现在我们已经构建了第一个可运行的 AI Agent,是时候赋予它真正的能力 了。本章将超越基础,深入探讨 OpenAI Agents SDK 中最重要的元素之一:工具(tools) 。工具让 Agent 能与外部世界互动:查询数据库、调用 API、执行计算、生成内容,甚至调用其他 Agent。
本章你将学到:
- 自定义工具 :如何用
@function_tool装饰器把 Python 函数注册为工具;配置工具元数据、用 Pydantic 校验输入,以及控制工具的描述方式。 - Agent-Tool 行为 :如何通过
tool_choice、tool_use_behavior等参数影响 Agent 何时、如何使用工具。 - OpenAI 托管工具 :使用 OpenAI 预构建的工具(如
WebSearchTool、FileSearchTool、CodeInterpreterTool)扩展 Agent 能力。 - 把 Agent 当作工具:将整个 Agent 封装为可调用的工具,支持模块化编排与分层工作流。
- MCP(模型上下文协议) :连接外部 MCP 服务器以获取现成工具,而非自己实现。
读完本章,你将能为 Agent 配齐强大能力:从四则运算 到实时 API 访问 ,从图像生成 到向量数据库查询 ,再到对接外部 MCP 服务器 ;并能精细控制 Agent 的用工具策略。开干吧。
技术要求
请按照第 3 章的详细步骤完成环境搭建。
全书各章的示例与完整代码见配套仓库:
github.com/PacktPublis...
建议克隆仓库、复用并按需改造示例代码。
使用 Python 函数编写自定义工具
本节我们用 Python 函数 在 OpenAI Agents SDK 中定义与配置自定义工具。提醒:工具是 Agent 能力的核心,帮助其突破"内部知识",完成数据抓取、请求处理或触发动作 等任务。我们先从 @function_tool 的简单定义 开始,再进阶到覆写工具参数 与用 Pydantic 做复杂输入校验。
定义一个新工具
正如上一章所述,@function_tool 能把任意 Python 函数变为 Agent 可调用的工具。以下示例回顾了创建简单工具并携带该工具调用 Agent 的方式:
python
# Required imports
import os
from dotenv import load_dotenv
from agents import Agent, Runner, function_tool
# Load environment variables from the .env file
load_dotenv()
# Access the API key
api_key = os.getenv("OPENAI_API_KEY")
# Create a tool
@function_tool
def get_order_status(orderID: int) -> str:
"""
Returns the order status given an order ID
Args:
orderID (int) - Order ID of the customer's order
Returns:
string - Status message of the customer's order
"""
if orderID in (100, 101):
return "Delivered"
elif orderID in (200, 201):
return "Delayed"
elif orderID in (300, 301):
return "Cancelled"
# Define an agent
agent = Agent(name="Customer service agent",
instructions="You are an AI Agent that helps respond to customer queries for a local paper company",
model="gpt-4o",
tools=[get_order_status])
# Run the Control Logic Framework
result = Runner.run_sync(agent, "What's the status of my order? My Order ID is 200")
# Print the result
print(result.final_output)给函数加上装饰器后,SDK 会从函数名 (get_order_status)、docstring (功能描述)与签名 (orderID: int)中推断工具名、用途与输入参数 。请务必提供清晰的人类可读名称与 docstring,因为 Agent 会据此判断是否调用工具。本例无需手写 JSON Schema,SDK 会根据函数签名自动生成。
如需更强控制力,也可以显式覆写默认特征:
python
# Create a tool
@function_tool(
name_override="Get Status of Current Order",
description_override="Returns the status of an order given the customer's Order ID",
docstring_style="Args: Order ID in Integer format"
)
def get_order_status(orderID: int) -> str:
"""
Returns the order status given an order ID
Args:
orderID (int) - Order ID of the customer's order
Returns:
string - Status message of the customer's order
"""
if orderID in (100, 101):
return "Delivered"
elif orderID in (200, 201):
return "Delayed"
elif orderID in (300, 301):
return "Cancelled"这样做有助于让工具的呈现与被 Agent 理解更准确:当函数名过于通用、需要本地化或强制格式、或多工具结构相近但语义细微差异必须区分时尤为有用。
注
@function_tool既支持同步函数,也支持async def的异步函数。若是异步函数,SDK 会正确处理,Agent 会自动await其结果。这对调用外部 API/数据库或异步工作流的工具很有帮助。
Agent 与工具的行为
是否调用工具、调用哪个工具 由 Agent 自主决定------实质由 LLM 在控制逻辑循环 中决策,循环由 Runner 管理。每一轮大致如下:
Runner将当前消息列表发送给 LLM;- LLM 返回最终答案 或工具调用(为简化,此处只讨论这两种);
- 若是工具调用,
Runner执行对应 Python 函数,把字符串输出追加到消息历史,再进入下一轮,直到产出最终答案。
默认情况下,模型自行决定是否与何时用工具。但在某些场景我们需要干预。SDK 通过若干设置提供控制能力。
工具选择(tool_choice)
ModelSettings.tool_choice 用于控制模型使用工具的策略:
auto:模型自行决定(默认)required:强制模型必须使用工具none:禁止使用任何工具
当你希望强约束 Agent 行为 时很有用。例如,若你要 Agent 必须 从后端/知识库取数,绝不 依赖模型内生知识,可将 tool_choice="required":
python
from agents import Agent, Runner, function_tool, ModelSettings
@function_tool
def get_order_status(orderID: int) -> str:
if orderID in (100, 101):
return "Delivered"
elif orderID in (200, 201):
return "Delayed"
elif orderID in (300, 301):
return "Cancelled"
agent = Agent(
name="Strict customer service agent",
instructions="You are a customer service agent that must always use the backend system to check order status. Do not guess.",
model="gpt-4o",
tools=[get_order_status],
model_settings=ModelSettings(tool_choice="required")
)
result = Runner.run_sync(agent, "Can you check the status of Order ID 101?")
print(result.final_output)这样模型必须 调用 get_order_status,确保答案基于可信后端,提升准确性与可追溯性。
注
若
tool_choice="required"但没有任何可用工具 能完成任务,模型会报错或拒答,从而保证输出始终基于受信逻辑 。这在合规/审计 场景(法律/金融)尤其重要。你也可以把tool_choice设为具体工具名 (如"get_weather")以强制仅调用该工具,便于单测或绕过模型的选择逻辑。
工具使用行为(tool_use_behavior)
Agent.tool_use_behavior 控制工具执行后如何处理其输出:
run_llm_again(默认) :将工具输出回传给 LLM,由其决定是否形成最终答案。适合需要模型解释工具结果并结合上下文回复的场景。stop_on_first_tool:第一次工具输出即视为最终响应,不再调用 LLM。StopAtTools.stop_at_tool_names([...]):针对指定工具名 的白名单,触发后立即终止 Agent 执行并原样返回工具输出。
这些选项可让 Agent 更确定性 或更灵活 。例如当工具输出本身就是答案(DB 查询、计算结果等),stop_on_first_tool 很合适;而 stop_at_tool_names 适合某些敏感操作 (如开票)------直接呈现工具原文以保证准确性/格式/法务措辞。
示例(对"开票"工具直接回传):
ini
from agents import Agent, Runner, function_tool, StopAtTools
@function_tool
def create_invoice(orderID: int) -> str:
return f"Invoice for Order {orderID}: $123.45 (Generated on 2025-07-05)"
agent = Agent(
name="Invoice generator agent",
instructions="Generate and return an invoice when requested.",
model="gpt-4o",
tools=[create_invoice],
stop=StopAtTools.stop_at_tool_names(["create_invoice"])
)
result = Runner.run_sync(agent, "Please create an invoice for Order 300")
print(result.final_output)在此例中,Agent 调用了 create_invoice 并直接返回原始字符串 ,不再让 LLM"润色",从而保留工具输出的原貌与权威性。
使用 Pydantic 处理复杂工具入参
在上一章中我们讨论了 SDK 对 Pydantic 的支持,以及其在数据校验 方面的优势。回顾一下:与其在函数入参里只用 str、int 等简单类型提示,你可以定义一个 Pydantic BaseModel 来表示层次化或更细致 的输入结构。当把该模型作为函数参数使用时,SDK 会把整个模型视作单个参数 ,并自动生成 对应的嵌套 JSON 模式(schema) 。这让 LLM 更容易理解并以正确的输入模式调用复杂入参的工具。
下面通过一个具体示例来验证这一点。延续我们的客服主题,假设要创建一个处理客户退款 的工具。问题在于:退款处理需要复杂输入 ------订单号、客户邮箱、原因等等。更进一步,工具还需要一次性处理多个退款 。在这种情况下,我们定义一个 BaseModel 类 RefundRequest:
python
from pydantic import BaseModel, List
class RefundRequest(BaseModel):
order_id: str
customer_email: str
reason: str
requests: List[RefundRequest]有了这个定义,就可以把 RefundRequest 作为自定义函数的输入参数:
python
@function_tool
def process_refund(request: RefundRequest) -> str:
"""Process a refund request and return confirmation."""
# Logic to interface with internal refund systems would go here
return (f"Refund request for order {request.order_id} has been submitted. "
f"A confirmation will be sent to {request.customer_email}.")当 Agent 决定使用 process_refund 时,它会从 schema 中得知 request 是一个由 RefundRequest 对象构成的列表(每个对象都有三个必填字段)。模型的结构会清晰暴露给 LLM。
在处理包含多个字段、可选参数或重复对象的真实工作流 时,使用 Pydantic 进行结构化工具入参非常强大。
同时,它还能带来一个非 LLM 的输入校验 红利:如果 LLM 产生幻觉,传入了错误格式的数据,SDK 会通过抛出错误来捕获问题 ;你可以据此处理异常,从而显著提升应用的健壮性 。这对非确定性的 Agent--LLM 交互尤其重要。
例如,若模型疏漏了必填字段,或给出了错误类型(也许因为幻觉或误解了工具 schema)。假设它提交了如下 JSON:
perl
{
"order_id": 12345,
"customer_email": "customer@example.com"
}该载荷缺少必填字段 reason,且把 order_id 错误地写成了整数而不是字符串。当 SDK 尝试用这些数据实例化 RefundRequest 模型时,会自动抛出 Pydantic 的 ValidationError。
自定义工具的示例
既然我们已经讲过如何定义新工具并配置其被 Agent 调用时的行为,接下来就动手实现几个完整示例。每个示例都是一个可运行的独立脚本(前提是你已正确完成环境搭建)。
1) 算术计算工具
第一个带自定义工具的 Agent 用来执行算术计算 ------这是 LLM 著名易出错 的领域。事实上,数学运算不应该由 LLM 直接完成 。因此我们构建一个会调用专用计算工具的 Agent。
在本例中,Agent 将计算房贷月供 。新建 mortgage_agent.py,写入:
python
# Required imports
from dotenv import load_dotenv
from agents import Agent, Runner, function_tool
# Load environment variables from the .env file
load_dotenv()
@function_tool
def calculate_mortgage(
principal_amount: float, annualized_rate: float, number_of_years: int
) -> str:
"""
This function calculates the mortgage payment.
Args:
principal_amount: The mortgage amount.
annual_rate: The annualized interest rate in percent form.
years: The loan term in years.
Returns:
A message stating the monthly payment amount.
"""
monthly_rate = (annualized_rate / 100) / 12
months = number_of_years * 12
payment = principal_amount * (monthly_rate) / (1 - (1 + monthly_rate) ** -months)
print(payment)
return f"${payment:,.2f}."
# Define an agent that uses the mortgage calculator tool
mortgage_agent = Agent(
name="MortgageAdvisor",
instructions=("You are a mortgage assistant"),
tools=[calculate_mortgage]
)
# Run the agent with an example question
result = Runner.run_sync(mortgage_agent, "What is my monthly payments if I borrow $800,000 at 6% interest for 30 years?")
print(result.final_output)在这个脚本里,calculate_mortgage 被装饰为自定义工具。它接受三个输入并返回格式化的月供金额字符串。运行时,Agent 会识别到问题与"计算月供"有关,并以合适参数调用工具;工具计算结果(约 $4,796.84/月)传回给 LLM,随后 LLM 生成最终回答。
由于 LLM 非确定性 ,你的表述可能略有差异,但金额应一致(由工具计算)。
现在,调整代码以强制 Agent 总是调用工具,并直接返回工具输出 而不再回到 LLM。我们添加两个参数:tool_use_behavior="stop_on_first_tool" 与 ModelSettings.tool_choice="required"。更新后的 Agent 实例化如下:
ini
# Add import
from agents import Agent, Runner, function_tool
# Define an agent that uses the mortgage calculator tool
mortgage_agent = Agent(
name="MortgageAdvisor",
instructions=("You are a mortgage assistant"),
tools=[calculate_mortgage],
tool_use_behavior="stop_on_first_tool",
model_settings=ModelSettings(
tool_choice="required"
)
)这样会绕过 LLM 的进一步推理或改写:Agent 将直接返回工具结果 。这对于要求确定性、可审计 的场景(如房贷申请)特别重要,同时还能减少循环中的 LLM 调用,提高性能。
该示例清楚展示了工具的优势:计算精确、不依赖模型的"记忆",避免其在算术上"翻车"。
2) 外部 API 调用工具
下一个自定义工具会调用外部 API 。API 是连接其他程序与资源的接口:比如 Gmail API 可读/发邮件、查看日程邀请;Airbnb API 可查询房源、创建房源、发消息。API 也常用于获取实时数据(客户记录、天气、加密货币价格等)。
下面创建一个获取 比特币美元价 的工具。新建 crypto_pricing_agent.py:
python
import requests
from agents import Agent, Runner, function_tool
# Create the tool
@function_tool
def get_price_of_bitcoin() -> str:
"""Get the price of Bitcoin."""
url = "https://api.coingecko.com/api/v3/simple/price?ids=bitcoin&vs_currencies=usd"
response = requests.get(url)
price = response.json()["bitcoin"]["usd"]
return f"${price:,.2f} USD."
# Create the agent
crypto_agent = Agent(
name="CryptoTracker",
instructions="You are a crypto assistant. Use tools to get real-time data.",
tools=[get_price_of_bitcoin]
)
# Run the agent with an example prompt
result = Runner.run_sync(crypto_agent, "What's the price of Bitcoin?")
print(result.final_output)这里定义了 get_price_of_bitcoin,通过 requests 调用 CoinGecko(免费的加密行情 API)。Agent 调用工具 → 工具请求 API → 返回价格给 Agent。
运行后可获得最新价格,与 LLM 的训练时效性无关。例如书写时的输出为:
The current price of Bitcoin is $108,538.00 USD.
这说明通过工具,Agent 能扩展 到模型训练数据之外的实时世界。
接下来扩展:让工具能返回任意币种 的价格,并支持一次查询多个 币。记住:工具可以用 Pydantic 模型作为输入。定义如下模型:
python
from pydantic import BaseModel
from typing import List
class Crypto(BaseModel):
"""
coin_ids: full name string to represent the cryptocurrency
"""
coin_ids: List[str]更新工具以接受该模型并一次查询多个币:
ini
# Create the tool
@function_tool
def get_crypto_prices(crypto: Crypto) -> str:
"""Get the current prices of a list of cryptocurrencies.
Args:
Crypto: an object with list of coin_ids (e.g., bitcoinm ethereum, litecoin, etc.)
"""
ids = ",".join(crypto.coin_ids)
url = f"https://api.coingecko.com/api/v3/simple/price?ids={ids}&vs_currencies=usd"
response = requests.get(url)
data = response.json()
return data
# Create the agent
crypto_agent = Agent(
name="CryptoTracker",
instructions="You are a crypto assistant. Use tools to get real-time data. When getting cryptocurrency prices, call the tool only once for all requests.",
tools=[get_crypto_prices]
)在这种结构下,LLM 看到的是清晰的 schema :一个对象,包含必填字段 coin_ids,且其值必须是字符串列表。SDK 会自动验证传入数据是否匹配该结构。比如我们问 "What's the price of Bitcoin and Ethereum?",它会返回类似:
"The current price of Bitcoin is 108,575,andthepriceofEthereumis2,534.56"
因为它成功把币种列表传给了 Python 函数。
注
我们在 Agent 指令中额外加了一句:"当获取加密货币价格时,把多个请求批量 一次性调用工具。" 这是在提示工程 上引导 LLM 把多币种价格合并为一次调用,避免重复 API 请求。
你也可以在 Traces 面板中验证(图 4.1)。
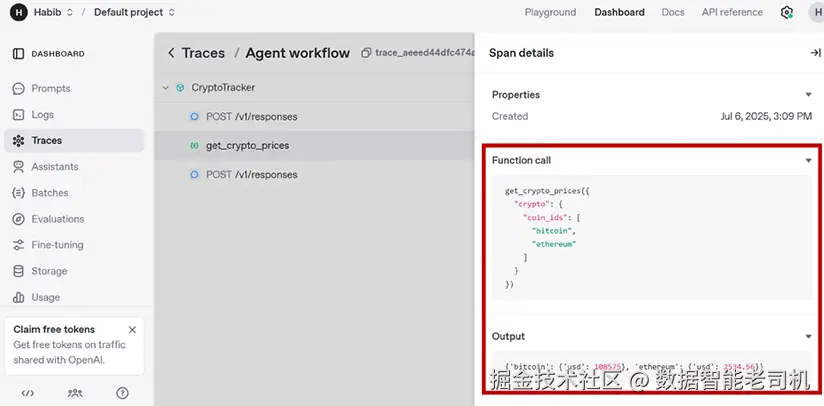
3) 数据库查询工具
前面的示例展示了精确计算 与实时 API 。另一个常见而强大的用法,是让 Agent 查询结构化的内部数据源 (如数据库),而不是硬编码查询或让模型直接写原生 SQL。我们可以把逻辑封装在连接数据库的工具里(机制类似 API 调用)。
这里构建一个查询客服工单 的 Agent。为避免真实数据库连接,我们用 Python 字典模拟数据库 ,真实环境下结构相同。新建 database_query.py:
python
from agents import Agent, Runner, function_tool
from pydantic import BaseModel
from typing import List
# create a simulated database
TICKETS_DB = {
"henry@gmail.com": [
{"id": "TCKT-001", "issue": "Login not working",
"status": "resolved"},
{"id": "TCKT-002", "issue": "Password reset failed",
"status": "open"},
],
"tom@gmail.com": [
{"id": "TCKT-003", "issue": "Billing error",
"status": "in progress"},
]
}
# define Pydantic model
class CustomerQuery(BaseModel):
email: str
# define the tool that does a database query
@function_tool
def get_customer_tickets(query: CustomerQuery) -> str:
"""Retrieve recent support tickets for a customer based on email."""
tickets = TICKETS_DB.get(query.email.lower())
if not tickets:
return f"No tickets found for {query.email}."
response = "\n".join(
[f"ID: {t['id']}, Issue: {t['issue']}, Status: {t['status']}"
for t in tickets]
)
return f"Tickets for {query.email}:\n{response}"
# create the agent
support_agent = Agent(
name="SupportHelper",
instructions="You are a customer support agent. Use tools to fetch user support history when asked about their tickets.",
tools=[get_customer_tickets]
)
# Run the agent
result = Runner.run_sync(support_agent, "Can you show me the ticket history for henry@gmail.com?")
print(result.final_output)在该示例中,我们定义了 CustomerQuery Pydantic 模型以约束输入结构 。get_customer_tickets 使用该输入去模拟数据库查找并返回结果。
收到诸如 "Can you show me the ticket history for henry@gmail.com?" 的请求时,Agent 会提取邮箱 、调用工具,并返回格式化的工单摘要,例如:
markdown
Here is the ticket history for henry@gmail.com:
1. **ID:** TCKT-001
- **Issue:** Login not working
- **Status:** Resolved
2. **ID:** TCKT-002
- **Issue:** Password reset failed
- **Status:** Open这种模式适用于大量企业场景:客户数据查询、库存数据库查询等。
工具调用链
Agent 背后的 LLM 不仅能决定是否 、何时 使用工具,还能在需要时决定调用工具的先后顺序 。当 Agent 需要执行多步操作 、并将前一个工具的输出 作为下一个工具的输入 时,这一点尤其有用。必要时,Agent 也可以多次调用同一个工具。
继续我们的客服主题:假设有一个工具 get_customer_orders(检索某个客户 ID 的所有订单),以及另一个工具 get_order_information(根据订单 ID 检索该订单的状态)。创建一个新的脚本 tool_chaining.py,代码如下:
python
# Required imports
from typing import List
from pydantic import BaseModel
from agents import Agent, Runner, function_tool
# Define the first tool to get all orders for a given customer
@function_tool
def get_customer_orders(customer_id: str) -> str:
"""
Retrieve all order IDs associated with a given customer ID.
Args:
customer_id: the customer ID
"""
# Dummy implementation
if customer_id == "CUST123":
return ["ORD001", "ORD002", "ORD003"]
# Define the second tool to get status of a specific order
@function_tool
def get_order_information(order_id: str) -> str:
"""
Fetch detailed information about a specific order.
"""
# Dummy implementation
status_map = {
"ORD001": "Shipped",
"ORD002": "Processing",
"ORD003": "Delivered"
}
return f"Order {order_id} is currently {status_map.get(order_id, 'Unknown')}."
# Define the agent
customer_service_agent = Agent(
name="CustomerSupportAgent",
instructions="You are a customer service assistant.",
tools=[get_customer_orders, get_order_information]
)
# Run the agent
result = Runner.run_sync(customer_service_agent, "Please check the status of my orders? My customer ID is CUST123.")
print(result.final_output)在此示例中,Agent 能够串联多次工具调用 。当被询问某位客户的所有订单状态时,它会先用提供的客户 ID 调用 get_customer_orders,获得一个订单 ID 列表;随后依次 对这些 ID 调用 get_order_information。这种多步推理 完全由 LLM 的控制逻辑框架 驱动,并会根据中间工具的输出动态 决定调用链的顺序。我们甚至可以在 Traces 模块中验证这串操作:
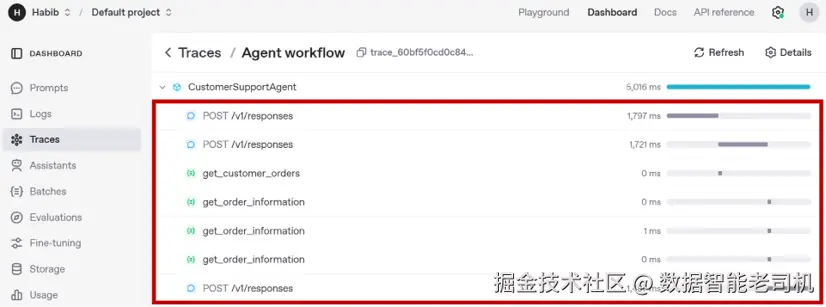
图 4.2:Traces 模块中的追踪列表
这展示了 Agent 在跨工具的多步推理 与调用链编排 方面的能力。你无需 手写工作流的硬编码流程;SDK 会为你完成编排。
OpenAI 托管工具
使用由 OpenAI 构建的 SDK 的一大好处,是它自带一组功能强大且预构建 的托管工具(hosted tools)。这些工具几乎零配置 即可使用;它们完全由 OpenAI 服务器托管与管理 (就像 LLM 也是托管在 OpenAI 服务器上一样)。这些工具还会持续更新,这意味着调用它们时可以直接受益于最新的技术进展。
注意
OpenAI 托管工具与模型调用一样会计入 token 成本。当模型调用这些工具时,工具调用本身以及模型与工具之间传递的数据,都会按 token 计费。
托管工具属于 OpenAI Responses API 框架的一部分。当你通过 Agents SDK 指定托管工具后,模型就知道这些工具的存在 ,并可像调用自定义 Python 函数一样以函数形式调用它们。可用的托管工具如下表所示:
| 托管工具 | 功能 |
|---|---|
| WebSearchTool | 执行实时网页搜索以获取最新信息 |
| FileSearchTool | 通过向量库执行文件信息检索与召回 |
| ImageGenerationTool | 生成图像 |
| CodeInterpreterTool | 在沙箱化的 Python 环境中运行代码 |
| ComputerTool | 打开计算机/浏览器实例并执行任务 |
| LocalShellTool | 在本地机器上执行 shell 命令 |
表 4.1:OpenAI 托管工具及其用途
注意
托管工具需要使用 OpenAI 的模型 (如 GPT-4 及之后的型号)。这些模型内置对工具的认知 并能调用它们。遗憾的是,你不能 用自有模型来配合这些 OpenAI 托管工具。
通常,对于已经被 OpenAI 托管工具覆盖的使用场景 ,没有必要 重复造轮子写自定义工具。例如,WebSearchTool 在网页搜索/查询方面表现优异,就不必再写一个 Python 函数来做同样的事。使用这些工具的方式非常简单:导入类 → 实例化 →(可选)设置输入参数 → 交给 Agent。
下面我们逐个介绍 OpenAI 托管工具的使用场景与参数,并创建示例 Agent。
WebSearchTool
WebSearchTool 让 Agent 具备网页搜索 能力。它是实现最容易 的工具之一。事实上,大多数企业级 Agent 都会包含它,以便在用户询问训练数据之外 的信息时也能作答。它特别适合处理最新动态、时效性强 的事实,或任何需要实时数据的查询。
该工具有两个可选输入:
user_location:按指定位置返回搜索结果。其格式为UserLocation(一个包含type、country、city、region键的字典)。当答案会因地域不同而变化(如"哪家珍珠奶茶最好喝?")时非常有用。search_context_size:指定每个网站 检索的信息量(以及检索的网站数量 )。可设为"low"、"medium"或"high",默认是"medium"。
创建一个执行简单网页搜索的 Agent(web_search_tool.py):
ini
from agents import Agent, Runner, WebSearchTool
# Instantiate the tool
websearchtool = WebSearchTool()
# Create an agent
agent = Agent(
name="WebTool",
instructions="You are an AI agent that answers web questions. Answer in one sentence.",
tools=[websearchtool]
)
result = Runner.run_sync(agent, "Who won the 2025 Stanley Cup?")
print(result.final_output)运行示例输出:
The Florida Panthers won the 2025 Stanley Cup, defeating the Edmonton Oilers in six games to secure their second consecutive championship. (reuters.com)
在这个例子中,Agent 能访问可搜索互联网 的工具。工具被调用后,OpenAI 会对该查询执行网页搜索、读取结果(可能是新闻或 Wikipedia 页面),并返回包含相关信息的文本片段 ;Agent 再据此组织对用户的回答。
如果去掉 WebSearchTool,该 Agent 将无法回答这类问题,因为模型的训练数据 并不包含 2025 年的实时信息: "I'm unable to provide real-time information or details about events occurring in 2025."
接着我们给 WebSearchTool 增加位置参数 。假设用户在加拿大多伦多 ,询问"前三名意大利餐厅":
ini
from agents import Agent, Runner, WebSearchTool
# Instantiate the tool
websearchtool = WebSearchTool(user_location={
"type": "approximate",
"country": "CA",
"city": "Toronto",
"region": "Ontario",
})
# Create an agent
agent = Agent(
name="WebTool",
instructions="You are an AI agent that answers web questions. Answer in one sentence.",
tools=[websearchtool]
)
result = Runner.run_sync(agent, "What are the top 3 Italian restaurants?")
print(result.final_output)示例输出:
yaml
Based on recent accolades and reviews, the top three Italian restaurants in Toronto are:
1. Don Alfonso 1890: Located on the 38th floor of The Westin Harbour Castle, this restaurant has retained its Michelin star since 2022 and was named the Best Italian Restaurant in the World (outside of Italy) by 50 Top Italy in 2022. (en.wikipedia.org)
2. Osteria Giulia: Situated in Yorkville, Osteria Giulia has held a Michelin star since 2022 and was ranked number 17 in Canada's 100 Best Restaurants list in 2024. (en.wikipedia.org)
3. DaNico: Also Michelin-starred, DaNico was ranked 59th in Canada's 100 Best Restaurants list in 2025. (en.wikipedia.org)这样,不到 15 行代码就做出了一个联网搜索 Agent。几乎没有其他 SDK 能以如此低成本实现同等能力。
FileSearchTool
FileSearchTool 让 Agent 能够针对向量库中的文档 执行检索,这实质上是 OpenAI 的托管式 RAG(检索增强生成)方案。本章仅演示其用法;关于 RAG 与 Agent 知识管理,我们会在后续章节深入讲解。
它最常见的用法是:针对内部知识库 或大规模文本语料 进行问答。借助该工具,你可以快速 搭建一个能从指定文档集中回答问题的 Agent,甚至能引用 用于得出答案的具体文档/片段。
要使用该工具,需要先在 OpenAI 平台上传文件并创建向量库(vector store) 。向量库是一种存储语义向量 的特殊数据库;向量是文本的数值化表示,能捕捉语义而非字面词形。这样 LLM 就能基于语义相关性 检索最相关文本,而不是依赖关键词精确匹配 。上传后,OpenAI 会在后台自动完成向量化 等工作,从而通过 RAG 实现快速、准确的检索------此过程发生在 SDK 之外,通常通过平台 UI 或常规 OpenAI API 完成。
创建向量库的步骤:
- 前往 platform.openai.com/ 登录(与生成 API Key 的账号一致)。
- 右上角选 Dashboard → 左侧选 Storage → 切换到 Vector stores。
- 点击 Create 新建一个向量库,命名如
DroneFiles。 - 下拉点击 + Add files 添加文件。
- 上传仓库(第 4 章)中的 XdroneManual.pdf ,命名为 DroneManual.pdf ,
Purpose选择user_data,然后点 Attach。
此时 PDF 已成功加入你的新向量库,与 RAG 相关的操作(如生成向量等)也已完成。复制并保存向量库 ID。
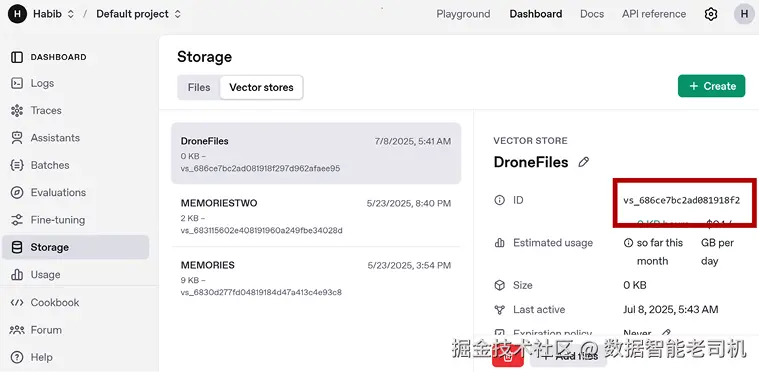
拿到向量库 ID 后,我们就能把它作为 FileSearchTool 的输入。该工具的关键参数包括:
vector_store_ids(必填) :调用工具时要检索的向量库 ID 列表。注意:你在 Agents SDK 中使用的 OpenAI API Key 必须属于对该向量库有访问权限的同一账号,否则会权限报错。max_num_results:返回的搜索结果数量上限。include_search_results:是否在工具输出中包含检索到的完整文本。
示例(file_search_tool.py):
ini
from agents import Agent, Runner, FileSearchTool
# Instantiate the tool
filesearchtool = FileSearchTool(
vector_store_ids=['vs_686ce7bc2ad081918f297d962afaee95'] # 替换为你的向量库 ID
)
# Create an agent
agent = Agent(
name="WebTool",
instructions="You are an AI agent that answers questions from the listed vector stores. Answer in one sentence.",
tools=[filesearchtool]
)
result = Runner.run_sync(agent, "How high can you fly this drone?")
print(result.final_output)运行后,Agent 将从我们上传的手册中获取答案,示例输出:
css
The drone can be flown up to a maximum altitude of 60 feet (20 meters).
由此可见,FileSearchTool 能让 Agent 的回答扎根于你提供的资料,而不是仅依赖模型的既有训练知识。
ImageGenerationTool
ImageGenerationTool 让 Agent 能够基于文本提示 生成图像,通常对接 OpenAI 的图像生成服务 。接入该工具后,Agent 可以响应诸如"生成一张大象的图片"之类的请求。常见用途包括生成视觉素材(产品稿、Demo、设计等)。
输入方面,ImageGenerationTool 通过 tool_config 接收一个 ImageGeneration 对象,你可以在其中指定尺寸、质量、格式、压缩 以及背景 等;同时必须指定 type,其取值为 "image_generation"。
示例(image_generation_tool.py):
ini
from agents import Agent, Runner, ImageGenerationTool
from agents.tool import ImageGeneration
# Instantiate the tool
tool_config = ImageGeneration(
type="image_generation",
)
imagetool = ImageGenerationTool(tool_config=tool_config)
# Create an agent
agent = Agent(
name="ImageTool",
instructions="You are an AI agent that generates images.",
tools=[imagetool]
)
result = Runner.run_sync(agent, "Generate an image of an elephant.")
print(result.final_output)运行脚本会返回一个图像 URL(由 OpenAI 服务器生成并托管):

图 4.5:示例代码生成的输出
注意
若遇到
PermissionDeniedError,请按 OpenAI 平台设置中的指引验证你的组织。
该工具会在 OpenAI 服务器上根据提示生成图像并返回其 URL。之后你可以将图片下载、保存或转发 到指定位置。它特别适合创意/视觉 类任务:例如 Agent 可根据描述动态生成数据可视化 (把描述转成图表图像),或用于插图。
注意
图像生成比文本更容易出现幻觉 :生成的图片可能与提示不够准确 ,甚至逻辑不一致。
CodeInterpreterTool
CodeInterpreterTool 允许 Agent 在沙箱环境 中编写并执行 Python 代码 。该工具对任何数据分析或计算 任务都极其有用。我们之前讨论过:数学计算应交由工具 完成(而非 LLM,自然语言模型易产生"幻觉");在前文中,我们通过自定义 Python 函数来计算房贷月供。而 CodeInterpreterTool 更进一步:无需你事先写出房贷月供公式,工具可以根据简单提示自行推导并执行代码。
此工具在沙箱容器 中执行代码。因此在使用前,需要先初始化一个容器对象 。容器可由工具自动创建 (运行时自建),也可显式创建 (你通过 OpenAI 端点创建容器并传入容器 ID)。为简化起见,这里选择自动方式。
下面直接看示例。创建 code_interpreter_tool.py 并运行以下代码:
ini
from agents import Agent, Runner, CodeInterpreterTool
from agents.tool import CodeInterpreter
# Instantiate the tool
tool_config = CodeInterpreter(
container={"type":"auto"},
type="code_interpreter"
)
codetool = CodeInterpreterTool(tool_config=tool_config)
# Create an agent
agent = Agent(
name="CodeTool",
instructions="You are an AI agent that writes and runs Python code to answer questions.",
tools=[codetool]
)
result = Runner.run_sync(agent, "What is my monthly payment for a $800,000 mortgage at 6% for 30 years?")
print(result.final_output)运行后得到输出:
The monthly payment for an 800,000mortgageat64,796.40.
为了得出答案,Agent 调用了 CodeInterpreterTool ,自动编写计算月供的 Python 代码并执行:在容器环境中运行代码 → 计算出结果 → 将结果反馈给 LLM 形成最终回答。
实际上,我们可以在 Traces 模块中验证这一点:

图 4.6:Traces 模块中的 Code Interpreter 输出
注意
容器中可执行的代码存在内在限制 ,例如配额 、可安装的Python 库 等。完整列表见:
platform.openai.com/docs/guides...
CodeInterpreterTool 使 Agent 能处理计算、数据处理 ,甚至生成图表 等输出;这些任务对于"纯 LLM"可能吃力或缓慢 。它就像给 Agent 配了一个聪明的初级数据分析员。
凭借这些预置托管工具 ,你可以用寥寥数行代码构建强大的 Agent:上网搜索、检索文件、生成图像、运行代码 ......也完全可以给同一个 Agent 同时添加多个工具。
在本节中,我们介绍了 Agents SDK 提供的 OpenAI 托管工具套件:WebSearchTool、FileSearchTool、ImageGenerationTool、CodeInterpreterTool 。这些工具显著扩展了 Agent 的能力:获取实时信息、从文档中检索知识、生成图像、执行高级计算------且配置极简 。理解如何集成与配置这些托管工具,是构建强大且可投产 Agent 的关键。下一节我们将把焦点转向 agent-as-tools (Agent 作为工具)的模式,学习如何把 Agent 定义成工具。
Agents as tools(Agent 作为工具,模式中译)
Agents SDK 中最强大的架构模式之一,是让一个完整的 Agent 作为另一个 Agent 的工具 来使用,即 agent-as-tool 模式。该模式能让 Agents 以分层 的方式协作:通常会有一个**编排者(orchestrator)负责整体流程控制,再由若干工作者(workers)**承担具体子任务。
工作者 Agent 是模块化组件:各自拥有系统提示 、推理流程 ,甚至自带工具 。对编排者而言,它们与普通工具 无异:不论是自定义 Python 工具 、OpenAI 托管工具 ,还是Agent 本体,在编排者眼中都是"可调用的工具"。
Handoff 与 Agent-as-Tool 的区别
agent-as-tool 与我们将在后文详细阐述的 handoff(交接) 截然不同:
- Handoff 模式 :一个 Agent 将控制权完全移交 给另一个 Agent(见图 4.7)。交接后,第二个 Agent 全面接管该任务/对话,直到完成或决定把控制权交还。

- Agent-as-tool 模式 :编排者 始终保留对整体工作流的控制权 ,仅在需要时调用另一个 Agent 处理某个子任务(见图 4.8)。

一个生活中的类比:拨打客服。客服经理可能把你转接 到另一个部门继续沟通(这就是 handoff );也可能让你稍等 ,自己去向同事打听/收集信息后再回来继续与你沟通(这就是 agent-as-tool)。
两种模式在 SDK 中都被完整支持,也可以混合使用 以实现更复杂的工作流。关键权衡点在于控制权 :handoff 倾向于模块化自治 ,而 agent-as-tool 倾向集中式协调。
适合 handoff 的场景:
- 问题明确落入另一个 Agent 的领域
- 该"工作者"需要完全拥有这段用户交互
- 无需对中间步骤进行严密监管
适合 agent-as-tool 的场景:
- 需要保持对逻辑与对话的集中控制
- 需要把多个工作者 的输入综合成一个答案
- 需要最大化可见性/可监督性
选择取决于你的工作流在控制、模块化、可见性方面的诉求。
功能
SDK 通过 as_tool() 将任意 Agent 转换为一个工具 ,返回 FunctionTool 对象,可加入另一个 Agent 的 tools 参数中。调用 as_tool() 时,需要指定名称 与描述 (与自定义函数工具时类似)。这些信息帮助编排者 判断是否 与何时 调用该工具,因此名称与描述应具体且信息量足够。
示例(agents_as_tool.py):
ini
from agents import Agent, Runner, WebSearchTool, CodeInterpreterTool
from agents.tool import CodeInterpreter
# Instantiate the tool
websearchtool = WebSearchTool()
# Create a worker agent
location_agent = Agent(
name="LocationAgent",
instructions="You are an AI agent that searches the web and gets latitude and longitude numbers for a particular city.",
tools=[websearchtool]
)
# Instantiate the tool
tool_config = CodeInterpreter(
container={"type":"auto"},
type="code_interpreter"
)
codetool = CodeInterpreterTool(tool_config=tool_config)
# Create another worker agent
distance_calculator_agent = Agent(
name="DistanceCalculatorAgent",
instructions="You are an AI agent that writes and runs Python code to calculate the distance in KM between two latitude/longitude points.",
tools=[codetool]
)
# Create the orchestrator agent
agent = Agent(
name="Agent",
instructions="You are an AI agent that calculates the distance between two locations. Use the Location Agent to get the latitude / longitude. Use the Distance Calculator agent to calculate the distance.",
tools=[
location_agent.as_tool(
tool_name="LocationAgent",
tool_description="Returns the latitude and longitude for a particular location"
),
distance_calculator_agent.as_tool(
tool_name="DistanceCalculatorAgent",
tool_description="Calculates the distance between two latitude/longitude points"
)
]
)
result = Runner.run_sync(agent, "What's the straight-line distance between Toronto and Vancouver?")
print(result.final_output)逐步解析:
-
创建两个工作者 Agent:
- LocationAgent :使用
WebSearchTool获取指定城市的经纬度; - DistanceCalculatorAgent :配备
CodeInterpreterTool,编写并运行 Python 代码 以计算两点间直线距离(KM) 。
- LocationAgent :使用
-
调用它们的
.as_tool():将每个 Agent 包装成可调用工具 ,并指定tool_name与tool_description。名称+描述 对 LLM 的工具选择 至关重要,应清晰且准确。 -
创建编排者 Agent,在指令中指导它:先用 LocationAgent 获取两地坐标,再用 DistanceCalculatorAgent 计算距离。
-
运行后,系统在幕后自动串联 调用:
LocationAgent被调用两次(多伦多 & 温哥华)→DistanceCalculatorAgent处理坐标 → 产出最终结果。
最终输出示例:
The straight-line distance between Toronto and Vancouver is approximately 3363.64 kilometers.
从 Traces 也能看到:先后调用两次"位置"代理(作为工具),再调用"距离计算"代理(作为工具)(见图 4.9)。

小结 :agent-as-tool 模式让你构建可组合、分层 的系统:专业化 Agent 各司其职,由中央编排者统筹。它鼓励模块化 与复用 ,并在复杂工作流中提供更好的可监督性。
到这里,我们已经学会如何用 agent-as-tool 组合 Agents。接下来,我们将聚焦更广泛的互操作性 问题:让 Agents 与工具在不同框架之间 通过共享标准 进行通信------这正是 MCP(Model Context Protocol,模型上下文协议) 要解决的。
MCP
Agentic AI 的开发仍然新兴,但热度正快速上升。随着开发者构建越来越多的 Agent 与工具 ,大家发现并没有一个统一标准 把工具接到 Agent 上------每个 SDK 的做法都不一样。我们已熟悉 Agents SDK 如何连接工具与 Agent,但它与 LangGraph 、CrewAI 等框架差异很大 。这带来两个问题:如果你在某个 SDK 中做了一个很棒的工具,难以迁移 到其它框架;而且如果别人已经为某个框架实现了"做 X 的工具",再为另一个框架重写一遍并不划算。
因此,需要一个跨 SDK 通用 的标准协议来定义"工具---Agent"的连接方式,MCP 应运而生。
什么是 MCP?
MCP(Model Context Protocol) 是一个标准化协议 ,规定了 AI Agent 如何发现并调用 本地或外部服务器上托管的工具。可以把 MCP 想成 Agent 与工具之间的万用适配器/USB-C 接口 。遵循该标准,工具提供方只需实现一个 MCP Server ,它就能插到任何兼容 MCP 的宿主 (例如用 Agents SDK 构建的 Agent)上,与不同的模型与框架互通。
MCP 的核心优势在于促进即插即用的工具生态 。开发者只需为自家数据库实现一次 MCP Server,就能立刻兼容 OpenAI、Anthropic 等所有支持 MCP 的宿主,无需额外集成工作。
注意
MCP 本身内容很广,完全可以写成一本书。本章仅演示如何用 Agents SDK 连接 MCP 服务器,并不深入覆盖协议细节,超出本书范围。
将 MCP 服务器作为工具接入
Agents SDK 让你非常容易地消费 MCP Server 提供的工具:只需建立到服务器的连接 ,并把它作为工具 传给 Agent。SDK 会自动完成连接、查询服务器可用工具,并把这些工具提供给 Agent 使用。
安全提示
使用外部 MCP 服务器时需考虑安全与隐私 :应启用认证 以限制访问主体,配置速率限制 以防误用/过载;此外要注意数据暴露风险(例如发送敏感输入或接收未经滤除的输出),务必有相应防护。
示例(mcp_tool.py):
ini
from agents import Agent, Runner, HostedMCPTool
from agents.tool import Mcp
# Create the tool
tool_config = Mcp(
server_label="CryptocurrencyPriceFetcher",
server_url="https://mcp.api.coingecko.com/sse",
type="mcp",
require_approval="never"
)
mcp_tool = HostedMCPTool(tool_config=tool_config)
# Create the agent
agent = Agent(
name="Crypto Agent",
instructions="You are an AI agent that returns crypto prices.",
tools=[mcp_tool]
)
result = Runner.run_sync(agent, "What's the price of bitcoin?")
print(result.final_output)这里并没有自己写一个请求 API 的工具来返回比特币价格,而是直接复用 CoinGecko 搭建的 MCP 服务器,其中已包含所需工具。无需自定义函数,直接使用他们提供的即可。
分解一下:Mcp 配置里包含工具的标签 、服务器的 URL 、工具类型("mcp"),以及 require_approval(是否在调用前要求人工批准 )。本例设为 "never",表示 Agent 可自主调用 。server_url 指向 CoinGecko 的 MCP 端点 (可在其官网找到),必须是能实时提供工具定义的有效 MCP 兼容地址。
在定义 Agent 时,我们把 MCP 工具加入 tools 列表。由于 MCP 服务器通常包含多个工具 (比如一个查比特币、一个查以太坊等),Agent 会在可用选项间推理选择合适的工具用于当前任务。
运行时,Agent 将用户消息发送给 LLM,LLM 决定调用 MCP 服务器上的某个工具;SDK 负责用正确的参数调用工具并把结果回传给 LLM,随后生成最终回答。
说明
实际的工具逻辑不在本地执行 。请求发往 MCP 服务器,由其远程托管并运行工具------这与直连外部 API 的方式类似。
简言之,借助 MCP 与 Agents SDK 的集成,Agent 可以无缝接入标准化的外部工具与服务生态,能力大幅提升。
总结(本章回顾)
本章我们让 Agent 具备了**真正"动手做事"**的能力:把它们接入各种工具(自定义、托管、Agent 作为工具、外部 MCP 服务器 )。我们先从 @function_tool 的自定义 Python 工具开始,讲了如何注册与描述工具,使 Agent 能理解并调用;又演示了如何通过 tool_choice 与 tool_use_behavior 影响用工具的决策逻辑。
随后,我们用四种范式构建了多个真实世界的工具与 Agent:
- 自定义工具(Python 函数)
- 托管工具(OpenAI 提供的模块)
- Agent 作为工具(agent-as-tool)
- 外部服务器工具(MCP)
有了这些模式,你就能构建既能理解与推理 、又能采取行动、连接实时系统、无缝整合外部服务的 Agent。
下一章,我们将继续探讨如何管理 Agent 的知识与记忆。