文章目录

一、题目描述
题目链接:力扣 703. 数据流中的第 K 大元素
题目描述:
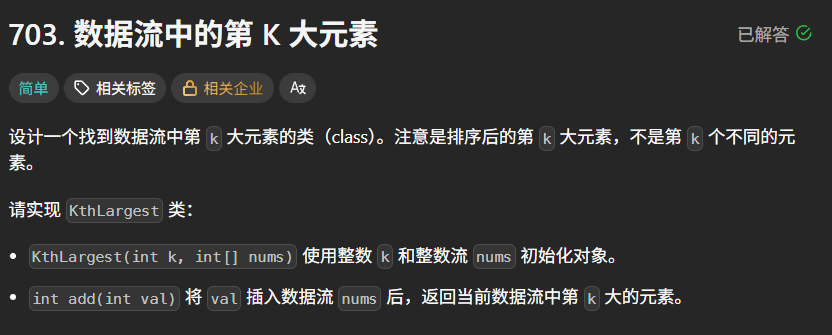
示例 1:
输入:
"KthLargest", "add", "add", "add", "add", "add"
\[3, \[4, 5, 8, 2\]\], \[3\], \[5\], \[10\], \[9\], \[4\]
输出:
null, 4, 5, 5, 8, 8
解释:
KthLargest kthLargest = new KthLargest(3, 4,5,8,2);
kthLargest.add(3); // 返回 4
kthLargest.add(5); // 返回 5
kthLargest.add(10); // 返回 5
kthLargest.add(9); // 返回 8
kthLargest.add(4); // 返回 8
提示:1 <= k <= 10⁴
0 <= nums.length <= 10⁴
-10⁴ <= numsi <= 10⁴
-10⁴ <= val <= 10⁴
最多调用 add 方法 10⁴ 次
题目数据保证,在查找第 k 大元素时,数据流中至少有 k 个元素
二、为什么这道题值得我们花几分钟弄懂?
这道题是堆(优先级队列)进阶应用的经典题,是面试中考察堆灵活使用的高频题。它和上一题"最后一块石头的重量"形成互补,从"大顶堆的基础使用"过渡到"小顶堆的场景化应用",能帮我们真正理解"根据场景选择堆类型"的核心思维,是夯实堆结构应用能力的关键题。
题目核心价值:
- 堆类型的灵活选择:本题需要"维护第k大元素",小顶堆是最优解,能让你理解"不同堆类型适配不同场景"的底层逻辑,而非只会机械使用大顶堆。
- 空间优化思维:用大小为k的小顶堆,将空间复杂度从O(n)优化到O(k),体现"用数据结构特性做空间优化"的工程思维。
- 数据流处理能力:本题模拟"动态数据流"场景(数据不断新增),是实际开发中日志分析、实时统计等场景的简化版,能训练你处理动态数据的能力。
- 面试的"进阶筛选题":相比基础堆题,本题更考察对堆的理解深度 而非使用熟练度,能区分"会用堆"和"懂堆的应用场景"的候选人。
面试考察的核心方向:
- 堆类型的选择逻辑:能否意识到"维护第k大元素"用小顶堆最优,而非暴力排序或大顶堆。
- 小顶堆的使用能力:能否熟练配置C++
priority_queue为小顶堆(指定比较器)。 - 空间优化思路:能否解释"为什么只用大小为k的小顶堆就能解决问题",而非存储所有元素。
- 复杂度分析:能否准确分析初始化和add操作的时间复杂度,理解小顶堆相比暴力排序的效率优势。
三、算法原理
小顶堆的核心特性
小顶堆是优先级队列的一种,其核心特性是堆顶元素是整个堆的最小值,且核心操作(插入、删除堆顶)的时间复杂度仍为O(logk)(k为堆的大小):
- 插入元素:O(logk)
- 删除堆顶元素:O(logk)
- 获取堆顶元素:O(1)
在C++中,标准库的priority_queue默认是大顶堆,要实现小顶堆需要显式指定比较器:
cpp
// 小顶堆的定义方式:三个模板参数分别是元素类型、底层容器、比较器
priority_queue<int, vector<int>, greater<int>> min_heap;这道题的核心算法是 "大小为k的小顶堆 + 动态维护":用小顶堆存储数据流中"当前最大的k个元素",堆顶就是这k个元素的最小值,也就是整个数据流的第k大元素。
- 初始化阶段 :
- 创建一个大小为k的小顶堆。
- 遍历初始数组
nums,将每个元素插入堆中。 - 若堆的大小超过k,删除堆顶元素(最小值),确保堆中始终只保留最大的k个元素。
- add操作阶段 :
- 将新元素
val插入堆中。 - 若堆的大小超过k,删除堆顶元素。
- 此时堆顶元素就是当前数据流的第k大元素,直接返回。
- 将新元素
这个思路的本质是:用小顶堆"过滤"掉数据流中较小的元素,只保留最大的k个,堆顶就是我们要找的第k大元素。
细节注意
- 堆类型选择:本题用的是小顶堆,若用大顶堆则需要存储所有元素,空间复杂度更高,且获取第k大元素需要弹出k次,效率更低。
- 堆大小控制:初始化和add操作中,必须在插入后检查堆大小,超过k就删除堆顶,这是保证堆顶是第k大元素的核心。
- 边界条件:
- 初始数组
nums为空时,堆初始为空,后续add操作会逐步填充到k个元素。 - 题目保证调用add时数据流至少有k个元素,无需处理堆大小不足k的情况。
- 初始数组
- 面试重点:能解释"为什么小顶堆+固定大小k"是最优解,而非只会写代码------这是面试中区分理解深度的关键。
四、代码实现
cpp
#include <vector>
#include <queue>
using namespace std;
class KthLargest {
public:
// 构造函数:初始化k和小顶堆
KthLargest(int k, vector<int>& nums)
{
_size = k; // 保存第k大的k值
// 遍历初始数组,填充小顶堆
for(auto e : nums)
{
_q.push(e); // 插入当前元素
// 若堆大小超过k,删除堆顶(最小值),保证堆中只保留最大的k个元素
if(_q.size() > _size)
_q.pop();
}
}
// 添加新元素,并返回当前第k大的元素
int add(int val)
{
_q.push(val); // 插入新元素
// 维护堆的大小为k
if(_q.size() > _size)
_q.pop();
// 堆顶就是第k大的元素
return _q.top();
}
private:
// 小顶堆:greater<int>指定比较器,堆顶为最小值
priority_queue<int, vector<int>, greater<int>> _q;
int _size; // 保存k值,代表要找的是第k大元素
};
/**
* Your KthLargest object will be instantiated and called as such:
* KthLargest* obj = new KthLargest(k, nums);
* int param_1 = obj->add(val);
*/代码细节说明
- 小顶堆定义 :
priority_queue<int, vector<int>, greater<int>> _q;是C++中小顶堆的标准定义方式:- 第一个参数:元素类型(int);
- 第二个参数:底层存储容器(vector);
- 第三个参数:比较器(greater 表示"大于",即小的元素优先级更高,形成小顶堆)。
- 构造函数逻辑 :
- 先保存k值到成员变量
_size,避免后续重复传参; - 遍历初始数组,逐个插入堆中,同时保证堆大小不超过k,核心目的是"筛选出初始数组中最大的k个元素"。
- 先保存k值到成员变量
- add函数逻辑 :
- 插入新元素后,同样维护堆大小为k;
- 直接返回堆顶,因为此时堆顶是"当前最大的k个元素中的最小值",也就是整个数据流的第k大元素。
复杂度分析
- 初始化时间复杂度 :O(nlogk)。n是初始数组
nums的长度,每个元素插入堆的时间是O(logk)(堆大小最多为k),因此整体为O(nlogk)。 - add操作时间复杂度:O(logk)。每次add仅插入一个元素,堆操作的时间复杂度为O(logk)。
- 空间复杂度:O(k)。堆中最多存储k个元素,空间复杂度为O(k),相比存储所有元素的O(n)大幅优化。
五、下题预告
下一篇我们一起学习堆的综合应用,攻克 692. 前K个高频单词。这道题会在我们今天的堆(优先级队列)的基础上加入哈希表进行映射更加综合~
搞定这道题目,你真的真的很棒哦!如果对小顶堆的定义、堆大小维护的逻辑还有疑问,或者有更简洁的实现思路,都可以在评论区交流~
别忘了点个赞、关个注~(๑˃̵ᴗ˂̵)و 你的支持就是继续肝优质算法内容的最大动力~我们下道题,不见不散~
