简介
题外话:前一阵子一直在做 达梦 DSC 集群数据同步,踩了挺多坑,不过值得庆幸的是最终还是把这件事情搞定了。
达梦 DSC(Data Shared Cluster)是达梦官方提供的一种共享存储的数据库集群系统,支持高可用、高性能及负载均衡。
挑战 1:达梦共享集群归档日志分析
在达梦共享数据集群中,各个节点维护着自己的日志系统,在最开始,打算走老路子:

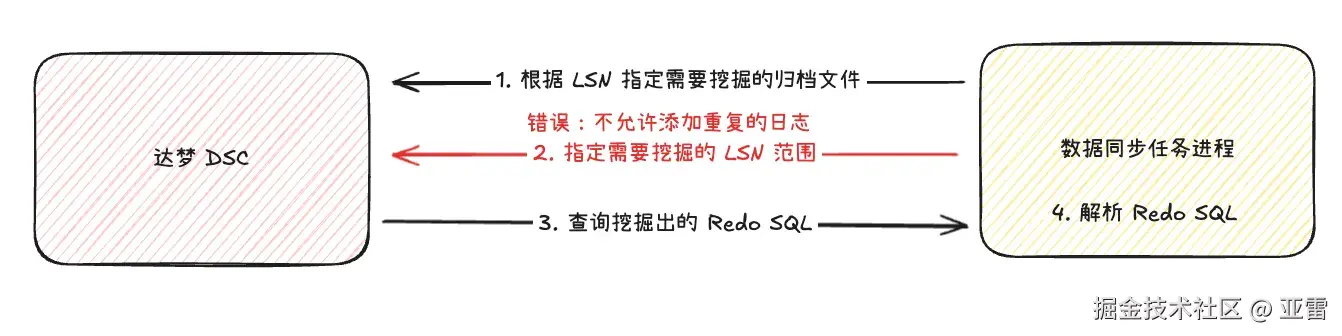
- 根据当前 LSN 指定需要挖掘的归档日志。
- 指定需要挖掘的 LSN 范围。
- 查询挖掘出来的 Redo SQL。
- 解析 Redo SQL 转换为增量数据。
在进行到第二步的时候,发现达梦直接报错了,提示"不允许添加重复的日志",实际上我并没有添加重复的日志。
重新翻阅达梦官方文档,最后发现,在达梦共享存储集群中,每个节点都有着自己的日志系统,但是达梦官方并没有提到该如何对达梦共享存储集群的日志挖掘。
我们沿着这个线索,进行了验证,发现根据节点编号分组后的日志可以分析,而且并不会报错之类的,于是乎,分析日志的步骤:
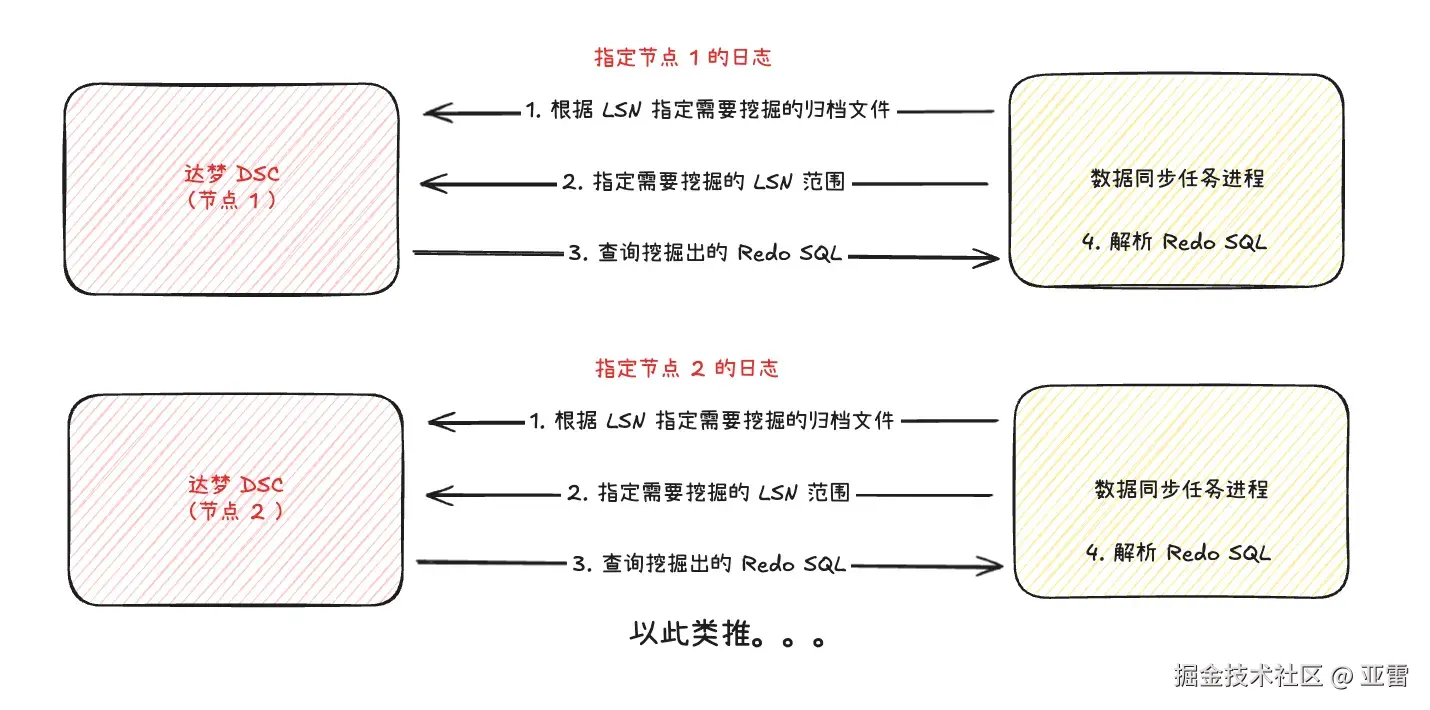
- 根据节点号以及当前 LSN 来指定所需要挖掘的归档日志。
- 指定需要挖掘的 LSN 范围。
- 查询挖掘出来的 Redo SQL。
- 解析 Redo SQL 转换为增量数据。
挑战 2:消费多实例日志数据乱序
解决归档日志分析之后,由于在消费不同节点的日志线程是隔离的,如果在多个节点操作同一张表的数据,会导致数据乱序的问题。
再次翻阅达梦文档,达梦文档有提到在故障重启的时候会根据事务提交的 LSN 排序,然后顺序消费排序之后的事务,我们延用达梦故障重启的思路,将多个实例上的事务号根据 LSN 进行排序,于是乎,分析日志的步骤:
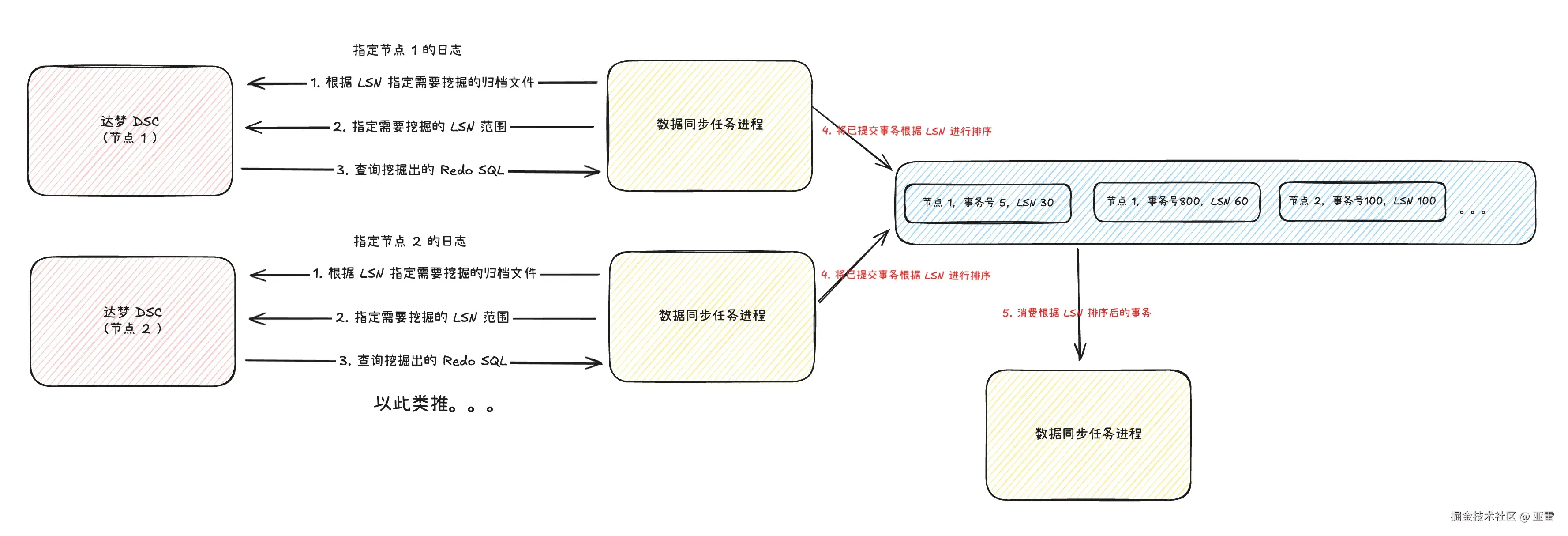
- 根据节点号以及当前 LSN 来指定所需要挖掘的归档日志。
- 指定需要挖掘的 LSN 范围。
- 查询挖掘出来的 Redo SQL。
- 将提交的事务号根据 LSN 号进行排序。
- 消费已排序完毕的事务的 Redo SQL 并转换为增量数据。
挑战 3:多节点 LSN 不连续
日志数据乱序的问题解决之后,又发现在达梦共享数据集群中 LSN 并不是连续的,对于集群中各个节点的 LSN 是连续的,这就可能会出现,节点 1 的 LSN 是 200 ,而节点 2 的 LSN 已经递增到 1000,这样就会导致任务的 LSN 始终无法递增,始终是节点 1 的 LSN。
翻阅达梦官方文档后,发现达梦 DSC 在不同实例操作不同数据页的时候,并不要求 LSN 连续,当不同节点操作了同一个数据页的时候,会触发一次全局 LSN 强同步。
根据文章中的内容,只能尝试去操作同一条数据,因为并不知道达梦在存储层干了些什么,按照下面这个步骤尝试验证了这段文章的内容:
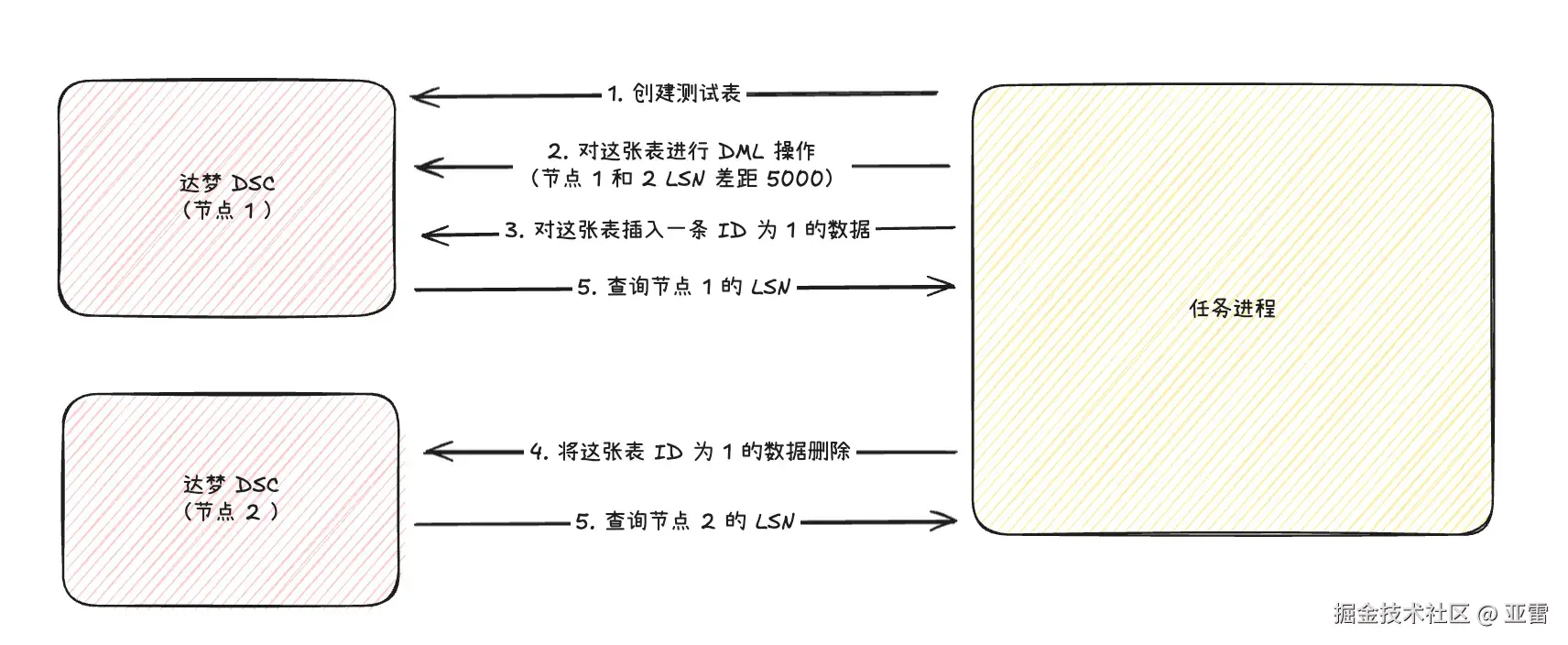
- 节点 1 创建一个表结构。
- 节点 1 进行一些操作(变更数据),使节点 1 和节点 2 的 LSN 差距 5000 以上。
- 节点 1 对这张表插入一条 ID 为 1 的数据。
- 节点 2 对这张表将 ID 为 1 的数据删除。
- 查询节点 1 和节点 2 的 LSN 。
经过这么一套操作下来,惊奇的发现节点 2 的 LSN 延续着节点 1 的 LSN 进行递增,这样就可以完全解决任务 LSN 无法递增的问题。