在日常开发和数据结构学习中,哈希表是当之无愧的高效数据结构 ,其增删查改的时间复杂度能达到 O (1) 级别,也是 STL 中unordered_map/unordered_set的底层实现。今天这篇文章就从哈希表与红黑树的对比入手,一步步拆解哈希表的核心概念,最后手把手实现一个简易的哈希表,保证新手也能看懂!
一、先搞懂:哈希表 VS 红黑树(STL 容器对比)
STL 中map/set底层是红黑树,unordered_map/unordered_set(下文简称 uset/umap)底层是哈希表,二者接口相似但特性差异巨大,用一张表就能看明白核心区别:
| 对比维度 | 红黑树(set/map) | 哈希表(uset/umap) |
|---|---|---|
| 遍历顺序 | 中序遍历,有序 | 无序(贴合 unordered 命名) |
| key 要求 | 支持比较大小(<) | 支持转整形 + 等于比较(==) |
| 迭代器类型 | 双向迭代器 | 单向迭代器 |
| 时间复杂度 | 增删查改 O (logn) | 增删查改 O (1)(理想情况) |
| 底层原理 | 平衡二叉搜索树 | 数组 + 链表(链地址法) |
简单来说,如果需要有序遍历,选红黑树实现的 set/map;如果追求极致的查询和插入效率,选哈希表实现的 uset/umap。
二、哈希表核心概念,一次性讲透
想要实现哈希表,先搞懂这几个核心概念,它们是哈希表的基础。
2.1 直接定址法
这是最基础的哈希映射方式,用关键字直接计算存储位置 ,适合关键字范围高度集中的场景。
- 例 1:关键字在 0,99,直接开一个 100 长度的数组,关键字值就是数组下标;
- 例 2:关键字是小写字母 a,z,用
字母ASCII码 - 'a'的ASCII码作为数组下标。
直接定址法简单高效,但缺点也很致命:如果关键字范围分散(比如 0,9999 只存 100 个值),会极度浪费内存,这时候就需要更灵活的哈希函数。
2.2 哈希冲突(哈希碰撞)
当我们把大范围的关键字映射到小范围的数组空间时,两个不同的关键字可能被映射到同一个数组位置 ,这种情况就是哈希冲突。
比如数组大小 M=200,哈希函数是h(key)=key%M,那么3%200=3,203%200=3,3 和 203 就发生了哈希冲突。
理想情况是设计完美的哈希函数避免冲突,但实际开发中冲突无法避免,我们能做的只有两点:
- 设计优秀的哈希函数,减少冲突次数;
- 设计合理的冲突解决方案,妥善处理冲突。
2.3 负载因子
负载因子是哈希表的核心性能指标 ,计算公式:负载因子 (load factor) = 哈希表中存储的元素个数 N / 哈希表的数组大小 M
负载因子的大小直接影响哈希冲突的概率:
- 负载因子越大:空间利用率越高,但哈希冲突概率也越高;
- 负载因子越小:哈希冲突概率越低,但空间利用率也越低。
STL 中对哈希表的负载因子做了严格控制:最大负载因子为 1,当负载因子大于 1 时,哈希表会触发扩容,以此保证查询效率。
2.4 关键字转整数
哈希函数的计算通常基于整数 ,如果关键字是浮点数、字符串等非整数类型,需要先将其转换为整形,再进行哈希映射。这一步是实现哈希表的关键细节,后面会用代码具体实现。
三、哈希函数怎么设计?重点看除留余数法
哈希函数的核心目标:让关键字尽可能均匀地散列到哈希表的数组空间中 ,最常用、最易实现的就是除留余数法(除法散列法)。
3.1 除留余数法核心公式
假设哈希表的数组大小为 M,关键字转换后的整数为 key,那么哈希函数为:h(key) = key % M
计算出的结果就是关键字在哈希表中的数组下标,结果范围天然在 [0,M) 之间,符合数组下标要求。
3.2 关键细节:M 的选择
M 的取值直接决定哈希冲突的概率,绝对不要选 2 的幂、10 的幂作为 M!
- 若 M 是 2 的幂,
key%M等价于取 key 的二进制后 X 位,后 X 位相同的 key 都会冲突; - 若 M 是 10 的幂,
key%M等价于取 key 的十进制后 X 位,后 X 位相同的 key 都会冲突。
推荐方案 :M 取不太接近 2 的整数次幂的质数(素数),能让关键字的散列更均匀,大幅降低冲突概率。
3.3 实战优化:Java/STL 的哈希函数
实际开发中不会单纯用取模,会做额外优化让散列更均匀:
- Java HashMap:M 取 2 的幂,通过
key >>> 16让 key 的高 16 位和低 16 位异或,让所有位都参与计算; - STL:直接将 M 设为质数,通过质数取模实现散列。
四、哈希冲突怎么解决?重点讲链地址法
解决哈希冲突的方法有开放地址法、链地址法等,链地址法是工业界最常用的方案(STL、Java HashMap 均采用),开放地址法因逻辑杂乱、负载因子必须小于 1 等缺点,实际使用较少。
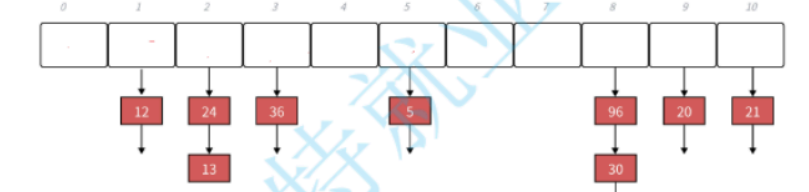
4.1 链地址法核心原理
哈希表的底层结构是数组 + 链表:
- 数组被称为哈希桶,每个桶对应一个数组下标,存储一个链表的头节点;
- 当发生哈希冲突时,将冲突的元素挂在对应桶的链表尾部 / 头部(STL 用头插法,效率更高);
- 查找元素时,先通过哈希函数找到对应桶,再遍历桶的链表比对关键字。
4.2 链地址法的优势
- 负载因子无严格限制,可以大于 1(链表可以无限挂节点,只是效率会下降);
- 实现简单,增删元素只需操作链表,无需移动其他元素;
- 不易产生堆积,冲突处理效率高。
4.3 极端场景处理
如果某个哈希桶的链表过长,会导致该桶的查询效率降到 O (n),解决方案:
- 扩容:通过增大哈希表的数组大小,重新散列元素,拆分长链表;
- 红黑树优化:Java8 中规定,当桶的链表长度超过 8 时,自动将链表转为红黑树,查询效率回到 O (logn);
- 全域散列法:让哈希函数随机化,避免被恶意构造的关键字针对。
示意图提示 :此处可插入链地址法哈希表结构示意图,展示哈希桶数组 + 链表的组合形式,标注出冲突元素的挂载方式。
五、手撕哈希表!从 0 到 1 实现(C++ 版)
接下来我们用 C++ 实现一个简易的哈希表(仿 STL 实现),采用链地址法,支持增删查改、自动扩容等核心功能,代码注释详细,直接可运行。
5.1 整体设计思路
- 底层结构:
vector作为哈希桶数组,每个桶存储链表头节点; - 节点设计:哈希节点存储键值对 和下一个节点的指针;
- 哈希函数:通过仿函数实现,支持 int、string 等常见类型,自动将关键字转整形;
- 质数表:预定义质数数组,哈希桶的大小始终为质数,保证散列均匀;
- 核心操作:插入(头插法)、查找、删除、自动扩容(负载因子 > 1 时触发)。
5.2 步骤 1:设计哈希节点
哈希节点存储键值对和链表指针,用模板实现泛型支持:
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
// 哈希节点模板类
template<class K, class V>
struct HashNode {
pair<K, V> _kv; // 存储键值对
HashNode<K, V>* _next; // 链表后继指针
// 构造函数
HashNode(const pair<K, V>& kv)
: _kv(kv)
, _next(nullptr)
{}
};5.3 步骤 2:实现哈希函数仿函数
仿函数的作用是将关键字转为整形 ,通过模板特化 支持不同类型(int、string 是重点),这里 string 的哈希采用BKDR 哈希算法(工业界常用,散列均匀)。
// 哈希函数仿函数基类(处理int类型)
template<class K>
struct HashFunc {
size_t operator()(const K& key) const {
return (size_t)key; // 直接将int转为size_t
}
};
// 模板特化:处理string类型(BKDR哈希算法)
template<>
struct HashFunc<string> {
size_t operator()(const string& s) const {
size_t hash = 0;
for (char ch : s) {
hash = hash * 131 + ch; // 131是魔法数,散列效果好
}
return hash;
}
};5.4 步骤 3:实现质数表和获取下一个质数的函数
仿 STL 实现,预定义 28 个质数,通过_stl_next_prime函数获取大于等于指定值的第一个质数,保证哈希桶大小始终为质数:
// 获取大于等于n的第一个质数
inline unsigned long _stl_next_prime(unsigned long n) {
// 预定义质数表,远离2的幂,散列效果好
static const int _stl_num_primes = 28;
static const unsigned long _stl_prime_list[_stl_num_primes] = {
53,97,193,389,769, 1543,3079,6151,12289, 24593,
49157,98317,196613,393241, 786433, 1572869,
3145739,6291469,12582917,25165843, 50331653,
100663319,201326611,402653189,805306457,
1610612741,3221225473,4294967291
};
// 用lower_bound找到第一个>=n的质数
const unsigned long* first = _stl_prime_list;
const unsigned long* last = _stl_prime_list + _stl_num_primes;
const unsigned long* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}示意图提示 :此处可插入STL 质数表分布示意图,展示质数随数值增长的规律,说明为何选这些质数。
5.5 步骤 4:实现哈希表主类(核心)
哈希表主类包含哈希桶数组、元素个数、哈希函数等成员,实现插入、查找、删除、扩容 四大核心功能,重点注意头插法 和扩容时的重新散列。
// 哈希表模板类
// K:键类型,V:值类型,Hash:哈希函数仿函数
template<class K, class V, class Hash = HashFunc<K>>
class HashTable {
typedef HashNode<K, V> Node; // 重定义哈希节点,简化代码
public:
// 构造函数:初始化哈希桶为第一个质数,元素个数为0
HashTable()
: _n(0)
{
_tables.resize(_stl_next_prime(0));
}
// 析构函数:释放所有节点内存
~HashTable() {
for (size_t i = 0; i < _tables.size(); ++i) {
Node* cur = _tables[i];
while (cur) {
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
// 核心1:插入键值对(不允许重复key)
bool Insert(const pair<K, V>& kv) {
// 1. 检查key是否已存在,存在则返回false
if (Find(kv.first)) {
return false;
}
// 2. 检查负载因子,>1则扩容
if (_n >= _tables.size()) {
Expand();
}
// 3. 计算哈希地址
Hash hash;
size_t hashi = hash(kv.first) % _tables.size();
// 4. 头插法插入节点(效率高,无需遍历链表)
Node* newnode = new Node(kv);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
// 5. 元素个数+1
_n++;
return true;
}
// 核心2:查找关键字,返回节点指针(nullptr表示不存在)
Node* Find(const K& key) {
// 1. 计算哈希地址
Hash hash;
size_t hashi = hash(key) % _tables.size();
// 2. 遍历对应桶的链表
Node* cur = _tables[hashi];
while (cur) {
if (cur->_kv.first == key) {
return cur; // 找到返回节点
}
cur = cur->_next;
}
return nullptr; // 没找到返回nullptr
}
// 核心3:删除关键字,成功返回true,失败返回false
bool Erase(const K& key) {
// 1. 计算哈希地址
Hash hash;
size_t hashi = hash(key) % _tables.size();
// 2. 遍历链表,找到待删除节点(记录前驱)
Node* prev = nullptr;
Node* cur = _tables[hashi];
while (cur) {
if (cur->_kv.first == key) {
// 3. 删除节点:头节点/中间节点
if (prev == nullptr) {
_tables[hashi] = cur->_next; // 头节点
} else {
prev->_next = cur->_next; // 中间节点
}
delete cur;
_n--; // 元素个数-1
return true;
}
prev = cur;
cur = cur->_next;
}
return false; // 没找到节点
}
// 打印哈希表(用于测试,查看每个桶的链表)
void Print() {
for (size_t i = 0; i < _tables.size(); ++i) {
cout << "桶" << i << ":";
Node* cur = _tables[i];
while (cur) {
cout << "[" << cur->_kv.first << ":" << cur->_kv.second << "] -> ";
cur = cur->_next;
}
cout << "nullptr" << endl;
}
cout << "当前元素个数:" << _n << endl;
}
private:
// 核心4:扩容函数(重新散列所有元素)
void Expand() {
// 1. 创建新的哈希桶,大小为下一个质数
vector<Node*> newTable;
newTable.resize(_stl_next_prime(_tables.size()));
// 2. 遍历旧桶,将所有节点重新散列到新桶
Hash hash;
for (size_t i = 0; i < _tables.size(); ++i) {
Node* cur = _tables[i];
while (cur) {
Node* next = cur->_next; // 保存后继,防止断链
// 计算新的哈希地址
size_t hashi = hash(cur->_kv.first) % newTable.size();
// 头插法插入新桶
cur->_next = newTable[hashi];
newTable[hashi] = cur;
// 遍历下一个节点
cur = next;
}
_tables[i] = nullptr; // 旧桶置空
}
// 3. 交换新旧桶(现代写法,效率高)
_tables.swap(newTable);
}
private:
vector<Node*> _tables; // 哈希桶数组(存储链表头节点)
size_t _n; // 哈希表中元素的个数
};5.6 步骤 5:测试哈希表
编写测试代码,验证 int、string 类型的增删查改和自动扩容功能:
// 测试int类型key
void TestIntHashTable() {
HashTable<int, int> ht;
ht.Insert({1, 10});
ht.Insert({2, 20});
ht.Insert({203, 2030}); // 203%53=203-3*53=44,1%53=1,2%53=2
ht.Insert({53, 530}); // 53%53=0
ht.Insert({106, 1060}); // 106%53=0,和53冲突
cout << "=====int类型哈希表=====" << endl;
ht.Print();
// 查找
HashNode<int, int>* node = ht.Find(203);
if (node) {
cout << "找到203:" << node->_kv.second << endl;
}
// 删除
ht.Erase(53);
cout << "=====删除53后=====" << endl;
ht.Print();
}
// 测试string类型key
void TestStringHashTable() {
HashTable<string, string> ht;
ht.Insert({"apple", "苹果"});
ht.Insert({"banana", "香蕉"});
ht.Insert({"orange", "橙子"});
ht.Insert({"pear", "梨"});
cout << "\n=====string类型哈希表=====" << endl;
ht.Print();
// 查找
HashNode<string, string>* node = ht.Find("banana");
if (node) {
cout << "找到banana:" << node->_kv.second << endl;
}
}
int main() {
TestIntHashTable();
TestStringHashTable();
return 0;
}5.7 运行结果说明
运行代码后,能看到:
- 冲突的元素(如 53 和 106)会被挂在同一个哈希桶的链表中;
- 删除元素后,对应桶的链表会被更新,元素个数减少;
- string 类型的关键字会通过 BKDR 算法正确计算哈希地址,无乱码。
示意图提示 :此处可插入哈希表扩容前后对比示意图,展示旧桶元素重新散列到新桶的过程。
六、哈希表的性能与实际应用
6.1 性能总结
- 理想情况:增删查改 O (1),这是哈希表的最大优势;
- 最坏情况:所有元素都冲突,哈希表退化为链表,时间复杂度 O (n)(可通过扩容、红黑树优化避免);
- 实际情况:通过合理的负载因子控制(如 STL 的 1)和质数哈希桶,哈希表的效率无限接近 O (1)。
6.2 实际应用场景
哈希表是工业界最常用的数据结构之一,常见场景:
- 缓存系统(如 Redis 的底层核心是哈希表);
- 数据库的索引设计;
- STL 中的
unordered_map/unordered_set; - 字符串匹配、词频统计;
- 分布式系统中的一致性哈希。
七、总结
哈希表的核心是 **"空间换时间"**,通过哈希函数将关键字映射到哈希桶,用链地址法处理冲突,最终实现高效的增删查改。本文的重点总结:
- 哈希表与红黑树的核心差异是无序 + O (1) 效率,适合无需有序的高效查询场景;
- 除留余数法是最常用的哈希函数,哈希桶大小必须选质数;
- 链地址法是工业界主流的冲突解决方案,底层是数组 + 链表;
- 负载因子是哈希表的核心指标,STL 中控制为 1,大于 1 则扩容;
- 实现哈希表的关键是关键字转整数 和扩容时的重新散列。
本次实现的哈希表是简易版,STL 中的unordered_map还做了更多优化(如迭代器封装、emplace 插入、桶的遍历等),但核心原理完全一致,掌握了本文的内容,就能轻松看懂 STL 哈希表的底层源码啦!
拓展思考 :可以尝试在本文基础上实现哈希表的迭代器 ,或者添加红黑树优化(链表长度超过 8 时转红黑树),让哈希表的性能更上一层楼。