前言
这是 最近有一个 来自于朋友的 pyflink 的使用需求
然后 看到了 很多 pyflink 这边的和 使用 java, scala 的 api 使用上的很多差异
这里使用的 pyflink 版本是 1.16.3
pyflink 1.16.3 中批处理相关貌似要使用 Table API 来进行处理, datastreaming api 使用多多少少存在问题
但是 这个如果是在 java, scala 中写一段 批处理的脚本就简单的多了
pyflink 1.16.3 这里, 要使用 Table API 进行处理
pyflink 1.16.3 使用 Table API 进行批处理
这里整体的过程, 也是 构建 Source, Transformation, Sink 然后进行执行
flink-sql 会转换为 flink job 进行业务处理, sql 中就包含了 转换的处理
from pyflink.table import EnvironmentSettings, TableEnvironment
settings = EnvironmentSettings.new_instance().in_batch_mode().build()
t_env = TableEnvironment.create(settings)
t_env.get_config().set("parallelism.default", "1")
t_env.execute_sql("""
CREATE TABLE mySource (
country STRING,
year_field STRING,
sex STRING
) WITH (
'connector' = 'filesystem',
'format' = 'csv',
'path' = '/Users/jerry/Tmp/17_pyspark_csv/suicide_clear_3fields.csv'
)
""")
t_env.execute_sql("""
CREATE TABLE mySink (
updated_country STRING,
updated_year STRING,
counter BIGINT
) WITH (
'connector' = 'filesystem',
'format' = 'csv',
'path' = '/Users/jerry/Tmp/17_pyspark_csv/output_by_flink_sql'
)
""")
t_env.execute_sql("""
INSERT INTO mySink
SELECT country as updated_country, year_field AS updated_year, count(*) as counter
FROM mySource
WHERE year_field = '1987'
group by country, year_field
""").wait()最终执行结果如下, 实现了 数据的批处理
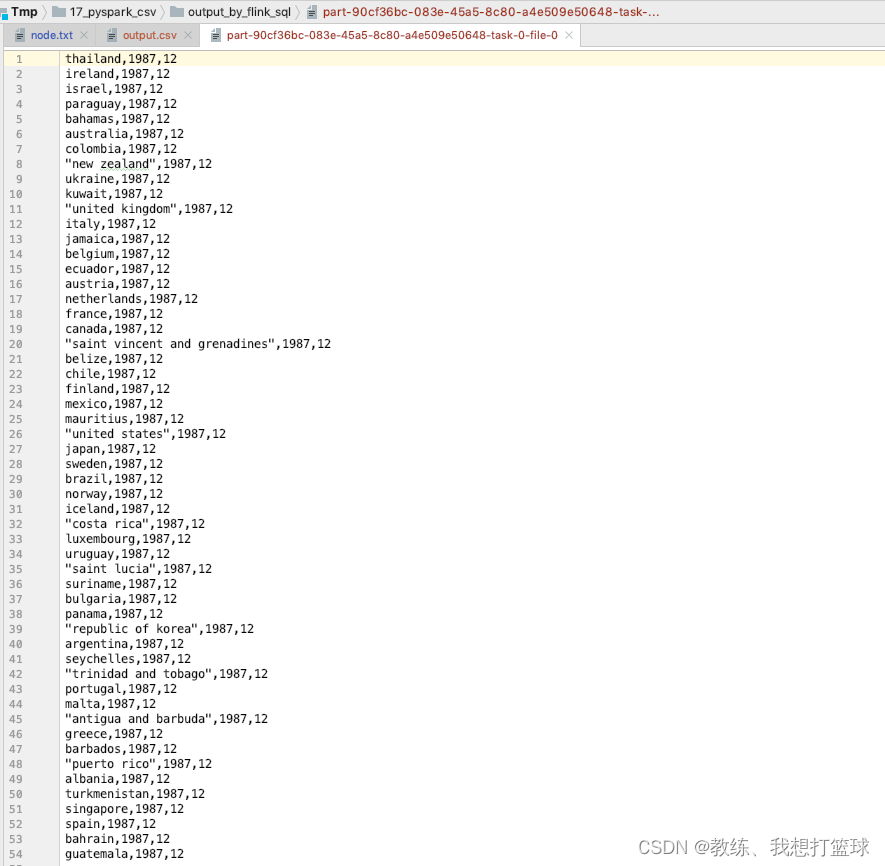
使用 scala 来进行数据的批处理
可以使用大量 api, 不仅仅局限于 sql, 处理方式上面 更加抽象, 灵活一些
可能是 程序员更加偏爱的处理方式, flink-sql 稍微简单一些, 处理的场景 也有一些局限
package com.hx.test
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.configuration.Configuration
/**
* Test01WordCount
*
* @author Jerry.X.He <970655147@qq.com>
* @version 1.0
* @date 2021-04-02 18:07
*/
object Test04ReadCsvThenGroup {
def main(args: Array[String]): Unit = {
// 创建一个批处理的执行环境
val conf = new Configuration()
conf.setString("taskmanager.numberOfTaskSlots", "3")
conf.setString("rest.bind-port", "8081")
conf.setString("parallelism.default", "1")
val env = ExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 从文件中读取数据
val inputPath = "/Users/jerry/Tmp/17_pyspark_csv/suicide_clear.csv"
val inputDs = env.readTextFile(inputPath)
val result = inputDs
.filter(line => !line.contains("year,"))
.map(line => {
val splits = line.split("\\s*,\\s*")
Person(splits(0), Integer.parseInt(splits(1)), splits(2), 1)
}
)
.filter(person => {
person.year == 1987
})
.map(person => {
(person.country, person)
})
.groupBy(0)
.reduce((v1, v2) => {
v1._2.count = v1._2.count + v2._2.count
v1
})
.map(tuple => tuple._2)
// 打印输出
result.print()
System.in.read()
}
case class Person(country: String, year: Int, sex: String, var count: Int) {
}
}输出结果如下
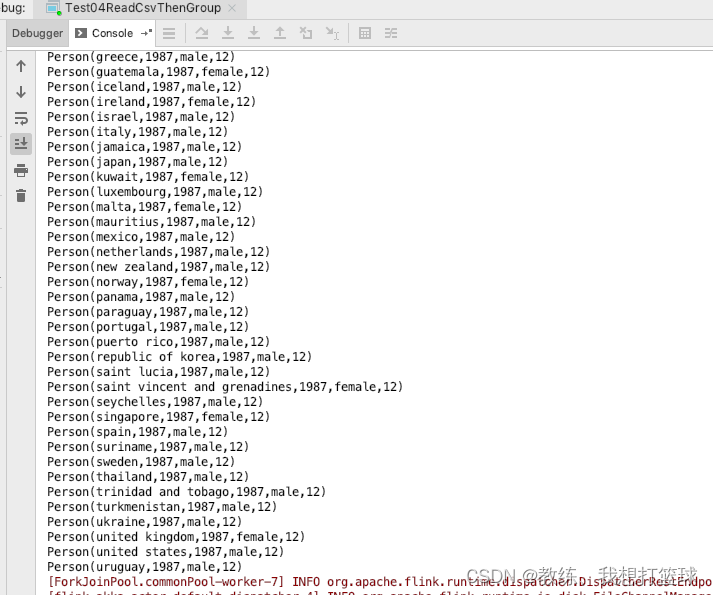
完