目录
[💡 一、链表到底是个啥?为什么我们还要"折腾指针"?](#💡 一、链表到底是个啥?为什么我们还要“折腾指针”?)
[🛠️ 三、动手实现你的第一个单链表](#🛠️ 三、动手实现你的第一个单链表)
[1. 定义节点结构体 (SListNode)](#1. 定义节点结构体 (SListNode))
[2. 创建和销毁节点 (Malloc & Free)](#2. 创建和销毁节点 (Malloc & Free))
[3. 核心操作:头插法 (SLTPushFront)](#3. 核心操作:头插法 (SLTPushFront))
[4. 尾插法 (SLTPushBack) & 易错点大全](#4. 尾插法 (SLTPushBack) & 易错点大全)
[5. 删除操作:SLTPopFront & SLTErase](#5. 删除操作:SLTPopFront & SLTErase)
[📱 五、实战项目:用单链表做一个通讯录!(详细版)](#📱 五、实战项目:用单链表做一个通讯录!(详细版))
[1. 数据结构设计 (contact.h)](#1. 数据结构设计 (contact.h))
[2. 核心功能实现 (contact.c)](#2. 核心功能实现 (contact.c))
[(1) 加载历史数据 (LoadContact)](#(1) 加载历史数据 (LoadContact))
[📌 重点解释:](#📌 重点解释:)
[(2) 添加联系人 (AddContact)](#(2) 添加联系人 (AddContact))
[📌 重点解释:](#📌 重点解释:)
[(3) 查找联系人 (FindByName)](#(3) 查找联系人 (FindByName))
[📌 重点解释:](#📌 重点解释:)
[(4) 删除联系人 (DelContact)](#(4) 删除联系人 (DelContact))
[(5) 展示所有联系人 (ShowContact)](#(5) 展示所有联系人 (ShowContact))
[(6) 保存数据到文件 (SaveContact)](#(6) 保存数据到文件 (SaveContact))
[(7) 程序退出时,销毁链表并保存数据 (DestroyContact)](#(7) 程序退出时,销毁链表并保存数据 (DestroyContact))
[3. 主程序 (main.c)](#3. 主程序 (main.c))
[🧩 六、经典 OJ 题目:练练手,巩固知识!](#🧩 六、经典 OJ 题目:练练手,巩固知识!)
[💬 结语:别怕,链表没那么难!](#💬 结语:别怕,链表没那么难!)
引言
你有没有想过,微信好友列表底层是怎么存的?今天我们不用数组排排坐,而是用一节一节能自由增删的"火车厢"来装------这就是链表。等你写完通讯录小项目,再去刷几道 OJ,就会惊讶:"原来指针也没那么可怕!"💪今天,我们就从顺序表升级到链表,一起拆解这个神秘的结构。

那我们就开始吧!
💡 一、链表到底是个啥?为什么我们还要"折腾指针"?
当你第一次听到"链表"两个字时,可能脑子里冒出一堆问号:"数组不是挺好用的吗?干嘛要多此一举?"
那我们用一个生活化的比喻👇
想象一列火车,每节车厢都能挂上或拆下:
-
旺季多拉几节(多申请节点)
-
淡季就减几节(释放节点)
-
而且拆哪节都不影响其他车厢(逻辑连续但物理不连续)
数组像是一整条钢轨 ,长度一旦定了就很难改;
链表更像自由拼接的车厢,灵活但需要你亲手"接电线"------这电线就是指针。
💡 关键理解:链表在物理内存上是"东一块西一块"的,但它通过"指针"这个"钥匙",把逻辑上的顺序串起来了。想象每节车厢里都放着下一节车厢的地址,你拿着这把钥匙,就能一路找到终点。
📦 每个"车厢"节点的结构长这样:
typedef int SLTDataType;
typedef struct SListNode {
SLTDataType data; // 数据
struct SListNode* next; // 存放下一个节点的地址,这就是"钥匙"!
} SLTNode;每次 malloc() 一节新的"车厢",把上一节的 next 指向它,链就成了。
🚨 新手第一大坑 :别忘了给每个节点配"钥匙"! 也就是 next 指针。
和顺序表的"本质区别"
-
✅ 插入/删除更友好:理论上只改指针,不大规模搬迁元素。
-
✅ 容量弹性:来一个申请一个,走一个释放一个。
-
❌ 随机访问不香:想要第 k 个,得走 k 步。
-
❌ 多一次内存开销:每个节点要存一个指针。
💡记忆法:数组适合"查得多、改得少";链表适合"改得多、查得少"。
☝二、为什么很多函数要"二级指针(指向头指针的指针)"?
为什么很多函数参数要传 SLTNode** pphead?
因为函数里可能会改变头指针本身 (比如头插、头删、在空表插入),如果只传 SLTNode*,你改的是"副本",出了函数就丢了;传 SLTNode** 才能把"新的头"带回去。💡
🚨易错:忘记传二级指针,导致"插入看似成功,函数外头指针没变",程序一脸懵。
易错对比:
// ❌ 错误示例:头插却只传了一级指针,改变不了实参的头指针
void PushFrontBad(SLTNode* phead, int x) {
SLTNode* node = malloc(sizeof(SLTNode));
node->data = x;
node->next = phead;
phead = node; // 只是改了形参副本!
}
// ✅ 正确示例:传二级指针,函数里"改头真改头"
void SLTPushFront(SLTNode** pphead, int x) {
SLTNode* node = malloc(sizeof(SLTNode));
node->data = x;
node->next = *pphead; // 新节点指向旧头
*pphead = node; // 让头指针指向新节点
}💡 核心概念:(再强调一下,加深理解)
- 节点 (Node) :每个车厢就是一个节点,它包含两部分:
- 数据域 (data):存你的信息,比如姓名、电话。
- 指针域 (next):下一个节点的指针。
- 头指针 (phead):一个变量,它保存的是第一个节点的地址。通过它,你就能找到整个链表。
🛠️ 三、动手实现你的第一个单链表
我们一步一步来 先定义节点结构体。
先定义节点结构体。
1. 定义节点结构体 (SListNode)
这是整个链表的基础,就像定义便签的格式。
// 我们先假设数据是整型,后面会改成通讯录结构体
typedef int SLTDataType; // 为了方便,给数据类型起个"别名"
// 定义节点结构体
typedef struct SListNode {
SLTDataType data; // 数据域,存放实际的数据
struct SListNode* next; // 指针域,存放下一个节点的地址
} SLTNode;📌 重点解释:
typedef struct SListNode { ... } SLTNode;这句话的意思是:定义了一个名为SListNode的结构体,并给它起了一个更短、更好记的名字叫SLTNode。struct SListNode* next;这里很关键!它是一个指向自身类型 的指针。因为下一个节点也是SLTNode类型,所以要用struct SListNode*来声明。虽然我们在前面用了typedef,但在结构体内部定义时,必须用完整的名字struct SListNode,这是C语言的规定。
2. 创建和销毁节点 (Malloc & Free)
节点是在程序运行时动态申请的,我们需要用 malloc 函数。
// 创建一个新节点的函数
SLTNode* CreateNode(SLTDataType x) {
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode)); // 申请一块内存,大小等于一个 SLTNode 结构体
if (newnode == NULL) { // 🚨 坑点1:malloc 可能失败!一定要检查!
printf("内存分配失败!\n");
return NULL;
}
newnode->data = x; // 给数据域赋值
newnode->next = NULL; // 初始化指针域为 NULL,表示它是最后一个节点(暂时)
return newnode; // 返回新节点的地址
}
// 销毁一个节点的函数(通常用于删除操作后)
void DestroyNode(SLTNode* node) {
if (node != NULL) { // 防止传入空指针
free(node); // 释放内存
node = NULL; // 避免野指针(虽然这里作用不大,但养成好习惯)
}
}📌 重点解释:
malloc(sizeof(SLTNode)):sizeof是计算SLTNode结构体占用的字节数。malloc会返回一个void*类型的指针,我们需要用(SLTNode*)强制转换成我们需要的类型。free(node):当节点不再需要时,必须用free释放它占用的内存,否则会造成内存泄漏,程序跑久了会变慢甚至崩溃。
3. 核心操作:头插法 (SLTPushFront)
这是最简单的插入,但也是最容易出错的地方!很多同学在这里栽跟头。
// ❌ 错误示范:只传一级指针,无法修改头指针本身!
void SLTPushFront_Wrong(SLTNode* phead, SLTDataType x) {
SLTNode* newnode = CreateNode(x);
if (newnode == NULL) {
return; // 创建失败,直接返回
}
newnode->next = phead; // 新节点的 next 指向原来的头节点
phead = newnode; // ❌ 这里修改的是形参 phead,对实参无效!
// 因为 C 语言是"值传递",函数内部修改的是参数的副本,不会影响外面的变量。
}
// ✅ 正确做法:传二级指针!
void SLTPushFront(SLTNode** pphead, SLTDataType x) {
SLTNode* newnode = CreateNode(x);
if (newnode == NULL) {
return;
}
newnode->next = *pphead; // 新节点的 next 指向原来的头节点
*pphead = newnode; // ✅ 修改实参指向的地址,这才是真正的"头插"
// *pphead 就是解引用,相当于拿到了 phead 这个变量本身,然后把它赋值为 newnode 的地址。
}📌 重点解释:
-
为什么要用二级指针
**pphead?- 我们的目的是改变
phead这个变量本身的值(让它指向新的节点)。 - 如果只传
phead(一级指针),函数内部只能看到phead的值(即它指向的地址),无法修改phead这个变量。 - 传
&phead(取地址),函数接收到的是phead这个变量的地址,也就是一个二级指针**pphead。 - 通过
*pphead,我们就可以直接修改phead变量本身的值了。
- 我们的目的是改变
-
调用方式:
SLTNode* phead = NULL; // 初始为空链表
SLTPushFront(&phead, 10); // 传入 phead 的地址
4. 尾插法 (SLTPushBack) & 易错点大全
尾插比头插复杂一点,需要遍历到末尾。
void SLTPushBack(SLTNode** pphead, SLTDataType x) {
SLTNode* newnode = CreateNode(x);
if (newnode == NULL) {
return;
}
if (*pphead == NULL) { // 🚨 坑点1:链表为空时,直接让头指针指向新节点
*pphead = newnode;
} else {
SLTNode* cur = *pphead; // 从头节点开始遍历
while (cur->next != NULL) { // 找到最后一个节点(它的 next 是 NULL)
cur = cur->next;
}
cur->next = newnode; // 最后一个节点的 next 指向新节点
}
}📌 易错点总结:
- 坑点1:忘记判断空链表 (
if (*pphead == NULL))。如果不判断,cur = *pphead就是NULL,接着cur->next就会导致段错误(Segmentation Fault),程序直接崩溃! - 坑点2:忘记给新节点的
next赋值为NULL。在CreateNode函数里我们已经做了,但如果在其他地方手动创建节点,一定要记得newnode->next = NULL;。否则,这个节点的next会是一个随机值,导致链表"跑偏",出现无限循环或访问非法内存。 - 坑点3:忘记释放内存 。每次
malloc都要对应free。在DestroyContact或SListDesTroy函数里,我们要遍历整个链表,逐个释放节点。
5. 删除操作:SLTPopFront & SLTErase
删除同样有坑,尤其是删除头节点和指定位置节点。
// 删除头节点
void SLTPopFront(SLTNode** pphead) {
if (*pphead == NULL) { // 🚨 坑点:空链表不能删!
printf("链表为空,删除失败!\n");
return;
}
SLTNode* del = *pphead; // 保存要删除的节点
*pphead = del->next; // 头指针指向下一个节点
free(del); // ✅ 记得释放内存!
del = NULL; // 避免野指针(虽然这里作用不大,但养成好习惯)
}
// 删除指定位置的节点 (pos)
void SLTErase(SLTNode** pphead, SLTNode* pos) {
if (*pphead == NULL || pos == NULL) { // 🚨 坑点:参数合法性检查
printf("参数错误,删除失败!\n");
return;
}
if (pos == *pphead) { // 如果要删除的是头节点
SLTPopFront(pphead);
} else {
SLTNode* prev = *pphead;
while (prev->next != pos) { // 找到 pos 的前一个节点
prev = prev->next;
}
prev->next = pos->next; // 前一个节点绕过 pos,指向 pos 的下一个
free(pos); // ✅ 释放内存
pos = NULL; // 避免野指针
}
}📌 重点解释:
- 为什么删除头节点要特殊处理? 因为删除头节点后,头指针
phead本身需要改变,指向第二个节点。这和删除中间节点不同,中间节点的删除不影响头指针。 - 删除中间节点的关键 :你需要找到被删除节点
pos的前一个节点prev。然后让prev->next指向pos->next,这样就"跳过"了pos。最后别忘了free(pos)!
☺四、链表的分类
链表的结构⾮常多样,以下情况组合起来就有8种(2 x 2 x 2)链表结构:
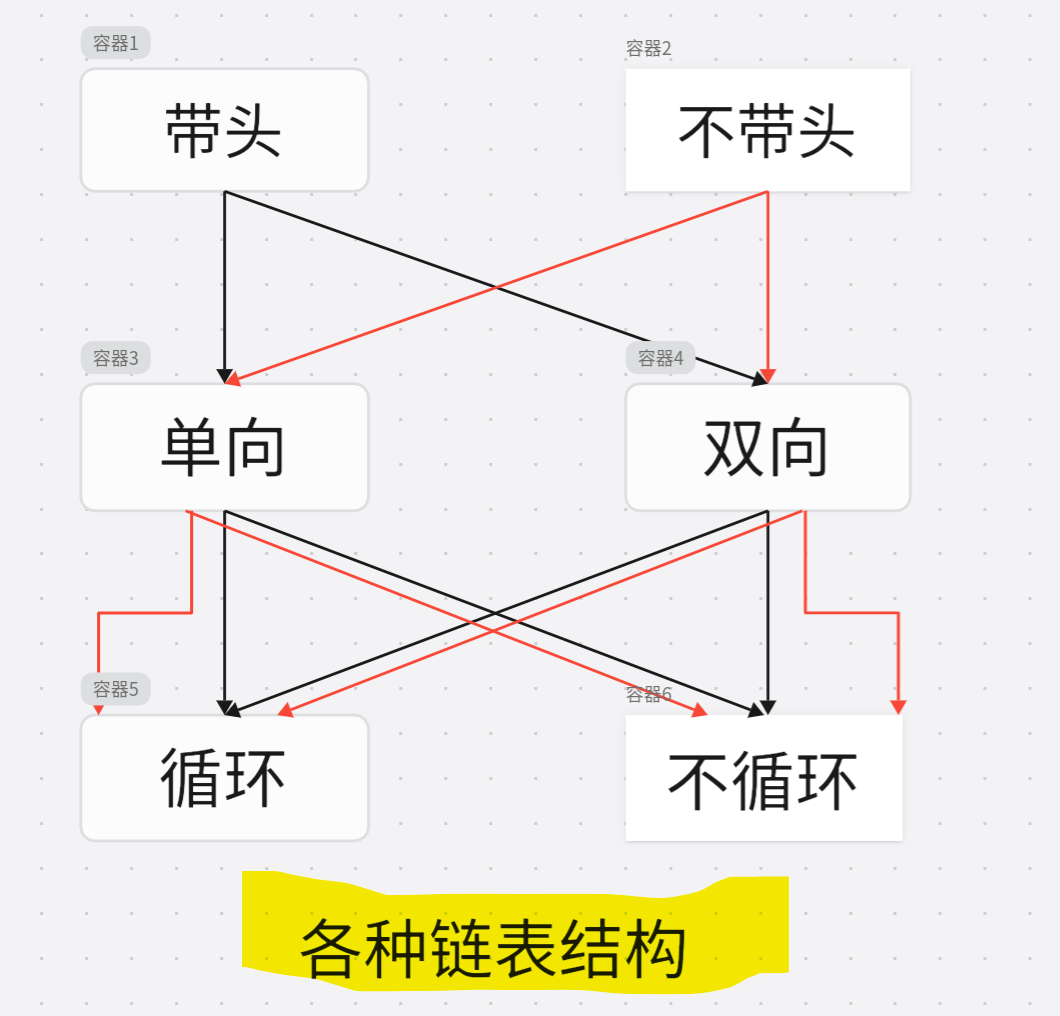
链表说明:
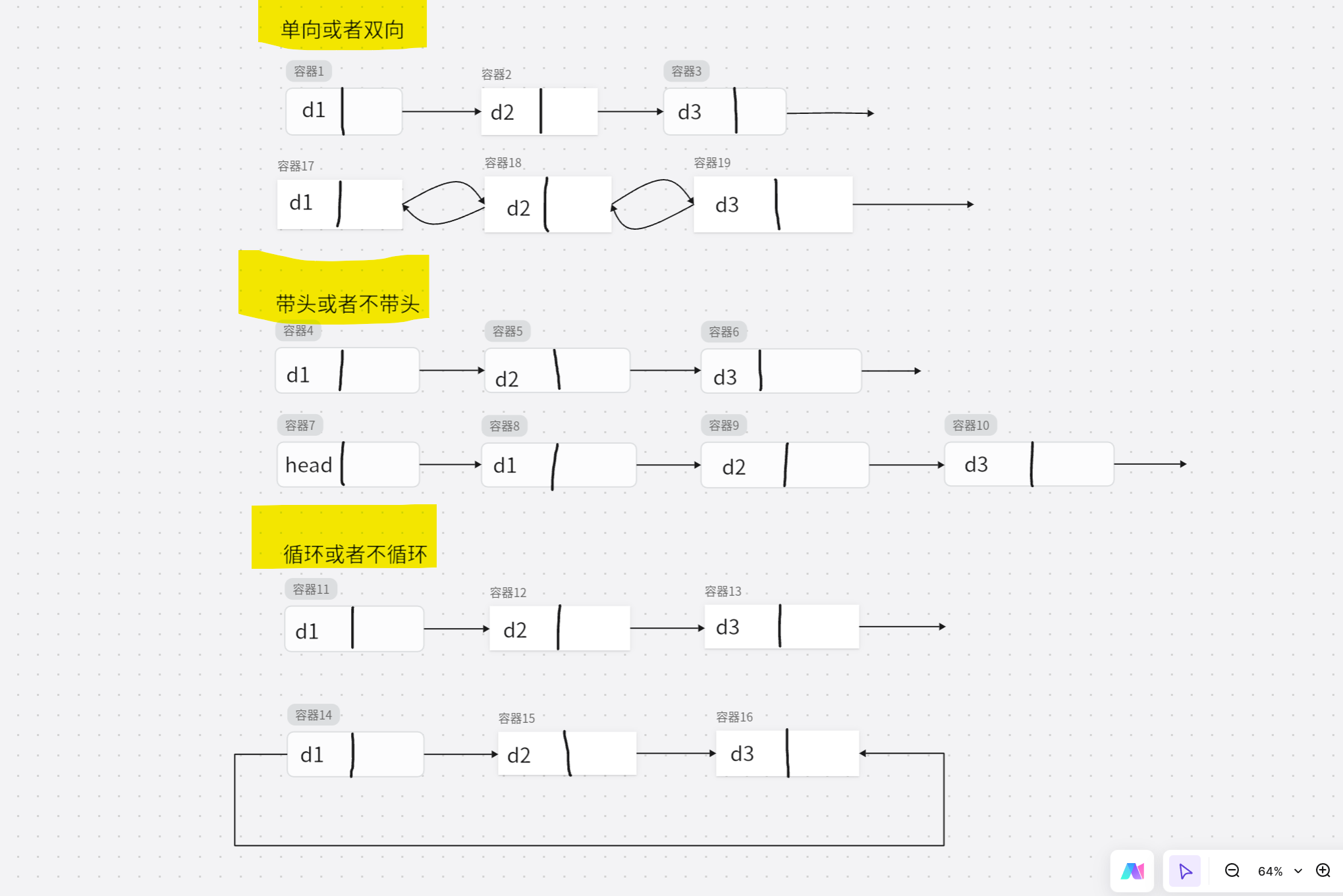
虽然有这么多的链表的结构,但是我们实际中最常⽤还是两种结构:
单链表 和 双向带头循环链表
- ⽆头单向⾮循环链表:结构简单,⼀般不会单独⽤来存数据。实际中更多是作为其他数据结
构的⼦结构,如哈希桶、图的邻接表等等。另外这种结构在笔试⾯试中出现很多。 - 带头双向循环链表:结构最复杂,⼀般⽤在单独存储数据。实际中使⽤的链表数据结构,都
是带头双向循环链表。另外这个结构虽然结构复杂,但是使⽤代码实现以后会发现结构会带
来很多优势,实现反⽽简单了,后⾯我们代码实现了就知道了
📱 五、实战项目:用单链表做一个通讯录!(详细版)
学了这么多,总得有个地方用吧?我们就用单链表来做一个简易通讯录,支持增、删、改、查,还能把数据保存到文件里,下次打开还能读回来!是不是很酷?

1. 数据结构设计 (contact.h)
// contact.h
#pragma once // 防止重复包含
#include "SList.h" // 引入我们之前写的链表接口
// 定义一些常量,方便后续使用
#define NAME_MAX 100
#define SEX_MAX 4
#define TEL_MAX 11
#define ADDR_MAX 100
// 用户信息结构体
typedef struct PersonInfo {
char name[NAME_MAX]; // 姓名
char sex[SEX_MAX]; // 性别
int age; // 年龄
char tel[TEL_MAX]; // 电话
char addr[ADDR_MAX]; // 地址
} PeoInfo;
// 通讯录就是一个单链表,节点数据是 PeoInfo
// 注意:这里用了前置声明,因为 contact 和 SListNode 会互相引用,避免循环包含
typedef struct SListNode contact;2. 核心功能实现 (contact.c)
(1) 加载历史数据 (LoadContact)
// 加载历史数据
void LoadContact(contact** con) {
FILE* pf = fopen("contact.txt", "rb"); // 以二进制读取模式打开文件
if (pf == NULL) {
// 文件不存在是正常情况,不需要报错
printf("未发现历史数据文件,将新建通讯录。\n");
return;
}
PeoInfo info;
// fread 返回成功读取的元素个数,如果读到文件末尾或出错,会返回小于1的值
while (fread(&info, sizeof(info), 1, pf) == 1) {
SLTPushBack(con, info); // 将读取到的信息添加到链表中
}
fclose(pf); // 🚨 记得关闭文件!
printf("历史数据导入通讯录成功!\n");
}📌 重点解释:
fopen("contact.txt", "rb"):rb表示以二进制模式读取。因为我们保存的是结构体,用文本模式可能会出问题。fread(&info, sizeof(info), 1, pf):从文件pf中读取sizeof(info)字节的数据到info变量中,读取 1 个元素。while (fread(...) == 1):这是一个非常重要的循环条件!fread成功读取一个元素时返回 1,读到文件末尾或发生错误时返回小于 1 的值(通常是 0)。这样可以确保我们读取所有数据。
(2) 添加联系人 (AddContact)
void AddContact(contact** con) {
PeoInfo info;
printf("请输入姓名:\n");
scanf("%s", info.name); // 🚨 注意:这里用 %s 读取字符串,不要加 &
printf("请输入性别:\n");
scanf("%s", info.sex);
printf("请输入年龄:\n");
scanf("%d", &info.age); // 整数要加 &
printf("请输入联系电话:\n");
scanf("%s", info.tel);
printf("请输入地址:\n");
scanf("%s", info.addr);
SLTPushBack(con, info); // 直接调用链表尾插
printf("插入成功!\n");
}📌 重点解释:
scanf("%s", info.name):%s用于读取字符串,它会自动忽略开头的空白字符(空格、回车等),并读取到下一个空白字符为止。info.name是一个字符数组,它的名字本身就是数组的首地址,所以不需要加&。scanf("%d", &info.age):%d用于读取整数,info.age是一个int变量,需要取地址&info.age。
(3) 查找联系人 (FindByName)
// 查找联系人 (按姓名)
contact* FindByName(contact* con, char name[]) {
contact* cur = con; // 从头节点开始遍历
while (cur) { // 当 cur 不为 NULL 时继续循环
// 🚨 坑点:字符串比较不能用 ==,要用 strcmp!
// == 比较的是两个指针的地址是否相等,而不是字符串内容是否相等。
if (strcmp(cur->data.name, name) == 0) {
return cur; // 找到了,返回该节点的指针
}
cur = cur->next; // 移动到下一个节点
}
return NULL; // 没找到,返回 NULL
}📌 重点解释:
strcmp(cur->data.name, name):strcmp是标准库函数,用于比较两个字符串。如果相等,返回 0;如果第一个字符串小于第二个,返回负数;如果大于,返回正数。while (cur):这是一个简洁的写法,等价于while (cur != NULL)。只要cur不是空指针,就继续循环。
(4) 删除联系人 (DelContact)
void DelContact(contact** con) {
char name[NAME_MAX];
printf("请输入要删除的用户姓名:\n");
scanf("%s", name);
contact* pos = FindByName(*con, name); // 先找到节点
if (pos == NULL) {
printf("要删除的用户不存在,删除失败!\n");
return;
}
SLTErase(con, pos); // 调用链表删除函数
printf("删除成功!\n");
}(5) 展示所有联系人 (ShowContact)
void ShowContact(contact* con) {
// 打印表头
printf("%-10s%-4s%-4s%15s%-20s\n", "姓名", "性别", "年龄", "联系电话", "地址");
contact* cur = con;
while (cur) {
// %-10s 表示左对齐,宽度为10;%-4s 表示左对齐,宽度为4;%15s 表示右对齐,宽度为15
printf("%-10s%-4s%-4d%15s%-20s\n",
cur->data.name,
cur->data.sex,
cur->data.age,
cur->data.tel,
cur->data.addr);
cur = cur->next;
}
}(6) 保存数据到文件 (SaveContact)
void SaveContact(contact* con) {
FILE* pf = fopen("contact.txt", "wb"); // 以二进制写入模式打开文件
if (pf == NULL) {
perror("fopen error!\n"); // 打印错误信息
return;
}
contact* cur = con;
while (cur) {
fwrite(&(cur->data), sizeof(cur->data), 1, pf); // 写入结构体
cur = cur->next;
}
fclose(pf); // 🚨 记得关闭文件!
printf("通讯录数据保存成功!\n");
}(7) 程序退出时,销毁链表并保存数据 (DestroyContact)
void DestroyContact(contact** con) {
SaveContact(*con); // 先保存数据
SListDesTroy(con); // 再销毁链表,释放所有内存
}3. 主程序 (main.c)
// main.c
#include "contact.h"
int main() {
contact* con = NULL; // 通讯录头指针,初始为空
InitContact(&con); // 初始化,加载历史数据
int choice;
do {
printf("\n======== 通讯录系统 ========\n");
printf("1. 添加联系人\n");
printf("2. 删除联系人\n");
printf("3. 查找联系人\n");
printf("4. 显示所有联系人\n");
printf("0. 退出\n");
printf("请选择: ");
scanf("%d", &choice);
switch (choice) {
case 1:
AddContact(&con);
break;
case 2:
DelContact(&con);
break;
case 3:
FindContact(con);
break;
case 4:
ShowContact(con);
break;
case 0:
printf("再见!\n");
break;
default:
printf("无效选择!\n");
}
} while (choice != 0);
DestroyContact(&con); // 退出前销毁链表并保存数据
return 0;
}🧩 六、经典 OJ 题目:练练手,巩固知识!
链表经典算法OJ题⽬
- 移除链表元素 :遍历链表,删除所有值等于
val的节点。 - 反转链表:将链表的顺序完全颠倒过来。技巧是使用三个指针。
- 合并两个有序链表:像归并排序一样,合并成一个新的有序链表。
- 链表的中间结点:快慢指针的经典应用。
- 分割链表 :给定一个值
x,将链表分割成两部分,小于x的在左边,大于等于x的在右边。
题目的答案在下一篇博客里!!!
💬 结语:别怕,链表没那么难!
看到这里,相信你对单链表已经有了一个清晰的认识。记住几个关键点:
✅ 理解指针和内存管理 是学好链表的基础。 ✅ 善用二级指针 来修改头指针。 ✅ 时刻检查空指针 和内存分配是否成功 。 ✅ 记得释放内存 ,避免内存泄漏。 ✅ 字符串比较用 strcmp ,别用 ==!
链表看起来复杂,但只要掌握了它的"游戏规则",你会发现它其实非常强大和灵活。希望这篇笔记能帮你少走弯路,早日成为链表高手!

