
大家好,我是Tony Bai。
"现代 CPU 很快,而内存很慢。"
这句看似简单的陈词滥调,是理解现代高性能编程的唯一"真理"。我们常常致力于优化算法的时间复杂度,却忽略了一个更为根本的性能瓶颈:数据在内存和 CPU 缓存之间的移动 。一次 L1 缓存的命中可能仅需数个时钟周期(~1ns),而一次主内存的访问则需要超过上百个周期(~100ns),这之间存在着超过 100 倍的惊人差距(2020年数据,如下图,近些年内存速度提升,但与L1缓存相比依旧有几十倍的差距)。
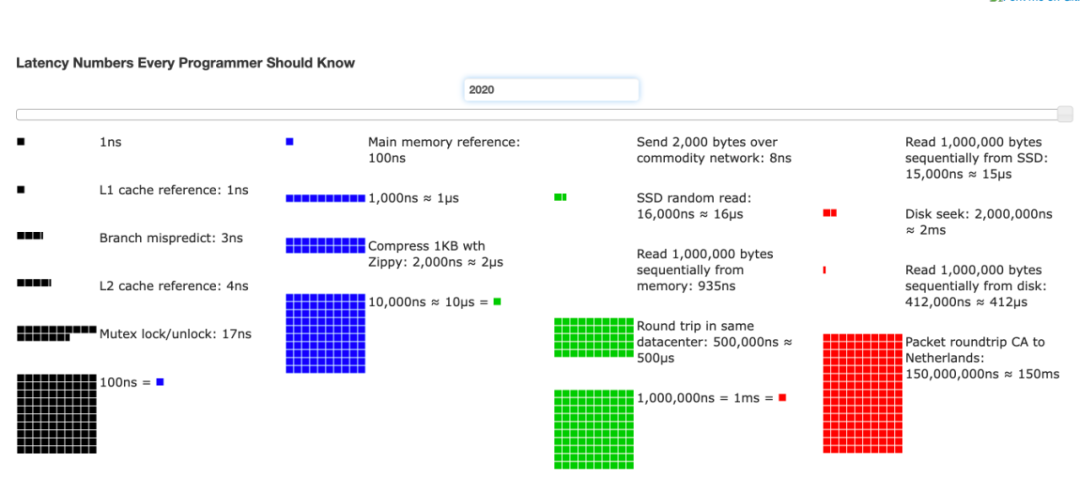
访问延迟,来自参考资料2(2020年数据)
近年来,自从 Go 更换了新的技术负责人后,整个项目对性能的追求达到了前所未有的高度。从GreenTea GC的探索,到对map等核心数据结构的持续优化,再到即将在 Go 1.26 中引入的实验性simd包,无不彰显出 Go 团队提升运行时性能和榨干硬件潜能的决心。
在这个背景下,理解并应用"CPU 缓存友好"的设计原则,不再是少数性能专家的"屠龙之技",而是每一位 Gopher 都应掌握的核心能力。即便算法完全相同,仅仅通过优化数据结构,我们就有可能获得 2-10 倍甚至更高的性能提升。这并非"过早优化",对于性能敏感的系统而言,这是一种必要优化。
本文受Serge Skoredin的"CPU Cache-Friendly Data Structures in Go: 10x Speed with Same Algorithm"启发,将和大家一起从 CPU 缓存的第一性原理出发,并结合完整的 Go 示例与基准测试,为你揭示一系列强大的"数据驱动设计"(Data-Oriented Design) 技术,包括伪共享、AoS vs. SoA、冷热数据分离等,助你编写出真正能与硬件产生"机械共鸣"的 Go 程序。
机械共鸣入门 ------ 深入理解 CPU 缓存架构
在讨论任何优化技巧之前,我们必须先建立一个坚实的心智模型:CPU 是如何读取数据的?答案就是多级缓存。你可以将它想象成一个信息检索系统:
-
L1 缓存 :就在你办公桌上的几张纸。访问速度最快(~1ns),但容量极小(几十 KB)。
-
L2 缓存 :你身后的文件柜。稍慢一些(~3ns),但容量更大(几百 KB)。
-
L3 缓存 :这层楼的小型图书馆。更慢(~10ns),但容量更大(几 MB)。
-
主内存 (RAM):城市另一头的中央仓库。访问速度最慢(~100ns+),但容量巨大(几十 GB)。
CPU 总是优先从最快的 L1 缓存中寻找数据。如果找不到(即缓存未命中, Cache Miss),它会逐级向 L2、L3 乃至主内存寻找,每一次"升级"都意味着巨大的性能惩罚。
这个多层级的结构,解释了为什么"缓存命中"如此重要。但要真正编写出缓存友好的代码,我们还必须理解数据在这条信息高速公路上运输的规则。其中,最核心的一条规则,就是关于数据运输的"集装箱"------缓存行。
缓存行 (Cache Line)
CPU 与内存之间的数据交换,并非以单个字节为单位,而是以一个固定大小的块------缓存行 (Cache Line)------为单位。在现代 x86_64 架构上,一个缓存行通常是 64 字节。
一个生动的比喻:CPU 去仓库取货,从不一次只拿一个螺丝钉,而总是整箱整箱地搬运。
这意味着,当你程序中的某个变量被加载到缓存时,它周围的、在物理内存上相邻的变量,也会被一并 加载进来。这个特性是所有缓存优化的基础。
物理核心、逻辑核心与缓存归属
我们已经知道了数据是以"集装箱"(缓存行)为单位进行运输的。那么下一个关键问题便是:这些集装箱,被运往了谁的"专属仓库"?在 Go 这样一个以并发为核心的语言中,理解多核 CPU 的缓存"所有权"结构,是解开所有并发性能谜题的钥匙。
一个典型的多核 CPU 结构可以用如下示意图来表示:
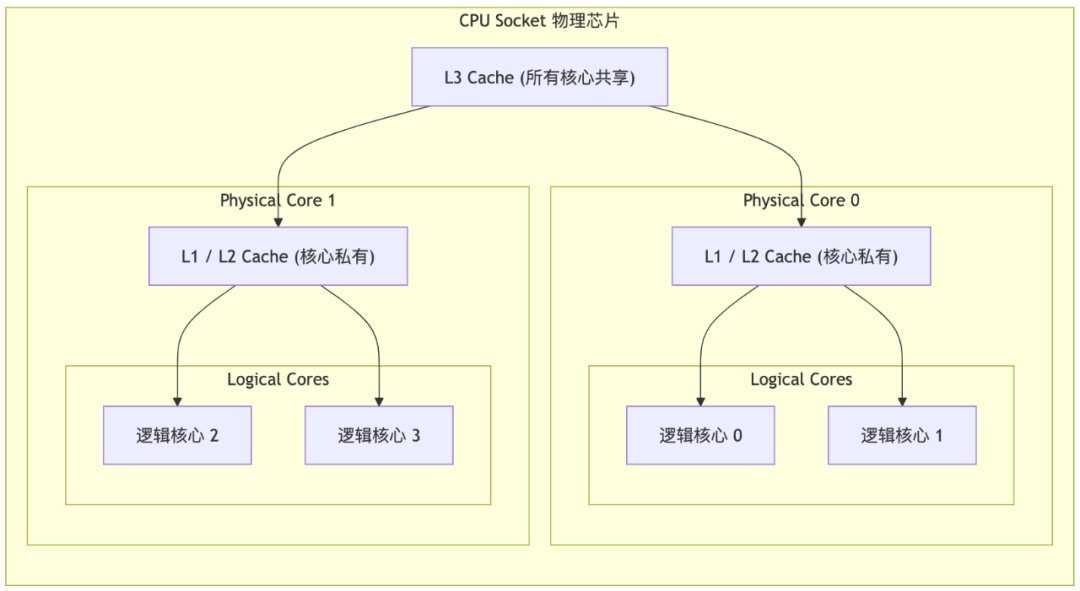
从图中我们看到:
-
L1 和 L2 缓存是物理核心私有的。这意味着,不同物理核心之间的数据同步(例如,当核心0修改了某个数据,核心1也需要这个最新数据时),必须通过昂贵的、跨核心的**缓存一致性协议(MESI)**来进行,这是性能损耗的主要来源。
-
超线程 (Hyper-Threading) 使得一个物理核心能模拟出两个逻辑核心。
-
这两个逻辑核心共享同一个物理核心的 L1 和 L2 缓存。这意味着,运行在同一个物理核心上的两个 goroutine(即使它们在不同的逻辑核心上),它们之间的数据交换非常廉价,因为数据无需离开该核心的私有缓存。
现在,你已经掌握了理解后续所有优化技巧的"第一性原理"。
诊断先行 ------ 如何测量缓存未命中
在进行任何优化之前,我们还必须先学会诊断。"Profile, don't guess" (要剖析,不要猜测) 是所有性能优化的第一原则。对于缓存优化而言,最有力的工具就是 Linux 下的 perf 命令。
perf 可以精确地告诉你,你的程序在运行时发生了多少次缓存引用和缓存未命中。
-
快速概览:
go# 运行你的程序,并统计缓存相关的核心指标 perf stat -e cache-misses,cache-references ./myapp Performance counter stats for './myapp': 175202 cache-misses # 14.582 % of all cache refs 1201466 cache-references 0.125950526 seconds time elapsed 0.038287000 seconds user 0.030756000 seconds syscache-misses与cache-references的比率,就是你的"缓存未命中率",这是衡量程序缓存效率最直观的指标。 -
与 Go Benchmark 结合 :你可以将
perf直接作用于一个已编译为可执行文件的Go 基准测试上。go# 将测试编译为一个可执行文件 go test -c -o benchmark.test # 针对该测试进程进行缓存的负载和未命中分析 perf stat -e cache-misses,cache-references ./benchmark.test -test.benchmem -test.bench "BenchmarkFalseSharing/Padded" goos: linux goarch: amd64 pkg: demo cpu: Intel(R) Xeon(R) CPU E5-2695 v2 @ 2.40GHz BenchmarkFalseSharing/Padded_(No_False_Sharing)-2 292481478 4.109 ns/op 0 B/op 0 allocs/op PASS Performance counter stats for'./benchmark.test -test.benchmem -test.bench BenchmarkFalseSharing/Padded': 279945 cache-misses # 20.848 % of all cache refs 1342771 cache-references 1.644051530 seconds time elapsed 3.188438000 seconds user 0.039960000 seconds sys通过这种方式,我们也可以量化地评估后续章节中各种优化技巧带来的实际效果。
注:建议大家先执行
dmesg | grep -i perf来确认你的物理机器或虚拟机是否有支持perf的驱动,然后再通过apt/yum在你的特定发布版的linux上安装perf:yum install perforapt-get install linux-tools-common。对于特定内核的版本(比如5.15.0),还可以使用类似apt-get install linux-tools-5.15.0-125-generic的命令。
伪共享 (False Sharing) ------ 深入剖析并发性能陷阱
"伪共享" (False Sharing) 是并发编程中最微妙、也最致命的性能杀手之一。
问题根源 :前面说过,现代 CPU 并不以单个字节为单位与内存交互,而是以缓存行 (Cache Line) 为单位。当一个 CPU 核心修改某个变量时,它会获取包含该变量的整个缓存行的独占所有权。如果此时,另一个物理核心 需要修改位于同一个缓存行内的另一个逻辑上独立的变量,就会引发昂贵的缓存一致性协议,强制前一个核心的缓存行失效,并重新从主存加载。这种由物理内存布局导致的、逻辑上不相关的核间竞争,就是伪共享。
实验设计:并发计数器
为了精确地量化伪共享的影响,我们设计了一个基准测试。该测试包含两种结构体:CountersUnpadded(计数器紧密排列,可能引发伪共享)和 CountersPadded(通过内存填充,确保每个计数器独占一个缓存行)。我们将让多个 goroutine 并发地更新不同的计数器,并使用 perf 工具来观测其底层的硬件行为。
go
// false-sharing/demo/main.go
package main
const (
cacheLineSize = 64
// 为了更容易观察效果,我们将计数器数量增加到与常见核心数匹配
numCounters = 16
)
// --- 对照组 A (未填充): 计数器紧密排列,可能引发伪共享 ---
type CountersUnpadded struct {
counters [numCounters]uint64
}
// --- 对照组 B (已填充): 通过内存填充,确保每个计数器独占一个缓存行 ---
type PaddedCounter struct {
counter uint64
_ [cacheLineSize - 8]byte// 填充 (64-byte cache line, 8-byte uint64)
}
type CountersPadded struct {
counters [numCounters]PaddedCounter // 跨多个缓存行,每个缓存行一个计数器
}初步验证尝试与结果分析
我们的基准测试使用 b.RunParallel来执行并发的benchmark,这是 Go 中进行并行 benchmark 的标准方式。
go
// false-sharing/demo/main_test.go
package main
import (
"runtime"
"sync/atomic"
"testing"
)
func BenchmarkFalseSharing(b *testing.B) {
// 使用 GOMAXPROCS 来确定并行度,这比 NumCPU 更能反映实际调度情况
parallelism := runtime.GOMAXPROCS(0)
if parallelism < 2 {
b.Skip("Skipping, need at least 2 logical CPUs to run in parallel")
}
b.Run("Unpadded (False Sharing)", func(b *testing.B) {
var counters CountersUnpadded
// 使用一个原子计数器来为每个并行goroutine分配一个唯一的、稳定的ID
var workerIDCounter uint64
b.RunParallel(func(pb *testing.PB) {
// 每个goroutine在开始时获取一次ID,并在其整个生命周期中保持不变
id := atomic.AddUint64(&workerIDCounter, 1) - 1
counterIndex := int(id) % numCounters
for pb.Next() {
atomic.AddUint64(&counters.counters[counterIndex], 1)
}
})
})
b.Run("Padded (No False Sharing)", func(b *testing.B) {
var counters CountersPadded
var workerIDCounter uint64
b.RunParallel(func(pb *testing.PB) {
id := atomic.AddUint64(&workerIDCounter, 1) - 1
counterIndex := int(id) % numCounters
for pb.Next() {
atomic.AddUint64(&counters.counters[counterIndex].counter, 1)
}
})
})
}在我的一台macOS上的benchmark运行结果如下:
go
$go test -bench .
goos: darwin
goarch: amd64
pkg: demo
cpu: Intel(R) Core(TM) i5-8257U CPU @ 1.40GHz
BenchmarkFalseSharing/Unpadded_(False_Sharing)-8 75807434 15.20 ns/op
BenchmarkFalseSharing/Padded_(No_False_Sharing)-8 740319799 1.720 ns/op
PASS
ok demo 2.616s我们看到padding后的counter由于单独占据一个缓存行,避免了不同核心对同一缓存行的争用,就能带来超过10 倍的性能提升。
结合perf分析benchmark结果
接下来,我使用支持perf的一台linux vps(2core),结合perf和benchmark来全面地分析一下上述的benchmark结果。
go
$go test -bench .
goos: linux
goarch: amd64
pkg: demo
cpu: Intel(R) Xeon(R) CPU E5-2695 v2 @ 2.40GHz
BenchmarkFalseSharing/Unpadded_(False_Sharing)-2 58453443 20.49 ns/op
BenchmarkFalseSharing/Padded_(No_False_Sharing)-2 297915252 4.068 ns/op
PASS
ok demo 2.866s
$gotest -c -o benchmark.test
// 获取Padded counter的cache-misses
$perfstat -e cache-misses,cache-references ./benchmark.test -test.benchmem -test.bench "BenchmarkFalseSharing/Padded"
goos: linux
goarch: amd64
pkg: demo
cpu: Intel(R) Xeon(R) CPU E5-2695 v2 @ 2.40GHz
BenchmarkFalseSharing/Padded_(No_False_Sharing)-2 292481478 4.109 ns/op 0 B/op 0 allocs/op
PASS
Performance counter stats for'./benchmark.test -test.benchmem -test.bench BenchmarkFalseSharing/Padded':
279945 cache-misses # 20.848 % of all cache refs
1342771 cache-references
1.644051530 seconds time elapsed
3.188438000 seconds user
0.039960000 seconds sys
// 获取Unpadded counter的cache-misses
$perfstat -e cache-misses,cache-references ./benchmark.test -test.benchmem -test.bench "BenchmarkFalseSharing/Unpadded"
goos: linux
goarch: amd64
pkg: demo
cpu: Intel(R) Xeon(R) CPU E5-2695 v2 @ 2.40GHz
BenchmarkFalseSharing/Unpadded_(False_Sharing)-2 90129991 15.48 ns/op 0 B/op 0 allocs/op
PASS
Performance counter stats for'./benchmark.test -test.benchmem -test.bench BenchmarkFalseSharing/Unpadded':
224973 cache-misses # 0.750 % of all cache refs
29986826 cache-references
1.424455948 seconds time elapsed
2.806636000 seconds user
0.019904000 seconds sys
// 获取Unpadded counter的l1-cache-misses
$perfstat -e L1-dcache-loads,L1-dcache-load-misses ./benchmark.test -test.benchmem -test.bench "BenchmarkFalseSharing/Unpadded"
goos: linux
goarch: amd64
pkg: demo
cpu: Intel(R) Xeon(R) CPU E5-2695 v2 @ 2.40GHz
BenchmarkFalseSharing/Unpadded_(False_Sharing)-2 76737583 20.43 ns/op 0 B/op 0 allocs/op
PASS
Performance counter stats for'./benchmark.test -test.benchmem -test.bench BenchmarkFalseSharing/Unpadded':
229843537 L1-dcache-loads
35433482 L1-dcache-load-misses # 15.42% of all L1-dcache accesses
1.619401127 seconds time elapsed
3.156380000 seconds user
0.027971000 seconds sys
// 获取Padded counter的l1-cache-misses
$perfstat -e L1-dcache-loads,L1-dcache-load-misses ./benchmark.test -test.benchmem -test.bench "BenchmarkFalseSharing/Padded"
goos: linux
goarch: amd64
pkg: demo
cpu: Intel(R) Xeon(R) CPU E5-2695 v2 @ 2.40GHz
BenchmarkFalseSharing/Padded_(No_False_Sharing)-2 281670135 4.090 ns/op 0 B/op 0 allocs/op
PASS
Performance counter stats for'./benchmark.test -test.benchmem -test.bench BenchmarkFalseSharing/Padded':
1154274976 L1-dcache-loads
1136810 L1-dcache-load-misses # 0.10% of all L1-dcache accesses
1.617512776 seconds time elapsed
3.143121000 seconds user
0.040095000 seconds sys分析一:性能的最终裁决 (ns/op)
首先,我们来看基准测试的最终结果,这是衡量性能的"黄金标准"。
| Benchmark | 性能 (ns/op) |
|---|---|
Unpadded |
~20.5 ns/op |
Padded |
~4.1 ns/op |
Padded(无伪共享)版本的性能是 Unpadded(有伪共享)版本的约 5 倍。这无可辩驳地证明,内存填充在这种场景下带来了巨大的性能提升。
分析二:深入 L1 缓存------锁定"犯罪证据"
为了理解这 5 倍的性能差距从何而来,我们再看一下使用 perf 观察到的 L1 数据缓存 (L1-dcache) 的行为。
| Benchmark | L1-dcache-loads |
L1-dcache-load-misses |
L1 Miss Rate |
|---|---|---|---|
Unpadded |
~2.3 亿 | ~3543 万 | 15.42% |
Padded |
~11.5 亿 | ~113 万 | 0.10% |
这份数据揭示了两个惊人的、看似矛盾却直指真相的现象:
-
L1 未命中率是决定性指标 :
Unpadded版本的 **L1 缓存未命中率高达 15.42%**,而Padded版本则低至 **0.10%**。这正是伪共享的直接证据:在Unpadded场景下,当一个核心修改了共享的缓存行,其他核心的 L1 缓存中的该行就会失效。当其他核心尝试访问自己的变量时,就会导致一次昂贵的 L1 缺失,必须通过缓存一致性协议从其他核心或更慢的内存层级获取数据。 -
L1 加载次数是"吞吐量"的体现 :性能更好的
Padded版本,其L1-dcache-loads(L1 缓存加载次数)竟然是Unpadded版本的近 5 倍 !这并非性能问题,恰恰是高性能的"症状" 。Unpadded版本因为频繁的缓存同步,CPU 核心大部分时间都在**停顿 (Stalled)**,等待数据。而Padded版本由于极高的 L1 命中率,CPU 核心火力全开,以极高的吞吐量疯狂执行指令,因此在相同时间内执行了多得多的 L1 访问。
分析三:通用 cache-misses 指标的"误导性"
现在,让我们来看一组最容易让人得出错误结论的数据------顶层的 cache-misses 指标。这个指标在 perf中通常衡量的是**最后一级缓存 (Last Level Cache, LLC)**,也就是 L3 缓存的未命中次数。
| Benchmark | cache-misses (LLC Misses) |
cache-references |
Miss Rate |
|---|---|---|---|
Unpadded |
~22.5 万 | ~3000 万 | 0.75% |
Padded |
~28.0 万 | ~134 万 | 20.85% |
惊人的反常现象 :性能差了 5 倍的 Unpadded 版本,其 LLC 未命中率竟然只有 **0.75%**,堪称"完美"!而性能极佳的 Padded 版本,未命中率却高达 **20.85%**。这究竟是为什么?
要理解这个现象,我们必须深入到多核 CPU 的缓存一致性 (Cache Coherence) 协议(如 MESI 协议)的层面。
Unpadded 场景:一场 L1/L2 之间的"内部战争"
在 Unpadded(伪共享)场景下,多个物理核心正在争夺同一个缓存行的写入权。让我们简化一下这个过程:
-
核心 A 对
counters[0]进行原子加操作。它首先需要获得该缓存行的独占 (Exclusive) 所有权。它将该缓存行加载到自己的 L1/L2 缓存中,并将其状态标记为**已修改 (Modified)**。 -
与此同时,核心 B 试图对
counters[1](位于同一个缓存行)进行原子加操作。它发出请求,想要获得该缓存行的独占权。 -
总线监听到这个请求,发现核心 A 持有该缓存行的"脏"数据。
-
此时,并不会直接去访问最慢的主内存。相反,会发生以下情况之一(具体取决于协议细节和硬件):
-
核心 A 将其 L1/L2 中的"脏"缓存行数据写回 (write-back) 到共享的 L3 缓存中。
-
核心 A 直接通过高速的核间互联总线,将缓存行数据转发 (forward) 给核心 B。
-
核心 B 获得了最新的缓存行,执行操作,并将其标记为"已修改"。
-
紧接着,核心 A 又需要更新
counters[0],于是上述过程反向重复。 -
这个在不同核心的私有缓存(L1/L2)之间来回传递缓存行所有权的"乒乓效应",就是伪共享性能损耗的根源。
注:
cache-misses的真正含义:perf的cache-misses指标,通常统计的是 LLC 未命中 ,即连 L3 缓存都找不到数据,必须去访问主内存的情况。在伪共享场景下,这种情况非常罕见!因此,
Unpadded版本那 0.75% 的超低 LLC 未命中率,非但不是性能优异的证明,反而是一个危险的信号。它掩盖了在 L1/L2 层面发生的、数以千万计的、极其昂贵的核间同步开销。Padded场景:清晰的"内外分工"在
Padded(无伪共享)场景下,每个核心操作的都是自己独占的缓存行,互不干扰。-
初始加载 :在 benchmark 开始时,每个核心第一次访问自己的计数器时,会发生一次"强制性未命中"(Compulsory Miss)。数据会从主内存 -> L3 -> L2 -> L1,一路加载进来。这些初始加载,构成了
Padded版本中cache-misses和L1-dcache-load-misses的主要来源。 -
后续操作 :一旦数据进入了核心的私有缓存(特别是 L1),后续的所有原子加操作都将以极高的速度在 L1 缓存内部完成。这些操作既不会干扰其他核心,也几乎不再需要访问 L3 或主内存。
Padded版本那 20.85% 的 LLC 未命中率,反映了一个完全健康 的行为模式。它的分母 (cache-references) 很小,因为大部分操作都在 L1 内部消化了,没有产生需要统计的"引用"事件。这个比率,主要反映的是程序启动和数据初始化时的正常开销。综上,在分析伪共享这类并发性能问题时,顶层的
cache-misses(LLC misses)指标是一个极具误导性的"虚荣指标" 。我们必须深入到更底层的、核心私有的缓存指标(如L1-dcache-load-misses)中,才能找到问题的真正根源。数据导向设计 ------ AoS vs. SoA 的抉择
面向对象编程(OOP)教会我们围绕"对象"来组织数据,这通常会导致结构体数组 (Array of Structs, AoS) 的布局。然而,在高性能计算中,这种布局往往是缓存的噩梦,因为它违背了数据局部性 (Data Locality) 原则。
AoS vs. SoA 的核心差异
-
AoS (Array of Structs) : 当你顺序处理一个
[]EntityAoS切片时,你感兴趣的Position数据在内存中是不连续 的,它们被其他无关数据隔开。这导致 CPU 为了处理N个实体的位置,可能需要加载N个缓存行,其中很大一部分数据都是在当前循环中无用的"噪音",造成了严重的缓存和内存带宽浪费。 -
SoA (Struct of Arrays) : 数据导向设计(DOD)的核心思想是,根据数据的处理方式来组织数据 。通过将相同类型的字段聚合在一起,我们确保了在处理特定任务时,所有需要的数据在内存中都是紧密连续的。这使得 CPU 的硬件预取器能够完美工作,极大地提高了缓存命中率。
注:是不是觉得AoS更像"面向行的数据",而SoA更像是"面向列的数据"呢!
设计一个有意义的 Benchmark:隔离内存访问瓶颈
要通过 benchmark 来验证
AoS和SoA的性能差异,我们必须精心设计实验,确保内存访问是唯一的瓶颈。这意味着循环体内的计算量应该尽可能小。一个简单的求和操作是理想的选择。同时,我们必须确保工作集远大于 CPU 的最后一级缓存 (LLC),以强制 CPU 从主内存流式加载数据。
go// data-oriented-design/demo/main.go package main const ( // 将实体数量增加到 1M,确保工作集大于大多数 CPU 的 L3 缓存 numEntities = 1024 * 1024 ) // --- AoS (Array of Structs): 缓存不友好 --- type EntityAoS struct { // 假设这是一个更复杂的结构体 ID uint64 Health int Position [3]float64 // ... 更多字段 } func SumHealthAoS(entities []EntityAoS) int { var totalHealth int for i := range entities { // 每次循环,CPU 都必须加载整个庞大的 EntityAoS 结构体, // 即使我们只用到了 Health 这一个字段。 totalHealth += entities[i].Health } return totalHealth } // --- SoA (Struct of Arrays): 缓存的挚友 --- type WorldSoA struct { IDs []uint64 Healths []int Positions [][3]float64 // ... 更多字段的切片 } func NewWorldSoA(n int) *WorldSoA { return &WorldSoA{ IDs: make([]uint64, n), Healths: make([]int, n), Positions: make([][3]float64, n), } } func SumHealthSoA(world *WorldSoA) int { var totalHealth int // 这个循环只访问 Healths 切片,数据完美连续。 for i := range world.Healths { totalHealth += world.Healths[i] } return totalHealth }go// data-oriented-design/demo/main_test.go package main import"testing" func BenchmarkAoSvsSoA(b *testing.B) { b.Run("AoS (Sum Health) - Large", func(b *testing.B) { entities := make([]EntityAoS, numEntities) for i := range entities { entities[i].Health = i } b.ReportAllocs() b.ResetTimer() for i := 0; i < b.N; i++ { SumHealthAoS(entities) } }) b.Run("SoA (Sum Health) - Large", func(b *testing.B) { world := NewWorldSoA(numEntities) for i := range world.Healths { world.Healths[i] = i } b.ReportAllocs() b.ResetTimer() for i := 0; i < b.N; i++ { SumHealthSoA(world) } }) }下面是在我的机器上的benchmark运行结果 (在内存密集型负载下):
go$go test -bench . goos: darwin goarch: amd64 pkg: demo cpu: Intel(R) Core(TM) i5-8257U CPU @ 1.40GHz BenchmarkAoSvsSoA/AoS_(Sum_Health)_-_Large-8 2030 574302 ns/op 0 B/op 0 allocs/op BenchmarkAoSvsSoA/SoA_(Sum_Health)_-_Large-8 3964 288648 ns/op 0 B/op 0 allocs/op PASS ok demo 2.491s(注意:具体数值会因硬件而异)
我们看到:当 benchmark 真正触及内存访问瓶颈时,
SoA布局的性能优势尽显,比AoS快了超过 1 倍!这也揭示了在处理大数据集时,与硬件缓存协同工作的数据布局是通往高性能的必由之路。与硬件共舞 ------ 高级数据布局与访问模式
冷热数据分离
这是 SoA 思想的一种延伸。在一个大型结构体中,总有一些字段被频繁访问(热数据 ),而另一些则很少被触及(冷数据)。将它们混在一个结构体中,会导致在处理热数据时,不必要地将冷数据也加载到缓存中,造成**"缓存污染" (Cache Pollution)**,浪费宝贵的内存带宽。
通过将热数据打包在一个紧凑的结构体中,我们可以:
-
提高数据密度:一个 64 字节的缓存行,可以容纳更多的"有效"热数据。
-
提升内存带宽利用率:CPU 从主内存加载数据的带宽是有限的。确保加载到缓存的每一字节都是即将要用的数据,是性能优化的关键。
让我们通过一个模拟的用户数据结构,来直观地理解这个概念:
优化前:冷热数据混合的"胖"结构体
gotype UserMixed struct { // --- 热数据 (Hot Data) --- // 在列表页排序、过滤时被高频访问 ID uint64 Score int IsActive bool Timestamp int64 // --- 冷数据 (Cold Data) --- // 仅在用户详情页才会被访问 Name string Email string AvatarURL string Bio string Address string // ... 可能还有几十个不常用的字段 } // 当我们对 []UserMixed 按 Score 排序时, // 每次比较都会将包含 Name, Email, Bio 等冷数据的整个结构体加载到缓存中。优化后:冷热数据分离
go// "热"结构体:紧凑,只包含高频访问的字段 type UserHot struct { ID uint64 Score int IsActive bool Timestamp int64 // 用一个指针指向不常用的冷数据 ColdData *UserCold } // "冷"结构体:包含所有低频访问的字段 type UserCold struct { Name string Email string AvatarURL string Bio string Address string // ... } // 现在,对 []UserHot 按 Score 排序时, // 每次比较只加载一个非常小的 UserHot 结构体,缓存效率极高。 // 只有当用户真正点击进入详情页时,我们才通过 ColdData 指针去加载冷数据。这个简单的重构,正是"冷热数据分离"思想的精髓。
尽管"冷热数据分离"的原理无可辩驳,但在一个简单的基准测试 (benchmark) 中想可靠地、大幅度地展示其性能优势,却较为困难 。这是因为基准测试的环境相对"纯净",它常常无法模拟出这项优化真正能发挥作用的现实世界瓶颈。
其原因主要有二:
- 被其他瓶颈掩盖:
-
算法瓶颈 :如果我们用一个本身就缓存不友好的算法(如
sort.Slice)来测试,那么算法的非线性内存访问模式所带来的缓存未命中,将成为性能的主导瓶颈,完全淹没掉因数据结构变小而带来的收益。 -
内存延迟瓶颈 :如果我们用一个计算量极小的循环(如简单的求和)来测试,CPU 绝大部分时间都在**"停顿" (Stalled),等待下一个数据块从主内存的到来。在这种场景下,性能的瓶颈是内存访问的延迟** ,而不是内存带宽。无论是加载一个 100 字节的"大"数据块,还是一个 24 字节的"小"数据块,CPU 都得等。因此,性能差异不明显。
-
-
现代 CPU 的"智能化" :现代 CPU 拥有极其复杂的硬件预取器 (Prefetcher) 和乱序执行引擎 (Out-of-Order Execution)。对于一个简单的、可预测的线性扫描,预取器可能会非常成功地提前加载数据,从而隐藏了大部分内存延迟,进一步削弱了"胖"、"瘦"结构体之间的性能差异。
帮助 CPU 预测未来
现代 CPU 拥有强大的硬件预取器 (Hardware Prefetcher) 和 分支预测器 (Branch Predictor)。它们都依赖于一种核心能力:从过去的行为中预测未来。我们的代码能否高效运行,很大程度上取决于我们能否写出让 CPU"容易猜到"的代码。
模式一:可预测的内存访问 (Prefetching)
糟糕的模式 :随机内存访问 。它会彻底摧毁预取器的作用,导致每一次访问都可能是一次昂贵的缓存未命中。 优秀的模式 :线性、连续的内存访问。这是 CPU 预取器的最爱。
下面是一个是否支持预取的对比benchmark示例:
go
// prefetching/main.go
package main
// 线性访问,预取器可以完美工作
func SumLinear(data []int) int64 {
var sum int64
for i := 0; i < len(data); i++ {
sum += int64(data[i])
}
return sum
}
// 随机访问,预取器失效
func SumRandom(data []int, indices []int) int64 {
var sum int64
for _, idx := range indices {
sum += int64(data[idx])
}
return sum
}
go
// prefetching/main_test.go
package main
import (
"math/rand"
"testing"
)
func BenchmarkPrefetching(b *testing.B) {
size := 1024 * 1024
data := make([]int, size)
indices := make([]int, size)
for i := 0; i < size; i++ {
data[i] = i
indices[i] = i
}
rand.Shuffle(len(indices), func(i, j int) {
indices[i], indices[j] = indices[j], indices[i]
})
b.Run("Linear Access", func(b *testing.B) {
for i := 0; i < b.N; i++ {
SumLinear(data)
}
})
b.Run("Random Access", func(b *testing.B) {
for i := 0; i < b.N; i++ {
SumRandom(data, indices)
}
})
}运行结果:
go
$go test -bench .
goos: darwin
goarch: amd64
pkg: demo
cpu: Intel(R) Core(TM) i5-8257U CPU @ 1.40GHz
BenchmarkPrefetching/Linear_Access-8 4164 315895 ns/op
BenchmarkPrefetching/Random_Access-8 2236 522074 ns/op
PASS
ok demo 3.711s这个 benchmark 的结果是稳定且可靠的 ,因为它直接测量了内存访问模式的差异。近2倍的性能差距清晰地证明了线性访问的优势。
模式二:可预测的分支
现代 CPU 的流水线在遇到 if 等条件分支时,会进行"分支预测"。如果猜对了,流水线继续顺畅执行;如果猜错了,则需要清空流水线并重新填充,带来巨大的性能惩罚(几十个时钟周期)。
下面我们从理论上对比一下好坏两种模式的代码。
糟糕的模式(不可预测的分支):
go
// 如果 data 是完全随机的,if 分支的走向大约有 50% 的概率被预测错误
func CountUnpredictable(data []int) int {
var count int
for _, v := range data {
if v > 128 {
count++
}
}
return count
}优秀的模式:
-
先排序 :如果可以,在处理前先对数据进行排序。这样,
if分支会先连续地false一段时间,然后连续地true,分支预测器的准确率会更高。 -
**无分支代码 (Branchless Code)**:在某些情况下,可以用算术运算来替代条件判断。
go// 无分支版本,性能稳定 func CountBranchless(data []int) int { var count int for _, v := range data { // (v > 128) -> (v >> 7) & 1 for positive v < 256 count += (v >> 7) & 1 } return count }
尽管分支预测的原理无可辩驳,但在一个简单的基准测试中可靠地、大幅度地展示其性能优势,却较为困难 ,原因无非是现代 CPU 过于智能 ,以至于在一个"纯净"的基准测试环境中,它们有能力掩盖分支预测失败带来的惩罚,因此这里也不举例了。
SIMD 友好的数据布局 (SIMD-Friendly Layouts)
SIMD (Single Instruction, Multiple Data) 是一种硬件能力,允许 CPU 在一条指令中,同时对多个数据执行相同的操作。即将到来的 Go 1.26 计划引入一个实验性的simd包,这将为 Gopher 提供更直接、更强大的向量化计算能力。
要让 Go 编译器(或未来的 simd 包)能够有效地利用 SIMD 指令,SoA 布局 和内存对齐 是关键。SoA 布局确保了需要同时处理的数据(例如多个向量的 X 分量)在内存中是连续的。
go
// Enable SIMD processing with proper alignment
type Vec3 struct {
X, Y, Z float32
_ float32// Padding for 16-byte alignment
}
// Process 4 vectors at once with SIMD
func AddVectors(a, b []Vec3, result []Vec3) {
// Compiler can vectorize this loop (目前Go编译器可能暂不支持该优化)
for i := 0; i < len(a); i++ {
result[i].X = a[i].X + b[i].X
result[i].Y = a[i].Y + b[i].Y
result[i].Z = a[i].Z + b[i].Z
}
}
// 强制 64 字节对齐的技巧,可以确保数据块的起始地址与缓存行对齐
type AlignedBuffer struct {
_ [0]byte
data [1024]float64
}
// var buffer = new(AlignedBuffer) // buffer.data 将保证 64 字节对齐超越单核 ------ NUMA 架构下的性能考量
在多路 CPU 服务器上(若干个物理cpu socket,几百个逻辑核心),我们会遇到 NUMA (Non-Uniform Memory Access) 问题。简单来说,每个 CPU Socket 都有自己的"本地内存",访问本地内存的速度远快于访问另一个 Socket 的"远程内存"。
解决方案:NUMA 感知调度
由于Go runtime的goroutine调度器目前尚未支持NUMA结构下的调度,对于极端的性能场景,我们可以手动将特定的 goroutine "钉" 在一个 CPU 核心上,确保它和它的数据始终保持"亲和性"。
go
package main
import (
"fmt"
"runtime"
"golang.org/x/sys/unix"
)
// PinToCPU 将当前 goroutine 绑定到固定的 OS 线程,并将该线程钉在指定的 CPU 核心上
func PinToCPU(cpuID int) error {
runtime.LockOSThread()
var cpuSet unix.CPUSet
cpuSet.Zero()
cpuSet.Set(cpuID)
// SchedSetaffinity 的第一个参数 0 表示当前线程
err := unix.SchedSetaffinity(0, &cpuSet)
if err != nil {
runtime.UnlockOSThread()
return fmt.Errorf("failed to set CPU affinity: %w", err)
}
returnnil
}
func main() {
fmt.Println(PinToCPU(0))
}当然也可以使用一些服务器或OS发行版厂商提供的工具,在启动时为Go应用绑核(固定在一个CPU Socket上),以避免程序运行时的跨CPU Socket的数据访问。
小结 ------ 成为与硬件共鸣的 Gopher
我们从一个简单的前提开始:CPU 很快,内存很慢。但这场穿越伪共享、数据布局、分支预测等重重迷雾的探索之旅,最终将我们引向了一个更深刻的结论:编写高性能 Go 代码,其本质是一场与硬件进行"机械共鸣" (Mechanical Sympathy) 的艺术。
"机械共鸣"这个词,由工程师 Martin Thompson 提出,意指赛车手需要深刻理解赛车的工作原理,才能榨干其全部潜能。对于我们软件工程师而言,这意味着我们必须理解计算机的工作原理。
然而,现代 CPU 极其复杂,而试图用简单的模型去精确地"算计"它,往往是徒劳的。 超线程、复杂的缓存一致性协议、强大的硬件预取器、深不可测的乱序执行引擎......这些"黑魔法"使得底层性能在微观层面充满了不确定性。
这是否意味着性能优化已无章可循?恰恰相反。它为我们指明了真正的方向:
我们追求的不应是基于特定硬件的、脆弱的"微优化技巧",而应是那些能够在宏观层面、大概率上 与硬件工作模式相符的设计原则:
-
数据局部性 (Locality):让相关的数据在物理上靠得更近 (AoS -> SoA, 冷热分离)。
-
线性访问 (Linearity):让数据以可预测的顺序被访问 (数组优于链表)。
-
独立性 (Independence):让并发任务在物理上相互隔离 (避免伪共享)。
这些原则,之所以有效,并非因为它们能"战胜"硬件的复杂性,而是因为它们顺应了硬件的设计初衷。它们为 CPU 强大的优化引擎提供了最佳的"原材料",让硬件能够最大限度地发挥其威力。
最终,这场探索之旅的终极教训,或许在于培养一种全新的思维模式:像 CPU 一样思考。在设计数据结构时,不仅仅考虑其逻辑上的抽象,更要思考它在内存中的物理形态;在编写循环时,不仅仅考虑其算法复杂度,更要思考其内存访问模式。
Go 语言,以其对底层一定程度的暴露(如显式的内存布局)和强大的工具链(如 pprof),为我们实践"机械共鸣"提供了绝佳的舞台。掌握了这些原则,你将不仅能写出"能工作"的 Go 代码,更能写出与硬件和谐共鸣、释放极限潜能的、真正优雅的 Go 程序。
本文涉及的示例源码请在这里下载 - https://github.com/bigwhite/experiments/tree/master/cpu-cache-friendly
附录:Go 高性能优化速查手册
缓存友好型 Go 编程的七大黄金法则
-
打包热数据:将频繁访问的字段放在同一个结构体和缓存行中,以提高数据密度。
-
填充并发数据:用内存填充将不同 goroutine 独立更新的数据隔离开来,避免伪共享。
-
数组优于链表:线性、连续的内存访问远胜于随机跳转,能最大限度地发挥硬件预取器的作用。
-
使用更小的数据类型 :在范围允许的情况下,使用
int32而非int64,可以在一个缓存行中容纳更多数据。 -
处理前先排序:可以极大地提升分支预测的准确率和数据预取的效率(但在性能测试中要小心将排序本身的开销计算在内)。
-
池化分配 :通过重用内存(如
sync.Pool)可以避免 GC 开销,并有很大概率保持缓存的热度。 -
剖析,不要猜测 :始终使用
perf,pprof和精心设计的基准测试来指导你的优化。
高性能优化"食谱"
-
分析 (Profile):用
perf找到缓存未命中的重灾区,或用pprof定位 CPU 和内存热点。 -
重构 (Restructure):在热点路径上,将 AoS 布局重构为 SoA 布局。
-
填充 (Pad):消除伪共享。
-
打包 (Pack):分离冷热数据。
-
线性化 (Linearize):确保你的核心循环是线性的,避免随机内存访问。
-
测量 (Measure):用严谨的、能够隔离变量的基准测试,来验证每一项优化的真实效果。
测试策略
-
隔离变量:设计基准测试时,要确保你正在测量的,确实是你想要优化的那个单一变量,而不是被算法、GC、或其他运行时开销所掩盖。
-
关注吞吐量而非延迟:对于缓存优化,很多时候我们关心的是在单位时间内能处理多少数据(带宽),而不是单次操作的延迟。
-
使用真实数据规模:确保你的工作集远大于 CPU 的 L3 缓存,以模拟真实世界的内存压力。
-
跨硬件测试:在不同的 CPU 架构(Intel, AMD, ARM)和不同的硬件环境(笔记本 vs. 服务器)上进行测试,因为缓存行为是高度硬件相关的。
参考资料
-
CPU Cache-Friendly Data Structures in Go: 10x Speed with Same Algorithm - https://skoredin.pro/blog/golang/cpu-cache-friendly-go
-
Latency Numbers Every Programmer Should Know - https://colin-scott.github.io/personal_website/research/interactive_latency.html
-
Cache Lines - https://en.algorithmica.org/hpc/cpu-cache/cache-lines/
-
Mechanical Sympathy -https://www.infoq.com/presentations/mechanical-sympathy/
如果本文对你有所帮助,请帮忙点赞、推荐和转发 !
!
点击下面标题,阅读更多干货!
🔥 你的Go技能,是否也卡在了"熟练"到"精通"的瓶颈期?
-
想写出更地道、更健壮的Go代码,却总在细节上踩坑?
-
渴望提升软件设计能力,驾驭复杂Go项目却缺乏章法?
-
想打造生产级的Go服务,却在工程化实践中屡屡受挫?
继《Go语言第一课》后,我的 《Go语言进阶课》 终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》 就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从"Go熟练工"到"Go专家"的蜕变! 现在就加入,让你的Go技能再上一个新台阶!
