Flask-SQLAlchemy精读-双语精选文章
The Architecture of Open Source Applications (Volume 2) SQLAlchemy 《开源应用程序架构(第二卷)SQLAlchemy》
Michael Bayer 迈克尔·贝耶尔
If you enjoy these books, you may also enjoy Software Design by Example in Python and Software Design by Example in JavaScript.
如果你喜欢这些书,你可能也会喜欢《Python 实例软件设计》和《JavaScript 实例软件设计》。
SQLAlchemy is a database toolkit and object-relational mapping (ORM) system for the Python programming language, first introduced in 2005. From the beginning, it has sought to provide an end-to-end system for working with relational databases in Python, using the Python Database API (DBAPI) for database interactivity. Even in its earliest releases, SQLAlchemy's capabilities attracted a lot of attention. Key features include a great deal of fluency in dealing with complex SQL queries and object mappings, as well as an implementation of the "unit of work" pattern, which provides for a highly automated system of persisting data to a database.
SQLAlchemy 是 Python 编程语言的一个数据库工具包和对象关系映射(ORM)系统,于 2005 年首次推出。从一开始,它就致力于提供一个用于在 Python 中处理关系数据库的端到端系统,使用 Python 数据库 API(DBAPI)进行数据库交互。即使在最早的版本中,SQLAlchemy 的功能也吸引了大量关注。主要特点包括处理复杂 SQL 查询和对象映射的出色能力,以及"工作单元"模式的实现,该模式提供了一种高度自动化的系统,用于将数据持久化到数据库中。
Starting from a small, roughly implemented concept, SQLAlchemy quickly progressed through a series of transformations and reworkings, turning over new iterations of its internal architectures as well as its public API as the userbase continued to grow. By the time version 0.5 was introduced in January of 2009, SQLAlchemy had begun to assume a stable form that was already proving itself in a wide variety of production deployments. Throughout 0.6 (April, 2010) and 0.7 (May, 2011), architectural and API enhancements continued the process of producing the most efficient and stable library possible. As of this writing, SQLAlchemy is used by a large number of organizations in a variety of fields, and is considered by many to be the de facto standard for working with relational databases in Python.
从一个小而粗略的概念开始,SQLAlchemy 通过一系列的转换和重做迅速发展,随着用户基数的增长,不断推出其内部架构的新版本以及公共 API。到 2009 年 1 月版本 0.5 发布时,SQLAlchemy 已经呈现出一种稳定的形态,并在各种生产部署中证明了其有效性。在 0.6(2010 年 4 月)和 0.7(2011 年 5 月)期间,架构和 API 的增强继续推动着创建尽可能高效和稳定的库的过程。截至本文写作时,SQLAlchemy 被众多不同领域的组织使用,并被许多人认为是 Python 中处理关系数据库的事实标准。
20.1. The Challenge of Database Abstraction 20.1. 数据库抽象的挑战
The term "database abstraction" is often assumed to mean a system of database communication which conceals the majority of details of how data is stored and queried. The term is sometimes taken to the extreme, in that such a system should not only conceal the specifics of the relational database in use, but also the details of the relational structures themselves and even whether or not the underlying storage is relational.
"数据库抽象"这一术语通常被认为是一种数据库通信系统,该系统隐藏了数据存储和查询的大部分细节。这个术语有时会被极端化理解,即这样的系统不仅应该隐藏所使用的关系数据库的具体细节,还应隐藏关系结构本身的细节,甚至是否底层存储是关系型的。
The most common critiques of ORMs center on the assumption that this is the primary purpose of such a tool---to "hide" the usage of a relational database, taking over the task of constructing an interaction with the database and reducing it to an implementation detail. Central to this approach of concealment is that the ability to design and query relational structures is taken away from the developer and instead handled by an opaque library.
对 ORM 最常见的批评集中在这样一个假设上:这种工具的主要目的是"隐藏"关系数据库的使用,接管与数据库交互的任务,并将其简化为实施细节。这种隐藏方法的核心在于,设计和查询关系结构的能力被从开发者手中剥夺,转而由一个不透明的库来处理。
Those who work heavily with relational databases know that this approach is entirely impractical. Relational structures and SQL queries are vastly functional, and comprise the core of an application's design. How these structures should be designed, organized, and manipulated in queries varies not just on what data is desired, but also on the structure of information. If this utility is concealed, there's little point in using a relational database in the first place.
那些大量使用关系型数据库的人都知道这种方法完全不切实际。关系型结构和 SQL 查询功能强大,构成了应用程序设计的核心。这些结构应该如何设计、组织以及在查询中如何操作,不仅取决于所需的数据,还取决于信息的结构。如果这种工具被隐藏起来,那么使用关系型数据库本身就没有什么意义了。
The issue of reconciling applications that seek concealment of an underlying relational database with the fact that relational databases require great specificity is often referred to as the "object-relational impedance mismatch" problem. SQLAlchemy takes a somewhat novel approach to this problem.
将那些寻求隐藏底层关系型数据库的应用与关系型数据库需要高度具体性的事实协调起来的问题,通常被称为"对象-关系阻抗不匹配"问题。SQLAlchemy 对这个问题的处理方式有些新颖。
SQLAlchemy's Approach to Database Abstraction SQLAlchemy 的数据库抽象方法
SQLAlchemy takes the position that the developer must be willing to consider the relational form of his or her data. A system which pre-determines and conceals schema and query design decisions marginalizes the usefulness of using a relational database, leading to all of the classic problems of impedance mismatch.
SQLAlchemy 认为开发者必须愿意考虑其数据的关系型形式。一个预先确定并隐藏模式设计和查询决策的系统会降低使用关系型数据库的实用性,从而导致所有经典的阻抗不匹配问题。
At the same time, the implementation of these decisions can and should be executed through high-level patterns as much as possible. Relating an object model to a schema and persisting it via SQL queries is a highly repetitive task. Allowing tools to automate these tasks allows the development of an application that's more succinct, capable, and efficient, and can be created in a fraction of the time it would take to develop these operations manually.
与此同时,这些决策的实施应当尽可能通过高级模式来执行。将对象模型与模式关联并通过 SQL 查询进行持久化是一项高度重复的任务。允许工具自动化这些任务,可以使应用程序更加简洁、强大和高效,并且可以在手动开发这些操作所需时间的一小部分时间内完成。
To this end, SQLAlchemy refers to itself as a toolkit , to emphasize the role of the developer as the designer/builder of all relational structures and linkages between those structures and the application, not as a passive consumer of decisions made by a library. By exposing relational concepts, SQLAlchemy embraces the idea of "leaky abstraction", encouraging the developer to tailor a custom, yet fully automated, interaction layer between the application and the relational database. SQLAlchemy's innovation is the extent to which it allows a high degree of automation with little to no sacrifice in control over the relational database.
为此,SQLAlchemy 将自己称为一个工具包,以强调开发者的角色是所有关系结构的开发者/构建者,以及这些结构与应用程序之间的链接,而不是作为一个被动接受库所做决策的消费者。通过暴露关系概念,SQLAlchemy 拥抱了"泄漏抽象"的理念,鼓励开发者定制一个自定义的、但完全自动化的应用程序与关系数据库之间的交互层。SQLAlchemy 的创新之处在于它允许在几乎不牺牲对关系数据库控制权的情况下实现高度自动化。
20.2. The Core/ORM Dichotomy 20.2. 核心/ORM 二元论
Central to SQLAlchemy's goal of providing a toolkit approach is that it exposes every layer of database interaction as a rich API, dividing the task into two main categories known as Core and ORM . The Core includes Python Database API (DBAPI) interaction, rendering of textual SQL statements understood by the database, and schema management. These features are all presented as public APIs. The ORM, or object-relational mapper, is then a specific library built on top of the Core. The ORM provided with SQLAlchemy is only one of any number of possible object abstraction layers that could be built upon the Core, and many developers and organizations build their applications on top of the Core directly.
SQLAlchemy 的核心目标在于提供工具箱式方法,它将每一层数据库交互都暴露为丰富的 API,将任务分为两大主要类别,即核心(Core)和对象关系映射(ORM)。核心(Core)包括 Python 数据库 API(DBAPI)交互、数据库理解的文本 SQL 语句的渲染以及模式管理。这些功能都以公共 API 的形式呈现。ORM,即对象关系映射器,是建立在核心(Core)之上的一个特定库。SQLAlchemy 提供的 ORM 只是基于核心(Core)可能构建的众多对象抽象层之一,许多开发者和组织直接在核心(Core)之上构建他们的应用程序。
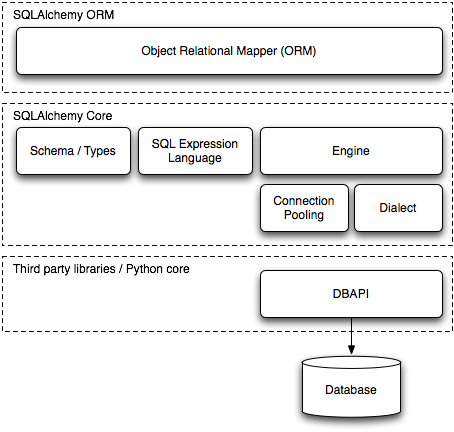
Figure 20.1: SQLAlchemy layer diagram
图 20.1:SQLAlchemy 层结构图
The Core/ORM separation has always been SQLAlchemy's most defining feature, and it has both pros and cons. The explicit Core present in SQLAlchemy leads the ORM to relate database-mapped class attributes to a structure known as a Table, rather than directly to their string column names as expressed in the database; to produce a SELECT query using a structure called select, rather than piecing together object attributes directly into a string statement; and to receive result rows through a facade called ResultProxy, which transparently maps the select to each result row, rather than transferring data directly from a database cursor to a user-defined object.
核心/ORM 的分离一直是 SQLAlchemy 最显著的特点,它既有优点也有缺点。SQLAlchemy 中明确的核心使得 ORM 将数据库映射类属性与一个称为 Table 的结构相关联,而不是直接关联到数据库中表达的字符串列名;使用一个称为 select 的结构来生成 SELECT 查询,而不是直接将对象属性拼接到字符串语句中;并通过一个称为 ResultProxy 的接口接收结果行,该接口透明地将 select 映射到每一行结果,而不是直接从数据库游标传输数据到用户定义的对象。
Core elements may not be visible in a very simple ORM-centric application. However, as the Core is carefully integrated into the ORM to allow fluid transition between ORM and Core constructs, a more complex ORM-centric application can "move down" a level or two in order to deal with the database in a more specific and finely tuned manner, as the situation requires. As SQLAlchemy has matured, the Core API has become less explicit in regular use as the ORM continues to provide more sophisticated and comprehensive patterns. However, the availability of the Core was also a contributor to SQLAlchemy's early success, as it allowed early users to accomplish much more than would have been possible when the ORM was still being developed.
在非常简单的以 ORM 为中心的应用中,核心元素可能并不明显。然而,由于核心被精心集成到 ORM 中,使得 ORM 和核心构造之间能够流畅过渡,一个更复杂的以 ORM 为中心的应用可以根据需要"向下"移动一个或两个级别,以便以更具体和精细的方式处理数据库。随着 SQLAlchemy 的成熟,核心 API 在日常使用中变得越来越不明确,因为 ORM 持续提供更复杂和全面的模式。然而,核心的可用性也是 SQLAlchemy 早期成功的一个因素,因为它允许早期用户完成比 ORM 仍在开发时可能完成的更多的事情。
The downside to the ORM/Core approach is that instructions must travel through more steps. Python's traditional C implementation has a significant overhead penalty for individual function calls, which are the primary cause of slowness in the runtime. Traditional methods of ameliorating this include shortening call chains through rearrangement and inlining, and replacing performance-critical areas with C code. SQLAlchemy has spent many years using both of these methods to improve performance. However, the growing acceptance of the PyPy interpreter for Python may promise to squash the remaining performance problems without the need to replace the majority of SQLAlchemy's internals with C code, as PyPy vastly reduces the impact of long call chains through just-in-time inlining and compilation.
ORM/Core 方法的一个缺点是指令必须经过更多步骤。Python 的传统 C 实现对于单个函数调用有显著的开销惩罚,这是运行时缓慢的主要原因。传统的改善方法包括通过重新排列和内联来缩短调用链,以及用 C 代码替换性能关键区域。SQLAlchemy 花费了多年时间使用这两种方法来提高性能。然而,随着 PyPy 解释器在 Python 中的日益普及,它或许能够在无需用 C 代码替换 SQLAlchemy 的大部分内部组件的情况下,通过即时内联和编译大大减少长调用链的影响,从而解决剩余的性能问题。
20.3. Taming the DBAPI 20.3. 控制 DBAPI
At the base of SQLAlchemy is a system for interacting with the database via the DBAPI. The DBAPI itself is not an actual library, only a specification. Therefore, implementations of the DBAPI are available for a particular target database, such as MySQL or PostgreSQL, or alternatively for particular non-DBAPI database adapters, such as ODBC and JDBC.
SQLAlchemy 的基础是一个通过 DBAPI 与数据库交互的系统。DBAPI 本身并不是一个实际的库,而只是一个规范。因此,DBAPI 的实现可用于特定的目标数据库,如 MySQL 或 PostgreSQL,或者用于特定的非 DBAPI 数据库适配器,如 ODBC 和 JDBC。
The DBAPI presents two challenges. The first is to provide an easy-to-use yet full-featured facade around the DBAPI's rudimentary usage patterns. The second is to handle the extremely variable nature of specific DBAPI implementations as well as the underlying database engines.
DBAPI 提出了两个挑战。第一个是提供一个易于使用且功能全面的 DBAPI 基本使用模式的外部接口。第二个是处理特定 DBAPI 实现以及底层数据库引擎的高度可变性。
The Dialect System 方言系统
The interface described by the DBAPI is extremely simple. Its core components are the DBAPI module itself, the connection object, and the cursor object---a "cursor" in database parlance represents the context of a particular statement and its associated results. A simple interaction with these objects to connect and retrieve data from a database is as follows:
DBAPI 描述的接口极其简单。其核心组件包括 DBAPI 模块本身、连接对象和游标对象------在数据库术语中,游标表示特定语句及其相关结果的上下文。与这些对象进行简单交互以连接数据库并检索数据的过程如下:
connection = dbapi.connect(user="user", pw="pw", host="host")
cursor = connection.cursor()
cursor.execute("select * from user_table where name=?", ("jack",))
print "Columns in result:", [desc[0] for desc in cursor.description]
for row in cursor.fetchall():
print "Row:", row
cursor.close()
connection.close()
connection = dbapi.connect(user="user", pw="pw", host="host")
cursor = connection.cursor()
cursor.execute("select * from user_table where name=?", ("jack",))
print "Columns in result:", [desc[0] for desc in cursor.description]
for row in cursor.fetchall():
print "Row:", row
cursor.close()
connection.close()SQLAlchemy creates a facade around the classical DBAPI conversation. The point of entry to this facade is the create_engine call, from which connection and configuration information is assembled. An instance of Engine is produced as the result. This object then represents the gateway to the DBAPI, which itself is never exposed directly.
SQLAlchemy 在经典的 DBAPI 会话周围创建了一个外观。进入这个外观的入口是 create_engine 调用,从中组装连接和配置信息。产生一个 Engine 的实例作为结果。这个对象随后代表了通往 DBAPI 的入口,而 DBAPI 本身永远不会直接暴露。
For simple statement executions, Engine offers what's known as an implicit execution interface. The work of acquiring and closing both a DBAPI connection and cursor are handled behind the scenes:
对于简单的语句执行, Engine 提供了一种隐式执行接口。获取和关闭 DBAPI 连接和游标的工作在后台处理:
engine = create_engine("postgresql://user:pw@host/dbname")
result = engine.execute("select * from table")
print result.fetchall()When SQLAlchemy 0.2 was introduced the Connection object was added, providing the ability to explicitly maintain the scope of the DBAPI connection:
当 SQLAlchemy 0.2 版本发布时,引入了 Connection 对象,提供了显式维护 DBAPI 连接范围的能力:
conn = engine.connect()
result = conn.execute("select * from table")
print result.fetchall()
conn.close()The result returned by the execute method of Engine or Connection is called a ResultProxy, which offers an interface similar to the DBAPI cursor but with richer behavior. The Engine, Connection, and ResultProxy correspond to the DBAPI module, an instance of a specific DBAPI connection, and an instance of a specific DBAPI cursor, respectively.
execute 方法返回的结果称为 ResultProxy ,它提供了一个类似于 DBAPI 游标的接口,但具有更丰富的行为。 Engine 、 Connection 和 ResultProxy 分别对应于 DBAPI 模块、特定 DBAPI 连接的实例以及特定 DBAPI 游标的实例。
Behind the scenes, the Engine references an object called a Dialect. The Dialect is an abstract class for which many implementations exist, each one targeted at a specific DBAPI/database combination. A Connection created on behalf of the Engine will refer to this Dialect for all decisions, which may have varied behaviors depending on the target DBAPI and database in use.
在幕后, Engine 引用一个称为 Dialect 的对象。 Dialect 是一个抽象类,存在许多针对特定 DBAPI/数据库组合的实现。为 Engine 创建的 Connection 将针对所有决策引用这个 Dialect ,其行为可能因目标 DBAPI 和使用的数据库而异。
The Connection, when created, will procure and maintain an actual DBAPI connection from a repository known as a Pool that's also associated with the Engine. The Pool is responsible for creating new DBAPI connections and, usually, maintaining them in an in-memory pool for frequent re-use.
当 Connection 被创建时,它会从与 Engine 关联的一个名为 Pool 的存储库中获取并维护一个实际的 DBAPI 连接。 Pool 负责创建新的 DBAPI 连接,并且通常会在内存池中维护它们以便频繁重用。
During a statement execution, an additional object called an ExecutionContext is created by the Connection. The object lasts from the point of execution throughout the lifespan of the ResultProxy. It may also be available as a specific subclass for some DBAPI/database combinations.
在语句执行期间, Connection 会创建一个名为 ExecutionContext 的额外对象。该对象从执行点持续到 ResultProxy 的整个生命周期。对于某些 DBAPI/数据库组合,它也可能作为一个特定的子类可用。
Figure 20.2 illustrates all of these objects and their relationships to each other as well as to the DBAPI components.
图 20.2 展示了所有这些对象及其相互关系,以及它们与 DBAPI 组件的关系。
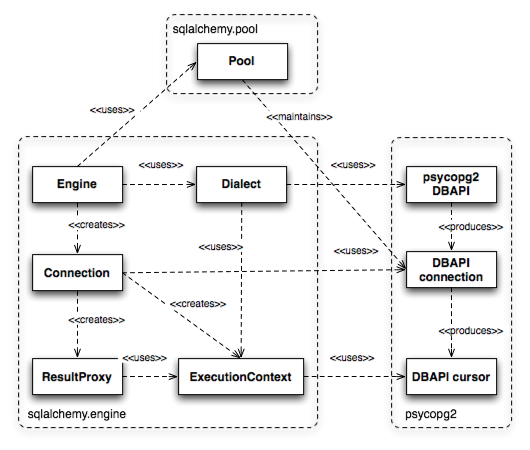
Figure 20.2: Engine, Connection, ResultProxy API
图 20.2:引擎、连接、结果代理 API
Dealing with DBAPI Variability 处理 DBAPI 的差异性
For the task of managing variability in DBAPI behavior, first we'll consider the scope of the problem. The DBAPI specification, currently at version two, is written as a series of API definitions which allow for a wide degree of variability in behavior, and leave a good number of areas undefined. As a result, real-life DBAPIs exhibit a great degree of variability in several areas, including when Python unicode strings are acceptable and when they are not; how the "last inserted id"---that is, an autogenerated primary key---may be acquired after an INSERT statement; and how bound parameter values may be specified and interpreted. They also have a large number of idiosyncratic type-oriented behaviors, including the handling of binary, precision numeric, date, Boolean, and unicode data.
对于管理 DBAPI 行为差异的任务,我们首先需要考虑问题的范围。当前的 DBAPI 规范版本为二,它是一系列 API 定义的集合,允许行为具有很大的差异性,并且留下了许多未定义的领域。因此,现实中的 DBAPI 在多个方面表现出很大的差异性,包括当 Python Unicode 字符串可以被接受和不被接受的时候;如何在执行 INSERT 语句后获取"最后插入的 ID"------即自动生成的主键;以及如何指定和解释绑定参数值。它们还拥有大量特殊类型导向的行为,包括处理二进制、精确数值、日期、布尔值和 Unicode 数据。
SQLAlchemy approaches this by allowing variability in both Dialect and ExecutionContext via multi-level subclassing. Figure 20.3 illustrates the relationship between Dialect and ExecutionContext when used with the psycopg2 dialect. The PGDialect class provides behaviors that are specific to the usage of the PostgreSQL database, such as the ARRAY datatype and schema catalogs; the PGDialect_psycopg2 class then provides behaviors specific to the psycopg2 DBAPI, including unicode data handlers and server-side cursor behavior.
SQLAlchemy 通过多级子类化来实现 Dialect 和 ExecutionContext 的多样性。图 20.3 展示了在使用 psycopg2 方言时 Dialect 和 ExecutionContext 之间的关系。 PGDialect 类提供了针对 PostgreSQL 数据库使用的特定行为,例如 ARRAY 数据类型和模式目录;而 PGDialect_psycopg2 类则提供了针对 psycopg2 DBAPI 的特定行为,包括 unicode 数据处理器和服务器端游标行为。
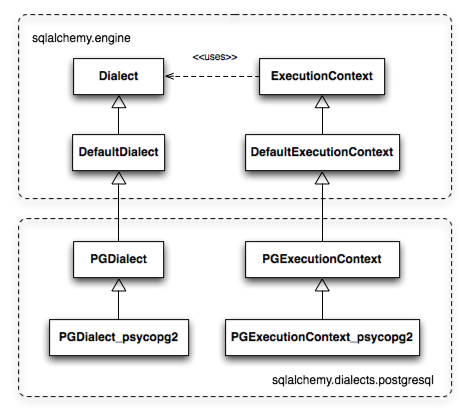
Figure 20.3: Simple Dialect/ExecutionContext hierarchy
图 20.3:简单的方言/执行上下文层次结构
A variant on the above pattern presents itself when dealing with a DBAPI that supports multiple databases. Examples of this include pyodbc, which deals with any number of database backends via ODBC, and zxjdbc, a Jython-only driver which deals with JDBC. The above relationship is augmented by the use of a mixin class from the sqlalchemy.connectors package which provides DBAPI behavior that is common to multiple backends. Figure 20.4 illustrates the common functionality of sqlalchemy.connectors.pyodbc shared among pyodbc-specific dialects for MySQL and Microsoft SQL Server.
在处理支持多个数据库的 DBAPI 时,会出现上述模式的变体。例如 pyodbc,它通过 ODBC 处理任意数量的数据库后端,以及 zxjdbc,这是一个仅适用于 Jython 的驱动程序,用于处理 JDBC。上述关系通过使用来自 sqlalchemy.connectors 包的混入类得到增强,该类提供了多个后端共有的 DBAPI 行为。图 20.4 说明了 sqlalchemy.connectors.pyodbc 在 pyodbc 特定的 MySQL 和 Microsoft SQL Server 方言之间共享的通用功能。
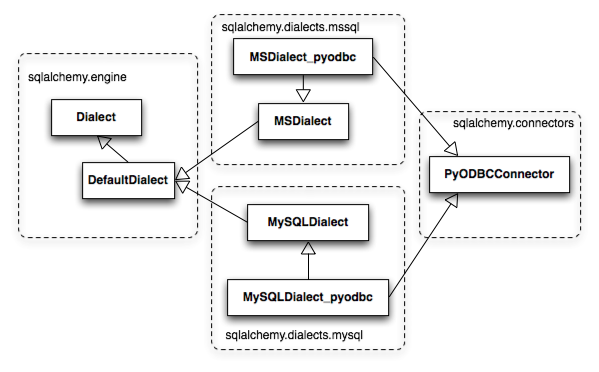
Figure 20.4: Common DBAPI behavior shared among dialect hierarchies
图 20.4:方言层次结构之间共享的通用 DBAPI 行为
The Dialect and ExecutionContext objects provide a means to define every interaction with the database and DBAPI, including how connection arguments are formatted and how special quirks during statement execution are handled. The Dialect is also a factory for SQL compilation constructs that render SQL correctly for the target database, and type objects which define how Python data should be marshaled to and from the target DBAPI and database.
Dialect 和 ExecutionContext 对象提供了一种定义与数据库和 DBAPI 交互的方式,包括如何格式化连接参数以及如何处理语句执行过程中的特殊问题。 Dialect 还是一个 SQL 编译结构的工厂,用于为目标数据库正确渲染 SQL,以及类型对象,用于定义 Python 数据如何序列化到和从目标 DBAPI 和数据库反序列化。
20.4. Schema Definition 20.4. 模式定义
With database connectivity and interactivity established, the next task is to provide for the creation and manipulation of backend-agnostic SQL statements. To achieve this, we need to define first how we will refer to the tables and columns present in a database---the so-called "schema". Tables and columns represent how data is organized, and most SQL statements consist of expressions and commands referring to these structures.
在建立了数据库连接和交互之后,下一个任务是提供创建和操作后端无关的 SQL 语句的功能。为了实现这一点,我们首先需要定义如何引用数据库中存在的表和列------所谓的"模式"。表和列代表了数据的组织方式,大多数 SQL 语句都由引用这些结构的表达式和命令组成。
An ORM or data access layer needs to provide programmatic access to the SQL language; at the base is a programmatic system of describing tables and columns. This is where SQLAlchemy offers the first strong division of Core and ORM, by offering the Table and Column constructs that describe the structure of the database independently of a user's model class definition. The rationale behind the division of schema definition from object relational mapping is that the relational schema can be designed unambiguously in terms of the relational database, including platform-specific details if necessary, without being muddled by object-relational concepts---these remain a separate concern. Being independent of the ORM component also means the schema description system is just as useful for any other kind of object-relational system which may be built on the Core.
一个 ORM 或数据访问层需要提供对 SQL 语言的程序化访问;其基础是一个描述表和列的程序化系统。这正是 SQLAlchemy 提供了 Core 和 ORM 的第一层强分界,通过提供 Table 和 Column 结构来独立描述数据库结构,而与用户模型类的定义无关。将模式定义与对象关系映射分离的理由在于,关系模式可以在关系数据库的术语中明确地设计,包括必要的平台特定细节,而不会被对象关系概念所混淆------这些仍然是一个独立的问题。与 ORM 组件的独立性也意味着,模式描述系统对于任何可能建立在 Core 之上的其他类型的对象关系系统同样有用。
The Table and Column model falls under the scope of what's referred to as metadata , offering a collection object called MetaData to represent a collection of Table objects. The structure is derived mostly from Martin Fowler's description of "Metadata Mapping" in Patterns of Enterprise Application Architecture . Figure 20.5 illustrates some key elements of the sqlalchemy.schema package.
Table 和 Column 模型属于所谓的元数据范畴,提供一个名为 MetaData 的集合对象来表示一组 Table 对象。这种结构主要源自马丁·福勒在《企业应用架构模式》中描述的"元数据映射"。图 20.5 展示了 sqlalchemy.schema 包的一些关键元素。
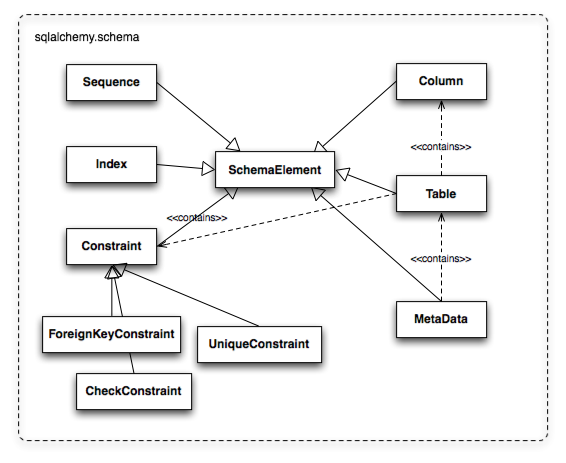
Figure 20.5: Basic sqlalchemy.schema objects
图 20.5:基本的 sqlalchemy.schema 对象
Table represents the name and other attributes of an actual table present in a target schema. Its collection of Column objects represents naming and typing information about individual table columns. A full array of objects describing constraints, indexes, and sequences is provided to fill in many more details, some of which impact the behavior of the engine and SQL construction system. In particular, ForeignKeyConstraint is central to determining how two tables should be joined.
Table 代表目标模式中实际存在的表的名字和其他属性。其 Column 对象的集合表示单个表列的命名和类型信息。提供了一组完整的对象来描述约束、索引和序列,以填充更多细节,其中一些细节会影响引擎和 SQL 构建系统的行为。特别是, ForeignKeyConstraint 对于确定两个表如何连接至关重要。
Table and Column in the schema package are unique versus the rest of the package in that they are dual-inheriting, both from the sqlalchemy.schema package and the sqlalchemy.sql.expression package, serving not just as schema-level constructs, but also as core syntactical units in the SQL expression language. This relationship is illustrated in Figure 20.6.
模式包中的 Table 和 Column 与包中的其他部分不同,因为它们是双重继承的,既继承自 sqlalchemy.schema 包也继承自 sqlalchemy.sql.expression 包,不仅作为模式级别的结构,还作为 SQL 表达式语言的核心语法单元。这种关系在图 20.6 中进行了说明。
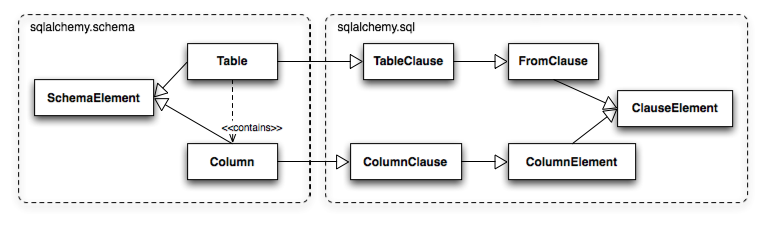
Figure 20.6: The dual lives of Table and Column
图 20.6:Table 和 Column 的双重生活
In Figure 20.6 we can see that Table and Column inherit from the SQL world as specific forms of "things you can select from", known as a FromClause, and "things you can use in a SQL expression", known as a ColumnElement.
在图 20.6 中我们可以看到, Table 和 Column 继承了 SQL 世界的特性,作为"可以从中选择的东西"的具体形式,被称为 FromClause ,以及"可以在 SQL 表达式中使用的东西",被称为 ColumnElement 。
20.5. SQL Expressions 20.5. SQL 表达式
During SQLAlchemy's creation, the approach to SQL generation wasn't clear. A textual language might have been a likely candidate; this is a common approach which is at the core of well-known object-relational tools like Hibernate's HQL. For Python, however, a more intriguing choice was available: using Python objects and expressions to generatively construct expression tree structures, even re-purposing Python operators so that operators could be given SQL statement behavior.
在 SQLAlchemy 的创建过程中,SQL 生成方法并不明确。一种文本语言可能是一个合适的选择;这是一种常见方法,是知名对象关系工具如 Hibernate 的 HQL 的核心。然而,对于 Python 来说,有一个更有趣的选择:使用 Python 对象和表达式来生成表达式树结构,甚至重新利用 Python 运算符,使运算符能够具有 SQL 语句的行为。
While it may not have been the first tool to do so, full credit goes to the SQLBuilder library included in Ian Bicking's SQLObject as the inspiration for the system of Python objects and operators used by SQLAlchemy's expression language. In this approach, Python objects represent lexical portions of a SQL expression. Methods on those objects, as well as overloaded operators, generate new lexical constructs derived from them. The most common object is the "Column" object---SQLObject would represent these on an ORM-mapped class using a namespace accessed via the .q attribute; SQLAlchemy named the attribute .c. The .c attribute remains today on Core selectable elements, such as those representing tables and select statements.
虽然它可能不是第一个实现该功能的工具,但完全应该归功于 Ian Bicking 的 SQLObject 中包含的 SQLBuilder 库,它为 SQLAlchemy 表达式语言所使用的 Python 对象和操作符系统提供了灵感。在这种方法中,Python 对象代表 SQL 表达式的词法部分。这些对象上的方法以及重载的操作符会生成新的词法结构。最常见的对象是"Column"对象------SQLObject 会使用一个通过 .q 属性访问的命名空间来表示这些对象在 ORM 映射的类上;SQLAlchemy 将这个属性命名为 .c 。至今, .c 属性仍然存在于 Core 可选择的元素上,例如表示表和 SELECT 语句的元素。
Expression Trees 表达式树
A SQLAlchemy SQL expression construct is very much the kind of structure you'd create if you were parsing a SQL statement---it's a parse tree, except the developer creates the parse tree directly, rather than deriving it from a string. The core type of node in this parse tree is called ClauseElement, and Figure 20.7 illustrates the relationship of ClauseElement to some key classes.
SQLAlchemy 的 SQL 表达式结构非常类似于如果你在解析 SQL 语句时创建的结构------它是一个解析树,只是开发者直接创建了解析树,而不是从字符串中派生出来。这种解析树的核心节点类型称为 ClauseElement ,图 20.7 展示了 ClauseElement 与一些关键类的关系。
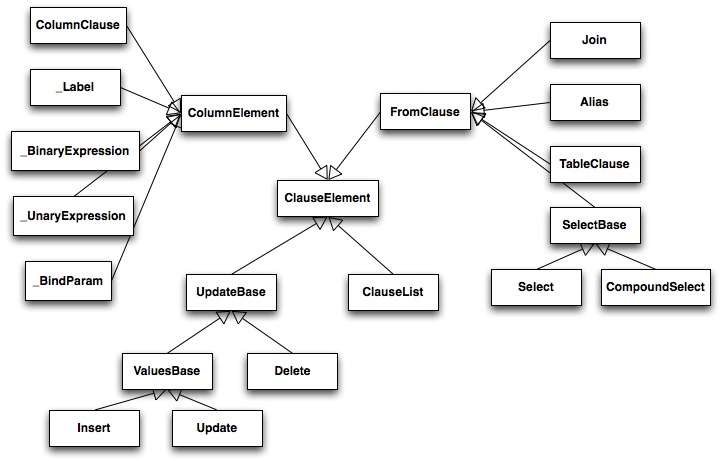
Figure 20.7: Basic expression hierarchy
图 20.7:基本表达式层次结构
Through the use of constructor functions, methods, and overloaded Python operator functions, a structure for a statement like:
通过使用构造函数、方法和重载的 Python 运算符函数,可以构建类似于以下结构的语句:
SELECT id FROM user WHERE name = ?might be constructed in Python like:
可以用 Python 构建如下:
from sqlalchemy.sql import table, column, select
user = table('user', column('id'), column('name'))
stmt = select([user.c.id]).where(user.c.name=='ed')The structure of the above select construct is shown in Figure 20.8. Note the representation of the literal value 'ed' is contained within the _BindParam construct, thus causing it to be rendered as a bound parameter marker in the SQL string using a question mark.
上述 select 结构的构成如图 20.8 所示。请注意,字面值 'ed' 包含在 _BindParam 结构中,因此在 SQL 字符串中将其渲染为绑定参数标记(问号)。
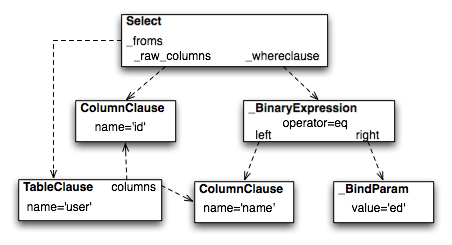
Figure 20.8: Example expression tree
图 20.8:示例表达式树
From the tree diagram, one can see that a simple descending traversal through the nodes can quickly create a rendered SQL statement, as we'll see in greater detail in the section on statement compilation.
从树状图可以看出,通过节点进行简单的降序遍历可以快速创建渲染后的 SQL 语句,正如我们在语句编译部分将更详细地看到的那样。
Python Operator Approach Python 运算符方法
In SQLAlchemy, an expression like this:
在 SQLAlchemy 中,像这样的表达式:
column('a') == 2produces neither True nor False, but instead a SQL expression construct. The key to this is to overload operators using the Python special operator functions: e.g., methods like __eq__, __ne__, __le__, __lt__, __add__, __mul__. Column-oriented expression nodes provide overloaded Python operator behavior through the usage of a mixin called ColumnOperators. Using operator overloading, an expression column('a') == 2 is equivalent to:
不会生成 True 或 False ,而是生成一个 SQL 表达式结构。关键在于使用 Python 的特殊运算符函数重载运算符:例如 __eq__ 、 __ne__ 、 __le__ 、 __lt__ 、 __add__ 、 __mul__ 等方法。列式表达式节点通过使用名为 ColumnOperators 的混入(mixin)提供重载的 Python 运算符行为。通过运算符重载,表达式 column('a') == 2 等同于:
from sqlalchemy.sql.expression import _BinaryExpression
from sqlalchemy.sql import column, bindparam
from sqlalchemy.operators import eq
_BinaryExpression(
left=column('a'),
right=bindparam('a', value=2, unique=True),
operator=eq
)The eq construct is actually a function originating from the Python operator built-in. Representing operators as an object (i.e., operator.eq) rather than a string (i.e., =) allows the string representation to be defined at statement compilation time, when database dialect information is known.
eq 语法实际上是源自 Python 的 operator 内置功能。将运算符表示为对象(即 operator.eq )而不是字符串(即 = )允许在语句编译时定义其字符串表示,此时已知数据库方言信息。
Compilation 编译
The central class responsible for rendering SQL expression trees into textual SQL is the Compiled class. This class has two primary subclasses, SQLCompiler and DDLCompiler. SQLCompiler handles SQL rendering operations for SELECT, INSERT, UPDATE, and DELETE statements, collectively classified as DQL (data query language) and DML (data manipulation language), while DDLCompiler handles various CREATE and DROP statements, classified as DDL (data definition language). There is an additional class hierarchy focused around string representations of types, starting at TypeCompiler. Individual dialects then provide their own subclasses of all three compiler types to define SQL language aspects specific to the target database. Figure 20.9 provides an overview of this class hierarchy with respect to the PostgreSQL dialect.
负责将 SQL 表达式树渲染为文本 SQL 的核心类是 Compiled 类。该类有两个主要子类, SQLCompiler 和 DDLCompiler 。 SQLCompiler 处理 SELECT、INSERT、UPDATE 和 DELETE 语句的 SQL 渲染操作,这些语句统称为 DQL(数据查询语言)和 DML(数据操作语言),而 DDLCompiler 处理各种 CREATE 和 DROP 语句,这些语句属于 DDL(数据定义语言)。还有一个围绕类型字符串表示的额外类层次结构,从 TypeCompiler 开始。各个方言随后为三种编译器类型提供自己的子类,以定义针对目标数据库的特定 SQL 语言方面。图 20.9 展示了与 PostgreSQL 方言相关的类层次结构概述。
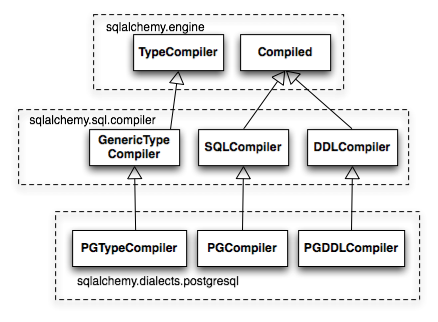
Figure 20.9: Compiler hierarchy, including PostgreSQL-specific implementation
图 20.9:编译器层次结构,包括 PostgreSQL 特定实现
The Compiled subclasses define a series of visit methods, each one referred to by a particular subclass of ClauseElement. A hierarchy of ClauseElement nodes is walked and a statement is constructed by recursively concatenating the string output of each visit function. As this proceeds, the Compiled object maintains state regarding anonymous identifier names, bound parameter names, and nesting of subqueries, among other things, all of which aim for the production of a string SQL statement as well as a final collection of bound parameters with default values. Figure 20.10 illustrates the process of visit methods resulting in textual units.
Compiled 的子类定义了一系列访问方法,每个方法由 ClauseElement 的特定子类引用。通过遍历 ClauseElement 节点的层次结构,并通过递归连接每个访问函数的字符串输出来构建语句。在此过程中, Compiled 对象维护关于匿名标识符名称、绑定参数名称和子查询嵌套等状态,所有这些都有助于生成字符串形式的 SQL 语句以及具有默认值的绑定参数集合。图 20.10 说明了访问方法如何产生文本单元的过程。
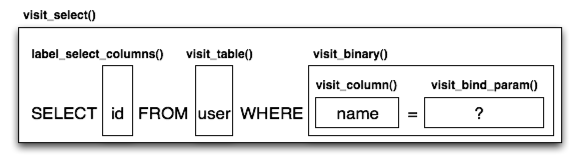
Figure 20.10: Call hierarchy of a statement compilation
图 20.10:语句编译的调用层次
A completed Compiled structure contains the full SQL string and collection of bound values. These are coerced by an ExecutionContext into the format expected by the DBAPI's execute method, which includes such considerations as the treatment of a unicode statement object, the type of collection used to store bound values, as well as specifics on how the bound values themselves should be coerced into representations appropriate to the DBAPI and target database.
完成的 Compiled 结构包含完整的 SQL 字符串和绑定值集合。这些值通过 ExecutionContext 转换为 DBAPI 的 execute 方法所期望的格式,其中包括对 Unicode 语句对象的处理、用于存储绑定值的集合类型,以及绑定值本身应如何转换为适合 DBAPI 和目标数据库的表示形式等具体考虑。
20.6. Class Mapping with the ORM 20.6. 与 ORM 的类映射
We now shift our attention to the ORM. The first goal is to use the system of table metadata we've defined to allow mapping of a user-defined class to a collection of columns in a database table. The second goal is to allow the definition of relationships between user-defined classes, based on relationships between tables in a database.
我们现在将注意力转向 ORM。第一个目标是利用我们定义的表元数据系统,将用户定义的类映射到数据库表中的一组列。第二个目标是允许根据数据库中表之间的关系来定义用户定义类之间的关系。
SQLAlchemy refers to this as "mapping", following the well known Data Mapper pattern described in Fowler's Patterns of Enterprise Architecture . Overall, the SQLAlchemy ORM draws heavily from the practices detailed by Fowler. It's also heavily influenced by the famous Java relational mapper Hibernate and Ian Bicking's SQLObject product for Python.
SQLAlchemy 将此称为"映射",遵循 Fowler 在《企业架构模式》中描述的著名数据映射模式。总体而言,SQLAlchemy ORM 大量借鉴了 Fowler 详细阐述的实践。它也深受著名 Java 关系映射器 Hibernate 和 Ian Bicking 为 Python 开发的 SQLObject 产品的影响。
Classical vs. Declarative 经典映射与声明式映射
We use the term classical mapping to refer to SQLAlchemy's system of applying an object-relational data mapping to an existing user class. This form considers the Table object and the user-defined class to be two individually defined entities which are joined together via a function called mapper. Once mapper has been applied to a user-defined class, the class takes on new attributes that correspond to columns in the table:
我们使用术语经典映射来指代 SQLAlchemy 将对象关系数据映射应用于现有用户类系统的做法。这种形式将 Table 对象和用户定义的类视为两个分别定义的实体,通过一个称为 mapper 的函数将它们连接起来。一旦 mapper 被应用于用户定义的类,该类就会获得对应于表中列的新属性:
class User(object):
pass
mapper(User, user_table)
# now User has an ".id" attribute
User.idmapper can also affix other kinds of attributes to the class, including attributes which correspond to references to other kinds of objects, as well as arbitrary SQL expressions. The process of affixing arbitrary attributes to a class is known in the Python world as "monkeypatching"; however, since we are doing it in a data-driven and non-arbitrary way, the spirit of the operation is better expressed with the term class instrumentation.
Modern usage of SQLAlchemy centers around the Declarative extension, which is a configurational system that resembles the common active-record-like class declaration system used by many other object-relational tools. In this system, the end user explicitly defines attributes inline with the class definition, each representing an attribute on the class that is to be mapped. The Table object, in most cases, is not mentioned explicitly, nor is the mapper function; only the class, the Column objects, and other ORM-related attributes are named:
现代 SQLAlchemy 的使用主要围绕声明式扩展,这是一个类似于许多其他对象关系工具中常用的常见活动记录式类声明系统的配置系统。在这个系统中,最终用户显式地按照类定义直接定义属性,每个属性代表要映射的类上的一个属性。在大多数情况下, Table 对象和 mapper 函数都没有被明确提及;只有类、 Column 对象和其他 ORM 相关的属性被命名:
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)It may appear, above, that the class instrumentation is being achieved directly by our placement of id = Column(), but this is not the case. The Declarative extension uses a Python metaclass, which is a handy way to run a series of operations each time a new class is first declared, to generate a new Table object from what's been declared, and to pass it to the mapper function along with the class. The mapper function then does its job in exactly the same way, patching its own attributes onto the class, in this case towards the id attribute, and replacing what was there previously. By the time the metaclass initialization is complete (that is, when the flow of execution leaves the block delineated by User), the Column object marked by id has been moved into a new Table, and User.id has been replaced by a new attribute specific to the mapping.
从上面看,类代理似乎是通过我们直接放置 id = Column() 来实现的,但这并非事实。声明式扩展使用了一个 Python 元类,这是一种方便的方式,每次新类首次声明时都会执行一系列操作,从已声明的类生成一个新的 Table 对象,并将其与类一起传递给 mapper 函数。然后 mapper 函数以完全相同的方式执行其工作,将自己的属性修补到类上,在这种情况下是 id 属性,并替换掉原来的内容。当元类初始化完成时(即执行流离开由 User 界定的块时),由 id 标记的 Column 对象已被移入一个新的 Table ,而 User.id 已被一个特定于映射的新属性所替换。
It was always intended that SQLAlchemy would have a shorthand, declarative form of configuration. However, the creation of Declarative was delayed in favor of continued work solidifying the mechanics of classical mapping. An interim extension called ActiveMapper, which later became the Elixir project, existed early on. It redefines mapping constructs in a higher-level declaration system. Declarative's goal was to reverse the direction of Elixir's heavily abstracted approach by establishing a system that preserved SQLAlchemy classical mapping concepts almost exactly, only reorganizing how they are used to be less verbose and more amenable to class-level extensions than a classical mapping would be.
SQLAlchemy 原本就计划提供一个简化的声明式配置方式。然而,由于要继续完善传统映射的机制,Declarative 的创建被推迟了。早期存在一个名为 ActiveMapper 的中间扩展,后来成为了 Elixir 项目。它在更高层次的声明系统中重新定义了映射结构。Declarative 的目标是通过建立一个几乎完全保留 SQLAlchemy 传统映射概念的系统,来逆转 Elixir 高度抽象化的方法,只重新组织它们的使用方式,使其更简洁,并且比传统映射更适合类级别的扩展。
Whether classical or declarative mapping is used, a mapped class takes on new behaviors that allow it to express SQL constructs in terms of its attributes. SQLAlchemy originally followed SQLObject's behavior of using a special attribute as the source of SQL column expressions, referred to by SQLAlchemy as .c, as in this example:
无论是使用传统映射还是声明式映射,映射类都会获得新的行为,使其能够通过其属性来表示 SQL 结构。SQLAlchemy 最初遵循 SQLObject 的行为,使用一个特殊属性作为 SQL 列表达式的来源,SQLAlchemy 称之为 .c ,例如这个例子:
result = session.query(User).filter(User.c.username == 'ed').all()In version 0.4, however, SQLAlchemy moved the functionality into the mapped attributes themselves:
然而,在 0.4 版本中,SQLAlchemy 将功能移至映射属性本身:
result = session.query(User).filter(User.username == 'ed').all()This change in attribute access proved to be a great improvement, as it allowed the column-like objects present on the class to gain additional class-specific capabilities not present on those originating directly from the underlying Table object. It also allowed usage integration between different kinds of class attributes, such as attributes which refer to table columns directly, attributes that refer to SQL expressions derived from those columns, and attributes that refer to a related class. Finally, it provided a symmetry between a mapped class, and an instance of that mapped class, in that the same attribute could take on different behavior depending on the type of parent. Class-bound attributes return SQL expressions while instance-bound attributes return actual data.
这种属性访问方式的改变被证明是一个巨大的改进,因为它允许类上存在的类似列的对象获得额外的、特定于类的功能,而这些功能在直接源自底层 Table 对象时并不存在。它还允许不同类型类属性之间的使用集成,例如直接引用表列的属性、引用由这些列派生出的 SQL 表达式的属性,以及引用相关类的属性。最后,它为映射类及其实例之间提供了一种对称性,即相同的属性可以根据父类的类型表现出不同的行为。类绑定的属性返回 SQL 表达式,而实例绑定的属性返回实际数据。
Anatomy of a Mapping 映射的解剖结构
The id attribute that's been attached to our User class is a type of object known in Python as a descriptor , an object that has __get__, __set__, and __del__ methods, which the Python runtime defers to for all class and instance operations involving this attribute. SQLAlchemy's implementation is known as an InstrumentedAttribute, and we'll illustrate the world behind this facade with another example. Starting with a Table and a user defined class, we set up a mapping that has just one mapped column, as well as a relationship, which defines a reference to a related class:
附加到我们 User 类上的 id 属性是一种在 Python 中被称为描述符的对象,这种对象具有 __get__ 、 __set__ 和 __del__ 方法,Python 运行时会将这些方法委托给所有涉及此属性的类和实例操作。SQLAlchemy 的实现被称为 InstrumentedAttribute ,我们将通过另一个例子来展示这个表象背后的世界。从一个 Table 和一个用户定义的类开始,我们设置一个只有一个映射列的映射,以及一个 relationship ,它定义了对相关类的引用:
user_table = Table("user", metadata,
Column('id', Integer, primary_key=True),
)
class User(object):
pass
mapper(User, user_table, properties={
'related':relationship(Address)
})When the mapping is complete, the structure of objects related to the class is detailed in Figure 20.11.
映射完成后,与类相关的对象结构在图 20.11 中详细展示。
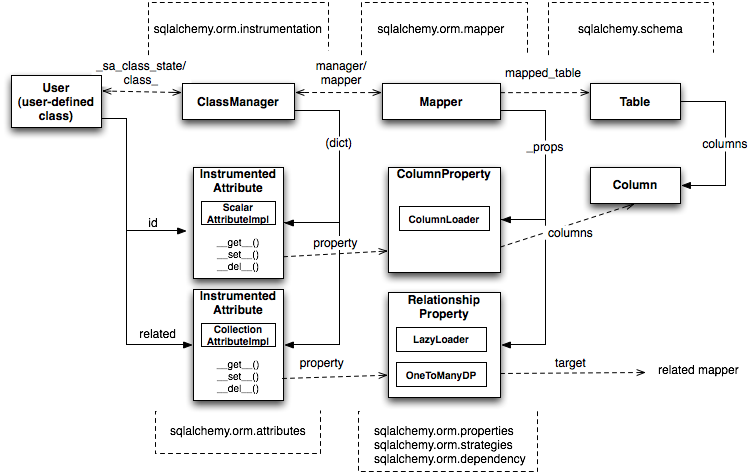
Figure 20.11: Anatomy of a mapping
图 20.11:映射的解剖结构
The figure illustrates a SQLAlchemy mapping defined as two separate layers of interaction between the user-defined class and the table metadata to which it is mapped. Class instrumentation is pictured towards the left, while SQL and database functionality is pictured towards the right. The general pattern at play is that object composition is used to isolate behavioral roles, and object inheritance is used to distinguish amongst behavioral variances within a particular role.
该图展示了一个 SQLAlchemy 映射,它定义了用户定义的类与其映射的表元数据之间的两个独立交互层。类元器具图示在左侧,而 SQL 和数据库功能则图示在右侧。起作用的一般模式是使用对象组合来隔离行为角色,并使用对象继承来区分特定角色内的行为差异。
Within the realm of class instrumentation, the ClassManager is linked to the mapped class, while its collection of InstrumentedAttribute objects are linked to each attribute mapped on the class. InstrumentedAttribute is also the public-facing Python descriptor mentioned previously, and produces SQL expressions when used in a class-based expression (e.g., User.id==5). When dealing with an instance of User, InstrumentedAttribute delegates the behavior of the attribute to an AttributeImpl object, which is one of several varieties tailored towards the type of data being represented.
在类元具的范围内, ClassManager 与映射的类相关联,而其 InstrumentedAttribute 对象集合则与类上映射的每个属性相关联。 InstrumentedAttribute 也是之前提到的面向公众的 Python 描述符,在基于类的表达式中使用时(例如, User.id==5 )会产生 SQL 表达式。在处理 User 的实例时, InstrumentedAttribute 将属性的委托行为分配给一个 AttributeImpl 对象,该对象是针对所表示数据类型设计的多种类型之一。
Towards the mapping side, the Mapper represents the linkage of a user-defined class and a selectable unit, most typically Table. Mapper maintains a collection of per-attribute objects known as MapperProperty, which deals with the SQL representation of a particular attribute. The most common variants of MapperProperty are ColumnProperty, representing a mapped column or SQL expression, and RelationshipProperty, representing a linkage to another mapper.
在映射方面, Mapper 表示用户定义类和可选择性单元之间的链接,最典型的是 Table 。 Mapper 维护一组称为 MapperProperty 的每个属性对象,这些对象处理特定属性的 SQL 表示形式。 MapperProperty 最常见的变体是 ColumnProperty ,表示映射列或 SQL 表达式,以及 RelationshipProperty ,表示与另一个映射器的链接。
MapperProperty delegates attribute loading behavior---including how the attribute renders in a SQL statement and how it is populated from a result row---to a LoaderStrategy object, of which there are several varieties. Different LoaderStrategies determine if the loading behavior of an attribute is deferred , eager , or immediate . A default version is chosen at mapper configuration time, with the option to use an alternate strategy at query time. RelationshipProperty also references a DependencyProcessor, which handles how inter-mapper dependencies and attribute synchronization should proceed at flush time. The choice of DependencyProcessor is based on the relational geometry of the parent and target selectables linked to the relationship.
MapperProperty 将属性加载行为------包括属性如何在 SQL 语句中呈现以及如何从结果行中填充------委托给 LoaderStrategy 对象,此类对象有多种类型。不同的 LoaderStrategies 决定属性的加载行为是延迟、即时还是立即。在映射器配置时选择默认版本,并在查询时可以选择使用替代策略。 RelationshipProperty 还引用一个 DependencyProcessor ,该对象处理在刷新时间如何进行映射器之间的依赖关系和属性同步。 DependencyProcessor 的选择基于与关系链接的父级和目标可选择性之间的关系几何形状。
The Mapper/RelationshipProperty structure forms a graph, where Mapper objects are nodes and RelationshipProperty objects are directed edges. Once the full set of mappers have been declared by an application, a deferred "initialization" step known as the configuration proceeds. It is used mainly by each RelationshipProperty to solidify the details between its parent and target mappers, including choice of AttributeImpl as well as DependencyProcessor. This graph is a key data structure used throughout the operation of the ORM. It participates in operations such as the so-called "cascade" behavior that defines how operations should propagate along object paths, in query operations where related objects and collections are "eagerly" loaded at once, as well as on the object flushing side where a dependency graph of all objects is established before firing off a series of persistence steps.
Mapper / RelationshipProperty 结构形成一个图,其中 Mapper 对象是节点, RelationshipProperty 对象是指向边。一旦应用程序声明了完整的映射集,就会进行一个延迟的"初始化"步骤,称为配置。它主要用于每个 RelationshipProperty 来固化其父映射和目标映射之间的细节,包括 AttributeImpl 的选择以及 DependencyProcessor 。这个图是整个 ORM 操作中的关键数据结构。它参与诸如所谓的"级联"行为等操作,该行为定义了操作应如何沿对象路径传播;在查询操作中,相关对象和集合会"立即"一次性加载;以及在对象刷新方面,在触发一系列持久化步骤之前,会建立所有对象的依赖关系图。
20.7. Query and Loading Behavior 20.7. 查询和加载行为
SQLAlchemy initiates all object loading behavior via an object called Query. The basic state Query starts with includes the entities , which is the list of mapped classes and/or individual SQL expressions to be queried. It also has a reference to the Session, which represents connectivity to one or more databases, as well as a cache of data that's been accumulated with respect to transactions on those connections. Below is a rudimentary usage example:
SQLAlchemy 通过名为 Query 的对象来启动所有对象加载行为。基本状态 Query 初始包含实体,即要查询的映射类列表和/或单个 SQL 表达式。它还包含对 Session 的引用,该引用表示与一个或多个数据库的连接,以及关于这些连接上事务所积累的数据的缓存。以下是一个基本的用法示例:
from sqlalchemy.orm import Session
session = Session(engine)
query = session.query(User)We create a Query that will yield instances of User, relative to a new Session we've created. Query provides a generative builder pattern in the same way as the select construct discussed previously, where additional criteria and modifiers are associated with a statement construct one method call at a time. When an iterative operation is called on the Query, it constructs a SQL expression construct representing a SELECT, emits it to the database, and then interprets the result set rows as ORM-oriented results corresponding to the initial set of entities being requested.
我们创建一个 Query ,它将生成 User 的实例,相对于我们创建的新 Session 。 Query 以与先前讨论的 select 构造相同的方式提供生成式构建器模式,其中附加标准和修饰符随方法调用一次关联到语句构造上。当在 Query 上调用迭代操作时,它构建一个表示 SELECT 的 SQL 表达式构造,将其发射到数据库,然后解释结果集行作为与最初请求的实体集对应的 ORM 导向结果。
Query makes a hard distinction between the SQL rendering and the data loading portions of the operation. The former refers to the construction of a SELECT statement, the latter to the interpretation of SQL result rows into ORM-mapped constructs. Data loading can, in fact, proceed without a SQL rendering step, as the Query may be asked to interpret results from a textual query hand-composed by the user.
Query 在操作的 SQL 渲染和数据加载部分之间做出硬性区分。前者指 SELECT 语句的构建,后者指将 SQL 结果行解释为 ORM 映射构造。实际上,数据加载可以在没有 SQL 渲染步骤的情况下进行,因为 Query 可能会被要求解释用户手工编写的文本查询的结果。
Both SQL rendering and data loading utilize a recursive descent through the graph formed by the series of lead Mapper objects, considering each column- or SQL-expression-holding ColumnProperty as a leaf node and each RelationshipProperty which is to be included in the query via a so-called "eager-load" as an edge leading to another Mapper node. The traversal and action to take at each node is ultimately the job of each LoaderStrategy associated with every MapperProperty, adding columns and joins to the SELECT statement being built in the SQL rendering phase, and producing Python functions that process result rows in the data loading phase.
SQL 渲染和数据加载都通过由一系列的 lead Mapper 对象形成的图进行递归下降,将每个包含列或 SQL 表达式的 ColumnProperty 视为叶节点,将每个通过所谓的"急加载"包含在查询中的 RelationshipProperty 视为指向另一个 Mapper 节点的边。每个 LoaderStrategy 与每个 MapperProperty 相关联,最终负责在每个节点上的遍历和采取的操作,在 SQL 渲染阶段向正在构建的 SELECT 语句添加列和连接,并在数据加载阶段生成处理结果行的 Python 函数。
The Python functions produced in the data loading phase each receive a database row as they are fetched, and produce a possible change in the state of a mapped attribute in memory as a result. They are produced for a particular attribute conditionally, based on examination of the first incoming row in the result set, as well as on loading options. If a load of the attribute is not to proceed, no callable function is produced.
数据加载阶段生成的 Python 函数在获取数据库行时接收一行数据,并作为结果产生内存中映射属性状态的可能变化。它们根据对结果集中的第一行输入行的检查以及加载选项有条件地生成。如果属性加载不继续进行,则不会生成可调用的函数。
Figure 20.12 illustrates the traversal of several LoaderStrategy objects in a joined eager loading scenario, illustrating their connection to a rendered SQL statement which occurs during the _compile_context method of Query. It also shows generation of row population functions which receive result rows and populate individual object attributes, a process which occurs within the instances method of Query.
图 20.12 展示了在联合急加载场景中多个 LoaderStrategy 对象的遍历过程,展示了它们与在 _compile_context 方法的 Query 期间生成的渲染 SQL 语句的连接。它还显示了行填充函数的生成,这些函数接收结果行并填充单个对象属性,该过程发生在 Query 的 instances 方法中。
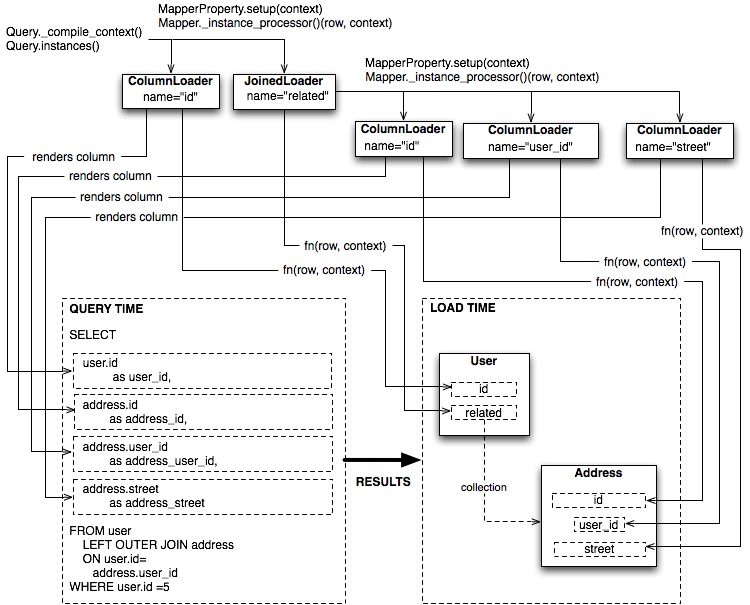
Figure 20.12: Traversal of loader strategies including a joined eager load
图 20.12:包括联合急加载的加载策略遍历
SQLAlchemy's early approach to populating results used a traditional traversal of fixed object methods associated with each strategy to receive each row and act accordingly. The loader callable system, first introduced in version 0.5, represented a dramatic leap in performance, as many decisions regarding row handling could be made just once up front instead of for each row, and a significant number of function calls with no net effect could be eliminated.
SQLAlchemy 早期的结果填充方法使用了与每种策略相关联的固定对象方法的传统遍历来接收每一行并相应地处理。在 0.5 版本中首次引入的加载可调用系统代表了性能上的巨大飞跃,因为许多关于行处理的决策可以一次性提前做出,而不是为每一行做出,并且可以消除大量没有净效果的函数调用。
20.8. Session/Identity Map
In SQLAlchemy, the Session object presents the public interface for the actual usage of the ORM---that is, loading and persisting data. It provides the starting point for queries and persistence operations for a given database connection.
在 SQLAlchemy 中, Session 对象提供了 ORM 实际使用的公共接口------也就是说,加载数据和持久化数据。它为给定数据库连接的查询和持久化操作提供了起点。
The Session, in addition to serving as the gateway for database connectivity, maintains an active reference to the set of all mapped entities which are present in memory relative to that Session. It's in this way that the Session implements a facade for the identity map and unit of work patterns, both identified by Fowler. The identity map maintains a database-identity-unique mapping of all objects for a particular Session, eliminating the problems introduced by duplicate identities. The unit of work builds on the identity map to provide a system of automating the process of persisting all changes in state to the database in the most effective manner possible. The actual persistence step is known as a "flush", and in modern SQLAlchemy this step is usually automatic.
Session 不仅作为数据库连接的网关,还维护着与该 Session 相关联的内存中所有映射实体的活跃引用。正是通过这种方式, Session 实现了 Fowler 所识别的身份映射和单元工作模式的面板。身份映射为特定的 Session 维护所有对象数据库身份唯一的映射,消除了由重复身份引入的问题。单元工作模式在身份映射的基础上,提供了一套自动化将所有状态变更以最有效的方式持久化到数据库的机制。实际的持久化步骤被称为"刷新",在现代 SQLAlchemy 中,这一步骤通常是自动的。
Development History 开发历史
The Session started out as a mostly concealed system responsible for the single task of emitting a flush. The flush process involves emitting SQL statements to the database, corresponding to changes in the state of objects tracked by the unit of work system and thereby synchronizing the current state of the database with what's in memory. The flush has always been one of the most complex operations performed by SQLAlchemy.
Session 最初是一个几乎完全隐藏的系统,负责单一任务------执行刷新。刷新过程涉及向数据库发出 SQL 语句,这些语句对应于工作单元系统跟踪的对象状态变化,从而将数据库的当前状态与内存中的状态同步。刷新始终是 SQLAlchemy 执行的最复杂操作之一。
The invocation of flush started out in very early versions behind a method called commit, and it was a method present on an implicit, thread-local object called objectstore. When one used SQLAlchemy 0.1, there was no need to call Session.add, nor was there any concept of an explicit Session at all. The only user-facing steps were to create mappers, create new objects, modify existing objects loaded through queries (where the queries themselves were invoked directly from each Mapper object), and then persist all changes via the objectstore.commit command. The pool of objects for a set of operations was unconditionally module-global and unconditionally thread-local.
commit 的调用最初在非常早期的版本中通过一个名为 commit 的方法进行,该方法存在于一个隐式、线程本地的对象 objectstore 上。当使用 SQLAlchemy 0.1 时,无需调用 Session.add ,也根本没有明确的 Session 的概念。用户面对的步骤仅包括创建映射器、创建新对象、修改通过查询加载的现有对象(查询本身直接从每个 Mapper 对象中调用),然后通过 objectstore.commit 命令持久化所有更改。一组操作的物体池是无条件模块全局的,也是无条件线程本地的。
The objectstore.commit model was an immediate hit with the first group of users, but the rigidity of this model quickly ran into a wall. Users new to modern SQLAlchemy sometimes lament the need to define a factory, and possibly a registry, for Session objects, as well as the need to keep their objects organized into just one Session at a time, but this is far preferable to the early days when the entire system was completely implicit. The convenience of the 0.1 usage pattern is still largely present in modern SQLAlchemy, which features a session registry normally configured to use thread local scoping.
objectstore.commit 模型在第一批用户中立刻大受欢迎,但这种模型的僵化很快遇到了瓶颈。对于刚开始使用现代 SQLAlchemy 的用户来说,有时会抱怨需要为 Session 对象定义一个工厂,甚至可能需要一个注册表,还需要将他们的对象组织到同一 Session 中,但这远比早期整个系统完全隐式化的日子要好得多。0.1 用法模式的便利性在现代 SQLAlchemy 中仍然很大程度上存在,其特点是会配置一个通常使用线程本地作用域的会话注册表。
The Session itself was only introduced in version 0.2 of SQLAlchemy, modeled loosely after the Session object present in Hibernate. This version featured integrated transactional control, where the Session could be placed into a transaction via the begin method, and completed via the commit method. The objectstore.commit method was renamed to objectstore.flush, and new Session objects could be created at any time. The Session itself was broken off from another object called UnitOfWork, which remains as a private object responsible for executing the actual flush operation.
Session 本身是在 SQLAlchemy 0.2 版本中引入的,其设计灵感来源于 Hibernate 中的 Session 对象。这个版本集成了事务控制,其中 Session 可以通过 begin 方法放入事务,并通过 commit 方法完成。 objectstore.commit 方法被重命名为 objectstore.flush ,并且可以在任何时候创建新的 Session 对象。 Session 本身是从另一个名为 UnitOfWork 的对象中分离出来的,该对象仍然作为一个私有对象负责执行实际的刷新操作。
While the flush process started as a method explicitly invoked by the user, the 0.4 series of SQLAlchemy introduced the concept of autoflush , which meant that a flush was emitted immediately before each query. The advantage of autoflush is that the SQL statement emitted by a query always has access on the relational side to the exact state that is present in memory, as all changes have been sent over. Early versions of SQLAlchemy couldn't include this feature, because the most common pattern of usage was that the flush statement would also commit the changes permanently. But when autoflush was introduced, it was accompanied by another feature called the transactional Session, which provided a Session that would start out automatically in a transaction that remained until the user called commit explicitly. With the introduction of this feature, the flush method no longer committed the data that it flushed, and could safely be called on an automated basis. The Session could now provide a step-by-step synchronization between in-memory state and SQL query state by flushing as needed, with nothing permanently persisted until the explicit commit step. This behavior is, in fact, exactly the same in Hibernate for Java. However, SQLAlchemy embraced this style of usage based on the same behavior in the Storm ORM for Python, introduced when SQLAlchemy was in version 0.3.
虽然刷新过程最初是作为用户显式调用的方法开始的,但 SQLAlchemy 0.4 系列引入了自动刷新的概念,这意味着在每次查询之前都会立即发出刷新。自动刷新的优点在于,查询发出的 SQL 语句始终能够在关系端访问到内存中存在的确切状态,因为所有更改都已发送。早期版本的 SQLAlchemy 无法包含此功能,因为最常见的使用模式是刷新语句也会永久提交更改。但当自动刷新被引入时,它伴随着另一个称为事务性 Session 的功能,该功能提供了一个 Session ,它将自动开始于一个事务,直到用户显式调用 commit 才会结束。随着这一功能的引入, flush 方法不再提交它刷新的数据,并且可以安全地自动调用。 Session 现在可以通过按需刷新,在内存状态和 SQL 查询状态之间提供逐步同步,直到显式的 commit 步骤才会永久持久化。 这种行为实际上在 Java 的 Hibernate 中也是如此。然而,SQLAlchemy 基于 Python 的 Storm ORM 中引入的相同行为,采用了这种使用风格,当时 SQLAlchemy 的版本是 0.3。
Version 0.5 brought more transaction integration when post-transaction expiration was introduced; after each commit or rollback, by default all states within the Session are expired (erased), to be populated again when subsequent SQL statements re-select the data, or when the attributes on the remaining set of expired objects are accessed in the context of the new transaction. Originally, SQLAlchemy was constructed around the assumption that SELECT statements should be emitted as little as possible, unconditionally. The expire-on-commit behavior was slow in coming for this reason; however, it entirely solved the issue of the Session which contained stale data post-transaction with no simple way to load newer data without rebuilding the full set of objects already loaded. Early on, it seemed that this problem couldn't be reasonably solved, as it wasn't apparent when the Session should consider the current state to be stale, and thus produce an expensive new set of SELECT statements on the next access. However, once the Session moved to an always-in-a-transaction model, the point of transaction end became apparent as the natural point of data expiration, as the nature of a transaction with a high degree of isolation is that it cannot see new data until it's committed or rolled back anyway. Different databases and configurations, of course, have varied degrees of transaction isolation, including no transactions at all. These modes of usage are entirely acceptable with SQLAlchemy's expiration model; the developer only needs to be aware that a lower isolation level may expose un-isolated changes within a Session if multiple Sessions share the same rows. This is not at all different from what can occur when using two database connections directly.
版本 0.5 在引入后事务过期机制时增加了更多的事务集成;默认情况下,每个 commit 或 rollback 之后, Session 内的所有状态都会过期(被清除),当后续 SQL 语句重新选择数据时,或者在新事务的上下文中访问剩余过期对象上的属性时,才会再次填充。最初,SQLAlchemy 是基于 SELECT 语句应尽可能少地无条件发出的假设构建的。由于这个原因,过期于提交的行为迟迟未能实现;然而,它完全解决了 Session 中包含事务后过时数据的问题,而没有任何简单的方法来加载新数据,除非重新构建已加载的对象完整集。早期,似乎这个问题无法合理解决,因为不清楚 Session 何时应将当前状态视为过时,从而在下次访问时生成昂贵的新的 SELECT 语句集。 然而,一旦 Session 切换到始终处于事务模式,事务结束点就自然成为数据过期点,因为具有高度隔离性的事务本质上是无法看到新数据,直到它被提交或回滚。当然,不同的数据库和配置具有不同程度的隔离性,包括完全不使用事务。这些使用模式在 SQLAlchemy 的过期模型中完全可行;开发者只需注意,如果多个 Session 共享相同行,较低的隔离级别可能会暴露未隔离的更改。这与直接使用两个数据库连接时可能发生的情况完全相同。
Session Overview Session 概述
Figure 20.13 illustrates a Session and the primary structures it deals with.
图 20.13 展示了 Session 及其处理的主要结构。
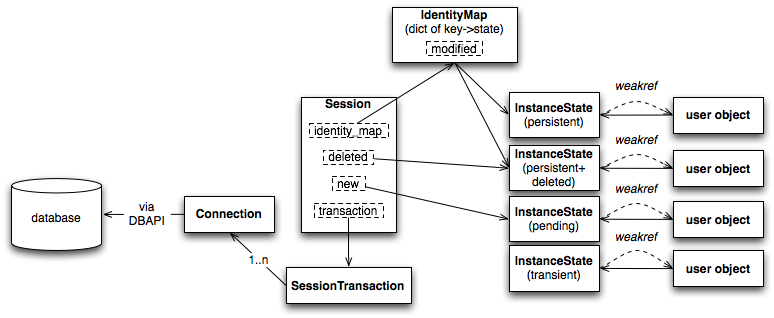
Figure 20.13: Session overview
图 20.13:会话概览
The public-facing portions above are the Session itself and the collection of user objects, each of which is an instance of a mapped class. Here we see that mapped objects keep a reference to a SQLAlchemy construct called InstanceState, which tracks ORM state for an individual instance including pending attribute changes and attribute expiration status. InstanceState is the instance-level side of the attribute instrumentation discussed in the preceding section, Anatomy of a Mapping , corresponding to the ClassManager at the class level, and maintaining the state of the mapped object's dictionary (i.e., the Python __dict__ attribute) on behalf of the AttributeImpl objects associated with the class.
上述面向公众的部分包括 Session 本身以及用户对象集合,每个对象都是映射类的一个实例。在这里我们看到映射对象保留了对一个名为 InstanceState 的 SQLAlchemy 结构的引用,该结构跟踪单个实例的 ORM 状态,包括待处理的属性更改和属性过期状态。 InstanceState 是前面讨论的映射解剖学中属性仪器化在实例级别的部分,对应于类级别的 ClassManager ,并为与类关联的 AttributeImpl 对象维护映射对象的字典(即 Python 的 __dict__ 属性)的状态。
State Tracking 状态跟踪
The IdentityMap is a mapping of database identities to InstanceState objects, for those objects which have a database identity, which are referred to as persistent . The default implementation of IdentityMap works with InstanceState to self-manage its size by removing user-mapped instances once all strong references to them have been removed---in this way it works in the same way as Python's WeakValueDictionary. The Session protects the set of all objects marked as dirty or deleted , as well as pending objects marked new , from garbage collection, by creating strong references to those objects with pending changes. All strong references are then discarded after the flush.
IdentityMap 是将数据库身份映射到 InstanceState 对象的映射,对于那些具有数据库身份的对象,这些对象被称为持久化对象。 IdentityMap 的默认实现与 InstanceState 协作,通过在所有强引用都被移除后删除用户映射的实例来自我管理其大小------这种方式与 Python 的 WeakValueDictionary 工作方式相同。 Session 通过为那些带有待处理更改的对象创建强引用,保护被标记为脏或已删除的对象集合,以及标记为新状态的待处理对象,使其免受垃圾回收。在刷新后,所有强引用都会被丢弃。
InstanceState also performs the critical task of maintaining "what's changed" for the attributes of a particular object, using a move-on-change system that stores the "previous" value of a particular attribute in a dictionary called committed_state before assigning the incoming value to the object's current dictionary. At flush time, the contents of committed_state and the __dict__ associated with the object are compared to produce the set of net changes on each object.
InstanceState 还执行一个关键任务,即维护特定对象属性的"已更改"状态,使用一个变更后移动的系统,在将传入值分配给对象的当前字典之前,将特定属性的"先前"值存储在一个名为 committed_state 的字典中。在刷新时,比较 committed_state 的内容以及与对象关联的 __dict__ ,以生成每个对象上的净变更集。
In the case of collections, a separate collections package coordinates with the InstrumentedAttribute/InstanceState system to maintain a collection of net changes to a particular mapped collection of objects. Common Python classes such as set, list and dict are subclassed before use and augmented with history-tracking mutator methods. The collection system was reworked in 0.4 to be open ended and usable for any collection-like object.
在集合的情况下,一个单独的 collections 包与 InstrumentedAttribute / InstanceState 系统协同工作,以维护对特定映射对象集合的一组净变更。常见的 Python 类如 set 、 list 和 dict 在使用前会被子类化,并添加了跟踪历史记录的变体方法。集合系统在 0.4 版本中进行了重构,以使其开放且适用于任何类似集合的对象。
Transactional Control 事务控制
Session, in its default state of usage, maintains an open transaction for all operations which is completed when commit or rollback is called. The SessionTransaction maintains a set of zero or more Connection objects, each representing an open transaction on a particular database. SessionTransaction is a lazy-initializing object that begins with no database state present. As a particular backend is required to participate in a statement execution, a Connection corresponding to that database is added to SessionTransaction's list of connections. While a single connection at a time is common, the multiple connection scenario is supported where the specific connection used for a particular operation is determined based on configurations associated with the Table, Mapper, or SQL construct itself involved in the operation. Multiple connections can also coordinate the transaction using two-phase behavior, for those DBAPIs which provide it.
Session 在其默认使用状态下,为所有操作维护一个打开的事务,当 commit 或 rollback 被调用时完成。 SessionTransaction 维护一组零个或多个 Connection 对象,每个对象代表一个特定数据库上的打开事务。 SessionTransaction 是一个懒加载对象,初始时没有数据库状态。当需要特定后端参与语句执行时,会向 SessionTransaction 的连接列表中添加一个对应的 Connection 对象。虽然通常一次只有一个连接,但支持多连接场景,其中特定操作使用的连接根据与操作相关的 Table 、 Mapper 或 SQL 构造本身的配置来确定。对于提供两阶段行为的 DBAPI,多个连接还可以使用两阶段行为来协调事务。
20.9. Unit of Work 20.9. 工作单元
The flush method provided by Session turns over its work to a separate module called unitofwork. As mentioned earlier, the flush process is probably the most complex function of SQLAlchemy.
Session 提供的 flush 方法将其工作交给一个名为 unitofwork 的独立模块。如前所述,刷新过程可能是 SQLAlchemy 最复杂的函数。
The job of the unit of work is to move all of the pending state present in a particular Session out to the database, emptying out the new, dirty, and deleted collections maintained by the Session. Once completed, the in-memory state of the Session and what's present in the current transaction match. The primary challenge is to determine the correct series of persistence steps, and then to perform them in the correct order. This includes determining the list of INSERT, UPDATE, and DELETE statements, including those resulting from the cascade of a related row being deleted or otherwise moved; ensuring that UPDATE statements contain only those columns which were actually modified; establishing "synchronization" operations that will copy the state of primary key columns over to referencing foreign key columns, at the point at which newly generated primary key identifiers are available; ensuring that INSERTs occur in the order in which objects were added to the Session and as efficiently as possible; and ensuring that UPDATE and DELETE statements occur within a deterministic ordering so as to reduce the chance of deadlocks.
单元工作的职责是将特定 Session 中所有待处理状态移至数据库,清空由 Session 维护的 new 、 dirty 和 deleted 集合。完成后, Session 的内存状态与当前事务中的内容将保持一致。主要挑战在于确定正确的持久化步骤序列,并按正确顺序执行这些步骤。这包括确定 INSERT、UPDATE 和 DELETE 语句的列表,包括因关联行被删除或其他移动而引发的语句;确保 UPDATE 语句仅包含实际被修改的列;建立"同步"操作,在新生成的主键标识符可用时,将主键列的状态复制到参照的外键列;确保 INSERT 操作按对象添加到 Session 的顺序以最高效的方式执行;并确保 UPDATE 和 DELETE 语句以确定性顺序执行,以降低死锁的可能性。
History 历史
The unit of work implementation began as a tangled system of structures that was written in an ad hoc way; its development can be compared to finding the way out of a forest without a map. Early bugs and missing behaviors were solved with bolted-on fixes, and while several refactorings improved matters through version 0.5, it was not until version 0.6 that the unit of work---by that time stable, well-understood, and covered by hundreds of tests---could be rewritten entirely from scratch. After many weeks of considering a new approach that would be driven by consistent data structures, the process of rewriting it to use this new model took only a few days, as the idea was by this time well understood. It was also greatly helped by the fact that the new implementation's behavior could be carefully cross-checked against the existing version. This process shows how the first iteration of something, however awful, is still valuable as long as it provides a working model. It further shows how total rewrites of a subsystem is often not only appropriate, but an integral part of development for hard-to-develop systems.
工作单元的实现最初是一个杂乱无章的结构系统,以一种临时的方式编写;其开发过程可以与在没有地图的情况下寻找森林出路相媲美。早期的错误和缺失的行为是通过临时的修补解决的,虽然几个重构在 0.5 版本中改善了情况,但直到 0.6 版本,工作单元------此时已经稳定、被充分理解并覆盖了数百个测试------才可以从头开始完全重写。在考虑了一种由一致数据结构驱动的新方法数周之后,将其重写为使用这个新模型的过程只用了几天,因为此时这个想法已经被充分理解。这也得益于新实现的行为可以与现有版本进行仔细的交叉检查。这个过程表明,无论多么糟糕,第一版只要提供了一个可工作的模型,仍然是有价值的。它还进一步表明,对子系统的完全重写不仅适当,而且对于难以开发的系统来说,是开发过程中不可或缺的一部分。
Topological Sort 拓扑排序
The key paradigm behind the unit of work is that of assembling the full list of actions to be taken into a data structure, with each node representing a single step; this is known in design patterns parlance as the command pattern . The series of "commands" within this structure is then organized into a specific ordering using a topological sort . A topological sort is a process that sorts items based on a partial ordering , that is, only certain elements must precede others. Figure 20.14 illustrates the behavior of the topological sort.
工作单元背后的关键范式是将所有要执行的操作组装成一个数据结构,其中每个节点代表一个步骤;在设计模式术语中,这被称为命令模式。在这个结构中的"命令"序列然后使用拓扑排序组织成特定的顺序。拓扑排序是一个基于偏序关系对项目进行排序的过程,也就是说,只有某些元素必须排在其他元素之前。图 20.14 说明了拓扑排序的行为。
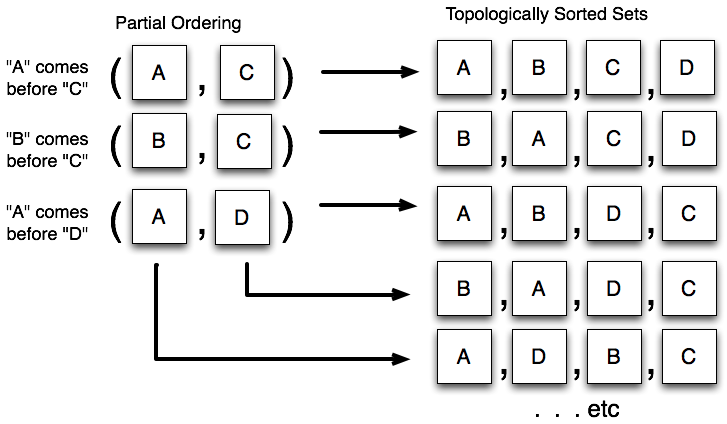
Figure 20.14: Topological sort
图 20.14:拓扑排序
The unit of work constructs a partial ordering based on those persistence commands which must precede others. The commands are then topologically sorted and invoked in order. The determination of which commands precede which is derived primarily from the presence of a relationship that bridges two Mapper objects---generally, one Mapper is considered to be dependent on the other, as the relationship implies that one Mapper has a foreign key dependency on the other. Similar rules exist for many-to-many association tables, but here we focus on the case of one-to-many/many-to-one relationships. Foreign key dependencies are resolved in order to prevent constraint violations from occurring, with no reliance on needing to mark constraints as "deferred". But just as importantly, the ordering allows primary key identifiers, which on many platforms are only generated when an INSERT actually occurs, to be populated from a just-executed INSERT statement's result into the parameter list of a dependent row that's about to be inserted. For deletes, the same ordering is used in reverse---dependent rows are deleted before those on which they depend, as these rows cannot be present without the referent of their foreign key being present.
工作单元根据必须先执行的其他持久化命令构建一个部分排序。然后对这些命令进行拓扑排序并按顺序调用。确定哪些命令先于哪些命令主要来源于存在一个连接两个 Mapper 对象的 relationship ------通常,一个 Mapper 被认为依赖于另一个 Mapper ,因为 relationship 表明一个 Mapper 对另一个 Mapper 有外键依赖。对于多对多关联表也存在类似的规则,但这里我们关注的是一对多/多对一关系。为了防止约束违规,外键依赖按顺序解决,无需标记约束为"延迟"。但同样重要的是,这种排序允许主键标识符------在许多平台上只有在实际发生 INSERT 时才会生成------能够从刚刚执行的 INSERT 语句的结果中填充到即将插入的依赖行的参数列表中。 对于删除操作,使用相反的顺序------依赖的行先删除,然后删除它们所依赖的行,因为这些行在没有其外键参照存在的情况下不可能存在。
The unit of work features a system where the topological sort is performed at two different levels, based on the structure of dependencies present. The first level organizes persistence steps into buckets based on the dependencies between mappers, that is, full "buckets" of objects corresponding to a particular class. The second level breaks up zero or more of these "buckets" into smaller batches, to handle the case of reference cycles or self-referring tables. Figure 20.15 illustrates the "buckets" generated to insert a set of User objects, then a set of Address objects, where an intermediary step copies newly generated User primary key values into the user_id foreign key column of each Address object.
工作单元的特点是一个系统,该系统根据现有依赖结构在两个不同级别执行拓扑排序。第一级根据映射器之间的依赖关系将持久化步骤组织成桶,即对应特定类的对象"完整桶"。第二级将零个或多个这些"桶"拆分成更小的批次,以处理引用循环或自引用表的情况。图 20.15 说明了为插入一组 User 对象,然后插入一组 Address 对象生成的"桶",其中中间步骤将新生成的 User 主键值复制到每个 Address 对象的 user_id 外键列。
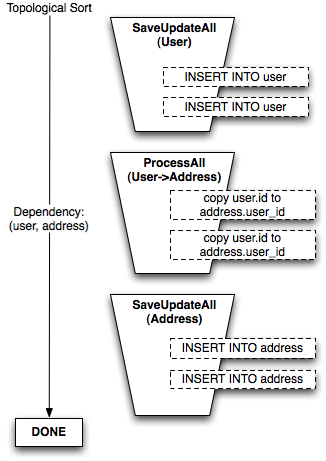
Figure 20.15: Organizing objects by mapper
图 20.15:按映射器组织对象
In the per-mapper sorting situation, any number of User and Address objects can be flushed with no impact on the complexity of steps or how many "dependencies" must be considered.
在按映射器排序的情况下,任意数量的 User 和 Address 对象都可以被刷新,而不会影响步骤的复杂性或需要考虑的"依赖"数量。
The second level of sorting organizes persistence steps based on direct dependencies between individual objects within the scope of a single mapper. The simplest example of when this occurs is a table which contains a foreign key constraint to itself; a particular row in the table needs to be inserted before another row in the same table which refers to it. Another is when a series of tables have a reference cycle : table A references table B, which references table C, that then references table A. Some A objects must be inserted before others so as to allow the B and C objects to also be inserted. The table that refers to itself is a special case of reference cycle.
第二级排序根据单个映射范围内对象之间的直接依赖关系来组织持久化步骤。这种情况最简单的例子是包含指向自身的外键约束的表;表中的某一行需要先插入,才能插入同一表中引用它的另一行。另一个例子是当一系列表存在引用循环时:表 A 引用表 B,表 B 引用表 C,而表 C 又引用表 A。某些 A 对象必须先插入,以便 B 和 C 对象也能被插入。引用自身的表是引用循环的一种特殊情况。
To determine which operations can remain in their aggregated, per-Mapper buckets, and which will be broken into a larger set of per-object commands, a cycle detection algorithm is applied to the set of dependencies that exist between mappers, using a modified version of a cycle detection algorithm found on Guido Van Rossum's blog. Those buckets involved in cycles are are then broken up into per-object operations and mixed into the collection of per-mapper buckets through the addition of new dependency rules from the per-object buckets back to the per-mapper buckets. Figure 20.16 illustrates the bucket of User objects being broken up into individual per-object commands, resulting from the addition of a new relationship from User to itself called contact.
为了确定哪些操作可以保留在它们的聚合、每个 Mapper 桶中,哪些将被拆分为更大的一组每个对象的命令,我们应用了一种循环检测算法到映射器之间存在的依赖关系集合上,该算法是 Guido Van Rossum 博客上找到的循环检测算法的修改版本。然后,那些涉及循环的桶被拆分为每个对象的操作,并通过从每个对象的桶向每个映射器的桶添加新的依赖规则,与每个映射器的桶集合混合。图 20.16 说明了 User 对象的桶被拆分为单个每个对象的命令,这是由于从 User 到它自己的新 relationship (称为 contact )的添加所导致的。
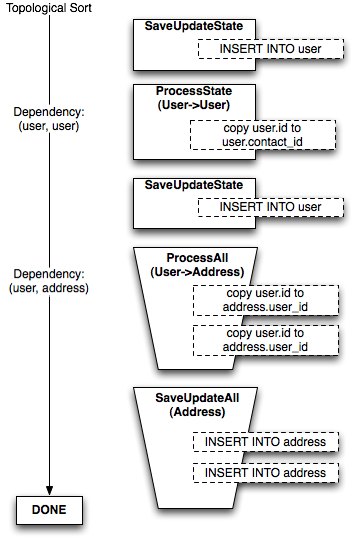
Figure 20.16: Organizing reference cycles into individual steps
图 20.16:将引用循环组织为单独的步骤
The rationale behind the bucket structure is that it allows batching of common statements as much as possible, both reducing the number of steps required in Python and making possible more efficient interactions with the DBAPI, which can sometimes execute thousands of statements within a single Python method call. Only when a reference cycle exists between mappers does the more expensive per-object-dependency pattern kick in, and even then it only occurs for those portions of the object graph which require it.
桶结构的原理在于它尽可能允许批量处理常见语句,这既减少了 Python 中所需的步骤数量,又使得与 DBAPI 的交互更加高效,DBAPI 有时可以在单个 Python 方法调用中执行数千条语句。只有当映射器之间存在引用循环时,更昂贵的每个对象依赖模式才会启动,即便如此,它也仅发生在对象图中需要它的部分。
20.10. Conclusion 20.10. 结论
SQLAlchemy has aimed very high since its inception, with the goal of being the most feature-rich and versatile database product possible. It has done so while maintaining its focus on relational databases, recognizing that supporting the usefulness of relational databases in a deep and comprehensive way is a major undertaking; and even now, the scope of the undertaking continues to reveal itself as larger than previously perceived.
SQLAlchemy 自诞生之初就设定了极高的目标,目标是成为功能最丰富、最通用的数据库产品。它做到了这一点,同时仍然专注于关系型数据库,认识到以深入而全面的方式支持关系型数据库的有效性是一项重大任务;甚至到现在,这项任务的范围仍然显示出比之前预想的要更大。
The component-based approach is intended to extract the most value possible from each area of functionality, providing many different units that applications can use alone or in combination. This system has been challenging to create, maintain, and deliver.
基于组件的方法旨在从每个功能领域提取最大价值,提供许多不同的单元供应用程序单独或组合使用。这个系统在创建、维护和交付方面都极具挑战性。
The development course was intended to be slow, based on the theory that a methodical, broad-based construction of solid functionality is ultimately more valuable than fast delivery of features without foundation. It has taken a long time for SQLAlchemy to construct a consistent and well-documented user story, but throughout the process, the underlying architecture was always a step ahead, leading in some cases to the "time machine" effect where features can be added almost before users request them.
开发过程原本计划缓慢,基于这样一种理论:系统性地构建坚实功能最终比快速交付缺乏基础的功能更有价值。SQLAlchemy 花费了很长时间来构建一个一致且文档完善的用户故事,但在整个过程中,底层架构始终领先一步,在某些情况下导致出现"时间机器"效应,即在用户请求之前几乎就能添加新功能。
The Python language has been a reliable host (if a little finicky, particularly in the area of performance). The language's consistency and tremendously open run-time model has allowed SQLAlchemy to provide a nicer experience than that offered by similar products written in other languages.
Python 语言是一个可靠的宿主(尽管有点挑剔,尤其是在性能方面)。该语言的统一性和极其开放的运行时模型,使 SQLAlchemy 能够提供比其他语言编写的类似产品更佳的使用体验。
It is the hope of the SQLAlchemy project that Python gain ever-deeper acceptance into as wide a variety of fields and industries as possible, and that the use of relational databases remains vibrant and progressive. The goal of SQLAlchemy is to demonstrate that relational databases, Python, and well-considered object models are all very much worthwhile development tools.
SQLAlchemy 项目希望 Python 能够尽可能深入到各种领域和行业中,并且关系型数据库的使用保持充满活力和进步。SQLAlchemy 的目标是证明关系型数据库、Python 以及经过深思熟虑的对象模型都是非常值得使用的开发工具。