了解就好,已经有极其优秀的轮子了,在 java 中类似的数据结构是 HashMap
散列表的实现方式
散列表一般使用 数组+桶(链表/树) 实现。
当两个数据的哈希值相同->存到同一个下标对应的位置->一个下标只有一个位置,怎么解决?
在这个位置建一个链表,将数据存储在链表中,如下图。
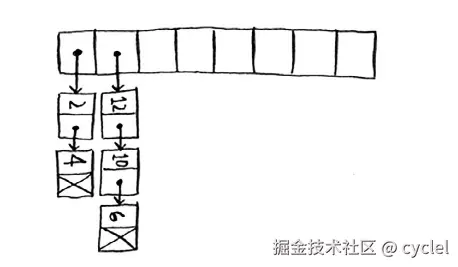
缺点:
当存储空间有限的时候,会出现大量数据堆积在一个位置,但可通过计算添装因子(散列表中已有的数据/位置总数)确定要不要扩容,添装因子超过 0.7 要调整散列表的长度。
散列表的应用:
-
模拟映射关系、
例如:可以使用散列表来存储商店的商品和价格。
散列表内部 通过一个数组 实现,并依赖散列函数 将商品名(如'水')转换为数组索引,在对应索引存储位置上存储 水的价格。
当输入'水'时,散列表会先通过散列函数 找到存储位置(即数组下标) ,再从该位置取出对应的值(价格),最终返回 价格。
散列函数:hash("水") → 数组索引(如 3)。 散列表:根据索引找到桶,再从桶中匹配键 "水",最终返回对应的值 2.5。
cssA[输入商品名 '水'] --> B[散列函数 hash'水' ] B --> C[输出索引 3] C --> D[定位数组索引3的桶] D --> E{桶内搜索键 '水'} E -->|匹配成功| F[返回价格 2.5] -
防止重复数据的出现
-
缓存
例如:浏览器的缓存机制
浏览器缓存的机制是一套 "资源存储、有效性校验、优先级读取" 的完整流程,核心是通过 "规则约定" 和 "HTTP 协议字段",决定 "哪些资源要缓存、缓存多久、下次请求时是否复用缓存"。其机制可拆解为 "缓存的分类""缓存的存储位置""缓存的校验规则" 三个核心维度,三者共同构成浏览器缓存的完整逻辑。
一、第一步:缓存的分类 ------ 按 "是否向服务端确认" 划分
浏览器缓存并非 "一刀切" 存储所有资源,而是根据 "是否需要每次请求前向服务端确认有效性",分为强缓存(强制缓存) 和协商缓存(对比缓存) 两类 ------ 二者的优先级和触发逻辑不同,共同决定资源的复用策略。
1. 强缓存(强制缓存):"本地有有效缓存,就直接用,不发请求"
强缓存是优先级最高 的缓存机制:当浏览器第一次下载资源后,会在本地记录 "缓存有效期";下次需要该资源时,先检查本地缓存是否在有效期内 ------ 若有效,完全不向服务端发送请求 ,直接从本地加载资源(浏览器控制台中显示
200 OK (from cache)或200 OK (memory cache))。强缓存的核心是 "用本地缓存跳过网络请求",效率极高,其有效期通过 HTTP 响应头字段 控制,主要有两个:
响应头字段 作用 兼容性与特点 Cache-Control现代浏览器首选,通过指令明确缓存规则(优先级高于 Expires)支持 HTTP/1.1,指令灵活,如:- max-age=3600:缓存有效期 3600 秒(1 小时);-public:允许中间节点(如 CDN)缓存该资源;-private:仅允许浏览器本地缓存(禁止 CDN 等缓存);-no-cache:不启用强缓存,直接进入协商缓存;-no-store:完全禁止缓存(任何情况下都不存储资源)。Expires早期 HTTP/1.0 字段,通过 "绝对时间" 指定缓存过期时间 兼容性好,但存在缺陷:- 时间基于 "服务端时间",若客户端与服务端时间不一致(如客户端时间调快),会导致缓存提前失效或过期后仍被使用;- 优先级低于 Cache-Control(若两者同时存在,以Cache-Control为准)。示例 :服务端返回一张图片的响应头,通过
Cache-Control设置强缓存 1 小时:makefileHTTP/1.1 200 OK Cache-Control: max-age=3600 Content-Type: image/png Content-Length: 10240浏览器下次请求该图片时,若距离上次下载时间小于 1 小时,直接用本地缓存,不发请求。
2. 协商缓存(对比缓存):"本地有缓存,但需先问服务端'是否可用'"
当强缓存失效(如
max-age过期、资源设置了no-cache)时,浏览器会进入协商缓存流程:先向服务端发送请求,携带 "本地缓存的资源标识" ,由服务端判断本地缓存是否仍有效 ------ 若有效,服务端返回304 Not Modified,浏览器直接复用本地缓存;若无效,服务端返回200 OK并携带新资源,浏览器更新本地缓存。协商缓存的核心是 "服务端决策缓存有效性",避免 "强缓存过期但资源未更新" 的冗余下载,其关键是 "资源标识" 的传递与对比,主要通过两组 HTTP 头字段实现:
客户端请求头(携带本地标识) 服务端响应头(返回资源标识) 标识含义与对比逻辑 If-Modified-SinceLast-Modified基于 "资源修改时间" 的标识:1. 首次请求:服务端返回 Last-Modified: Wed, 12 Oct 2024 10:00:00 GMT(资源最后修改时间),浏览器存储该时间;2. 再次请求:浏览器携带If-Modified-Since: Wed, 12 Oct 2024 10:00:00 GMT(本地存储的时间);3. 服务端对比:若资源最后修改时间 > 请求头时间(资源已更新),返回200+新资源;若 ≤,返回304。If-None-MatchETag基于 "资源内容哈希" 的标识(优先级高于 Last-Modified):1. 首次请求:服务端计算资源内容的哈希值(如 MD5),返回ETag: "abc123def456",浏览器存储该哈希;2. 再次请求:浏览器携带If-None-Match: "abc123def456"(本地存储的哈希);3. 服务端对比:若当前资源哈希 ≠ 请求头哈希(资源内容已变),返回200+新资源;若 =,返回304。为什么需要
ETag?Last-Modified存在缺陷:若资源内容未变,但修改时间被误改(如服务端重新部署但资源未更新),会导致Last-Modified变化,协商缓存失效(冗余下载);而ETag基于内容哈希,只要内容不变,哈希就不变,能更精准判断资源是否更新。二、第二步:缓存的存储位置 ------"不同资源存在不同地方"
浏览器会根据资源的 "使用频率" 和 "大小",将缓存存储在不同位置,读取速度和生命周期不同,优先级从高到低为:Memory Cache(内存缓存)→ Disk Cache(磁盘缓存)→ Service Worker Cache(服务工作线程缓存) 。
存储位置 读取速度 存储内容 生命周期 Memory Cache(内存缓存) 最快(微秒级) 最近访问的 "小体积、高频使用" 资源,如:- 页面渲染必需的 CSS、JS;- 刚加载的小图片、图标。 短(浏览器关闭后清空):内存空间有限,当内存不足时,会优先淘汰 "不常用的内存缓存"。 Disk Cache(磁盘缓存) 较慢(毫秒级) 大部分缓存资源,如:- 大体积资源(如大图、视频片段);- 非即时渲染但需长期复用的资源(如公共 CSS、第三方库)。 长(按缓存规则过期,浏览器关闭后仍保留):磁盘空间大,存储更持久,是浏览器缓存的核心。 Service Worker Cache(服务工作线程缓存) 中等 由前端代码(Service Worker)主动控制的缓存,如:- PWA(渐进式 Web 应用)的离线资源;- 自定义需要 "离线可用" 的资源(如文档、静态页面)。 由代码控制(需手动通过 API 删除或更新):完全脱离浏览器默认缓存逻辑,是 "可编程缓存"。 读取优先级逻辑:当浏览器需要某资源时,会按 "Memory Cache → Disk Cache → Service Worker Cache" 的顺序查找 ------ 若内存中有,直接用;若没有,查磁盘;若磁盘也没有,再通过 Service Worker 判断;都没有则发起网络请求。
三、第三步:缓存的完整流程 ------"从首次请求到再次请求"
结合 "分类" 和 "存储位置",浏览器缓存的完整流程可分为 "首次请求" 和 "再次请求" 两个阶段,清晰体现其机制:
1. 首次请求资源(无本地缓存)
- 浏览器向服务端发送 HTTP 请求(如请求
index.css); - 服务端处理请求,返回资源及 "缓存规则头"(如
Cache-Control: max-age=3600、ETag: "abc123"); - 浏览器接收资源,按 "存储位置规则" 将资源存入 Memory Cache(即时使用)和 Disk Cache(长期复用);
- 浏览器渲染页面,使用刚下载的资源。
2. 再次请求同一资源(有本地缓存)
-
浏览器先检查 Memory Cache :若有且未失效,直接使用(返回
200 from memory cache); -
若 Memory Cache 无,检查Disk Cache:
-
若 Disk Cache 无,直接发起网络请求(同首次请求);
-
若 Disk Cache 有,先触发强缓存校验:
-
若强缓存有效(
max-age未过期 /Expires未到),直接使用 Disk Cache(返回200 from disk cache); -
若强缓存失效,触发协商缓存校验:
① 浏览器携带 "本地标识"(
If-Modified-SinceIf-None-Match)向服务端发送请求;② 服务端对比标识:
- 若标识一致(资源未更新),返回
304 Not Modified,浏览器复用 Disk Cache; - 若标识不一致(资源已更新),返回
200 OK + 新资源 + 新缓存规则,浏览器更新 Disk Cache,再使用新资源。
- 若标识一致(资源未更新),返回
-
-
四、特殊场景:缓存的 "失效与更新"
浏览器缓存并非永久有效,当资源需要更新时(如网站改版,CSS 样式变化),需通过以下方式让缓存失效,确保用户获取最新资源:
-
资源路径加 "版本号" 或 "哈希值" :最常用的方式,如将
style.css改为style.v2.css或style.abc123.css(哈希值随内容变化)------ 由于路径不同,浏览器会认为是 "新资源",直接发起网络请求,避免复用旧缓存。(这也是前端工程化工具如 Webpack、Vite 自动处理缓存的核心原理)。 -
设置
Cache-Control: no-cache或no-store:- 对 "频繁更新的资源"(如首页 HTML、实时数据接口),设置
no-cache(跳过强缓存,每次都走协商缓存); - 对 "绝对不能缓存的资源"(如用户登录态、验证码图片),设置
no-store(完全不存储缓存,每次都发新请求)。
- 对 "频繁更新的资源"(如首页 HTML、实时数据接口),设置
-
服务端更新资源时同步更新
ETag或Last-Modified:当资源内容变化时,服务端会生成新的ETag(内容哈希变化)或更新Last-Modified(修改时间变化),协商缓存时会触发200响应,更新本地缓存。
- 浏览器向服务端发送 HTTP 请求(如请求
| 散列表的核心元素 | 快递柜的对应元素 | 映射逻辑 |
|---|---|---|
| Key(键) | 取件码(如 12-3) | 你手中的取件码就是 "键" |
| 哈希函数 | 快递柜的地址规则 | 比如 "取件码前两位是柜号,后一位是格子号",就是 "哈希函数",通过取件码计算出格子地址 |
| 哈希地址 | 快递格子位置(如 12 号柜 3 号格) | 计算出的 "地址",直接定位存储位置 |
| Value(值) | 你的快递包裹 | 地址对应的 "目标内容" |
| 哈希冲突 | 两个取件码算出同一格子 | 此时快递员会用 "备用格子"(类似散列表的冲突解决) |