在网络编程中,IO 操作的效率直接决定了系统的性能上限。从简单的阻塞 IO 到复杂的多路复用,每一种技术都对应着特定场景下的解决方案。本文将从网络 IO 的基本流程出发,逐步解析阻塞 / 非阻塞、同步 / 异步的核心区别,再到 BIO、NIO、AIO 三种模型的特点,最后深入探讨 IO 多路复用技术的实现原理。
一、网络 IO 的基本交互过程
一次完整的网络 IO 交互,本质上是数据在用户态、内核态和网卡之间的流转过程。以输入操作为例,整个流程可分为两个核心阶段:
- 数据准备阶段:等待网络数据包到达网卡,随后被拷贝到内核空间的缓冲区。这个阶段的核心是 "等待数据就绪",数据从硬件(网卡)进入内核管理的内存区域。
- 数据拷贝阶段:当内核缓冲区中的数据准备完毕,再将数据从内核空间拷贝到应用进程的用户空间缓冲区,供程序读取处理。
这两个阶段是理解所有 IO 模型的基础 ------ 后续的阻塞 / 非阻塞、同步 / 异步等概念,本质上都是围绕这两个阶段的处理方式展开的。
二、阻塞 / 非阻塞与同步 / 异步的区别
在实际开发中,我们经常混淆 "阻塞 / 非阻塞" 和 "同步 / 异步" 的概念。其实它们描述的是 IO 操作中两个不同维度的特性:
1. 阻塞与非阻塞:描述用户线程调用内核的方式
- 阻塞 IO:当用户线程发起 IO 请求后,会一直等待直到整个 IO 操作(包括数据准备和拷贝)完成才返回。如果第一阶段数据未就绪,线程会进入阻塞状态,暂停执行并释放 CPU 资源,直到数据拷贝到用户空间后才被唤醒。
- 非阻塞 IO:用户线程发起 IO 请求后会立即返回一个状态值,无需等待操作完成。若第一阶段数据未就绪,线程不会阻塞,而是通过轮询不断检查数据是否就绪,直到数据准备好后再进行拷贝。
2. 同步与异步:描述用户线程与内核的交互方式
- 同步 IO:用户线程发起请求后,必须等待内核完成 IO 操作(包括两个阶段)才能继续执行。即使采用非阻塞轮询,轮询过程仍由用户线程主动完成,本质上还是 "同步等待"。
- 异步 IO:用户线程发起请求后,无需等待内核处理,可直接执行其他任务。当内核完成数据准备和拷贝后,会通过回调函数或事件通知的方式告知用户线程,整个过程用户线程无需主动干预。
三、常见 IO 模型解析
基于上述特性,常见的 IO 模型可分为三类:BIO、NIO、AIO,它们分别对应不同的应用场景。
1. BIO(同步阻塞 IO)
BIO 是最基础的 IO 模型,核心特点是 "同步 + 阻塞"。在服务端,每当一个客户端通过 Socket 连接时,服务端会创建一个新线程专门处理该连接的读写操作。
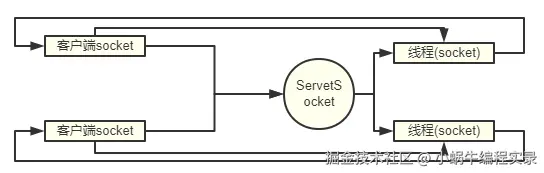
- 同步体现:客户端的请求必须等待服务端处理完成并返回响应后,才能进行下一步操作。
- 弊端:线程资源是有限的,当客户端数量激增时,服务端会因线程过多导致内存耗尽或调度开销过大,甚至崩溃。即使使用线程池限制线程数量,高并发场景下也会出现请求排队和延迟。
2. AIO(异步非阻塞 IO)
AIO 基于 Proactor 模型实现,属于 "异步 + 非阻塞" 模式。其核心是由操作系统完成 IO 的两个阶段后,再通知应用程序处理结果。
- 特点:用户线程无需关注数据准备和拷贝过程,只需在操作完成后处理结果即可。适用于连接数多且连接持续时间长的场景(如长连接服务)。
3. NIO(同步非阻塞 IO)
NIO 是 Java 在 JDK4 中引入的模型,基于 Reactor 模型,核心是 "同步 + 非阻塞 + 多路复用"。它通过三个核心组件实现高效 IO:
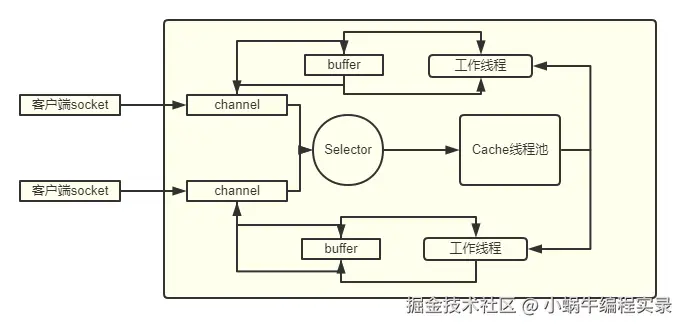
- Buffer:缓冲区,用于数据的临时存储,支持基本数据类型(如 IntBuffer、LongBuffer),数据读写均通过 Buffer 完成。
- Channel:通道,类似流但支持双向读写,可异步操作,且直接与 Buffer 交互(而非直接操作数据)。
- Selector:多路复用器,一个线程可管理多个 Channel。Selector 会轮询注册的 Channel,当某个 Channel 发生读写事件时,通过 SelectionKey 标记就绪状态,再由线程处理。
- 非阻塞核心:客户端连接时仅创建 Channel 并注册到 Selector,无需立即分配线程;只有当 Channel 有事件(如可读)时,才由工作线程处理,大幅减少线程开销。
- 同步体现:工作线程处理数据时(从 Buffer 读 / 写)仍为同步操作。
四、IO 多路复用技术详解
NIO 的高效依赖于 IO 多路复用技术 ------ 通过一个线程监控多个 IO 通道,实现 "多路连接复用一个线程" 的效果。其核心是解决传统阻塞 IO 中 "一个连接一个线程" 的资源浪费问题。
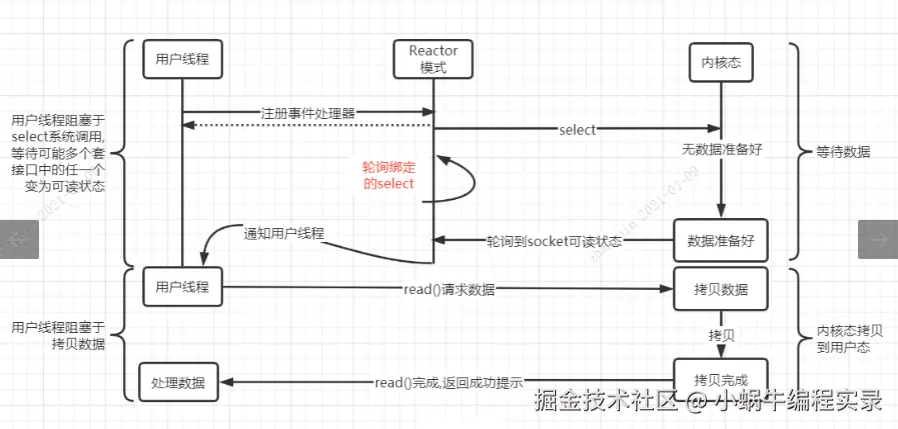
1. 多路复用的优势
传统阻塞 IO 中,若线程因 accept(接收连接)阻塞,即使有 read(读数据)事件发生,也必须等待 accept 完成才能处理。而多路复用模式下,不同事件的处理互不阻塞,一个线程即可响应多个事件。
2. 实现方式:select、poll 与 epoll
现代操作系统通过 select、poll、epoll 三种系统调用来实现多路复用,它们的核心差异体现在对文件描述符(fd)的管理方式上。
(1)select
- 原理:维护一个固定大小的 fd 数组(32 位系统最大 1024,64 位最大 2048),通过轮询检查数组中就绪的 fd。
- 函数原型 :
int select(int maxfdp1, fd_set *readset, fd_set *writeset, fd_set *exceptset, const struct timeval *timeout) - 弊端:fd 数量有限;轮询效率随 fd 增多而下降(O (n));每次调用需将 fd 数组从用户态拷贝到内核态,开销大。
(2)poll
- 改进:用链表替代数组,理论上突破了 fd 数量限制。
- 局限:仍需轮询(O (n))和频繁的数据拷贝,效率未本质提升。
(3)epoll:性能质的飞跃
epoll 是 Linux 对 select/poll 的改进,核心是事件驱动,通过回调机制避免轮询和冗余拷贝。
-
三个核心函数:
epoll_create:在内核创建红黑树,用于存储注册的 fd(支持动态扩容)。epoll_ctl:向红黑树添加 / 删除 fd,并为 fd 注册回调函数(当 fd 就绪时触发,将其加入就绪链表)。epoll_wait:从就绪链表中获取就绪的 fd,时间复杂度为 O (1)。
-
优点:
- 无 fd 数量限制(1G 内存可支持约 10 万连接)。
- 效率不随 fd 数量增加而下降(事件驱动而非轮询)。
- 减少用户态与内核态的数据拷贝(仅注册时拷贝一次)。
-
触发模式:
- 水平触发(LT,默认) :只要 fd 满足就绪条件(如缓冲区非空),就会持续通知,适合简单场景但可能频繁触发写事件。
- 边缘触发(ET) :仅当 fd 状态变化时通知(如缓冲区从空到有数据),效率更高,但需确保一次读完所有数据,否则可能遗漏事件。
总结
从 BIO 到 NIO 再到 AIO,IO 模型的演进始终围绕 "减少资源消耗、提高并发效率" 的目标。其中,IO 多路复用技术(尤其是 epoll)通过事件驱动和高效的 fd 管理,成为高并发网络编程的核心方案。理解这些模型的底层原理,能帮助我们在实际开发中选择合适的技术,优化系统性能。