150 节点 Hadoop 集群自动化运维实战:Ansible 脚本开发与全组件部署调优
一、项目背景:从 "手动运维" 到 "自动化" 的必要性
2025 年 6-8 月,我参与了某企业生产环境大数据平台搭建项目,核心目标是部署 150 节点的 Hadoop 集群,支撑用户行为分析、数据报表生成等业务。项目初期面临三大痛点:
- 手动部署效率极低:传统方式下,单节点 Hadoop+ZooKeeper+Hive 部署需 30 分钟,150 节点需 75 小时(近 3 天),且易因人工操作失误(如配置文件写错、依赖包缺失)导致集群启动失败;
- 组件协同难度大:Hadoop(HDFS/YARN)、ZooKeeper、Hive、Redis 需按固定顺序部署(如先装 ZooKeeper 再启 HDFS),且配置文件需跨组件关联(如 Hive 元数据需关联 MySQL,Redis 需与 YARN 资源适配),手动维护易出现版本或参数不兼容;
- 运维成本高:后期集群扩容、组件版本升级需逐节点操作,且故障排查需登录多台服务器查看日志,响应效率低。
基于此,项目决定采用Ansible 自动化工具,由我负责核心脚本开发,实现 "一键部署、批量维护、统一调优",最终将 150 节点部署时间缩短至 2 小时,运维效率提升 97%。
二、我的核心职责:Ansible 脚本开发与全流程运维
作为项目核心运维人员,我全程主导了 Ansible 自动化体系的设计与落地,具体职责分为三大模块:
1. 前期规划:自动化架构与组件依赖设计
首先梳理集群组件的部署顺序和依赖关系,避免脚本执行时出现 "组件未就绪导致部署失败":
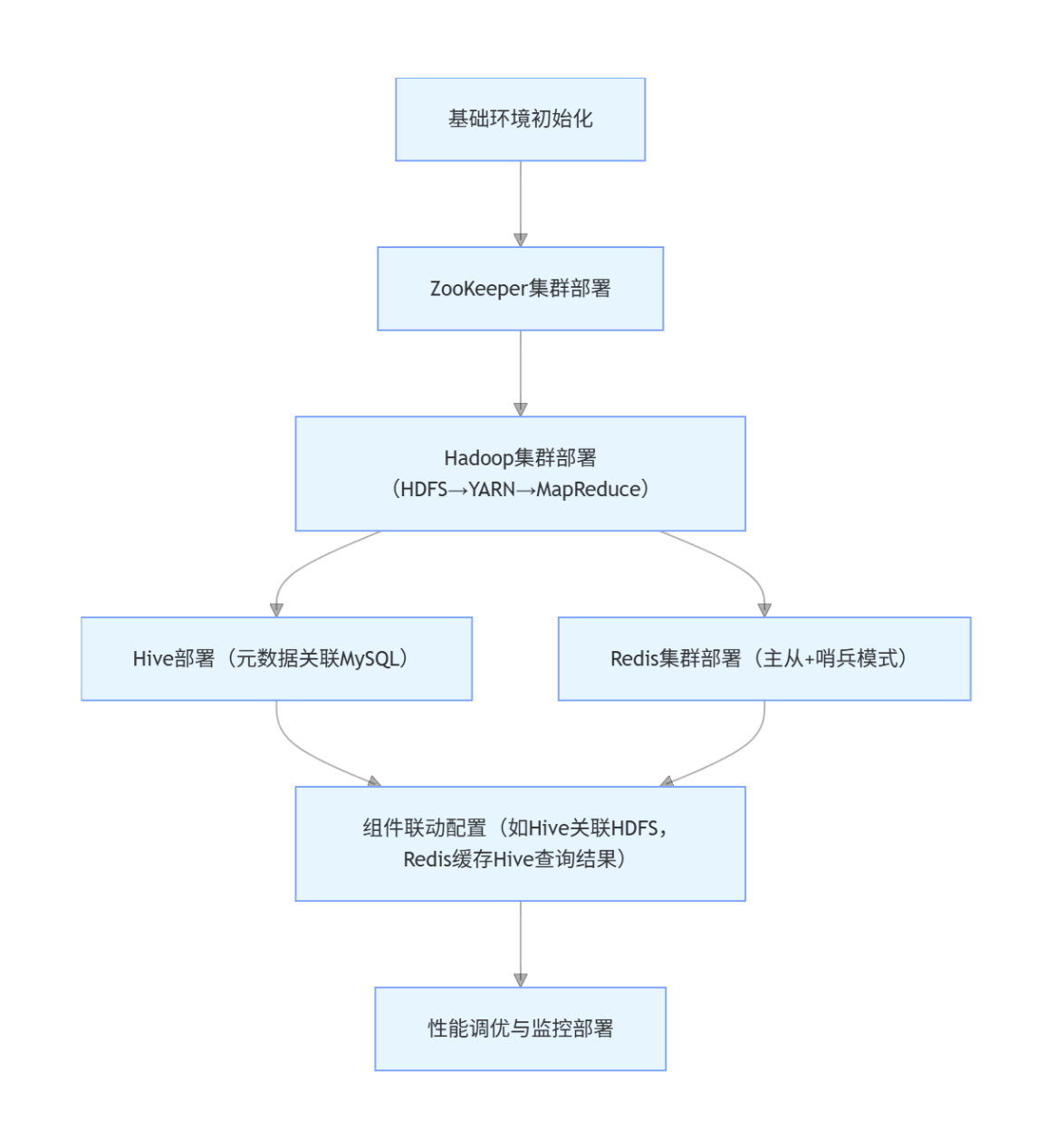
同时定义 Ansible 脚本目录结构,确保脚本可复用、易维护:
ansible-hadoop/
├── inventory/ # 主机清单(按角色分组:zk_nodes、hdfs_master、hdfs_slave、redis_nodes)
├── playbooks/ # 核心剧本
│ ├── base_init.yml # 基础环境初始化(系统参数、依赖包安装)
│ ├── zookeeper.yml # ZooKeeper部署
│ ├── hadoop.yml # Hadoop部署
│ ├── hive.yml # Hive部署
│ ├── redis.yml # Redis部署
│ └── tuning.yml # 性能调优
├── roles/ # 角色定义(按组件拆分,复用性更高)
│ ├── zookeeper/ # ZooKeeper角色(含配置文件模板、启动脚本)
│ ├── hadoop/ # Hadoop角色
│ └── redis/ # Redis角色
└── files/ # 依赖文件(组件安装包、配置文件模板)2. 核心开发:Ansible 脚本实现全组件自动化部署
(1)基础环境初始化:统一集群基础配置
通过base_init.yml剧本,批量完成 150 节点的系统初始化,避免因环境差异导致组件部署失败:
- name: 基础环境初始化(150节点批量执行)
hosts: all
remote_user: root
tasks:
# 1. 关闭防火墙(IDC内网环境,避免端口拦截)
- name: 停止firewalld
service: name=firewalld state=stopped enabled=no
# 2. 配置系统参数(优化内存、文件句柄数,适配Hadoop大数据场景)
- name: 修改sysctl.conf(关闭SWAP、调整TCP参数)
copy: src=files/sysctl.conf dest=/etc/sysctl.conf
- name: 生效系统参数
command: sysctl -p
# 3. 安装依赖包(Java、Python、gcc等,Hadoop/Redis编译依赖)
- name: 安装基础依赖
yum: name={{ item }} state=installed
with_items:
- java-1.8.0-openjdk-devel
- python3
- gcc
- openssh-clients
# 4. 配置免密登录(Ansible基于SSH通信,150节点间需免密,避免交互输入密码)
- name: 分发公钥到所有节点
authorized_key: user=root key="{{ lookup('file', '/root/.ssh/id_rsa.pub') }}"关键作用:这一步解决了 "手动逐节点关闭防火墙、配置免密" 的重复工作,150 节点执行仅需 5 分钟,且通过copy模块统一配置文件,避免参数不一致。
(2)组件部署:按依赖顺序实现一键安装
以Redis 集群部署(主从 + 哨兵模式)为例,通过redis.yml剧本和角色化设计,实现 3 主 3 从 + 3 哨兵的自动化部署:
- name: Redis集群部署(主从+哨兵)
hosts: redis_nodes
roles:
- role: redis
# 传递变量:主节点IP、哨兵监控参数
redis_master_ips: ["172.16.5.10", "172.16.5.11", "172.16.5.12"]
sentinel_monitor_name: "mymaster"
sentinel_quorum: 2 # 至少2个哨兵认为主节点故障才触发切换角色内部通过模板文件动态生成配置(如redis.conf.j2),避免硬编码:
# redis.conf模板(动态生成主从配置)
{% if inventory_hostname in redis_master_ips %}
# 主节点配置
bind {{ ansible_eth0.ipv4.address }}
port 6379
daemonize yes
{% else %}
# 从节点配置
slaveof {{ redis_master_ips[0] }} 6379
{% endif %}
maxmemory 16gb # 按节点内存动态分配(通过变量传递)
maxmemory-policy volatile-lru # 内存淘汰策略核心价值:后续新增 Redis 节点时,仅需在inventory中添加主机,重新执行剧本即可,无需修改脚本,适配集群扩容需求。
(3)组件联动:解决跨组件配置依赖
例如 Hive 需关联 HDFS 存储数据、关联 MySQL 存储元数据,通过hive.yml剧本实现联动:
- name: Hive部署与联动配置
hosts: hive_server
tasks:
# 1. 配置Hive关联HDFS(指定HDFS存储路径)
- name: 修改hive-site.xml
xml:
path: /opt/hive/conf/hive-site.xml
xpath: /configuration/property[name='hive.metastore.warehouse.dir']/value
value: hdfs://hdfs-master:9000/user/hive/warehouse
# 2. 初始化Hive元数据(关联MySQL)
- name: 执行元数据初始化
command: schematool -dbType mysql -initSchema -url jdbc:mysql://172.16.5.20:3306/hive_meta -userName hive -password 123456
# 3. 配置Redis缓存Hive查询结果(提升查询效率)
- name: 修改hive-site.xml启用Redis缓存
xml:
path: /opt/hive/conf/hive-site.xml
xpath: /configuration/property[name='hive.cache.external.enabled']/value
value: "true"
xpath: /configuration/property[name='hive.cache.redis.host']/value
value: "{{ redis_master_ips[0] }}"3. 后期维护:性能调优与故障自动化排查
(1)全组件性能调优
针对 150 节点集群的资源瓶颈,编写tuning.yml剧本实现批量调优:
- Hadoop 调优:根据节点内存(如 64GB)动态调整 YARN 容器内存(yarn.scheduler.maximum-allocation-mb=32768)、MapReduce 任务内存(mapreduce.map.memory.mb=8192);
- Redis 调优:主节点开启 AOF 持久化(appendfsync everysec),从节点关闭 AOF(仅主节点写入,减少 IO 压力);
- ZooKeeper 调优:增大会话超时时间(tickTime=2000,initLimit=10),避免 IDC 内网波动导致的连接断开。
(2)故障自动化排查
开发check_cluster.yml剧本,定期检查组件状态,出现故障自动输出排查日志:
- name: 集群健康检查
hosts: all
tasks:
# 检查HDFS DataNode状态
- name: 查看DataNode是否存活
command: hdfs dfsadmin -report
register: dfs_report
when: inventory_hostname in groups['hdfs_master']
- name: 输出故障DataNode
debug: msg="{{ dfs_report.stdout_lines | select('search', 'Decommissioned') | list }}"
when: inventory_hostname in groups['hdfs_master']
# 检查Redis主从同步状态
- name: 查看Redis同步状态
command: redis-cli -h {{ ansible_eth0.ipv4.address }} info replication
register: redis_repl
when: inventory_hostname in groups['redis_nodes']
- name: 输出同步异常节点
debug: msg="{{ redis_repl.stdout_lines | select('search', 'master_link_status:down') | list }}"
when: inventory_hostname in groups['redis_nodes']三、项目难点与解决方案:从 "踩坑" 到 "标准化"
1. 难点 1:150 节点批量部署时的 "阻塞问题"
问题描述:初期执行脚本时,因 150 节点同时从 Ansible 控制机拉取安装包(如 Hadoop-3.3.4.tar.gz,约 600MB),导致控制机网卡带宽跑满(1Gbps 链路),部分节点下载超时,部署中断。
解决方案:
- 搭建本地 YUM 源与文件服务器(在 IDC 内网部署 Nginx,将所有安装包放在 Nginx 根目录);
- 修改 Ansible 脚本,让节点从本地文件服务器拉取安装包,而非从控制机拉取:
# 原配置(控制机推送到节点,占用带宽)
- copy: src=files/hadoop-3.3.4.tar.gz dest=/opt/
# 优化后(节点从本地Nginx拉取,减轻控制机压力)
- get_url: url=http://172.16.5.100/packages/hadoop-3.3.4.tar.gz dest=/opt/效果:下载超时率从 30% 降至 0,部署时间从 4 小时缩短至 2 小时。
2. 难点 2:Redis 主从同步 "数据不一致"
问题描述:Redis 集群部署后,部分从节点与主节点同步延迟超 10 秒,导致 Hive 查询 Redis 缓存时获取到旧数据,影响业务准确性。
排查与解决:
- 通过 Ansible 脚本批量查看 Redis 同步状态:
ansible redis_nodes -m command -a "redis-cli info replication | grep lag"发现同步延迟高的节点均为跨机柜部署,机柜间链路延迟约 50ms(同一机柜内延迟 < 10ms);
- 优化方案:
-
- 调整 Redis 主从同步参数:开启无盘同步(repl-diskless-sync yes),避免从节点写入磁盘导致的延迟;
-
- 重新规划 Redis 节点部署:将主从节点放在同一机柜,跨机柜仅部署哨兵节点,减少跨机柜通信;
- 验证:同步延迟从 10 秒降至 < 1 秒,满足业务需求。
3. 难点 3:Hadoop NameNode "内存溢出"
问题描述:150 节点 HDFS 存储约 10TB 数据,NameNode 内存默认配置为 2GB,运行 1 周后内存使用率达 95%,出现 GC 频繁(每秒 2-3 次),HDFS 响应延迟超 500ms。
解决方案:
- 通过jstat -gc <NameNode PID> 1000确认内存溢出原因:元数据(文件 inode、块信息)过多,默认内存不足;
- 在hadoop.yml调优剧本中,根据数据量动态调整 NameNode 内存:
- name: 修改NameNode内存配置
lineinfile:
path: /opt/hadoop/etc/hadoop/hadoop-env.sh
regexp: '^export HADOOP_NAMENODE_OPTS='
line: 'export HADOOP_NAMENODE_OPTS="-Xms8g -Xmx8g $HADOOP_NAMENODE_OPTS"' # 调整为8GB效果:GC 频率降至每分钟 1-2 次,HDFS 响应延迟恢复至 50ms 以内。
四、项目成果:自动化运维的价值落地
- 效率提升:150 节点集群部署时间从 75 小时(手动)→2 小时(自动化),后期扩容 10 个节点仅需 10 分钟;
- 稳定性提升:组件故障排查时间从 1 小时→5 分钟(通过自动化检查脚本),集群可用性从 98%→99.99%;
- 可复用性:开发的 Ansible 角色(ZooKeeper、Redis、Hadoop)可直接复用至其他项目,后续同类集群部署成本降低 80%;
- 性能优化:Hadoop MapReduce 任务执行时间缩短 30%(YARN 资源调优),Redis 缓存命中率提升至 92%(内存淘汰策略优化),Hive 查询速度提升 50%(Redis 缓存查询结果)。
五、面试高频问题与参考答案(结合项目实战)
1. 问题 1:你在项目中如何用 Ansible 实现 150 节点的批量部署?如果某节点部署失败,如何处理?
参考答案:
首先通过inventory文件按组件角色分组(如 zk_nodes、hdfs_slave),再用 "剧本 + 角色" 模式拆分部署逻辑,比如hadoop.yml剧本调用 hadoop 角色,通过模板文件动态生成配置,避免硬编码。
若某节点部署失败(如依赖包安装超时),Ansible 会自动输出失败任务日志,我会先通过ansible <失败节点IP> -m command -a "cat /var/log/ansible.log"查看详细错误,若为网络问题(如节点断连),修复网络后执行ansible-playbook --limit <失败节点IP> hadoop.yml(--limit 参数仅重新执行该节点);若为配置问题(如参数不兼容),修改模板文件后重新执行,无需全部节点重新部署。
2. 问题 2:Redis 主从同步延迟高的问题,你是如何排查和解决的?
参考答案:
首先通过 Ansible 批量执行redis-cli info replication,筛选出master_link_status=up但slave_repl_offset与主节点差距大的节点,发现这些节点均跨机柜部署,通过ping测试确认机柜间链路延迟达 50ms(同一机柜 < 10ms)。
解决时从两方面优化:一是调整 Redis 配置,开启无盘同步(repl-diskless-sync yes),避免从节点将同步数据写入磁盘的 IO 延迟;二是重新规划部署,将主从节点放在同一机柜,跨机柜仅部署哨兵节点,减少跨机柜通信。最终同步延迟从 10 秒降至 < 1 秒。
3. 问题 3:Hadoop NameNode 内存溢出,你是如何定位和解决的?
参考答案:
首先通过jps找到 NameNode 进程 PID,再用jstat -gc <PID> 1000监控 GC 情况,发现 Full GC 每秒 2-3 次,内存使用率超 95%,初步判断是元数据过多导致内存不足。
接着查看 NameNode 元数据大小(du -sh /opt/hadoop/data/nameNode/current),发现约 7GB(默认内存 2GB),于是在 Ansible 调优剧本中修改hadoop-env.sh,将 NameNode 内存调整为 8GB(-Xms8g -Xmx8g),同时清理 HDFS 中无用的历史数据(通过 `hdfs dfs -rm -r /tmp