目录
[1.Self-supervised Learning](#1.Self-supervised Learning)
[Next sentence predition](#Next sentence predition)
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是Self-supervised Learning的基础概念以及BERT训练方式和BERT用在下游任务的例子
1.Self-supervised Learning
首先supervised是什么?就是一个model,输入一个x输出一个y,要让输出的y是我们所期待的,就要有label的资料,用label的资料去训练。
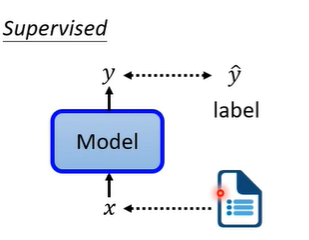
那什么是self-supervised呢?假设我们现在有一堆文章但是没有标注,我们把资料分为两部分,一部分作为模型的输入,一部分作为模型的标注。然后输出的y让他跟作为标注的资料对比,越接近越好。这就是self-supervised learning。
2.BERT
BERT其实就是transformer的encoder,通常用在自然语言处理上,所以它的输入一般为文字。
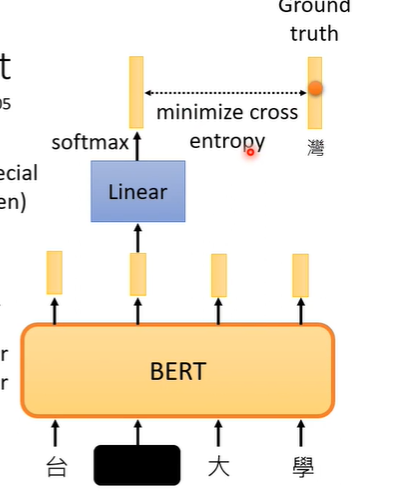
MASKING
假设输入一段文字,我们随机盖住一些文字,即将文字换为特殊符号(mask),或者随机替换为其他文字。之后用盖住部分对应的BERT输出的向量,做一个linear transform(乘一个矩阵),再做softmax,得到包含所有中文字(常见,自己设定的长向量)一个分布。
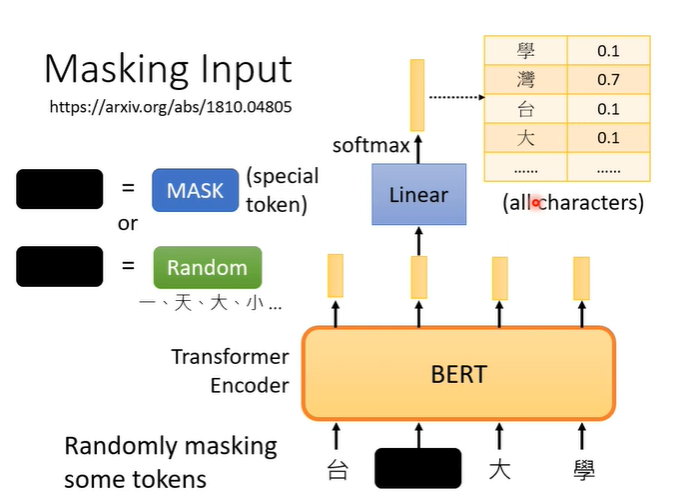
那么BERT需要训练的是,这个盖住部分对应的BERT输出的向量,要与原本被盖住前的字越接近越好。训练时BERT和Linear一起训练,这个训练方法叫做masking。
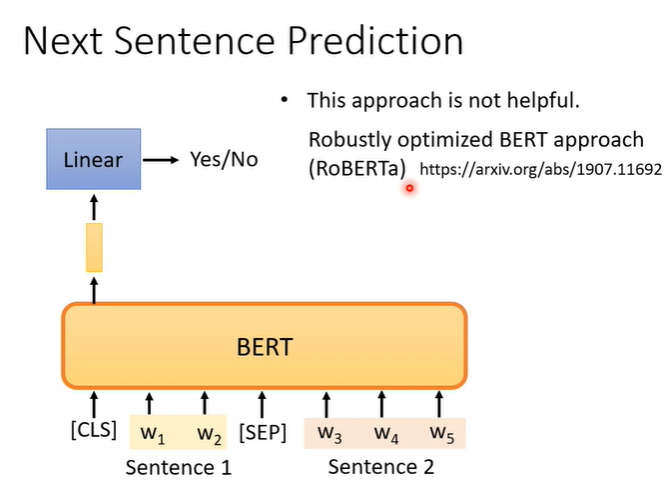
Next sentence predition
另一个方法叫做Next sentence predition,意思是从资料库拿出两个句子,再两个句子间加入特殊的分隔符号(SEP),再两个句子的最前面加入一个特别的符号(CLS),把两个句子和符号一起丢入BERT,我们只取CLS对应的输出,做linear transform,它要做的是一个二元分类的问题,输出yes或no,他要预测的就是这两个句子是否是相接的。
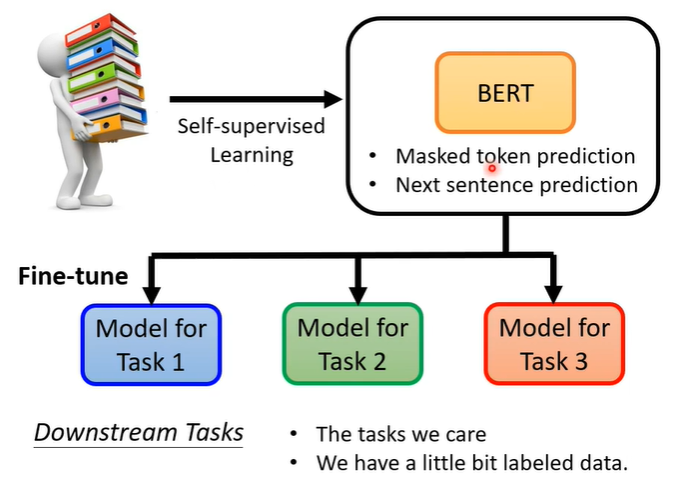
3.Fine-tune
虽然BERT训练时,表现只是会做填空题或者判断两个句子是否可以拼接,但是它可以完成的任务不只是这样而已,还有downstream tasks,但是需要一些有标注的资料。
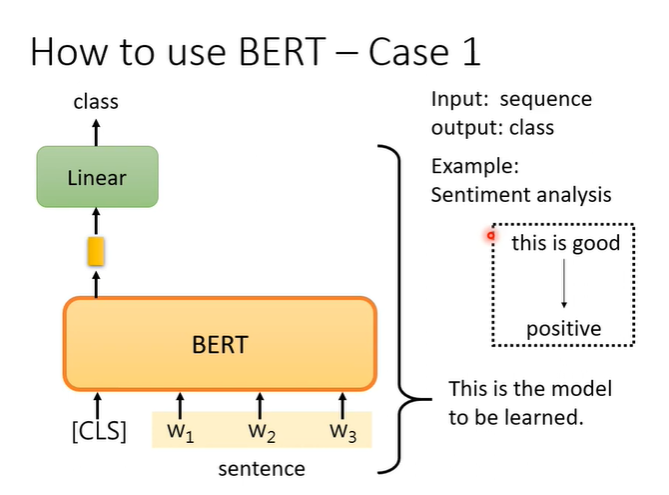
例子1,在sentiment analysis问题上,输入判断的句子,输出一个类别。
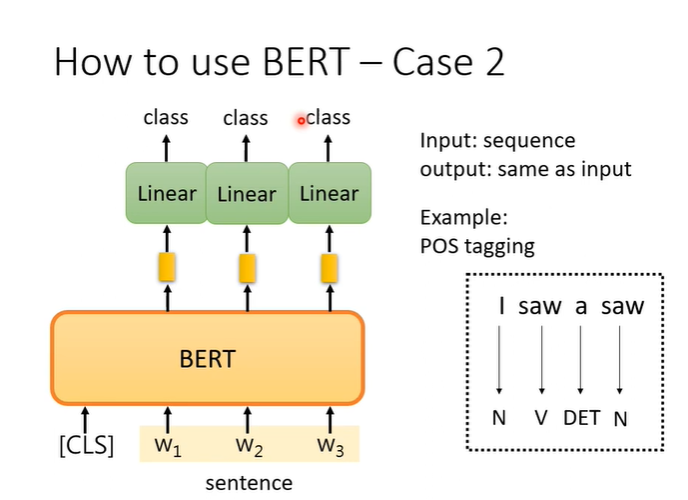
例子2,输入一个句子,输出一个句子但是他们长度相同,例如词性标注问题。
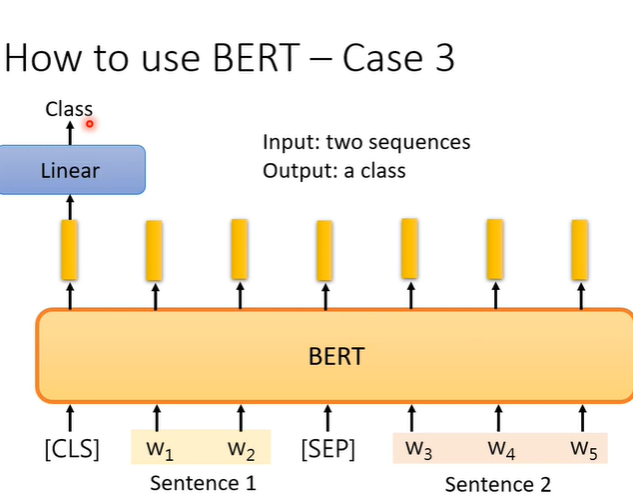
例子3,输入两个句子,输出一个类别,解决分类的问题。例如natural language inference(NLI),就是一个句子是前提,另一个句子是假设,机器要判断这个前提能不能推出这个假设,他们是否矛盾。
例子4,假设答案一定在文章中的问答系统,输入D,Q假设是中文字,那么每个d和q都代表一个中文字,输入是整篇文章D和问题Q,输出是两个正整数s,e。根据s,e从文章中截取出来的文字就是答案。
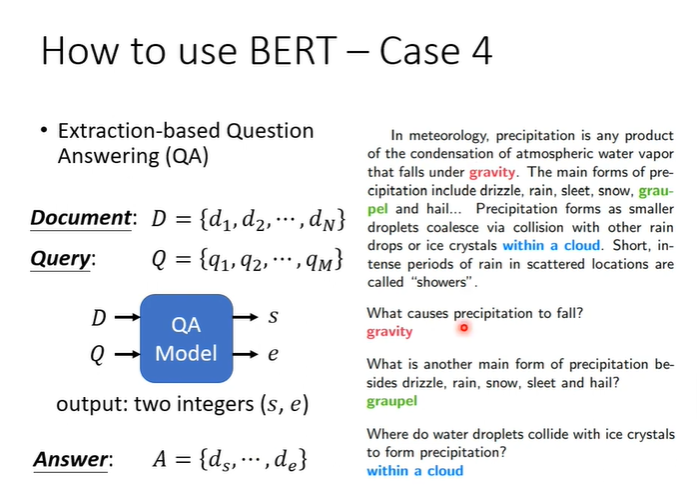
模型要做的事情就是训练两个向量,下图表示为一个橙色,一个蓝色,与文章中的每个文字进行inner product,选出最后得出的分数最高的,一个为起始位置,一个为末尾位置。