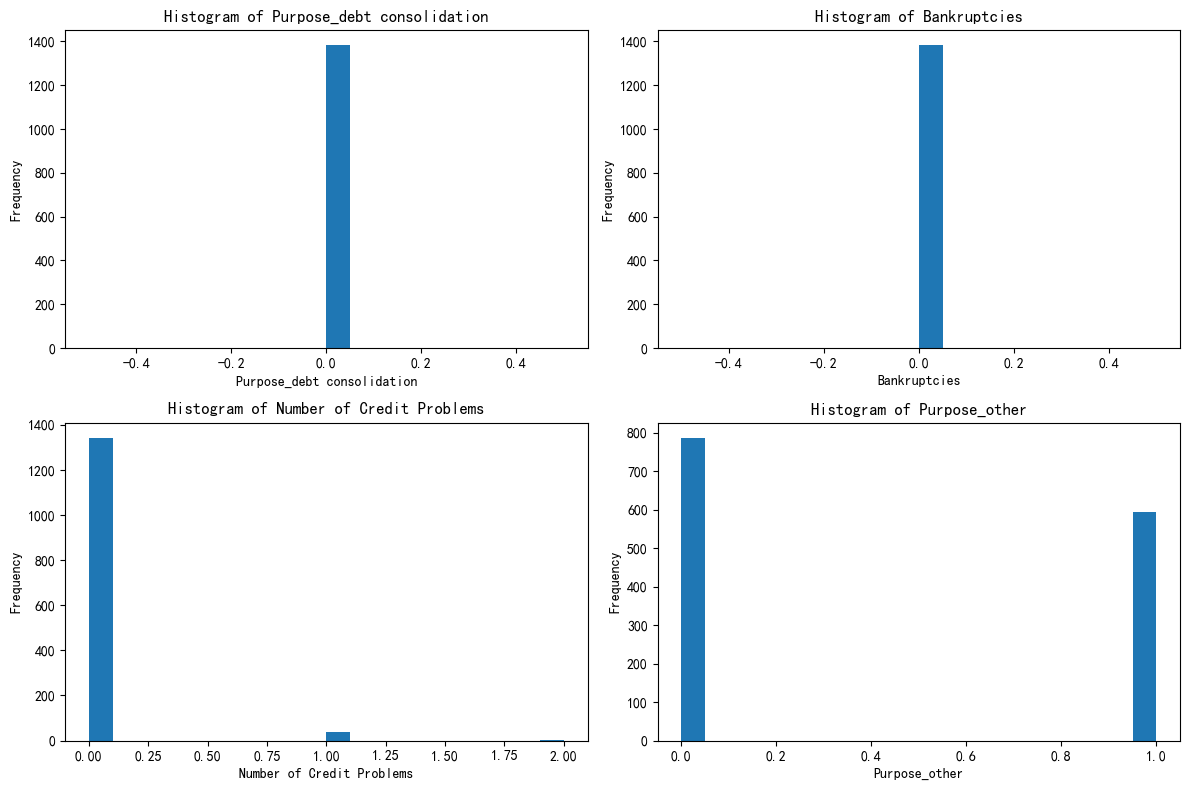
簇2:高风险财务困境型
债务合并需求分化,破产经历较多,信用问题普遍且严重,资金用途有差异。在财务健康和信用方面存在诸多问题,面临较大财务风险。
**作业:**参考示例代码对心脏病数据集采取类似操作,并且评估特征工程后模型效果有无提升。