有了InfluxDB环境,接下来就是往里面写数据了。InfluxDB使用一种叫Line Protocol的格式来接收数据,这个协议设计得很巧妙,既简洁又功能强大。
掌握Line Protocol是使用InfluxDB的基础技能,就像学SQL一样重要。
1 Line Protocol基础语法

图1-1:Line Protocol基础语法结构图,展示了measurement、tag set、field set和timestamp四个核心组成部分及其语法规则
1.1 基本格式
Line Protocol的格式看起来是这样的:
measurement,tag_key1=tag_value1,tag_key2=tag_value2 field_key1=field_value1,field_key2=field_value2 timestamp这一行包含了四个部分:
- 测量名(measurement):数据的类别
- 标签集(tag set):用逗号分隔的键值对
- 字段集(field set):用逗号分隔的键值对
- 时间戳(timestamp):可选,不写就用当前时间
1.2 实际例子
来看几个真实的例子:
# 温度传感器数据
temperature,room=living_room,sensor=DHT22 value=23.5,humidity=65.2 1640995200000000000
# 服务器监控数据
cpu_usage,host=server01,region=us-west cpu_percent=85.2,memory_percent=72.1 1640995260000000000
# 网站访问统计
page_views,page=/home,user_agent=chrome count=1,response_time=120 1640995320000000000看起来很直观对吧?每一行就是一条数据记录。
2 语法规则详解

图2-1:Line Protocol数据类型和格式规则图,详细展示了Tag和Field的数据类型、格式要求以及时间戳的不同精度格式
2.1 测量名规则
测量名就是你数据的分类,类似于数据库表名:
# 好的测量名
temperature
cpu_usage
network_traffic
user_login
# 避免的测量名
temperature data # 不要有空格
cpu-usage% # 避免特殊字符如果测量名包含空格或特殊字符,需要用反斜杠转义:
my\ measurement,tag1=value1 field1=1002.2 标签的使用
标签用来给数据分类,方便后续查询。记住几个要点:
标签值只能是字符串
# 正确
location=room1,sensor_type=temperature
# 错误 - 标签值不能是数字
room_number=1 # 应该写成 room_number="1"标签用于索引和筛选
# 这些适合做标签
host=server01 # 服务器名
region=us-west # 地区
environment=production # 环境
device_type=sensor # 设备类型标签顺序会影响性能
# 推荐:把基数小的标签放前面
environment=prod,region=us-west,host=server01
# 不推荐:把基数大的标签放前面
host=server01,region=us-west,environment=prod2.3 字段的使用
字段存储实际的数值数据:
支持多种数据类型
# 整数
count=100i
# 浮点数
temperature=23.5
cpu_percent=85.2
# 字符串(需要双引号)
status="online"
message="system started"
# 布尔值
is_active=true
is_error=false字段可以进行数学运算
# 多个字段
cpu_usage,host=server01 user=45.2,system=12.8,idle=42.02.4 时间戳格式
时间戳是可选的,支持多种格式:
# 纳秒时间戳(默认)
temperature,room=living_room value=23.5 1640995200000000000
# 不指定时间戳,使用当前时间
temperature,room=living_room value=23.5
# RFC3339格式
temperature,room=living_room value=23.5 2022-01-01T12:00:00Z3 数据写入方法

图3-1:InfluxDB数据写入方法对比图,展示了CLI、文件批量导入和HTTP API三种写入方式的特点、使用场景和性能对比
3.1 命令行写入
最简单的方式是用influx CLI:
bash
# 单条数据写入
influx write \
--bucket mybucket \
--org myorg \
--token $INFLUX_TOKEN \
'temperature,location=room1 value=23.5'
# 多条数据写入
influx write \
--bucket mybucket \
--org myorg \
--token $INFLUX_TOKEN \
'temperature,location=room1 value=23.5
temperature,location=room2 value=25.1
humidity,location=room1 value=65.2'3.2 文件批量导入
如果有大量数据,可以先写到文件里:
bash
# 创建数据文件 data.txt
cat > data.txt << EOF
temperature,location=room1,sensor=DHT22 value=23.5,humidity=65.2
temperature,location=room2,sensor=DHT22 value=25.1,humidity=62.8
cpu_usage,host=server01,region=us-west cpu_percent=85.2,memory_percent=72.1
cpu_usage,host=server02,region=us-west cpu_percent=78.9,memory_percent=68.5
EOF
# 批量导入
influx write \
--bucket mybucket \
--org myorg \
--token $INFLUX_TOKEN \
--file data.txt3.3 HTTP API写入
也可以直接用HTTP API:
bash
curl -XPOST "http://localhost:8086/api/v2/write?org=myorg&bucket=mybucket" \
-H "Authorization: Token $INFLUX_TOKEN" \
-H "Content-Type: text/plain; charset=utf-8" \
--data-binary 'temperature,location=room1 value=23.5'4 编程语言客户端

图4-1:InfluxDB编程语言客户端对比图,展示了Python、Java、Go、Node.js和C#客户端的特点、性能评级和适用场景
4.1 Python客户端
python
from influxdb_client import InfluxDBClient, Point
from influxdb_client.client.write_api import SYNCHRONOUS
# 连接配置
client = InfluxDBClient(
url="http://localhost:8086",
token="your-token",
org="myorg"
)
write_api = client.write_api(write_options=SYNCHRONOUS)
# 方式1:使用Point对象
point = Point("temperature") \
.tag("location", "room1") \
.tag("sensor", "DHT22") \
.field("value", 23.5) \
.field("humidity", 65.2)
write_api.write(bucket="mybucket", record=point)
# 方式2:使用Line Protocol字符串
line_protocol = "temperature,location=room1,sensor=DHT22 value=23.5,humidity=65.2"
write_api.write(bucket="mybucket", record=line_protocol)
# 方式3:批量写入
points = []
for i in range(100):
point = Point("temperature") \
.tag("location", f"room{i}") \
.field("value", 20 + i * 0.1)
points.append(point)
write_api.write(bucket="mybucket", record=points)4.2 Java客户端
java
import com.influxdb.client.InfluxDBClient;
import com.influxdb.client.InfluxDBClientFactory;
import com.influxdb.client.WriteApiBlocking;
import com.influxdb.client.domain.WritePrecision;
import com.influxdb.client.write.Point;
import java.time.Instant;
import java.util.ArrayList;
import java.util.List;
public class InfluxDBExample {
public static void main(String[] args) {
// 连接配置
String url = "http://localhost:8086";
String token = "your-token";
String org = "myorg";
String bucket = "mybucket";
InfluxDBClient client = InfluxDBClientFactory.create(url, token.toCharArray());
WriteApiBlocking writeApi = client.getWriteApiBlocking();
// 方式1:使用Point对象
Point point = Point.measurement("temperature")
.addTag("location", "room1")
.addTag("sensor", "DHT22")
.addField("value", 23.5)
.addField("humidity", 65.2)
.time(Instant.now(), WritePrecision.NS);
writeApi.writePoint(bucket, org, point);
// 方式2:使用Line Protocol字符串
String lineProtocol = "temperature,location=room1,sensor=DHT22 value=23.5,humidity=65.2";
writeApi.writeRecord(bucket, org, WritePrecision.NS, lineProtocol);
// 方式3:批量写入
List<Point> points = new ArrayList<>();
for (int i = 0; i < 100; i++) {
Point batchPoint = Point.measurement("temperature")
.addTag("location", "room" + i)
.addField("value", 20.0 + i * 0.1)
.time(Instant.now(), WritePrecision.NS);
points.add(batchPoint);
}
writeApi.writePoints(bucket, org, points);
// 方式4:使用POJO对象
TemperatureData data = new TemperatureData();
data.location = "room1";
data.sensor = "DHT22";
data.value = 23.5;
data.humidity = 65.2;
data.time = Instant.now();
writeApi.writeMeasurement(bucket, org, WritePrecision.NS, data);
client.close();
}
}
// POJO类定义
import com.influxdb.annotations.Column;
import com.influxdb.annotations.Measurement;
import java.time.Instant;
@Measurement(name = "temperature")
public class TemperatureData {
@Column(tag = true)
public String location;
@Column(tag = true)
public String sensor;
@Column
public Double value;
@Column
public Double humidity;
@Column(timestamp = true)
public Instant time;
}Maven依赖配置:
xml
<dependency>
<groupId>com.influxdb</groupId>
<artifactId>influxdb-client-java</artifactId>
<version>6.10.0</version>
</dependency>4.3 Go客户端
go
package main
import (
"context"
"fmt"
"time"
"github.com/influxdata/influxdb-client-go/v2"
)
func main() {
client := influxdb2.NewClient("http://localhost:8086", "your-token")
writeAPI := client.WriteAPIBlocking("myorg", "mybucket")
// 创建数据点
p := influxdb2.NewPoint("temperature",
map[string]string{
"location": "room1",
"sensor": "DHT22",
},
map[string]interface{}{
"value": 23.5,
"humidity": 65.2,
},
time.Now())
// 写入数据
err := writeAPI.WritePoint(context.Background(), p)
if err != nil {
fmt.Printf("Write error: %v\n", err)
}
client.Close()
}4.4 JavaScript客户端
javascript
const { InfluxDB, Point } = require('@influxdata/influxdb-client')
const client = new InfluxDB({
url: 'http://localhost:8086',
token: 'your-token'
})
const writeApi = client.getWriteApi('myorg', 'mybucket')
// 创建数据点
const point = new Point('temperature')
.tag('location', 'room1')
.tag('sensor', 'DHT22')
.floatField('value', 23.5)
.floatField('humidity', 65.2)
writeApi.writePoint(point)
// 批量写入
const points = []
for (let i = 0; i < 100; i++) {
const point = new Point('temperature')
.tag('location', `room${i}`)
.floatField('value', 20 + i * 0.1)
points.push(point)
}
writeApi.writePoints(points)
// 确保数据写入完成
writeApi.close().then(() => {
console.log('Data written successfully')
})5 批量写入优化
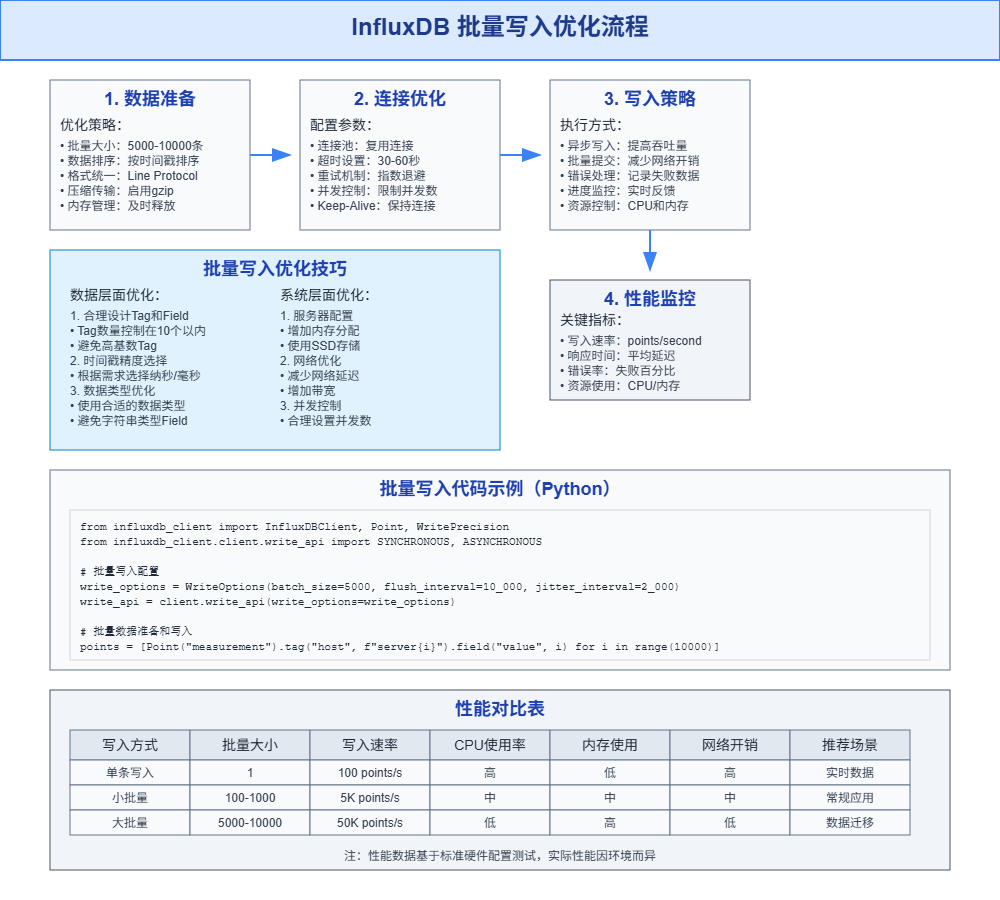
图5-1:InfluxDB批量写入优化流程图,展示了从数据准备到性能监控的完整优化策略和最佳实践
5.1 批量大小控制
不要一条一条地写入数据,批量写入效率更高:
python
# 不推荐:逐条写入
for data in sensor_data:
write_api.write(bucket="mybucket", record=data)
# 推荐:批量写入
batch_size = 1000
points = []
for data in sensor_data:
points.append(create_point(data))
if len(points) >= batch_size:
write_api.write(bucket="mybucket", record=points)
points = []
# 写入剩余数据
if points:
write_api.write(bucket="mybucket", record=points)5.2 异步写入
对于高频写入场景,使用异步写入:
python
from influxdb_client.client.write_api import WriteOptions
# 配置异步写入
write_options = WriteOptions(
batch_size=1000,
flush_interval=10_000, # 10秒
jitter_interval=2_000, # 2秒抖动
retry_interval=5_000, # 重试间隔
max_retries=3
)
write_api = client.write_api(write_options=write_options)5.3 压缩传输
对于大量数据,启用压缩能节省带宽:
python
client = InfluxDBClient(
url="http://localhost:8086",
token="your-token",
org="myorg",
enable_gzip=True # 启用压缩
)6 常见错误和解决方案

图6-1:InfluxDB Line Protocol常见错误诊断与解决方案图,提供了完整的错误分类、诊断流程和解决方法
6.1 语法错误
bash
# 错误:标签和字段之间缺少空格
temperature,room=living_roomvalue=23.5
# 正确:标签和字段之间要有空格
temperature,room=living_room value=23.5
# 错误:字段值包含空格但没有引号
status,host=server01 message=system started
# 正确:字符串字段值要用双引号
status,host=server01 message="system started"6.2 数据类型错误
bash
# 错误:标签值不能是数字
temperature,room_number=1 value=23.5
# 正确:标签值必须是字符串
temperature,room_number="1" value=23.5
# 错误:整数字段没有i后缀
count,type=request value=100
# 正确:整数字段要加i后缀
count,type=request value=100i6.3 时间戳问题
bash
# 错误:时间戳精度不对
temperature,room=living_room value=23.5 1640995200
# 正确:使用纳秒时间戳
temperature,room=living_room value=23.5 16409952000000000007 性能优化建议
7.1 标签设计原则
- 标签基数不要太高(避免超过100万个唯一组合)
- 把查询频繁的属性设为标签
- 把基数小的标签放在前面
7.2 字段设计原则
- 数值数据设为字段
- 需要聚合计算的数据设为字段
- 字段数量控制在合理范围内
7.3 写入频率控制
python
# 控制写入频率,避免过于频繁
import time
last_write_time = 0
min_interval = 1 # 最小间隔1秒
def write_data(data):
global last_write_time
current_time = time.time()
if current_time - last_write_time >= min_interval:
write_api.write(bucket="mybucket", record=data)
last_write_time = current_time掌握了Line Protocol,你就能灵活地向InfluxDB写入各种时间序列数据了。下一篇我们会学习如何查询这些数据,让数据真正发挥价值。