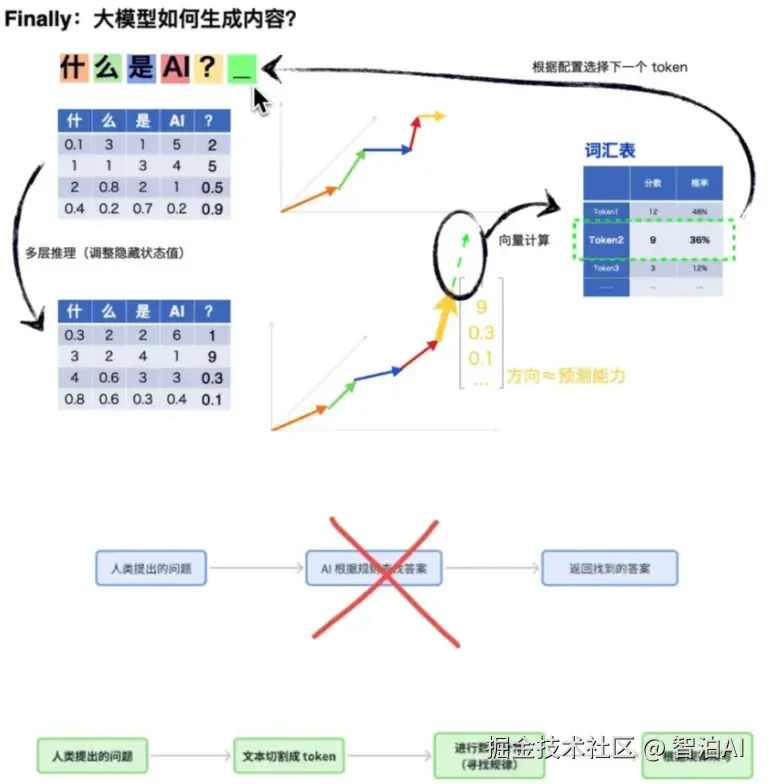
01 文本分割成Token
什么是Token?
Token: 单词表,大模型"推理"和"生成"的最小计算单位
Token数和单词/汉字数没有一一对应关系,以对DeepSeek V3为例
1个中文字符 ≈ 0.6 个Token
1个英文字符 ≈ 0.3个Token
文章篇幅有限,不便展示AI大模型全部资源。更多AI大模型学习视频及资源,都在智泊AI。
为什么进行分割Token?
把句子拆成Token的目的是为了方便进行后面的推理数学计算。
举个栗子
我们发送文本(Prompt)内容为"生成式AI是什么东西?"给大模型后,大模型先会按照模型预训练时的分词规则将我们的Prompt进行拆分,分割成"生成、式、AI、是什么、东西、?"6个Token。
图示如下

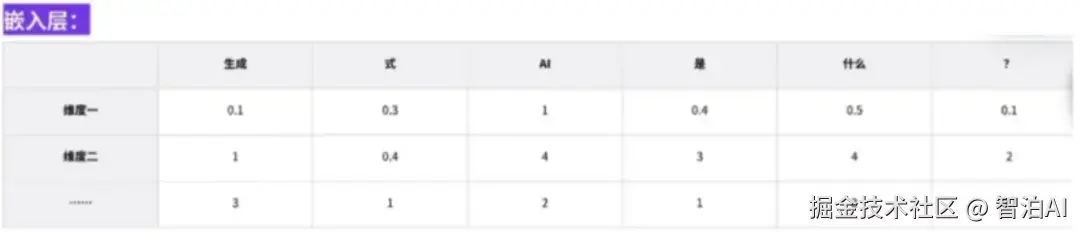
02 嵌入-向量化
把文字向量化
嵌入层: 大模型会将已经拆分好的Token嵌入到它的Token单词表中进行随机的标号,这个标号也叫做嵌入。
嵌入-向量化: 可以实现对语言中最小组成部分(Token)的对比和归类。
图示如下
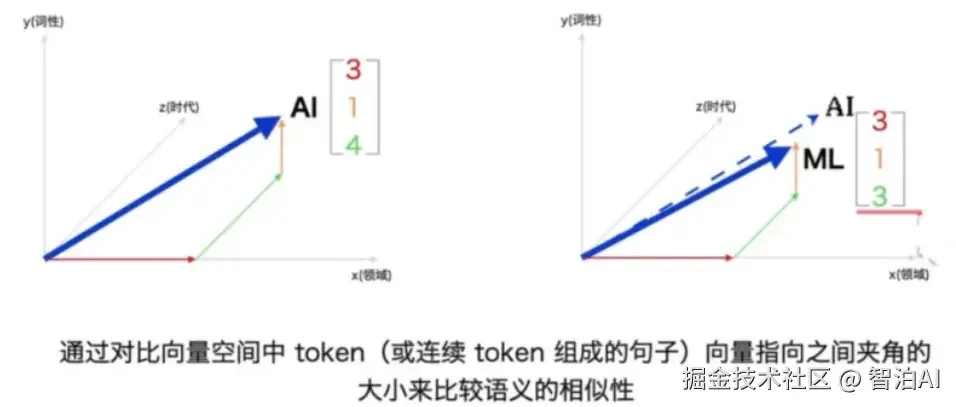
03 多层推理
调整隐藏状态值
推理层: 自注意力机制对已嵌入的Token与该词所在单词表中的位置和与其他词的关系进行隐藏状态值调整。
隐藏状态值: 这一层调整的不是嵌入层标号的参数,那个参数嵌入后就已经固定了,它调整的是隐藏状态值。
图示如下
04 向量计算-最终预测
调整隐藏状态值
掌握规律: 通过推理层对整句提示词中的隐藏状态值调整完成后,就能得到token的整体走向趋势(规律)。
预测生成词: 根据已掌握的整体走向规律,会进行下一个生成词的预测,预测结果包含但不限于去搞概率的词。
预测生成词: 将选择的Token作为下一个Token加到句子中,然后又生成了一个新的一句话,重复上面的(1、2、3)步骤,直到大模型计算完了后面不需要有了,非常合理了,以'。'结束。
一图回顾