什么是Spark?
Spark 是一个分布式内存计算引擎,核心目标是解决大数据场景下的 "快速计算" 问题,比 Hadoop 的 MapReduce 快 10-100 倍,是当前大数据领域最主流的计算框架之一。
- 问题:现在的计算不都是拿到内存吗?为啥说Spark是内存反而快?
- 答:因为中间计算结果放在内存。
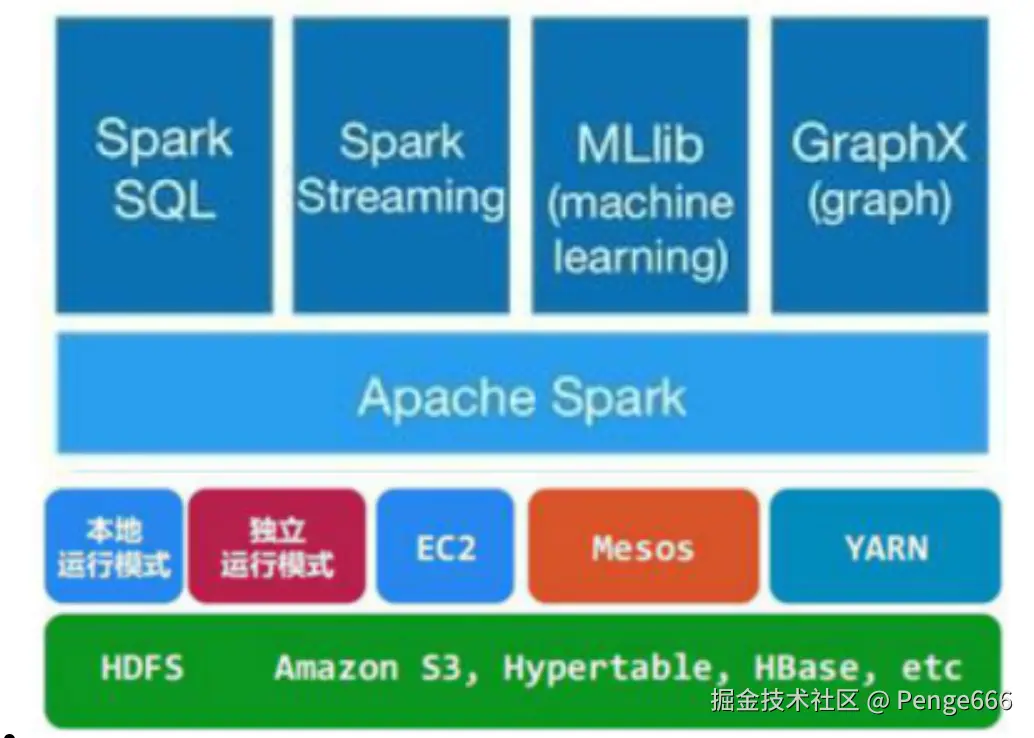
- Spark Core:核心引擎,提供分布式内存计算能力;
- Spark SQL:支持 SQL 查询(类似 Hive,但速度更快);
- Spark Streaming:处理实时流数据(准实时,秒级延迟);
- MLlib:机器学习库,内置常见算法(如分类、回归);
- GraphX:图计算库,处理社交网络等图结构数据。
Spark和Yarn队列的关系啥样?
Spark 与 YARN 队列:"申请资源 - 执行任务" 的关系
Spark 本身不管理硬件资源,当它需要运行任务时(如 Spark SQL 查询、批处理作业),会通过 YARN 进行资源调度:
- 步骤 1 :Spark 向 YARN 提交任务,并指定要使用的队列(如
--queue prod)。 - 步骤 2:YARN 检查该队列是否有空闲资源,若有则分配对应的 CPU 和内存(以 "容器(Container)" 为单位)。
- 步骤 3:Spark 在分配到的资源上启动 Executor(计算节点),并在 Executor 中执行具体的计算逻辑(如 Map/Reduce 操作、SQL 算子)。
- 步骤 4:任务结束后,Executor 释放资源,归还给 YARN 队列供其他任务使用。
具体流程如下:
- Spark SQL 转换为 Spark 任务
当你执行 Spark SQL 时,Spark 会先解析 SQL,生成逻辑执行计划,经过优化后转换为物理执行计划(如由 DataFrame/Dataset 算子组成的 DAG 图),最终拆解为一系列 Spark 任务(Task)。
- 提交任务到 YARN
Spark 通过 spark-submit 命令提交任务时,会指定 YARN 作为资源管理器(--master yarn),并可通过 --queue 参数指定 YARN 队列(如 --queue prod)。任务首先提交给 YARN 的 ResourceManager。
-
YARN 分配资源
- ResourceManager 从指定队列中分配初始资源(一个 Container),用于启动 Spark 的 ApplicationMaster(负责整个 Spark 作业的生命周期管理)。
- ApplicationMaster 根据任务所需的资源量(由
--executor-memory、--executor-cores等参数指定),向 ResourceManager 申请更多 Container,用于启动 Spark Executor(执行计算的工作节点)。 - YARN 从队列的资源配额中分配对应 CPU 和内存,确保资源使用不超过队列限制。
-
执行 Spark 任务
- Executor 启动后,会向 Spark 的 Driver 进程注册,接收并执行具体的 Task(如数据过滤、聚合、连接等)。
- 计算过程中,数据可从 HDFS、Hive 表、Kafka 等外部存储读取,中间结果优先保存在内存中(这是 Spark 速度快的核心原因)。
-
任务结束,释放资源所有 Task 执行完成后,ApplicationMaster 向 YARN 汇报,Executor 占用的 Container 释放资源,归还给 YARN 队列。
Spark SQL 会将 SQL 解析为一系列 Spark 任务(Task),通过 YARN 进行资源调度(分配 CPU、内存),最终在 YARN 管理的节点上执行这些任务。
基本概念
Spark运行模式
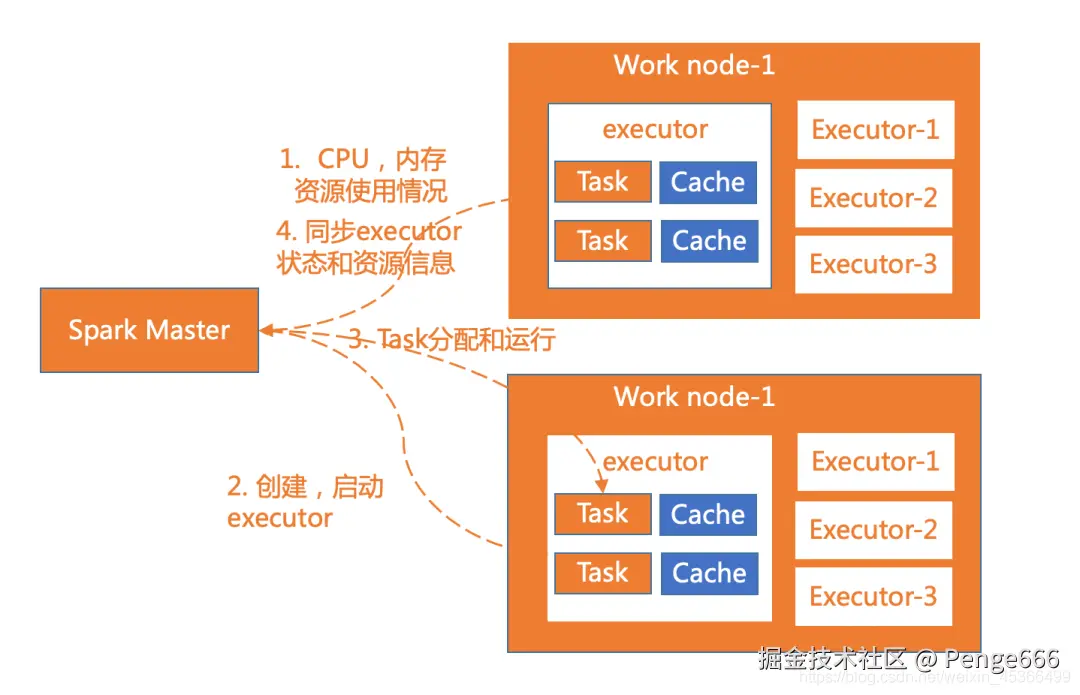
master和worker
(1)Cluster Manager
集群管理器,它存在于Master进程中,主要用来对应用程序申请的资源进行管理,根据其部署模式的不同,可以分为local,standalone,yarn,mesos等模式。
(2)worker
worker是spark的工作节点,用于执行任务的提交,主要工作职责有下面四点:
-
worker节点通过注册机向cluster manager汇报自身的cpu,内存等信息。
-
worker 节点在spark master作用下创建并启用executor,executor是真正的计算单元。
-
spark master将任务Task分配给worker节点上的executor并执行运用。
-
worker节点同步资源信息和executor状态信息给cluster manager。
driver和executor
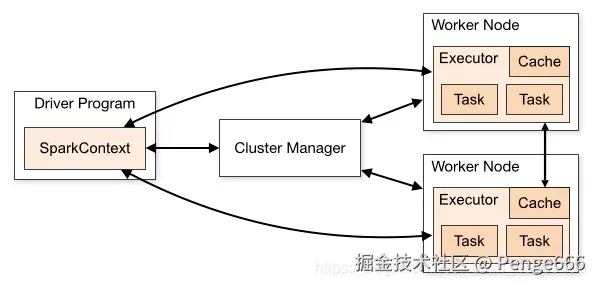
driver: 可运行在master/worker上;
作用:
- main函数,构建SparkContext对象;
- 向集群申请spark所需要资源,也就是executor,然后集群管理者会根据spark应用所设置的参数在各个worker上分配一定数量的executor,每个executor都占用一定数量的cpu和memory;
- 然后开始调度、执行应用代码
executor: 可运行在worker上(1:n)
作用:每个executor持有一个线程池,每个线程可以执行一个task,executor执行完task以后将结果返回给driver。
spark比mapreduce强在哪?
无论是 Spark 还是 MapReduce,向 YARN 申请 CPU 和内存都是为了在分布式集群上运行,这是 "分布式计算的基本操作",而非 Spark 的独特优势。YARN 就像 "资源中介",不管是 Spark 还是 MapReduce,都得通过它拿资源,区别在于:
- Spark 拿到资源后,用更高效的方式(内存、DAG)把活儿干完;
- MapReduce 拿到资源后,用相对低效的方式(磁盘、固定流程)干活。