文章目录
一、读题

题目的意思很简单,就是求两个数组的交集,和求链表的共同数据基本相同
二、思路
思路很简单,遍历两个数组,将相同的数据取出来即可,可以通过hash表来实现,遍历第一个数组的时候将每个数都加入到hash表当中,在遍历第二个数组的时候就进行判断,如果这个数据已经在hash表当中存在,那么说明这个数据是交集数据,那么就直接添加到ArrayList当中
实现细节
这道题有坑,如果只是单独的进行判断是否存在而不做其他处理的话,会导致结果错误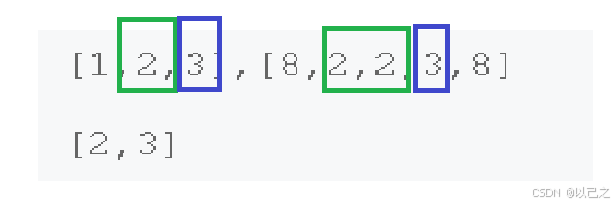
仔细分析,假设先遍历第一个数组,那么1 2 3会被添加到hash表,没有问题,问题出现在遍历第二个数组,当遍历到第一个2 的时候,我们发现hash表当中已经存在2了,那么说明2是公共数据添加到ArrayLiist,再往后遍历发现还是2,这个时候又将2添加到ArrayLiist当中,这个时候问题就呈现出来了,ArrayLiist里面会出现重复的数据,这是不对的
解决办法也很简单,当我们添加一个元素进入ArrayLiist的时候,我们就将该元素从hash表当中删除,这样就再也不会判断到该元素了
实现细节
有一个优化的空间,我们可以不使用hash表进行判断数据是否存在,我们可以创建一个boolean类型的数组,遍历数据的时候就将对应数组下标设置为true,表示当前下标的数据出现了,这样子可以节省hash表的导入时间以及hash值得计算,对于小范围数据,使用数组模拟哈希表确实比创建HashMap更高效,booolean类型的数组的范围可以用数据的最大值+10,只要大于数据的最大值即可
三、代码实现:
sql
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param nums1 int整型ArrayList
* @param nums2 int整型ArrayList
* @return int整型ArrayList
*/
public ArrayList<Integer> intersection (ArrayList<Integer> nums1, ArrayList<Integer> nums2) {
//通过hash表来进行判断是否重复出现某个数据 ,对于小范围数据,使用数组模拟哈希表确实比创建HashMap更高效,因此可以通过一个boolean类型的数组模拟hash表
//boolean默认是false
boolean[] ans = new boolean[1000 + 10];
ArrayList<Integer> list = new ArrayList<>();
for(Integer i : nums1) {
ans[i] = true;
}
for(Integer i : nums2) {
if(ans[i]) {
list.add(i);
ans[i] = false;
}
}
return list;
}
}各位佬,如果有什么更加高效的算法欢迎评论区讨论,指导一下主包进步,大家一起共勉