
Java 大视界 -- Java 大数据在智能电网电力市场交易数据分析与策略制定中的关键作用
- 引言:
- 正文:
-
- 一、智能电网电力市场交易概述
-
- [1.1 电力市场交易模式](#1.1 电力市场交易模式)
- [1.2 电力市场交易数据特点](#1.2 电力市场交易数据特点)
- [二、Java 大数据技术在电力市场交易数据分析中的应用](#二、Java 大数据技术在电力市场交易数据分析中的应用)
-
- [2.1 数据采集与存储](#2.1 数据采集与存储)
- [2.2 数据分析与挖掘](#2.2 数据分析与挖掘)
- [三、基于 Java 大数据的电力市场交易策略制定](#三、基于 Java 大数据的电力市场交易策略制定)
-
- [3.1 价格预测策略](#3.1 价格预测策略)
- [3.2 风险评估策略](#3.2 风险评估策略)
- 四、实际案例分析:某电力公司的电力市场交易优化
-
- [4.1 案例背景](#4.1 案例背景)
- [4.2 解决方案实施](#4.2 解决方案实施)
- [4.3 实施效果](#4.3 实施效果)
- 结束语:
- 🗳️参与投票和联系我:
引言:
嘿,亲爱的 Java 和 大数据爱好者们,大家好!我是CSDN(全区域)四榜榜首青云交!在数字技术浪潮奔涌的时代,Java 大数据技术宛如一座闪耀的灯塔,照亮了众多行业的创新征程。
当下,全球能源格局正经历着前所未有的深刻变革,智能电网作为能源革命与数字技术深度融合的标志性成果,已然成为能源领域发展的核心方向。电力市场交易作为智能电网的关键环节,每时每刻都在产生海量且复杂的数据。对这些数据进行深入分析,不仅能够优化电力资源配置,显著提升电网运行效率,还能为电力市场参与者提供科学的决策依据,推动电力市场朝着健康、稳定的方向蓬勃发展。Java 凭借其强大的生态体系、卓越的性能,以及与大数据和机器学习框架的深度融合能力,为智能电网电力市场交易数据分析与策略制定提供了坚实可靠的技术支撑。本文将深入剖析 Java 大数据在智能电网电力市场交易中的应用,结合真实案例与详尽代码,为能源领域的从业者、数据分析师以及技术爱好者,提供极具实操价值的技术指南。

正文:
一、智能电网电力市场交易概述
1.1 电力市场交易模式
智能电网环境下,电力市场交易模式丰富多样,主要包括双边协商交易、集中竞价交易和挂牌交易等。不同交易模式在交易机制、价格形成方式和适用场景等方面各有特点,且这些特点相互关联,共同塑造了电力市场的运行生态。下面从交易全流程视角,对各交易模式进行详细对比:
| 交易模式 | 交易发起阶段 | 交易执行阶段 | 价格形成机制 | 适用场景 | 潜在风险应对策略 |
|---|---|---|---|---|---|
| 双边协商交易 | 大型电力用户与发电企业基于长期合作意向,自主发起交易协商 | 双方通过多轮谈判,确定交易电量、电价,并签订双边交易合同 | 由双方基于自身成本、收益预期以及对市场的研判,协商确定价格 | 适用于大型电力用户与发电企业之间的长期稳定合作,能够满足双方个性化的交易需求 | 建立信用评估体系,加强信息披露,降低信息不对称风险;在合同中明确违约条款,防范信用风险 |
| 集中竞价交易 | 市场参与者在规定时间内,通过市场平台统一申报交易电量和电价 | 市场运营机构按照统一的竞价规则,对申报信息进行处理,确定市场出清价格和交易结果 | 根据市场供需关系,通过竞价机制确定市场出清价格 | 适用于短期电力供需平衡调节,能够充分反映市场价格信号,实现资源的优化配置 | 加强市场监管,严厉打击市场操纵行为;完善竞价规则,提高市场透明度 |
| 挂牌交易 | 卖方根据自身预期,在市场平台上挂牌出售电量和电价 | 买方在规定时间内自主摘牌,完成交易 | 以卖方挂牌价格作为交易价格 | 适用于小型电力用户的零散交易,操作简便,交易效率高 | 建立价格监测机制,及时发现并纠正挂牌价格与市场实际价格的偏差 |
1.2 电力市场交易数据特点
电力市场交易数据具有数据量大、实时性强、多源异构等显著特点,这些特点对数据分析工作提出了严峻挑战。以某省级电力市场为例,随着电力市场交易规模的不断扩大,每天产生的交易记录可达数百万条,数据量超过 1TB。这些数据不仅包含交易双方的基本信息、交易电量、电价等结构化数据,还涵盖电网运行状态、气象数据等非结构化数据。同时,电力市场交易的实时性要求极高,需要在短时间内完成数据的采集、分析和决策,以适应市场的快速变化。以下从数据处理流程角度,对数据特点及其影响进行具体分析:
| 数据特点 | 描述 | 数据采集阶段影响 | 数据存储阶段影响 | 数据分析阶段影响 |
|---|---|---|---|---|
| 数据量大 | 海量的交易记录,数据规模持续增长 | 需要高效的数据采集工具和技术,确保数据的完整性和准确性 | 传统单机存储方式难以满足需求,需采用分布式存储技术 | 传统单机计算方式难以应对,需采用分布式计算技术 |
| 实时性强 | 交易数据实时产生,市场变化迅速 | 要求数据采集系统具备实时采集和传输能力 | 需要实时更新存储的数据,以保证数据的时效性 | 要求数据分析系统具备实时处理能力,及时为决策提供支持 |
| 多源异构 | 数据来源多样,格式和结构复杂 | 增加了数据采集的难度,需要适配不同的数据接口 | 需要对不同格式和结构的数据进行统一处理,增加了存储的复杂性 | 增加了数据整合和处理的难度,需要采用数据清洗、转换等技术 |
二、Java 大数据技术在电力市场交易数据分析中的应用
2.1 数据采集与存储
利用 Java 开发的数据采集系统,能够实时采集电力市场交易数据。为确保数据的可靠性和稳定性,采用 Kafka 等消息队列技术,实现数据的缓冲和异步传输。Kafka 凭借其高吞吐量、低延迟的特性,能够有效应对电力市场交易数据实时性强的挑战。数据采集架构如下:
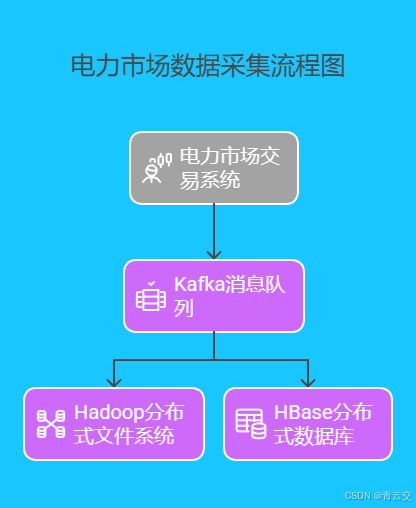
在数据存储方面,采用 Hadoop 分布式文件系统(HDFS)和 HBase 等分布式数据库,实现数据的高效存储和快速查询。HDFS 适合存储大规模的非结构化数据,而 HBase 则擅长处理结构化数据的随机读写。以下是使用 Java 操作 HDFS 进行数据存储的示例代码,添加了详细注释:
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
//该类展示如何使用Java将本地数据存储到HDFS中
public class HDFSDataStorage {
public static void main(String[] args) throws Exception {
//创建Hadoop配置对象
Configuration conf = new Configuration();
//设置HDFS的默认地址
conf.set("fs.defaultFS", "hdfs://localhost:9000");
//获取HDFS文件系统实例
FileSystem fs = FileSystem.get(conf);
//将本地文件复制到HDFS中
fs.copyFromLocalFile(new Path("local_data.txt"), new Path("/hdfs_data.txt"));
//关闭文件系统资源
fs.close();
}
}下面是使用 Java 操作 HBase 进行数据写入的示例代码,并对异常处理机制进行了完善:
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
//该类展示如何使用Java向HBase中写入数据
public class HBaseDataWriter {
public static void main(String[] args) {
try {
//创建HBase配置对象
Configuration conf = HBaseConfiguration.create();
//创建HBase连接
Connection connection = ConnectionFactory.createConnection(conf);
//获取表对象
Table table = connection.getTable(TableName.valueOf("electricity_market"));
//创建Put对象,指定行键
Put put = new Put(Bytes.toBytes("row1"));
//添加列数据
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("col1"), Bytes.toBytes("value1"));
//将数据写入表中
table.put(put);
//关闭表和连接
table.close();
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}2.2 数据分析与挖掘
借助 Apache Spark 等大数据处理框架,可对电力市场交易数据进行深度分析。例如,通过关联规则挖掘算法,分析不同交易因素之间的关联关系,为市场参与者提供决策支持。以下是使用 Spark 进行关联规则挖掘的示例代码,并添加了详细注释,对数据预处理环节进行了细化:
java
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.mllib.fpm.AssociationRules;
import org.apache.spark.mllib.fpm.FPGrowth;
import org.apache.spark.mllib.fpm.FPGrowthModel;
import java.util.ArrayList;
import java.util.List;
//该类展示如何使用Spark进行关联规则挖掘
public class SparkAssociationRules {
public static void main(String[] args) {
//创建Spark配置对象,设置应用名称和运行模式
SparkConf conf = new SparkConf().setAppName("SparkAssociationRules").setMaster("local[*]");
//创建Java Spark上下文对象
JavaSparkContext sc = new JavaSparkContext(conf);
List<List<String>> transactions = new ArrayList<>();
//模拟原始交易数据
String rawData = "item1,item2;item2,item3";
for (String transaction : rawData.split(";")) {
List<String> items = new ArrayList<>();
for (String item : transaction.split (",")) {
items.add(item);
}
transactions.add(items);
}
//将交易数据转换为Spark RDD
JavaRDD<List<String>> rdd = sc.parallelize(transactions);
//创建FPGrowth对象,设置最小支持度和分区数
FPGrowth fpg = new FPGrowth()
.setMinSupport(0.2)
.setNumPartitions(10);
//运行FPGrowth算法,生成关联规则模型
FPGrowthModel<String> model = fpg.run(rdd);
//遍历生成的关联规则,并打印规则前件、后件和置信度
for (AssociationRules.Rule<String> rule : model.generateAssociationRules(0.8)) {
System.out.println(rule.javaAntecedent() + " => " + rule.javaConsequent() + ", " + rule.confidence());
}
//停止Spark上下文
sc.stop();
}
}三、基于 Java 大数据的电力市场交易策略制定
3.1 价格预测策略
利用机器学习算法,如线性回归、决策树等,对电力市场交易价格进行预测。以线性回归为例,使用 Java 的机器学习库 Weka 进行价格预测的示例代码如下,并添加了详细注释,增加了模型评估环节:
java
import weka.core.Attribute;
import weka.core.DenseInstance;
import weka.core.Instance;
import weka.core.Instances;
import weka.regression.LinearRegression;
import weka.core.converters.ConverterUtils.DataSource;
//该类展示如何使用Weka库进行电力市场交易价格预测
public class PricePrediction {
public static void main(String[] args) throws Exception {
// 加载数据集
DataSource source = new DataSource("electricity_price_data.arff");
Instances dataset = source.getDataSet();
dataset.setClassIndex(dataset.numAttributes() - 1);
// 分割数据集为训练集和测试集
Instances train = dataset.trainCV(8, 0);
Instances test = dataset.testCV(8, 0);
//创建线性回归对象
LinearRegression lr = new LinearRegression();
//使用训练数据构建线性回归模型
lr.buildClassifier(train);
// 评估模型
double sumError = 0;
for (int i = 0; i < test.numInstances(); i++) {
double predicted = lr.classifyInstance(test.instance(i));
double actual = test.instance(i).classValue();
sumError += Math.abs(predicted - actual);
}
double averageError = sumError / test.numInstances();
System.out.println("Average Error: " + averageError);
// 创建新的实例,用于预测
Instance newInstance = new DenseInstance(3);
newInstance.setValue((Attribute) dataset.attribute(0), 4.0);
newInstance.setValue((Attribute) dataset.attribute(1), 5.0);
// 预测价格
double predictedPrice = lr.classifyInstance(newInstance);
System.out.println("Predicted Price: " + predictedPrice);
}
}3.2 风险评估策略
通过对电力市场交易数据的分析,评估交易风险。采用层次分析法(AHP)等方法,确定不同风险因素的权重,为市场参与者提供风险预警。具体实施过程中,可构建风险评估指标体系,收集相关数据,运用 AHP 方法计算各指标的权重,从而评估交易风险。风险评估流程如下:
四、实际案例分析:某电力公司的电力市场交易优化
4.1 案例背景
某电力公司在参与电力市场交易时,面临交易决策缺乏数据支持、交易风险难以评估等问题。随着电力市场竞争的日益激烈,传统的经验式决策方法已无法满足公司的发展需求,急需引入先进的数据分析技术,提升交易决策的科学性和准确性。
4.2 解决方案实施
-
数据平台搭建:搭建基于 Hadoop 和 Spark 的大数据平台,实现电力市场交易数据的采集、存储和分析。通过数据采集系统实时获取交易数据,并利用 Kafka 消息队列进行数据缓冲和异步传输,确保数据的可靠性。采用 HDFS 和 HBase 进行数据存储,为后续的数据分析提供支持。
-
分析模型构建:开发价格预测、风险评估等分析模型,为交易决策提供支持。利用 Spark 进行数据挖掘和分析,运用线性回归、关联规则挖掘等算法,挖掘数据中的潜在规律,为交易策略的制定提供依据。
-
策略制定与优化:根据分析结果,制定合理的交易策略,并不断优化。结合价格预测和风险评估结果,确定交易电量和电价,降低交易风险,提高交易收益。
4.3 实施效果
-
交易效益提升:通过价格预测和策略优化,该公司的交易收益提高了 20%。在市场价格波动的情况下,能够准确把握市场机会,制定合理的交易策略,实现收益最大化。
-
风险控制加强:通过风险评估和预警,有效降低了交易风险。提前识别潜在的风险因素,采取相应的风险控制措施,保障了公司的稳健运营。

结束语:
亲爱的 Java 和 大数据爱好者们,Java 大数据技术为智能电网电力市场交易数据分析与策略制定提供了强大的技术支持。通过数据采集、分析与挖掘,以及交易策略的制定与优化,能够显著提升电力市场的运行效率和经济效益。
亲爱的 Java 和 大数据爱好者,在构建电力市场交易分析模型时,你是否尝试过将多种算法进行融合?效果如何?欢迎在评论区分享您的宝贵经验与见解。
诚邀各位参与投票,哪种技术组合对提升电力市场交易决策质量最有效。