一、概念
安全模型是指描述安全重要方面(机密性,完整性等)及其与系统行为的关系(允许/拒绝访问、加密/解密数据等)的框架。
这句话真得晦涩,我的理解是:如何通过某一行为去保护某一安全特性,比如说如何通过加解密来保护机密性。
安全模型的作用是为安全策略提供具体的实现方案,确保系统在访问控制、机密性、完整性 等方面安全运行。
比如组织定制的安全策略是 "保护数据不被未授权访问",安全模型则是要给实现这个策略的 具体的方法,比如简单地说如何合理给用户和数据设计权限。
更通俗地解释就是,学校规定了只有学生老师才能进学校这条安全策略,安全模型就是给出一套成熟的实现方案,比如说【戴狗牌】【机器人脸识别】【保安驻守】,其他学校看到后,也可以直接照搬这一套安全模型。
安全模型有很多种,需要根据不同特性、不同场景,不同的控制关系,选择不同的安全模型
比如说有的场所安全性比较高,军事机密可能就需要双认证,人脸+指纹识别。
模型主要分为机密性 和完整性**两种。
其中机密性涉及模型比较多:
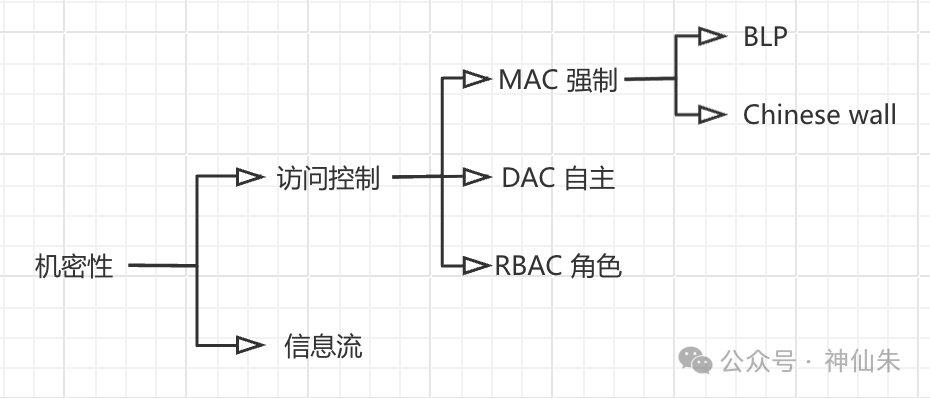
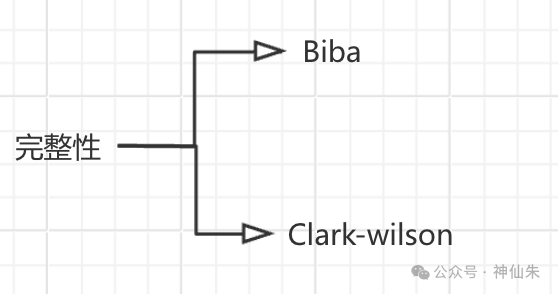
完整性包括两种模型:
先简单说下完整性和机密性的区别:
1)机密性是保证数据无法被非法读取;
2)完整性是保证数据不被非法篡改,保证数据真实性和唯一性。
二、机密性/访问控制
通俗说就是,控制谁有权限操作什么资源,比如你可以访问A文件,但是别人不行。然后可以看到访问控制下又分了三种类型。
(1)MAC 强制
(2)DAC 自主
(3)RBAC 角色
我们来看看有什么区别
**DAC自主:**Discretionary Access Control,自主访问控制,资源拥有者决定权限
权限分配是"自主的",即文件或数据的所有者可以决定谁可以读、写、执行
**RBAC角色:**Role-Based Access Control,基于角色的访问控制,职务分配权限
根据用户的组织角色来分配权限,你是开发就只能操作开发相关的文档,无法操作其他角色的
看完 DAC 和 RBAC,基本上都很熟悉了吧,就是我们工作中的权限分配,所以我们今天的重点是
MAC 强制。
2.1 MAC 强制
访问权限不是由资源拥有者决定的,而是根据系统预设的安全策略强制执行的。就算文件是你创建的,你也没有权限给别人授权!
比如会给你打上某个等级标签,低等级无法访问高等级的资源。
这咋么有点像 RBAC 角色权限呢,不都是划分某一类权限吗?我也可以建立高等级,中等级,低等级这样的角色啊!!
2.2 MAC强制 / BLP
Bell-LaPadula 模型,是 David Bell 和 Len LaPadula 在1973年提出的第一个正式的安全模型
模型最初是为美国国防部的多级安全策略(Multi-Level Security, MLS)设计的,适用于处理不同敏感级别的数据,如"绝密"、"机密"、"秘密"等。
(1)基本概念
BLP 模型基于以下几个核心概念:
-
主体(Subject):能够发起操作的实体,如用户、进程或程序。
-
客体(Object):被访问的资源,如文件、数据库记录、内存区域等。
-
安全级别(Security Level):每个主体和客体都被赋予一个安全级别,通常分为"绝密(Top Secret)"、"机密(Secret)"、"秘密(Sensitive)"等层次。
-
访问操作:主要包括读(Read)、写(Write)和 读/写(Read/Write)三种基本操作
(2)安全规则
1)简单安全规则 :主体不能读取安全级别高于自己的客体
说人话:级别低的不能读取级别高的
2)星属性安全规则 :主体不能向安全级别低于自己的客体写入数据
说人话: 级别高的不能向级别低的写数据
说实话当时看到这个我也有点疑惑,级别高的怎么还不能向低级别写数据了?后面我才领悟,是"写"这个字误导我了!
举一个通俗的例子就豁然开朗了:一个小兵可以向将军上报情报(写), 但是不能向将军打探情报(读取)。所以 " 级别高的不能向级别低的 写数据" ,就可以理解成 "将军不能把情报写给 小兵"。 但是同时我又疑惑了,"那小兵自己上报的情况,他自己能读取吗"
按道理来说应该也不行,那我又有疑惑了,"那小兵想要修改自己的情报怎么办"
我又明白了,"不用修改旧情报,而是重新上报就行了"。
所以根据"简单安全规则"和"星属性安全规则",我们可以得到一条单向的数据流,也就是可以上写下读!
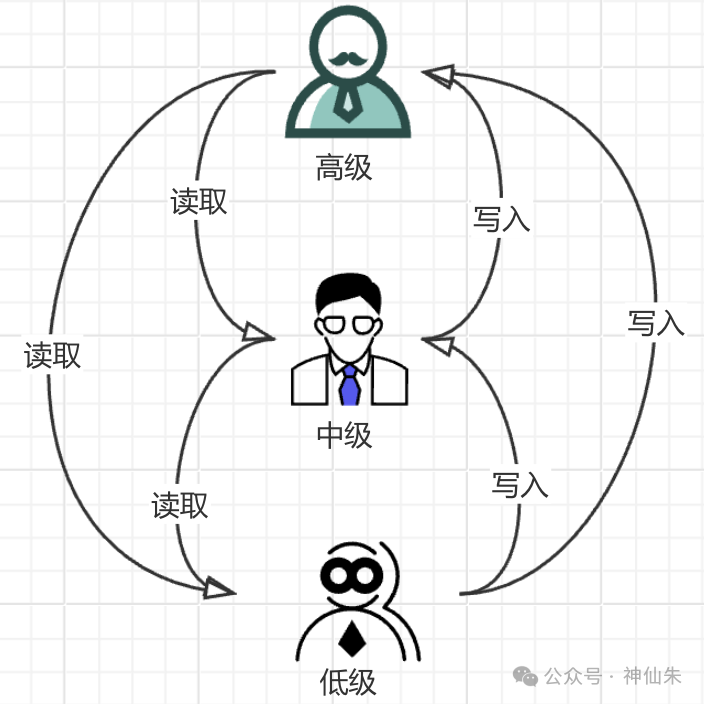
但是注意!!这是机密性模型!
对应实际的人员和资源,就类似这样
所以现在你可以知道 和 RBAC 的区别了吧,他不是单纯某一类权限的集合,已经变成一种对信息流向控制机制了。
3)强星属性安全规则 :不允许对其他级别进行读写
说人话:只能在同级别进行读写
我还在想,那不是跟前面两条规则冲突了吗,仔细一想,规则只是要求"不能上读、不能下写" , 下读上写只是我们默认的(法无禁止即可为)。
所以其实这条规则和前面两条规则不冲突,只是现在把这条通道也堵死了。
或许只有那种高度机密,比如核设施 那种高敏感场所了吧,估计这辈子都不会接触到
但是我又有一个疑惑,只能同级读写的话,难道就真的没有上下级数据流向的场景吗?
查了一下,常见做法是设置一个受控的、可审计的提交通道,由下级用户将数据提交至一个共享区域,再由上级主体主动读取(遵循简单安全规则和星属性规则),从而绕过直接写操作的限制。类似这样:

访问控制矩阵,如下表:

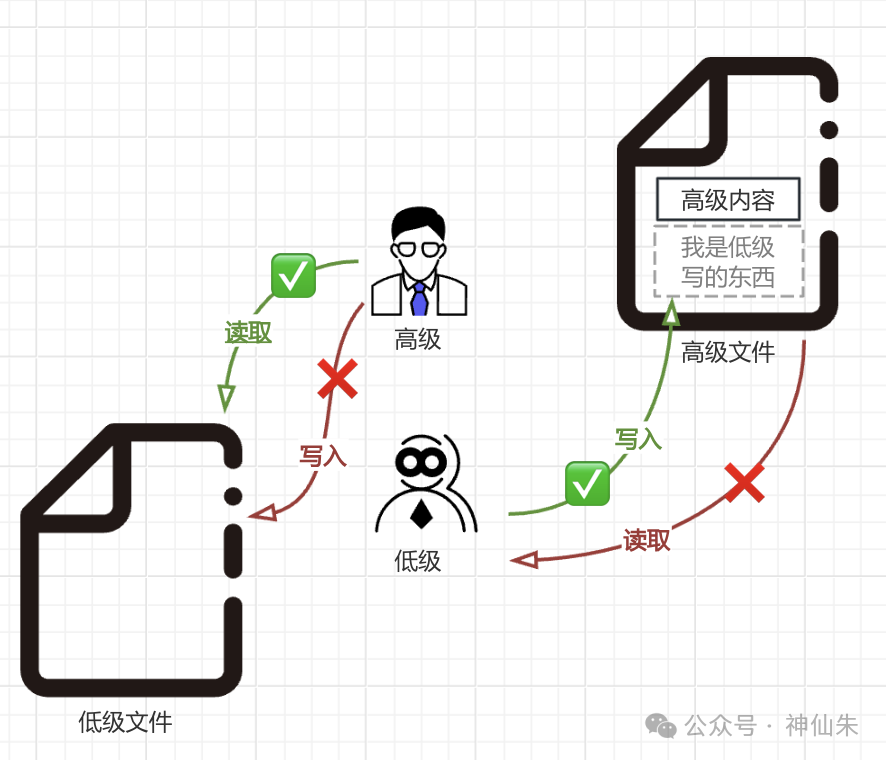
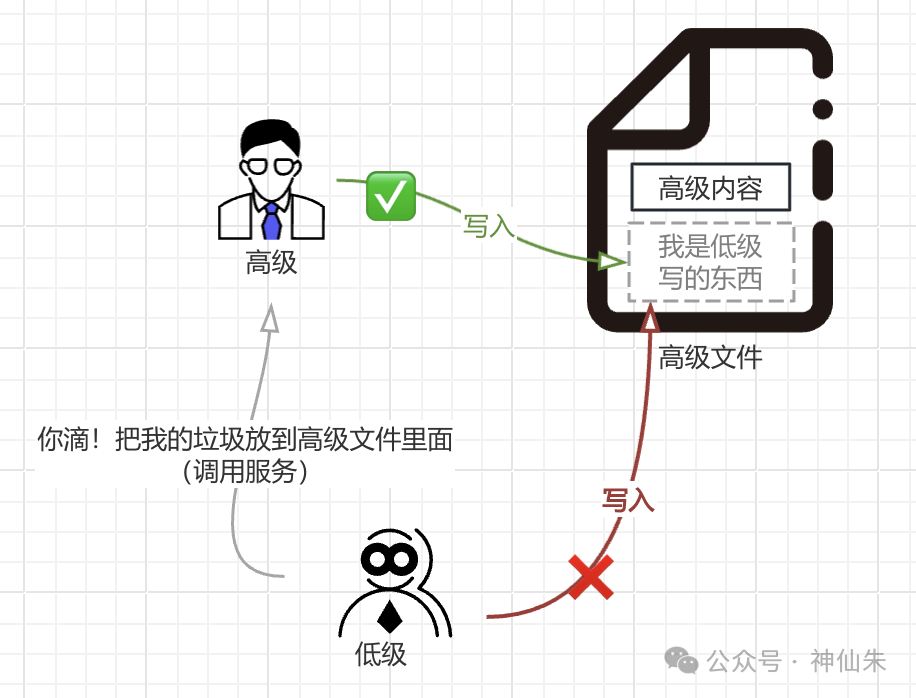
但是这个规则需要在其他三条规则基础上,也就是不能违背其他规则,比如这样是不行的:
你低级人怎么可以读高级文件!
之所以称为"自主",是因为文件或资源所有者可以自行修改这些权限,例如授予其他用户读取或写入的权限。
比如按前面三条规则下,虽然说:
1)低级B可以写入高级文件A;
2)高级A可以读取低级文件B。
但是我同样可以没收这些权限

2.3 MAC强制 / Chinese Wall
又名Brew-Nash 模型,不用想,就是Brewer和 Nash提出来的,最初为投资银行设计,用于防止因利益冲突而导致的信息泄露。核心目标是确保用户访问的信息不会与其已掌握的信息产生利益冲突,从而保护客户数据的完整性与保密性。
说人话就是,比如你是一个律师,你如果接了被告的单,就不能接原告的单,因为他们利益冲突。但是停一下!!
为什么叫 Chinese Wall?是不是黑我们?
bash
Chinese wall 这个短语源自中国的长城(the Great Wall),1929年华尔街股灾后,这个词便在股票市场流行,当时美国政府要求银行家和券商之间进行"信息隔离",防止银行家获取不当利益,保证市场的公平。
1980年宾夕法尼亚大学发表了一篇重要文章------题为 The Chinese Wall Defense to Law-Firm Disqualification(律所失格问题中的"中国墙"防御策略),进一步把"Chinese wall"这个短语发扬光大了。
指的是为了防止利益或者是信息泄露而建立的屏障,正如长城的建立是为抵御外敌入侵一样。安全规则
下面是主体访问客体的规则
1)与主体曾经访问过的信息属于同一公司数据集合的信息
2)属于一个完全不同的利益冲突组的可以访问
3)主体能够对一个客体进行写的前提是: 主体未对任何属于其他公司数据集进行过访问。
定理1:一个主体一旦访问过一个客体,该主体就只能访问 属于统一公司数据集的 客体 或者 不同利益的客体
定理2:在一个利益冲突组中,一个主体最多能访问一个 公司数据集
这些都是密密麻麻的一堆概念,简化就是
1)可以访问不同利益冲突的
2)同一利益冲突的,只能访问一个
同一案件,一个律师,只能接被告或者原告的单,因为他们利益冲突。但是你可以接不同案子的其他原告或被告。
三、机密性 / 信息流
这是属于机密性的另一种类型,跟访问控制相比更严格。信息流指的是信息在系统中从一个位置或实体向另一个位置或实体的传递过程。
信息流模型的目标是:防止敏感信息以任何形式"泄露"到不应获得它的主体或客体中,即使这种泄露不是通过直接访问实现的。
所以信息流模型是对数据更加全方位地保护,不单是控制读写,而是深入到数据在整个系统中传播的全过程,确保敏感信息不会通过显式或隐式的方式泄露。
比如说有一杯饮料是保密的
1)通过访问控制,可以限制只有你能喝,但是你喝完之后,别人通过和你接触,通过闻你说话的味道(间接),从而猜到饮料是什么(这就属于间接泄漏信息了)。
2)通过信息流,每个喝完饮料的人,都必须漱口,并喝点其他东西掩盖,从而让别人无法猜到。
但是这两种机制并不是互斥的,往往是协作的方式,比如高安全等级系统(军用系统、金融系统)中,往往同时采用"访问控制 + 信息流控制"双重机制。
信息流都有什么模型
1)非干扰模型(Noninterference Model)
2)信息流标签模型(Label-Based Information Flow)
稍微简单了解下这三个模型即可。
非干扰模型:无论高级用户执行了什么操作,系统的输出或状态变化都应当保持一致,即高级的行为对低级"不可见"或"无干扰"。
除了刚刚喝水那个例子,印象最深的就是 leetcode 刷题了,每次提交都需要跑几十上百个用例,如果你错得一塌糊涂,很快就返回响应了,如果你基本写对能通过大部分用例,肯定响应很慢。然后你就可以根据响应的快慢来判断代码准确程度。
如果要把这个运行结果保密,不能让你猜到,就不管你过一个用例还是过100个用例,响应时间都必须一样(比如1分钟),这样你就完全不知道代码到底是什么程度。
信息流标签模型,给程序中的每一个变量、表达式、函数打上"安全标签", 编译器或运行时系统检查:是否允许从高标签数据流向低标签目标

四、完整性
4.1 Biba
Biba和BLP模型很相似,但是是用于解决完整性问题的。
(1)核心目标是:
-
保护数据不被未授权用户修改
-
保护数据不被越权修改
-
维持数据内部和外部的一致性
(2)安全规则:
1)星完整性规则:完整性级别低的不能对完整性级别高的客体写数据
这个和BLP的星属性安全规则是相反的。
2)星属性安全规则:主体不能向安全级别低于自己的客体写入数据
因为侧重点不同,完整性要保证数据不被篡改。
我们来看一个场景,比如说国家颁布的规定,你省份改不了,省份颁布的规定,你个人也改不了;但是国家可以修改你省份的规定。

2.简单完整性规则 :完整性级别高的不能从完整性级别低的客体读取数据。理解了上面之后,这条规则也更好理解了:完整性更高,理解为权威性更高,权威性更高的院士不可能参考(读取) 你一个小学生的论文,否则就会拉低他的权威性(破坏完整性)。

3.调用属性规则:完整性级别低的不能调用完整性级别高的程序或服务。
虽然你完整性级别低, 不能写入完整性级别高的文件中,但是有没有可能你让完整性级别高的人 帮你写?
小学毕业的你如果可以指导院士去发表论文,那这个院士的权威性就大大降低。
4.2 Clark-Wilson
简称CWM,是由 David Clark 和 David Wilson 于1987年提出的一种完整性安全模型。
Clark-Wilson模型包含三个基本元素:主体、程序和客体,其中主体只能通过特定的程序来访问客体,而程序内部嵌入了权限校验和完整性验证逻辑。
Clark-Wilson 超越了传统的读写控制,引入了"受控过程"、"职责分离"、"状态一致性"等机制,通过受控的流程 ,防止非法或错误的操作破坏数据完整性。
(1)受控过程,所有操作都必须通过合法、可信的过程执行,而不是由用户直接修改。比如你不能直接修改自己的账户余额
(2)职责分离,一个完整的敏感操作不能由单一用户独立完成,必须由多个角色协同完成。我觉得类似于离职流程,要 组长审批,部门leader审批,CEO审批
(3)状态一致性,比如从一个账户转账到另一个账户,需要确保两个账户的新值准确无误,以维护内部和外部的一致性。
Clark-Wilson 还具有审计能力,需要记录所有日志信息以还原全链路操作(不过我觉得这个应该是每个模型都有的能力)
其中涉及的概念
-
主体(Subject):通常是用户或进程
-
客体(Object),分为两类:
-
-
CDI(Constrained Data Item):受约束的数据项,即关键数据(如银行账户余额),必须通过严格控制的过程才能修改。
-
UDI(Unconstrained Data Item):非受约束数据项,如外部输入,需经过验证后才能影响 CDI
-
-
TP(Transformation Procedure):转换过程,是一组受控的程序或操作,用于合法地修改 CDI。比如 "转账程序"就是一个TP。
-
IVP(Integrity Verification Procedure):完整性验证程序,确保 CID 是有效的
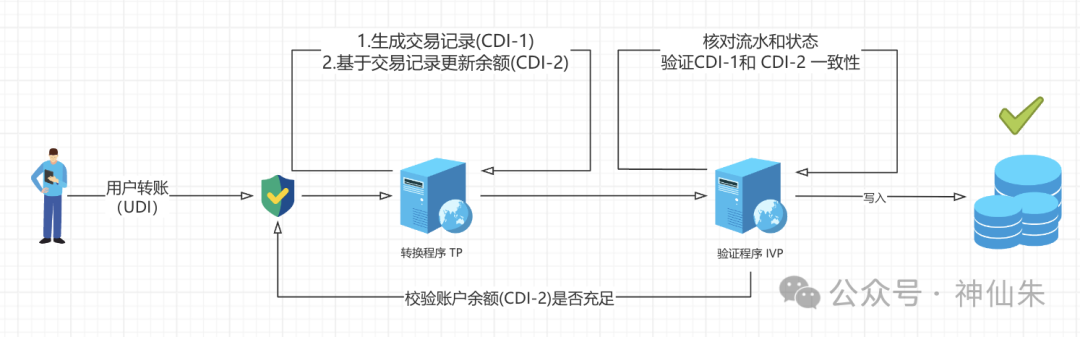
示例:以银行转账简单举下例
-
你要转账 10块(未受保护的数据输入,即UDI);
-
对账程序(IVP)检查账户余额(CDI-2)等关键数据是否处于合法状态(是否冻结,余额充足等);
-
IVP 通过,银行服务程序(TP)将 用户请求(UDI)生成 交易记录( CDI-1);
-
银行服务程序(TP)根据交易记录( CDI-1 )更新 账户余额(CDI-2);
-
对账程序(IVP)核对流水与账户状态,验证CDI-1与CDI-2的一致性;
-
数据写入数据库,转账成功。
参考文献1: