想象一下,当语音模型不仅能听懂你的话,还能根据你所给出的例子进行举一反三,搞定全新的语音任务。小米最新推出的 MiMo-Audio-7B-Instruct 做到了这一点。这全都归功于它首次将大语言模型领域的「涌现」能力和「少样本学习」能力移植到了语音模型上。
MiMo-Audio-7B-Instruct 基于创新预训练架构和上亿小时训练数据,打破了语音领域依赖大规模标注数据的瓶颈。在开源模型的语音智能与音频理解基准测试中均达到了 SOTA 水平。除标准指标外,该模型还能泛化到训练数据中未涵盖的任务,如语音转换、风格迁移和语音编辑。此外,MiMo-Audio-7B-Base 具备强大的语音续写能力,可生成高度逼真的脱口秀、朗诵、直播和辩论内容。
使用云平台:OpenBayes
openbayes.com/console/sig...
登录 OpenBayes.com,在「公共教程」页面,选择一键部署 「MiMo-Audio-7B-Instruct:小米开源的端到端语音模型」教程。
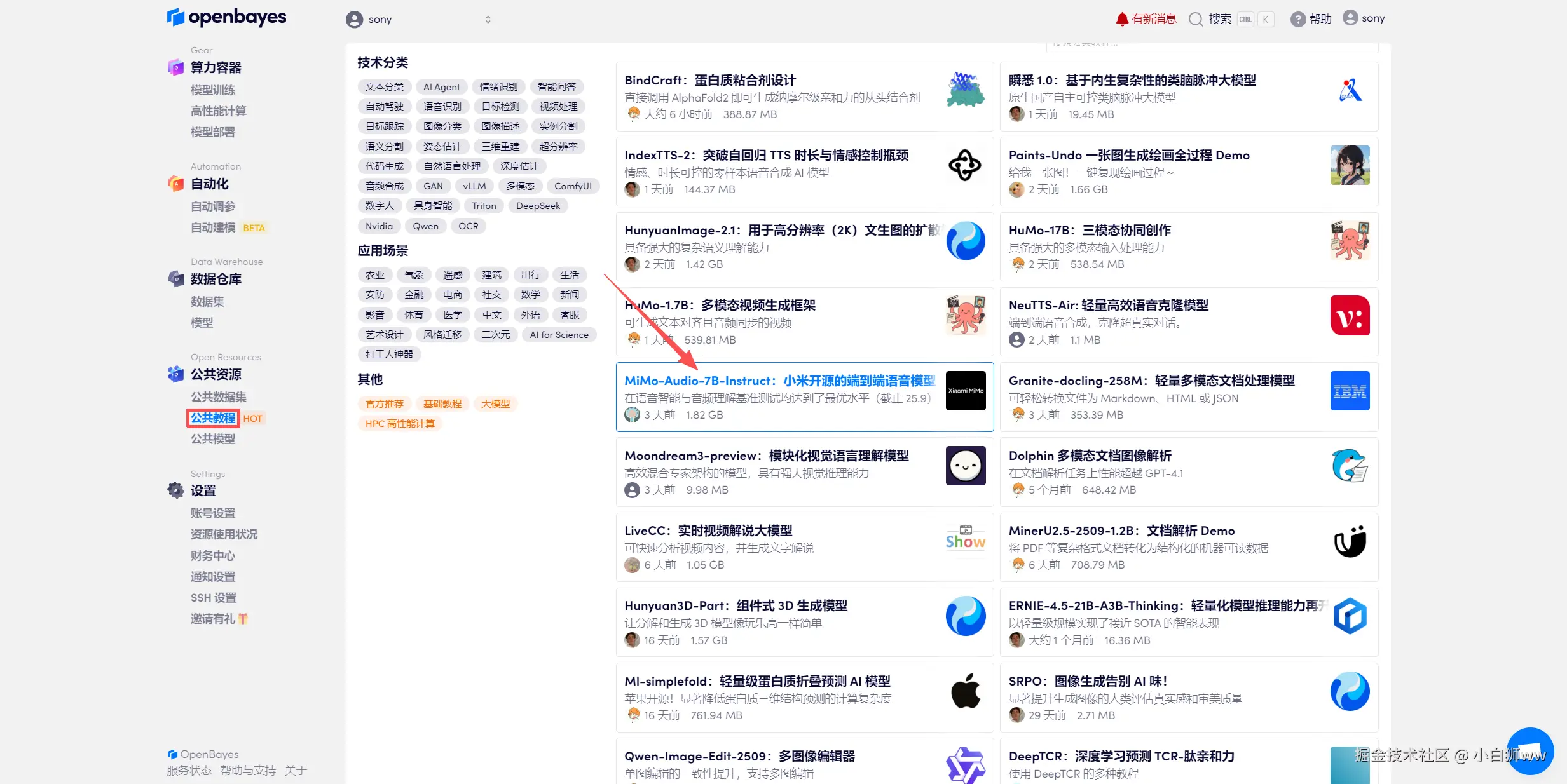
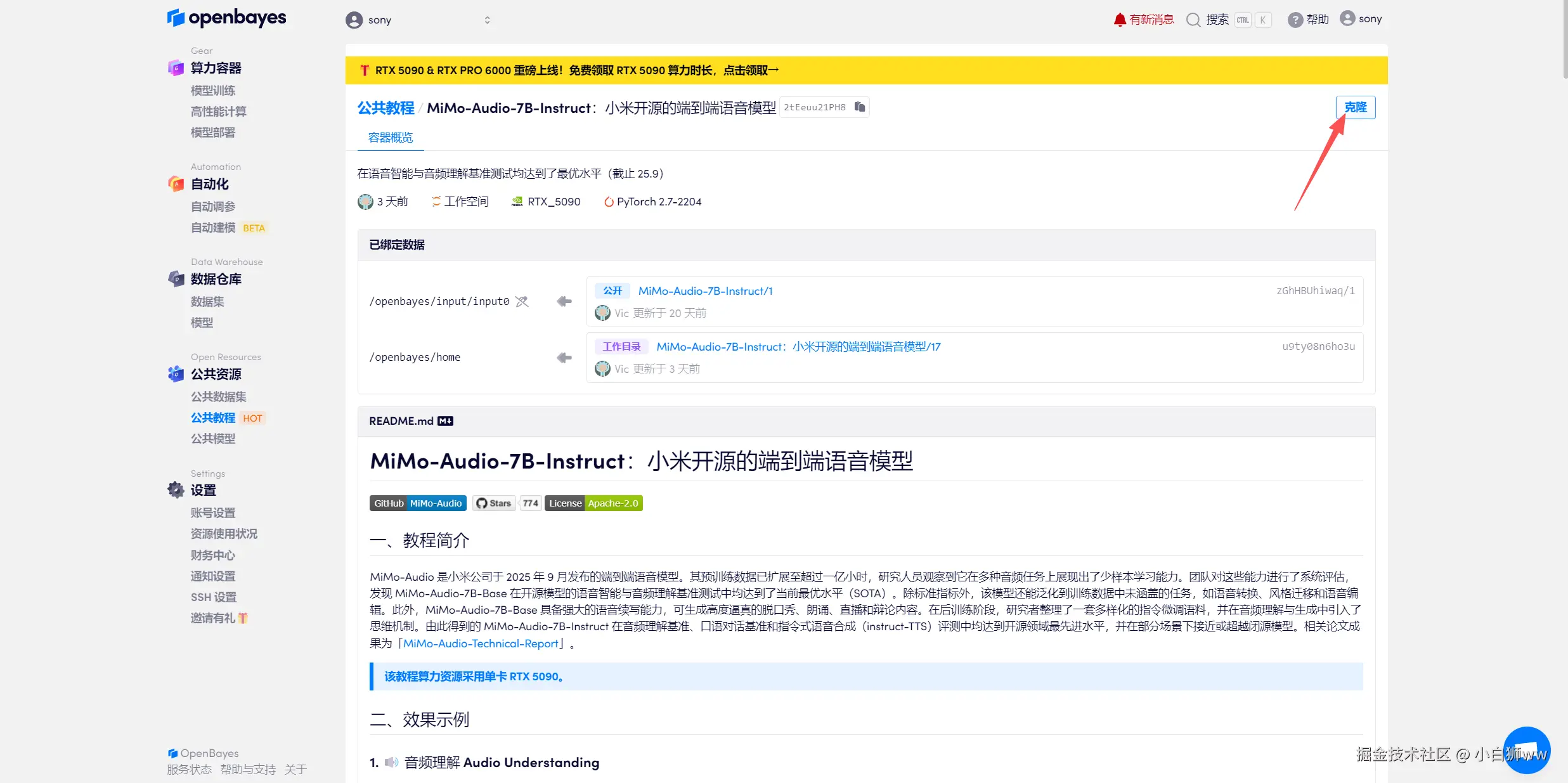
页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
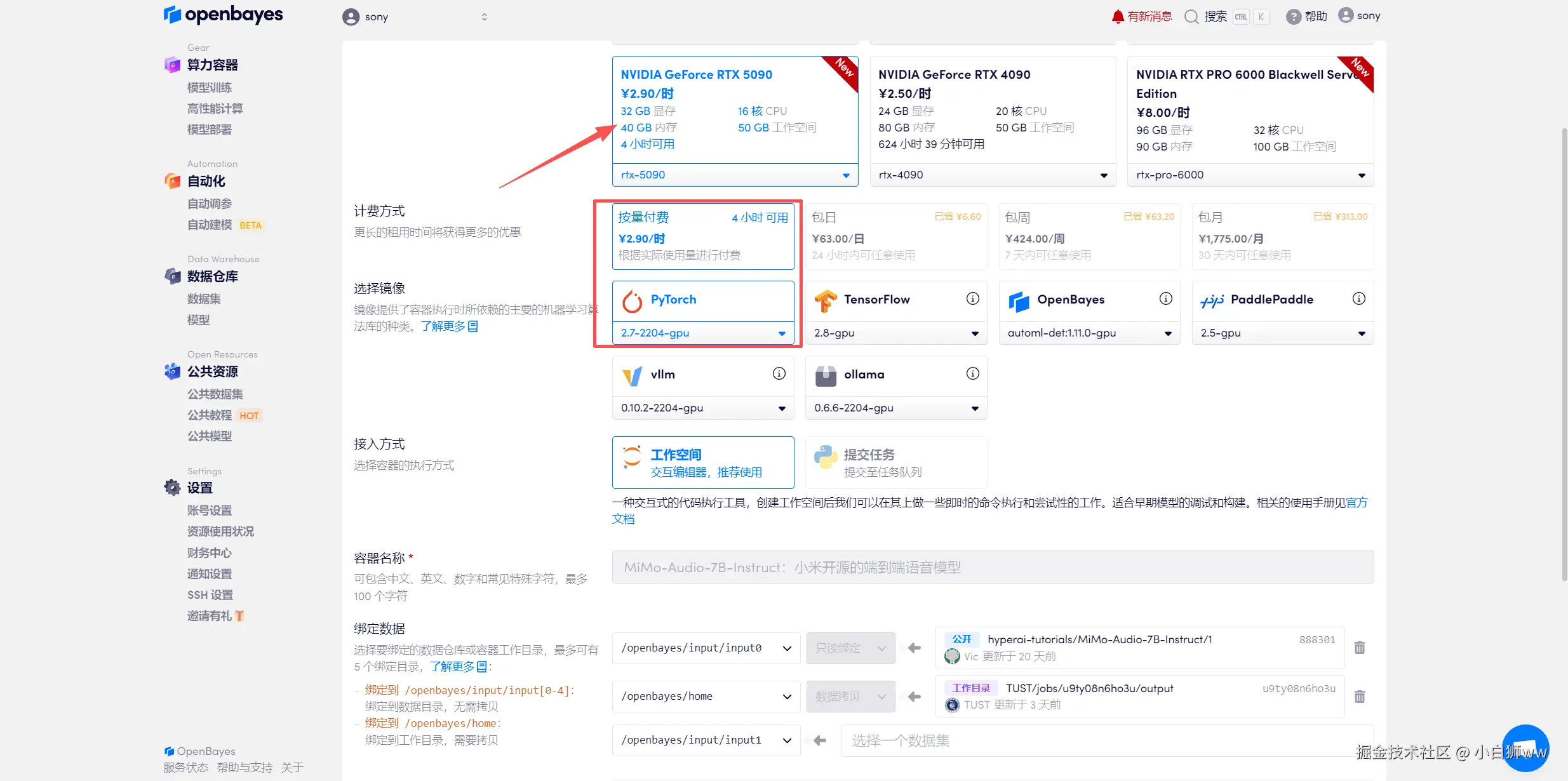
在当前页面中看到的算力资源均可以在平台一键选择使用。平台会默认选配好原教程所使用的算力资源、镜像版本,不需要再进行手动选择。点击「继续执行」,等待分配资源。
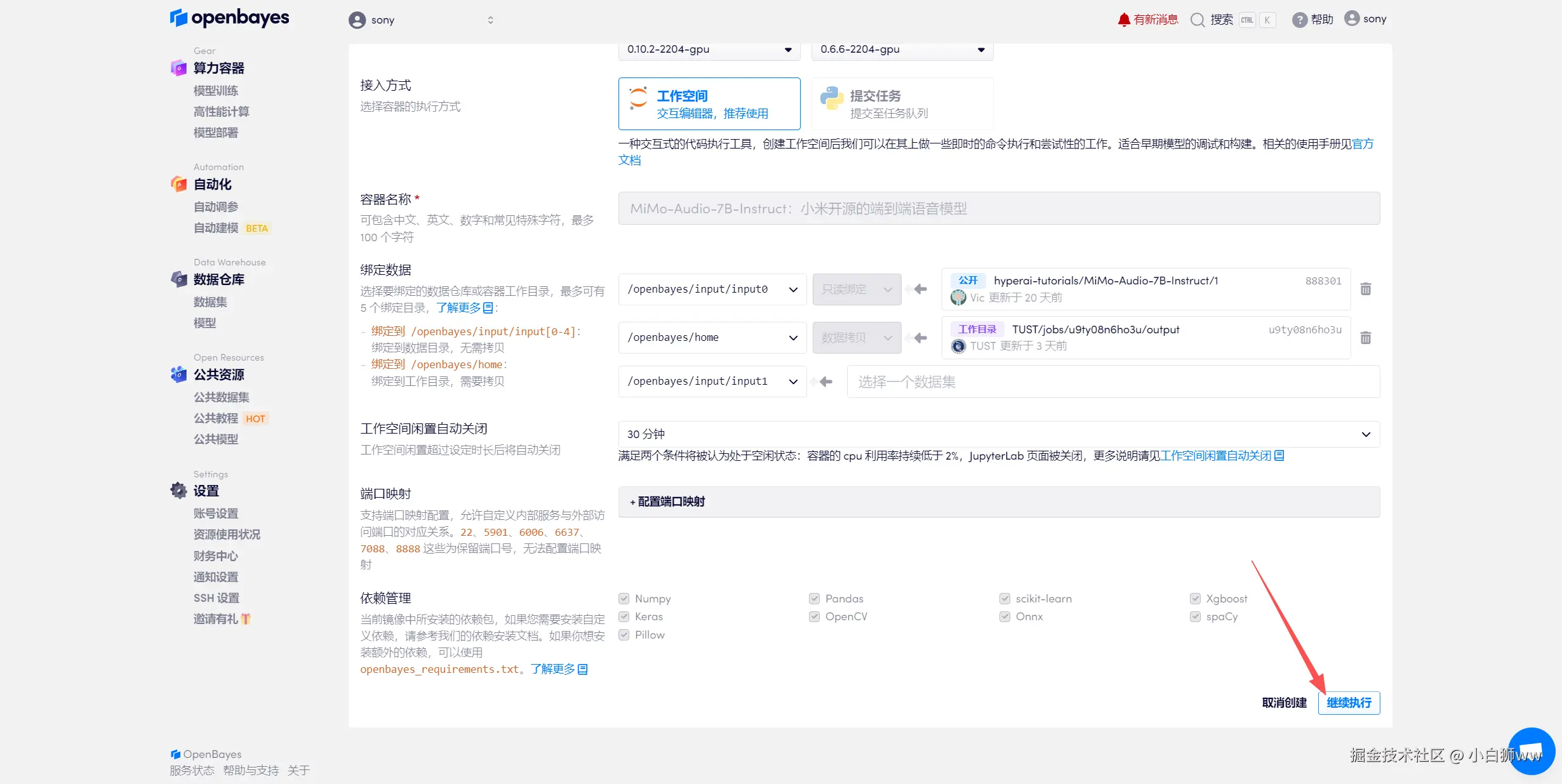
待系统分配好资源,当状态变为「运行中」后,点击「API 地址」边上的跳转箭头,即可跳转至 Demo 页面。
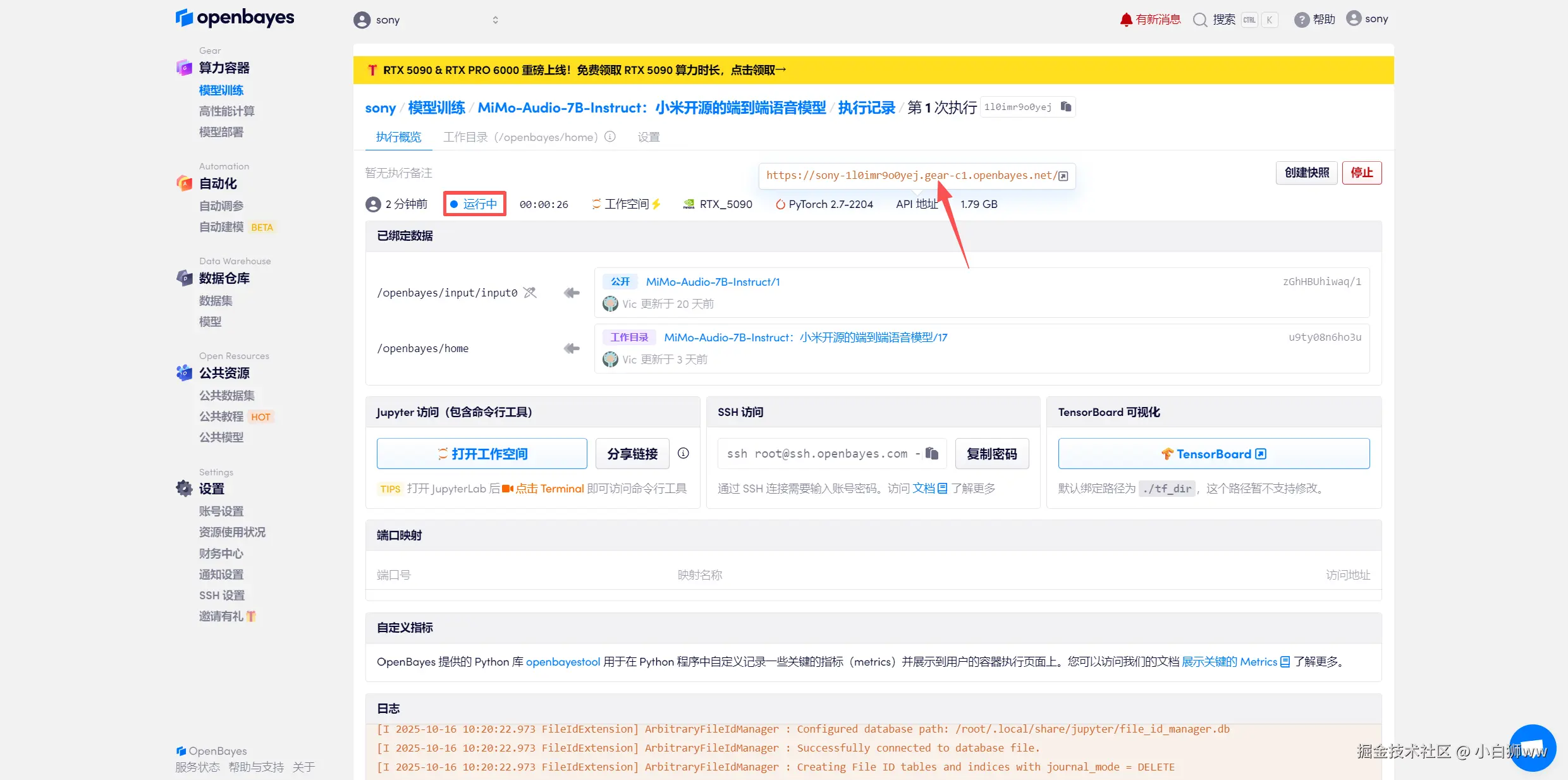
模型提供了 5 种功能,下面逐一进行演示:
进入 Demo 界面后,首先要初始化权重参数。在「Model Configuration」中使用默认路径,点击「Initialize model」对模型进行初始化。
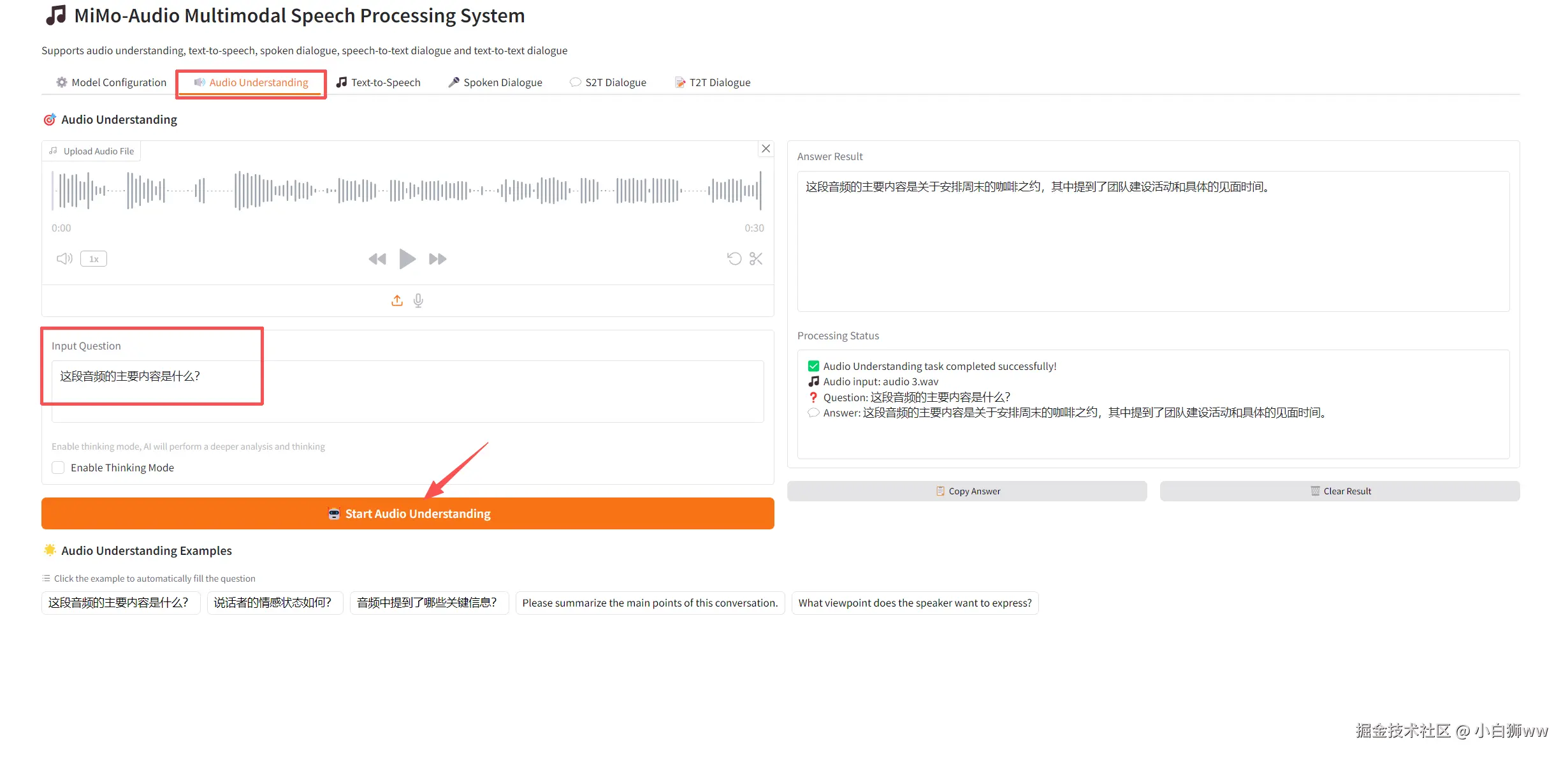
音频理解(Audio Understanding)
上传一段音频,在「input Question」中输入问题,然后点击「Start Audio Understanding」开始识别。
音频生成(Text-to-Speech)
在「Input Text」和「Style Description (Optional)」中分别输入需要转换的内容和音频指令,点击「Generate Speech」开始生成。
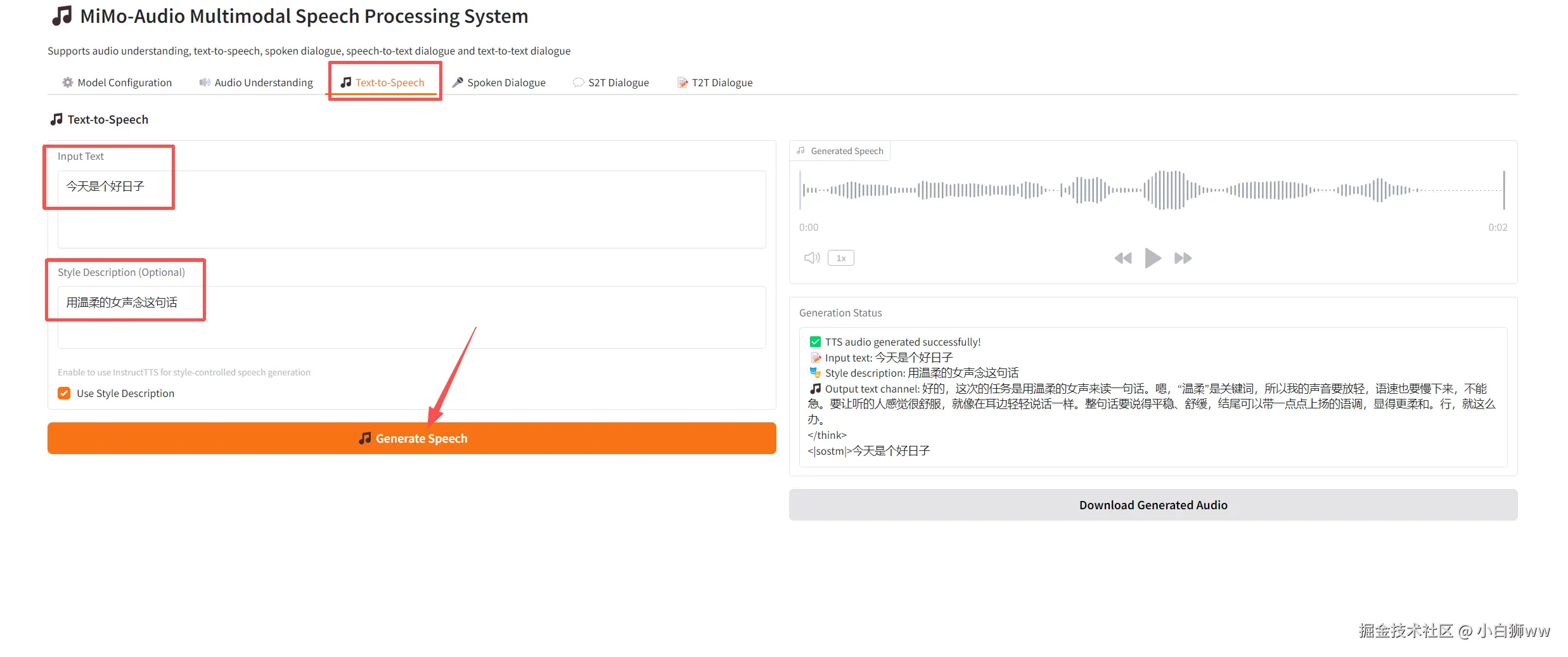
语音对话(Spoken Dialogue)
首先上传一段语音,在「System Prompt (Optional)」中输入提示词,在「Prompt Speech」中可输入输出语音的模板,点击「Start Dialogue」开始生成。
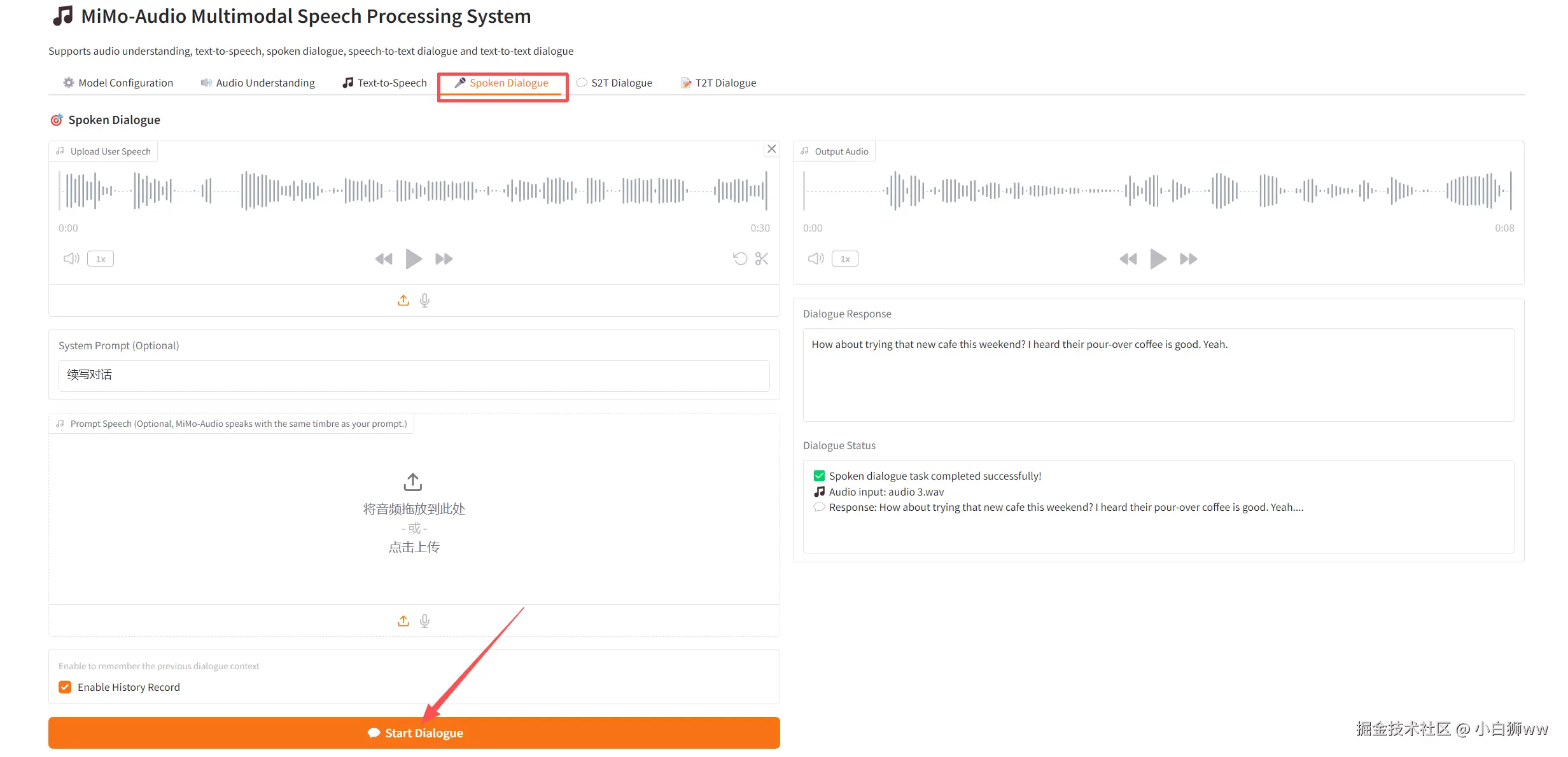
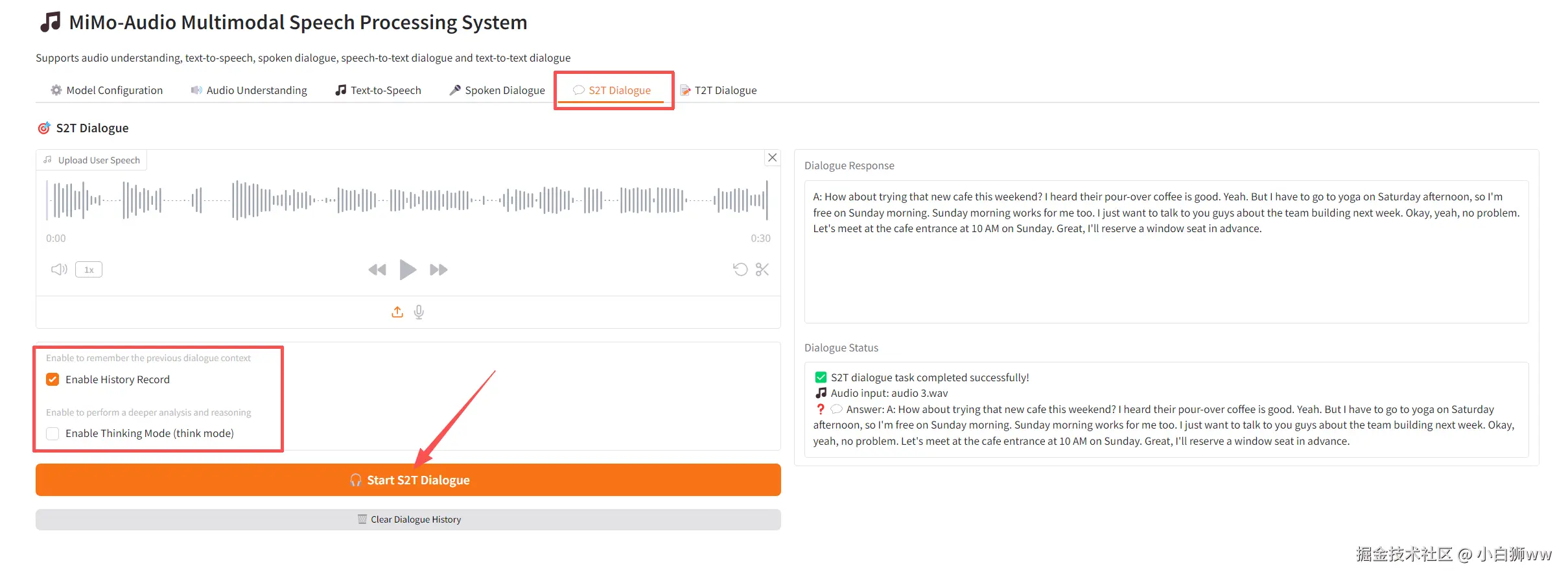
语音-文字对话(S2T Dialogue)
首先上传一段语音,可选择开关历史记录和思考模式,点击「Start S2T Dialogue」开始生成。
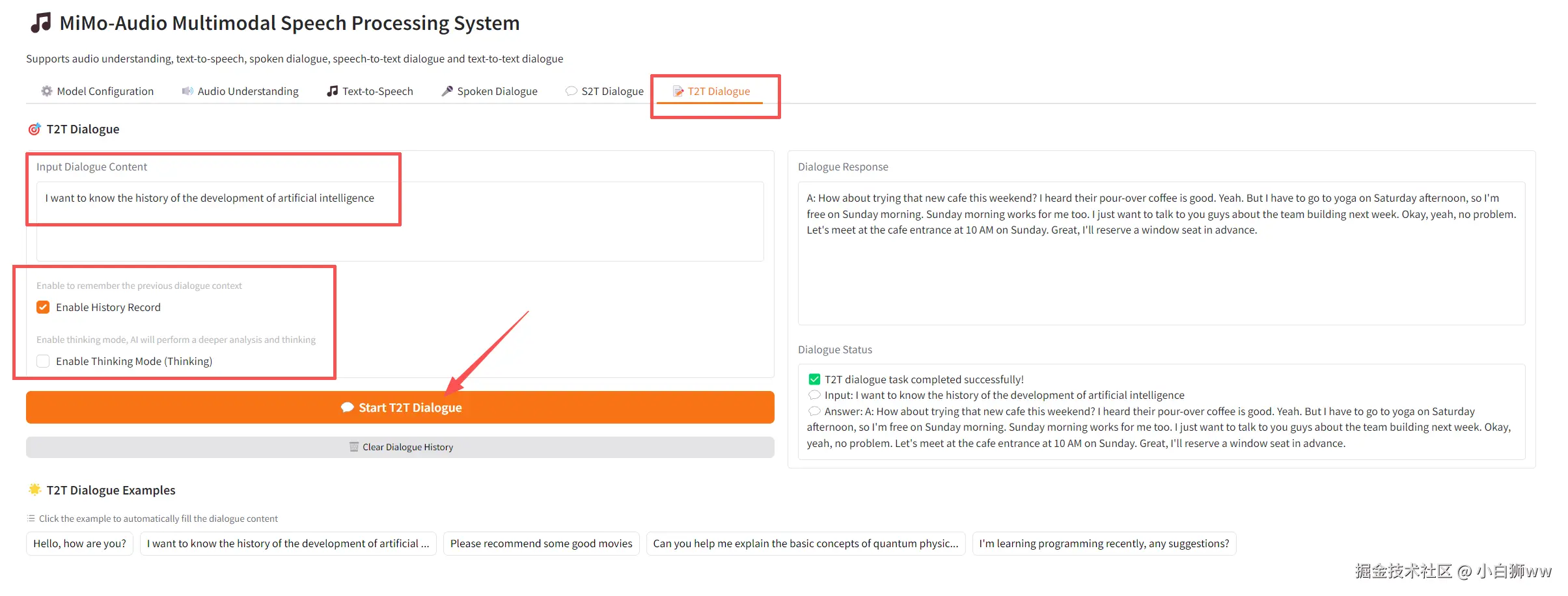
文字-文字对话(T2T Dialogue)
在「Input Dialogue Content」中输入问题,选择开关历史记录和思考模式,点击「Start T2T Dialogue」开始文本对话。