一、熟悉YOLO模型
模型下载网址:
https://github.com/ultralytics/assets/releases
从网址下载YOLOv8,YOLOv9,YOLOv11,YOLOv12最小的三个模型(n/s/m),放置到ultralytics-8.3.163文件夹下。后面将测试他们的效果。
在现在学习阶段,mytrian.py中的epochs(训练轮数)的值设置到能够让模型收敛就可以。正常情况下,设置为100就足够了;如果数据集简单的话,设置为20-30就可以。
训练设置技术文档:
https://docs.ultralytics.com/zh/modes/train/#train-settings
在mytrain.py中增加这两个选项,可以修改结果的保存位置。

(1)yolov8n.pt
修改mytrain.py文件,模型为yolov8n.pt:
python
from ultralytics import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
if __name__ == '__main__':
model = YOLO(r"yolov8n.pt") # 使用的模型
model.train(
data=r"bucket_cs.yaml",
epochs=100, # 训练轮数
imgsz=640, # 图片缩放尺寸
batch=-1, # 批次数(自动选择)
workers=1, # 同时打包数
cache="ram", # 使用内存
project="results", # 结果保存位置
name="yolov8n", # 结果保存文件夹名
)通过增加project和name选项可以将本次训练的结果保存到results\yolov8n文件夹下。
点击运行:
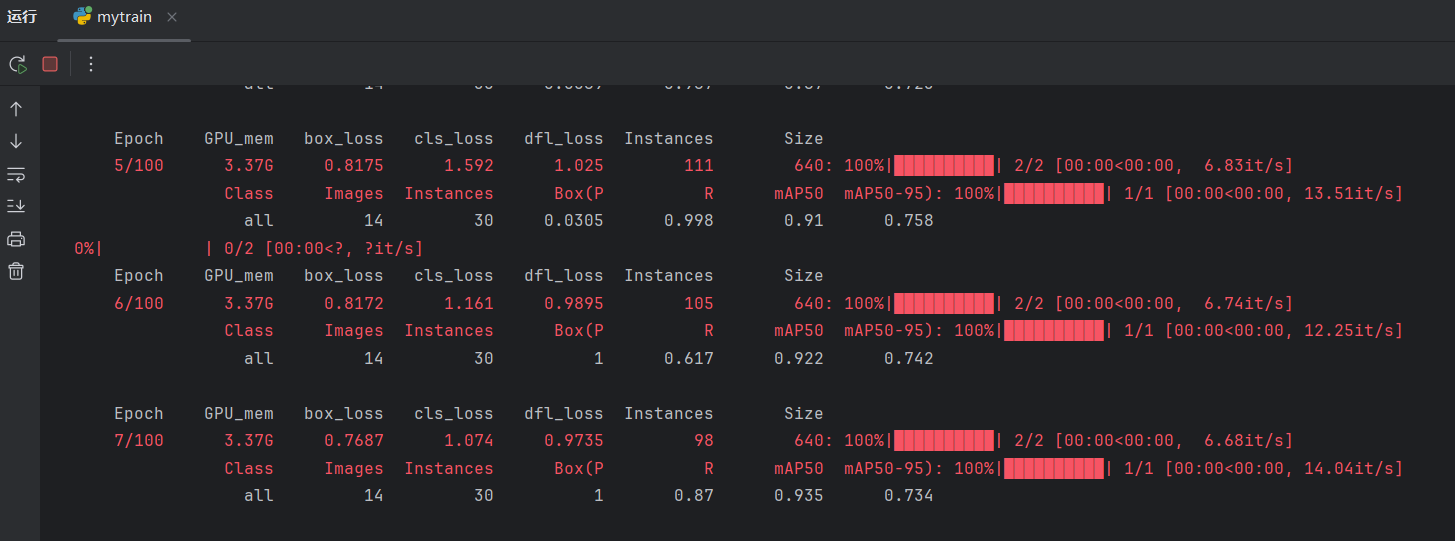
训练完成后,可以看到训练结果在results\yolov8n文件夹下:
如果要手动继续修改mytrain.py文件来依次使用剩下15个模型进行训练,太麻烦了。下面使用更加快捷自动化的方法。
(2)剩下15个模型
稍微修改一下mytrain.py文件:
python
from ultralytics import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
ms = [
'yolov8n', 'yolov8s', 'yolov8m',
'yolov9t', 'yolov9s', 'yolov9m',
'yolov10n', 'yolov10s', 'yolov10m',
'yolo11n', 'yolo11s', 'yolo11m',
'yolo12n', 'yolo12s', 'yolo12m',
]
if __name__ == '__main__':
for m in ms:
model = YOLO(m + ".pt")
model.train(
data=r"bucket_cs.yaml",
epochs=1,
imgsz=640,
batch=-1,
workers=1,
cache="ram",
project="results",
name=m,
)开始大规模训练前,最好先测试小规模训练是否能够跑通。epochs设置为1,让每个模型先只跑一轮,确保小规模训练能跑通,再进行训练:
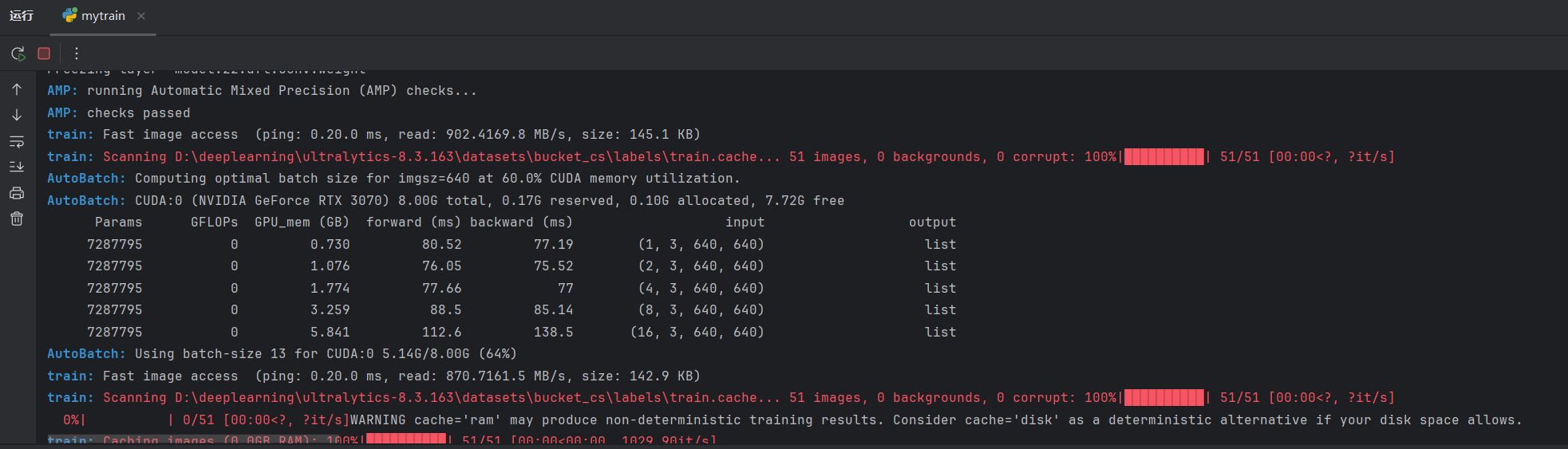
测试确实能够跑通,但切换到m尺寸模型的时候进行AutoBatch环节会卡一下:
如果能够为每个模型都调试好具体的Batch,就能跳过AutoBatch环节,提升训练速度。
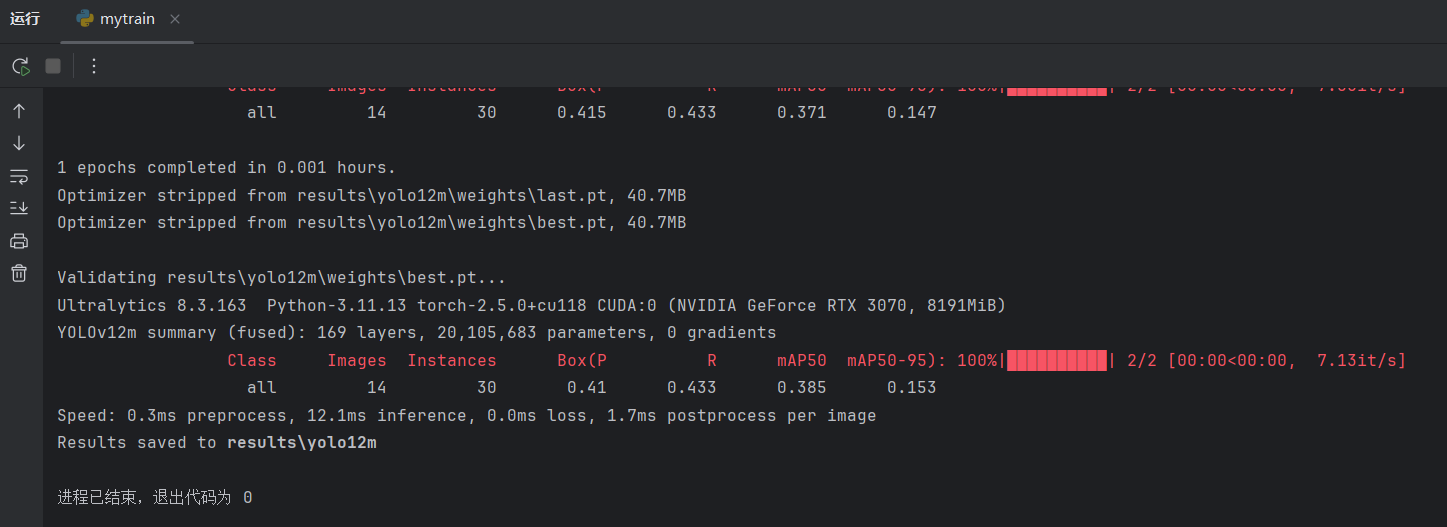
查看小规模训练结果,没有问题,清空文件夹空出空间给后面:
下面把epochs设置为100,开始正式训练。
python
from ultralytics import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
ms = [
'yolov8n', 'yolov8s', 'yolov8m',
'yolov9t', 'yolov9s', 'yolov9m',
'yolov10n', 'yolov10s', 'yolov10m',
'yolo11n', 'yolo11s', 'yolo11m',
'yolo12n', 'yolo12s', 'yolo12m',
]
if __name__ == '__main__':
for m in ms:
model = YOLO(m + ".pt")
model.train(
data=r"bucket_cs.yaml",
epochs=100,
imgsz=640,
batch=-1,
workers=1,
cache="ram",
project="results",
name=m,
)点击运行,开始训练:
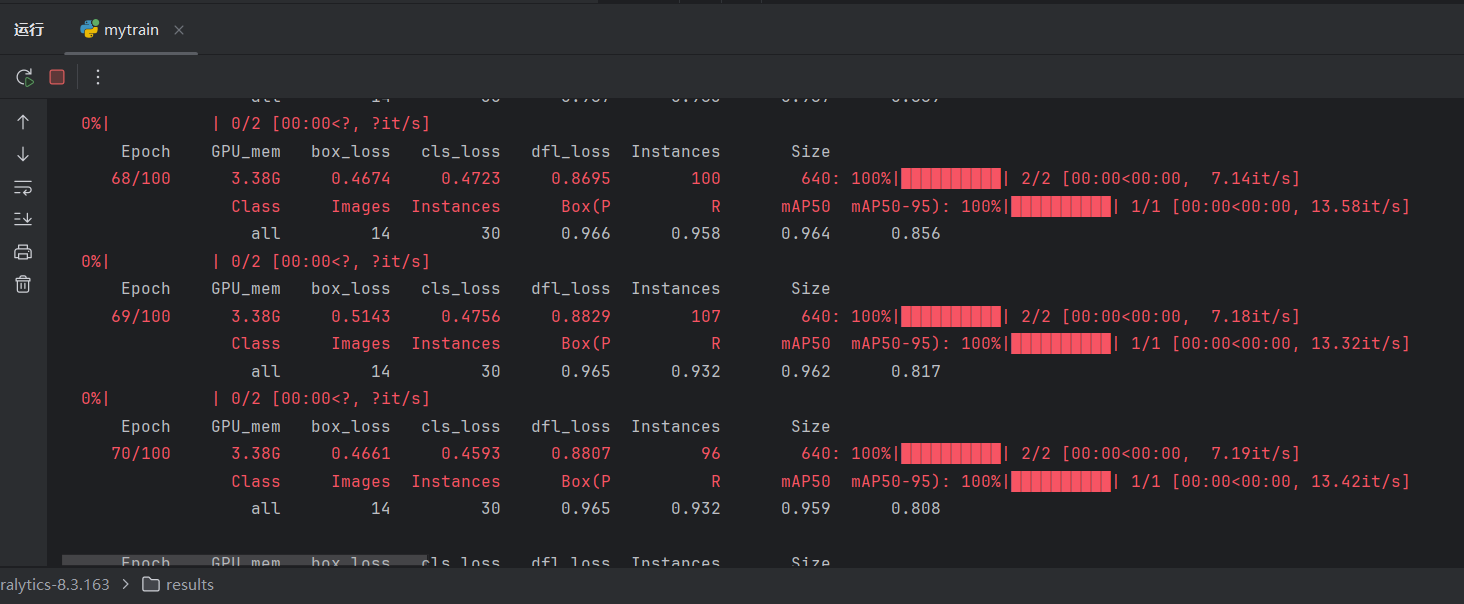
(3)查看训练效果
查看16个模型的训练效果,打开mypredict.py,分别查看不同模型的验证集和测试集的预测效果。这里以yolo11m.pt模型为例:
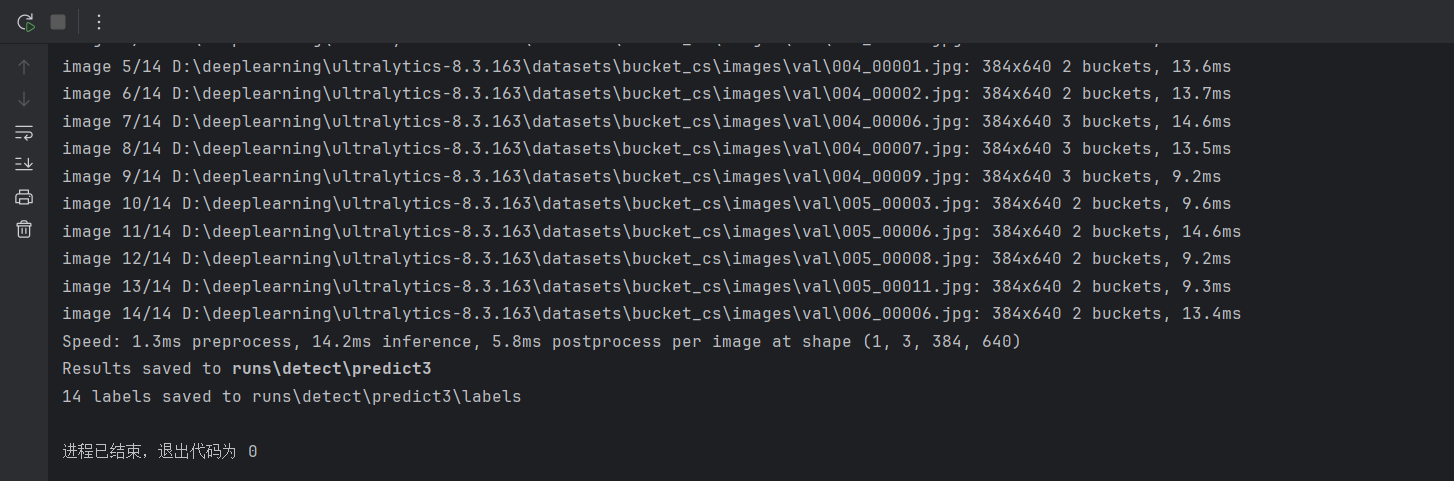
验证集:
python
from ultralytics import YOLO
model = YOLO(r"D:\deeplearning\ultralytics-8.3.163\results\yolo11m\weights\best.pt")
model.predict(
source=r"D:\deeplearning\ultralytics-8.3.163\datasets\bucket_cs\images\val",
save=True,
show=False,
save_txt=True,
)
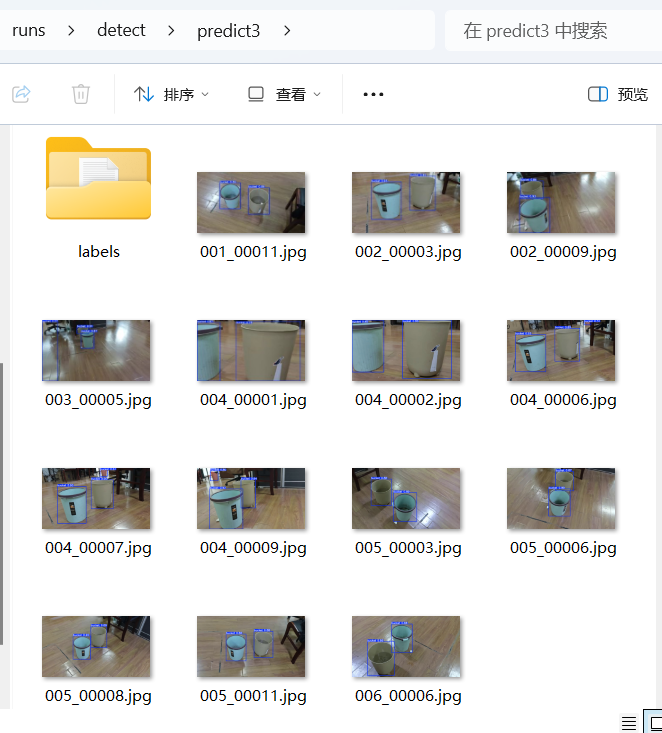
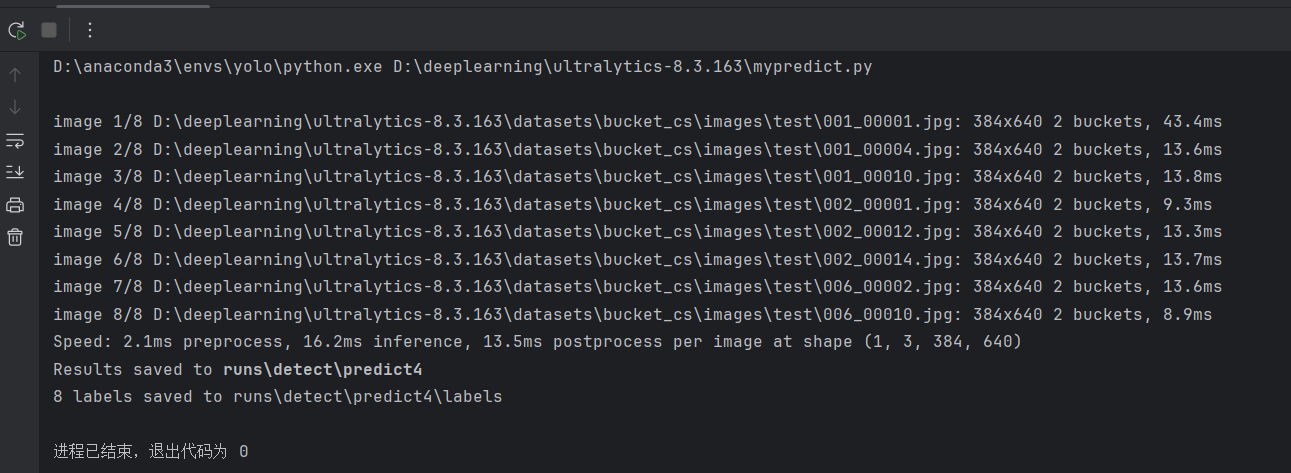
测试集:
python
from ultralytics import YOLO
model = YOLO(r"D:\deeplearning\ultralytics-8.3.163\results\yolo11m\weights\best.pt")
model.predict(
source=r"D:\deeplearning\ultralytics-8.3.163\datasets\bucket_cs\images\test",
save=True,
show=False,
save_txt=True,
)
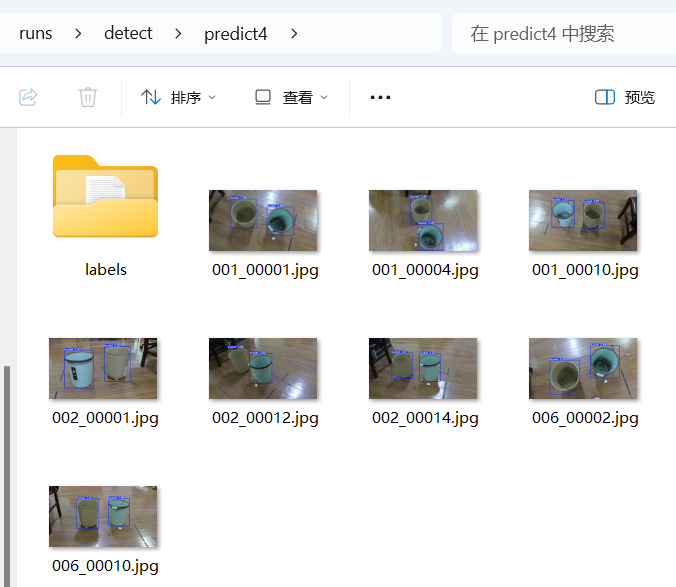
新视频素材:
也可以重新拍摄一段视频素材,进行测试:
python
from ultralytics import YOLO
model = YOLO(r"D:\deeplearning\ultralytics-8.3.163\results\yolo11m\weights\best.pt")
model.predict(
source=r"C:\Users\Avlon\Desktop\007.mp4",
save=True,
show=False,
save_txt=True,
)
查看结果:

如何让训练的预测效果更好点?------多训练点图片。
在环境变化比较大的情况,通过原来几十张图片训练的简易数据集训练出的模型预测就不够用了,这时候就需要根据实际使用场景来丰富数据集。把效果不佳的场景补充进原先的数据集。
如何判断不同模型的效果?------通过验证对模型进行打分。
二、验证模型能力
【模型】 【预测结果】
【一组图片】------------> .txt标签文件 ------------> 【对比结果】相似度XX%
全部推理 【真实结果】 对比
得到一个相似度,相似度越高代表模型预测能力越强。
评价指标:
|----------|------|
| 指标 | 分数 |
| P | 0.xx |
| R | 0.xx |
| F1 | 0.xx |
| mAP50 | 0.xx |
| mAP50-95 | 0.xx |
(1)**IoU:**判断预测结果是否正确的标准
目标检测领域通常使用IoU (Intersection over Union)评价两个框的接近程度。两个相交的框的交集/两个框的并集=IoU ,两个框完全重叠IoU 就是1,一点不重叠IoU就是0。
现在可以设置判断预测是否正确的IoU 阈值。超过这个阈值就算正确,低于这个阈值就算错误。在设定好IoU阈值后,给定一组预测结果和真实结果,就能判断预测是否正确。
(2)统计指标:TP, FP, FN
统计指标:针对每个预测类型,比较真实结果和预测结果,
- TP:True Positive (真正例),正确的预测结果数量。
- FP:False Postive (假正例),错误的预测结果数量。
- FN:False Negative (假负例),没有预测到的真实结果数量。
判断预测结果是否正确的标准就是上一节的IoU阈值。
=》如果有多个预测结果匹配一个真实结果,或者多个真实结果匹配一个预测结果,怎么办?
- 多个预测结果匹配一个真实结果:把一个预测结果标记为匹配失败,FP+1。
- 多个真实结果匹配一个预测结果:把一个真实结果标记为匹配失败,FN+1。
(3)常用评价指标**:**P, R, F1
评价指标:
- P:Percision (精确率),P = TP/(TP+FP),即等于正确预测/预测总数。
- R:Recall (召回率),R = TP/(TP+FN),即等于正确预测/真实总数。
- F1:F1 score (F1分数),F1 = (2*P*R)/(P+R)
精确率高:预测结果里很多都是正确的;召回率高:真实结果里很多都被预测到了,很少被遗漏; F1分数:基于P和R计算出来的一个评价分数,类似的有F2, F3, F0.5等等,区别是更侧重P还是R。
三、推理进阶
推理的步骤:
预处理 ---------> 推理 ------> 后处理
(1)后处理:
- 去弱:使用 conf (confidence,置信度) 阈值筛选掉低概率的框。conf=0.25,排除conf低于0.25的框。
- 去重:使用 NMS 过滤掉重复的预测结果。如以 IoU>0.7 为标准,排除重复框。
- 设限:限制预测结果的总数。如设置 max_det=300 。
在PyCharm中打开源码项目ultralytics-8.3.163,打开mypredict.py:
python
from ultralytics import YOLO
model = YOLO(r"yolo11n.pt")
model.predict(
source=r"ultralytics/assets",
save=True,
show=False,
conf=0.25,
iou=0.7,
max_det=300,
)conf=0.25, iou=0.7, max_det=300, 是三个选项的默认值,就算不写也会默认使用这三个数值进行后处理。
点击运行,并查看结果:
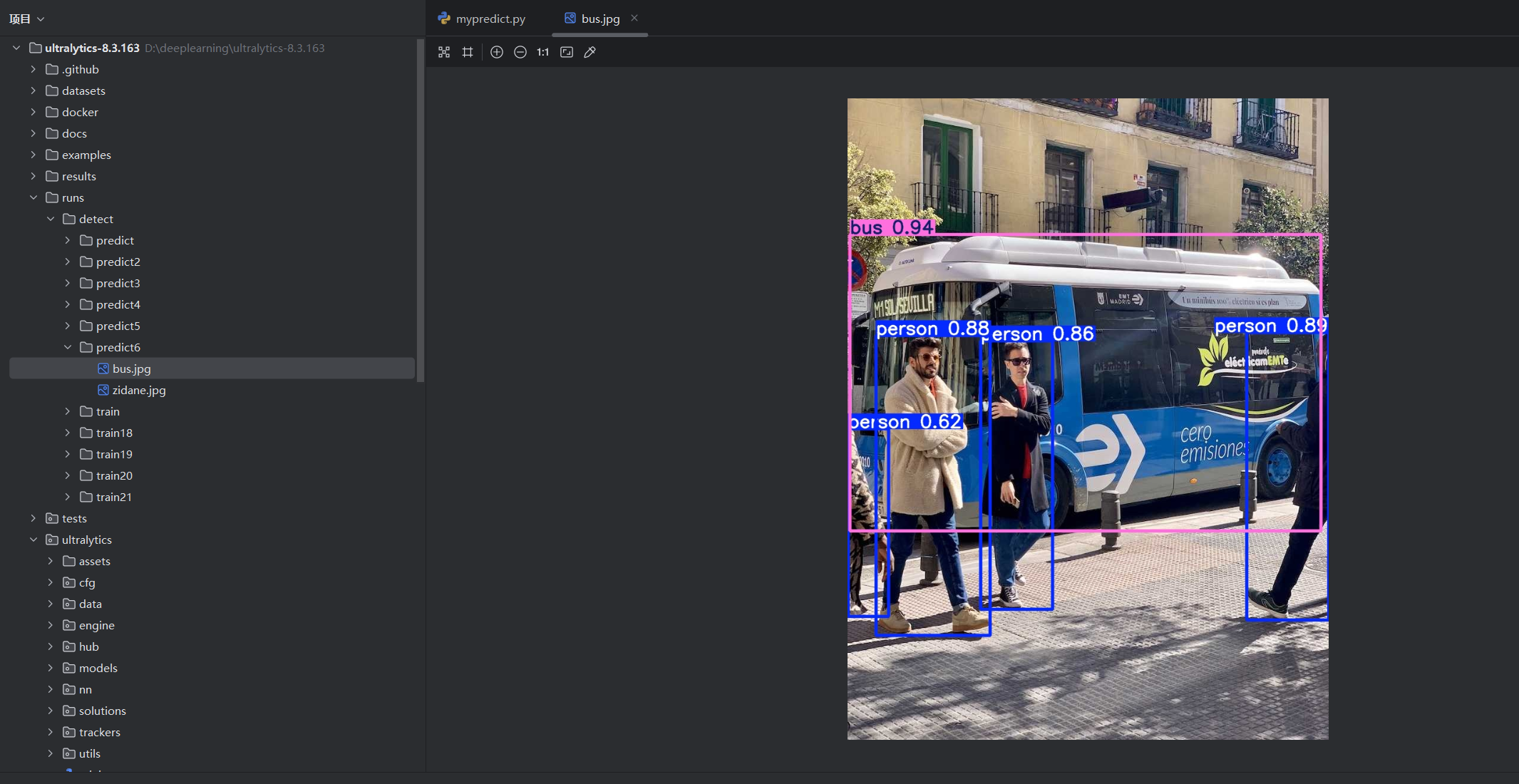
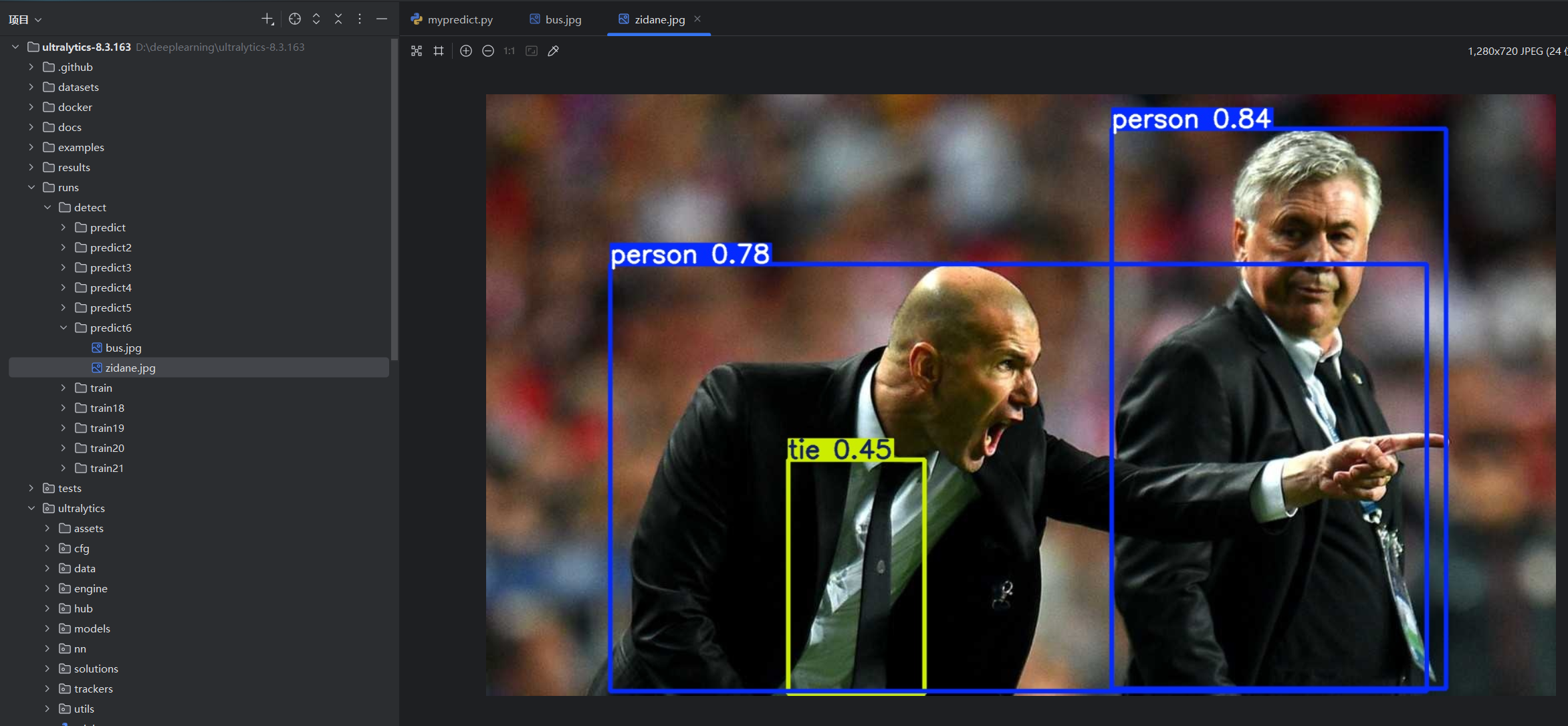
现在修改:
python
from ultralytics import YOLO
model = YOLO(r"yolo11n.pt")
model.predict(
source=r"ultralytics/assets",
save=True,
show=False,
conf=0.0, # 不去弱
iou=1.0, # 不去重
max_det=99999, # 数值过大,相当于不设限
)点击运行,可以看到最原始的预测结果:
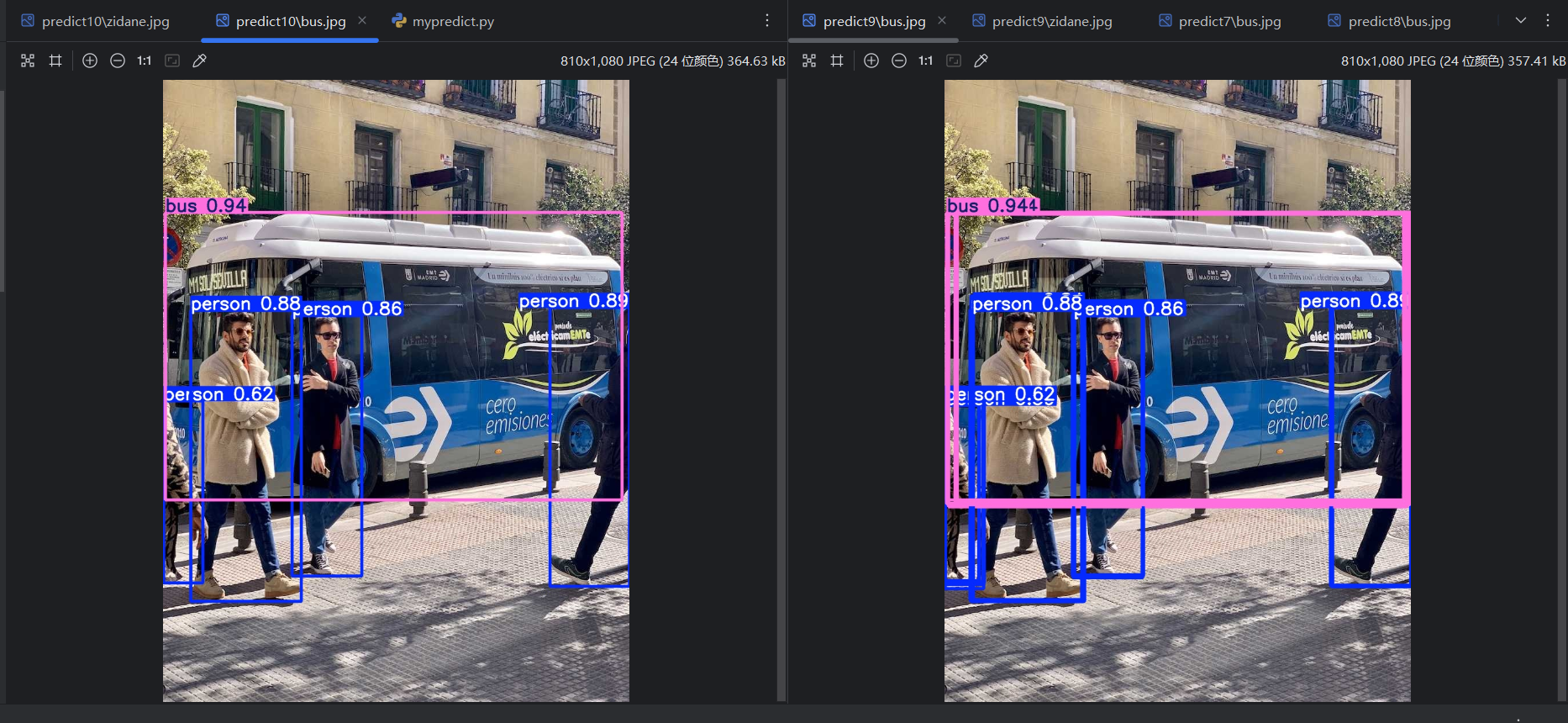
将max_det改为默认的300,重新运行,可以看到框的数量少了很多:
将conf改为默认的0.25,重新运行,可以看到框的数量右少了一些:
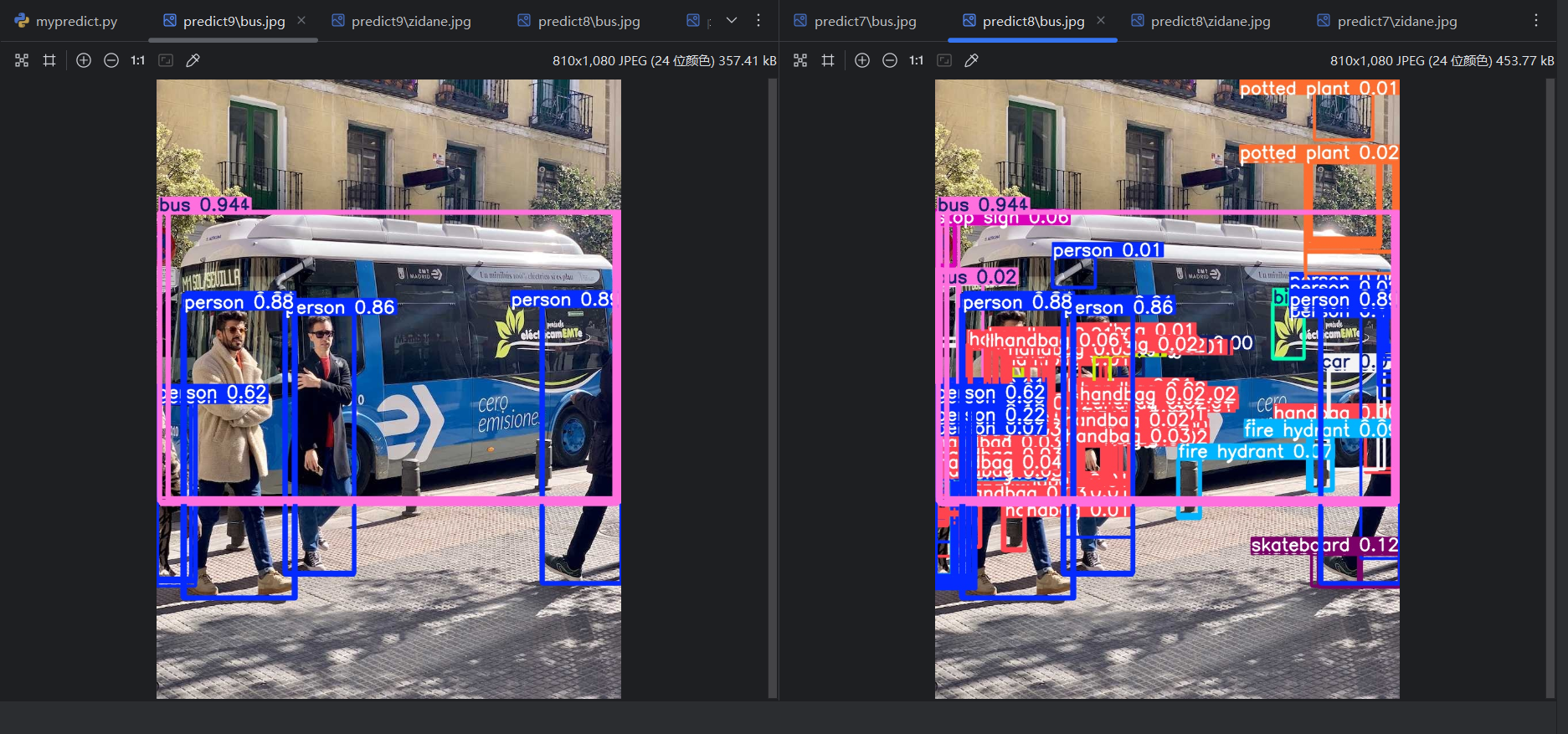
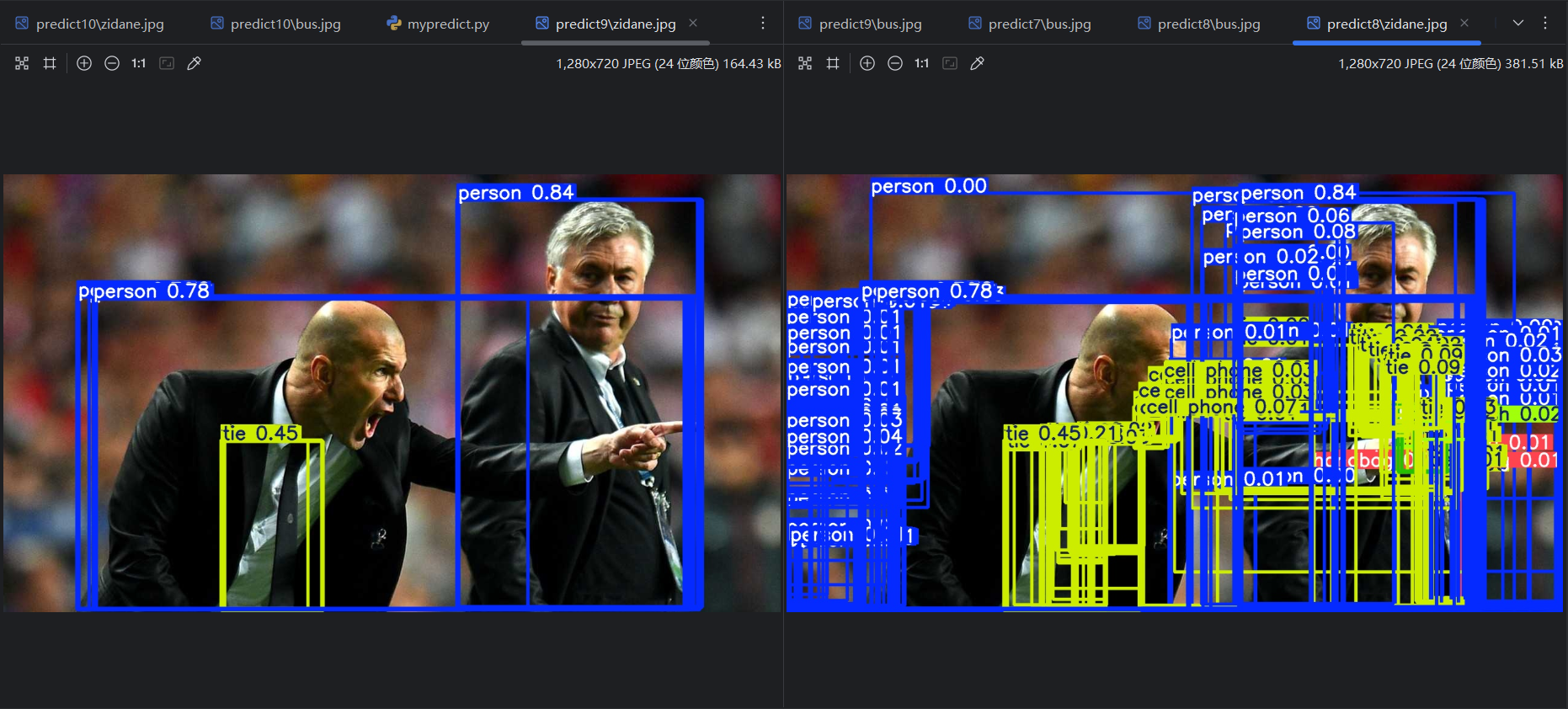
因为 conf 比 max_det 更早起作用。
将iou改为默认的0.7,重新运行,可以看到没有重复的框了:
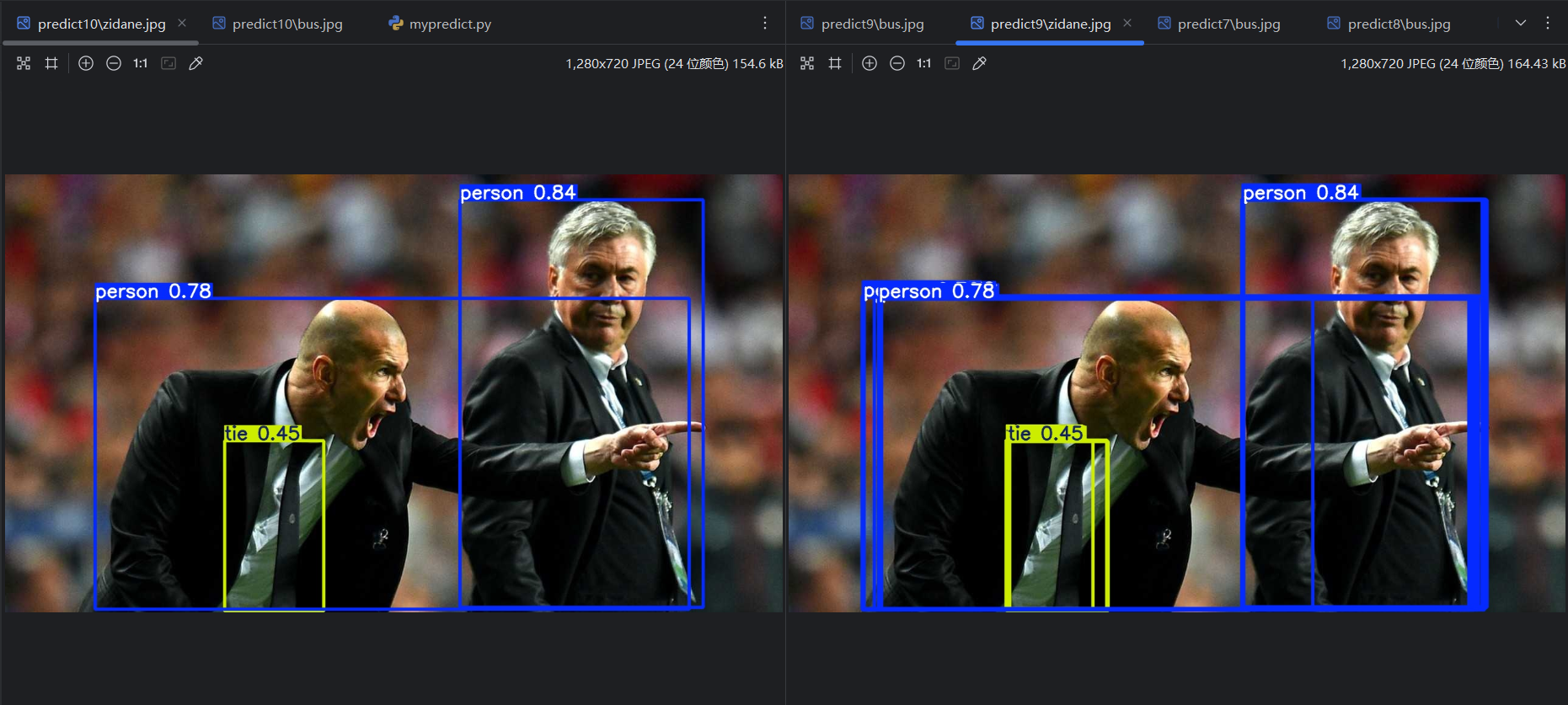
(2)conf 对预测结果的影响
将conf改为0.01,重新运行,可以看到多了一些预测结果:
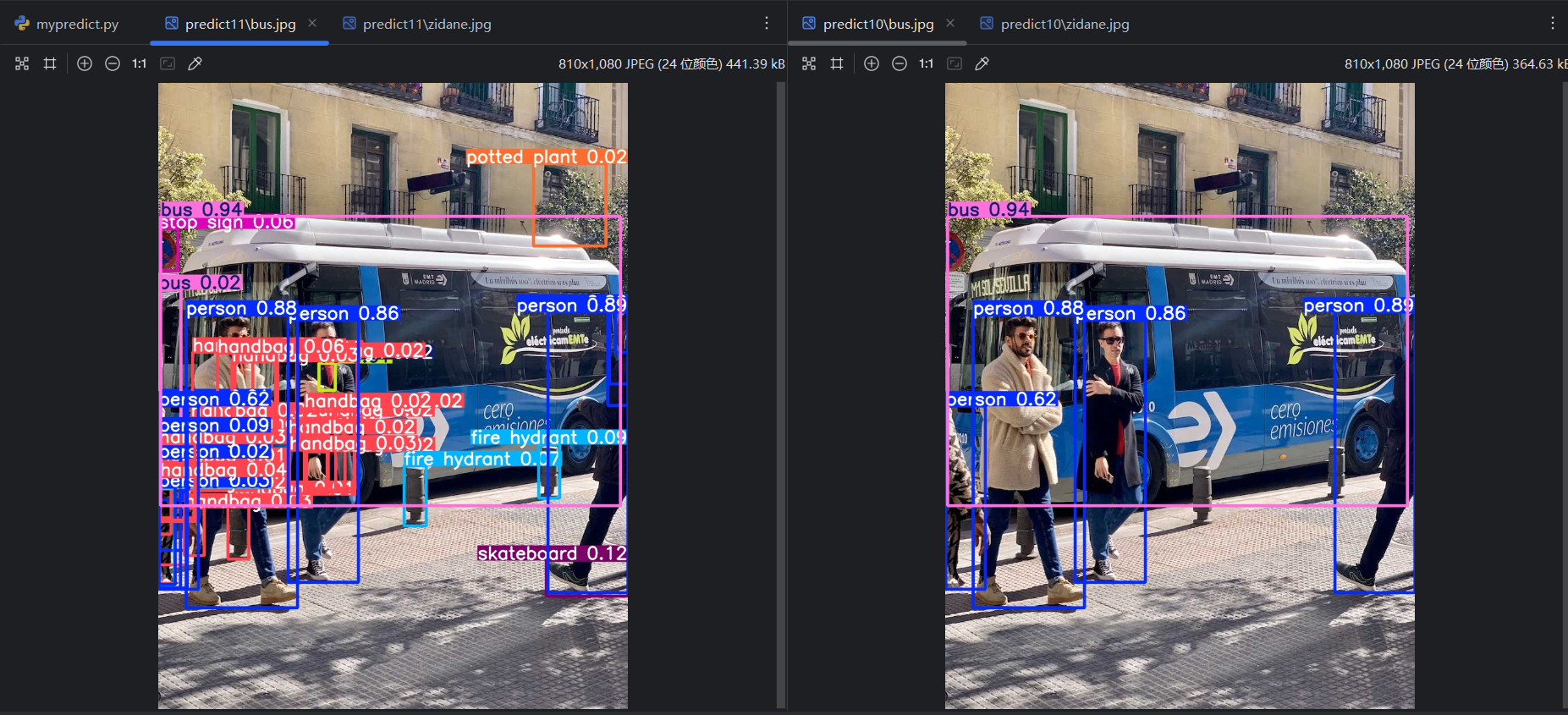
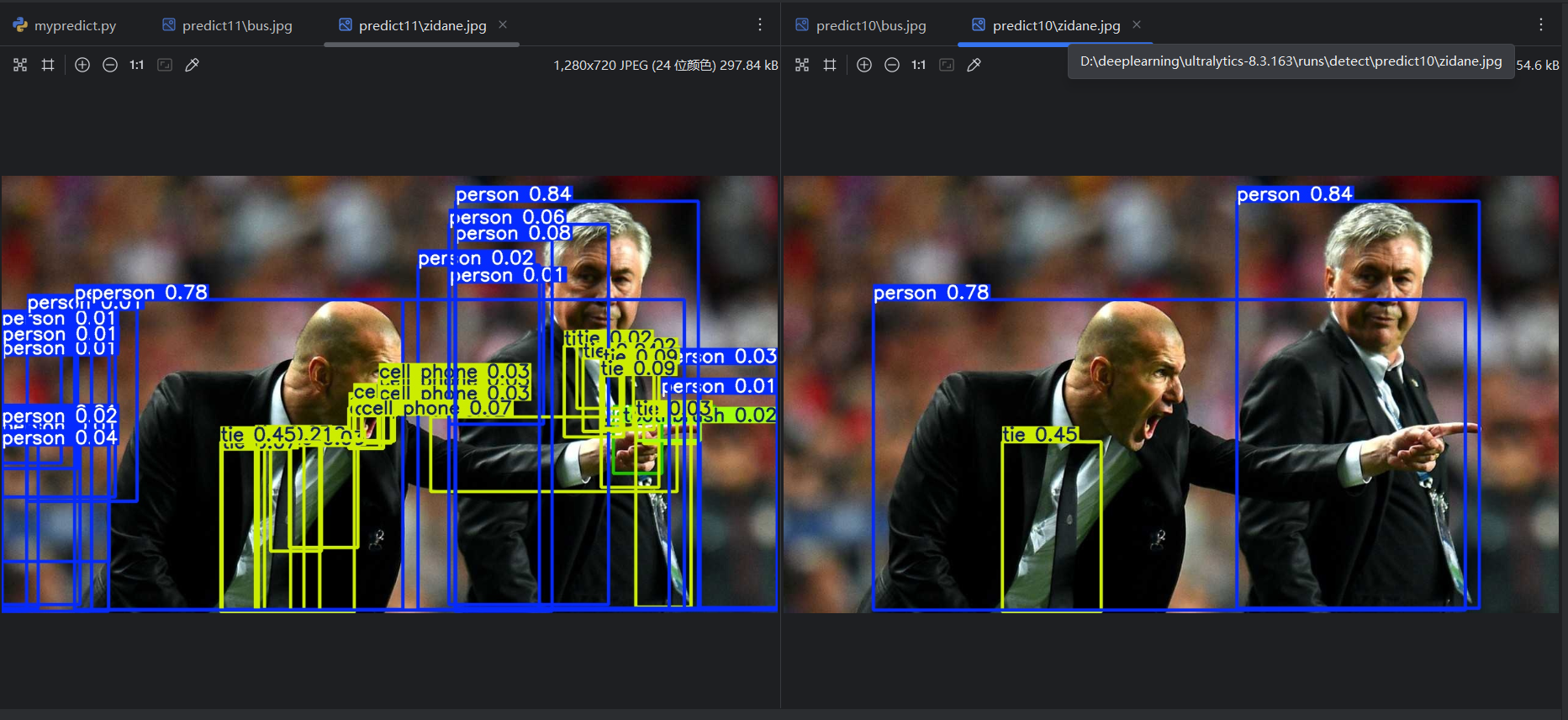
将conf改为0.9,重新运行,可以看到少了一些预测结果:
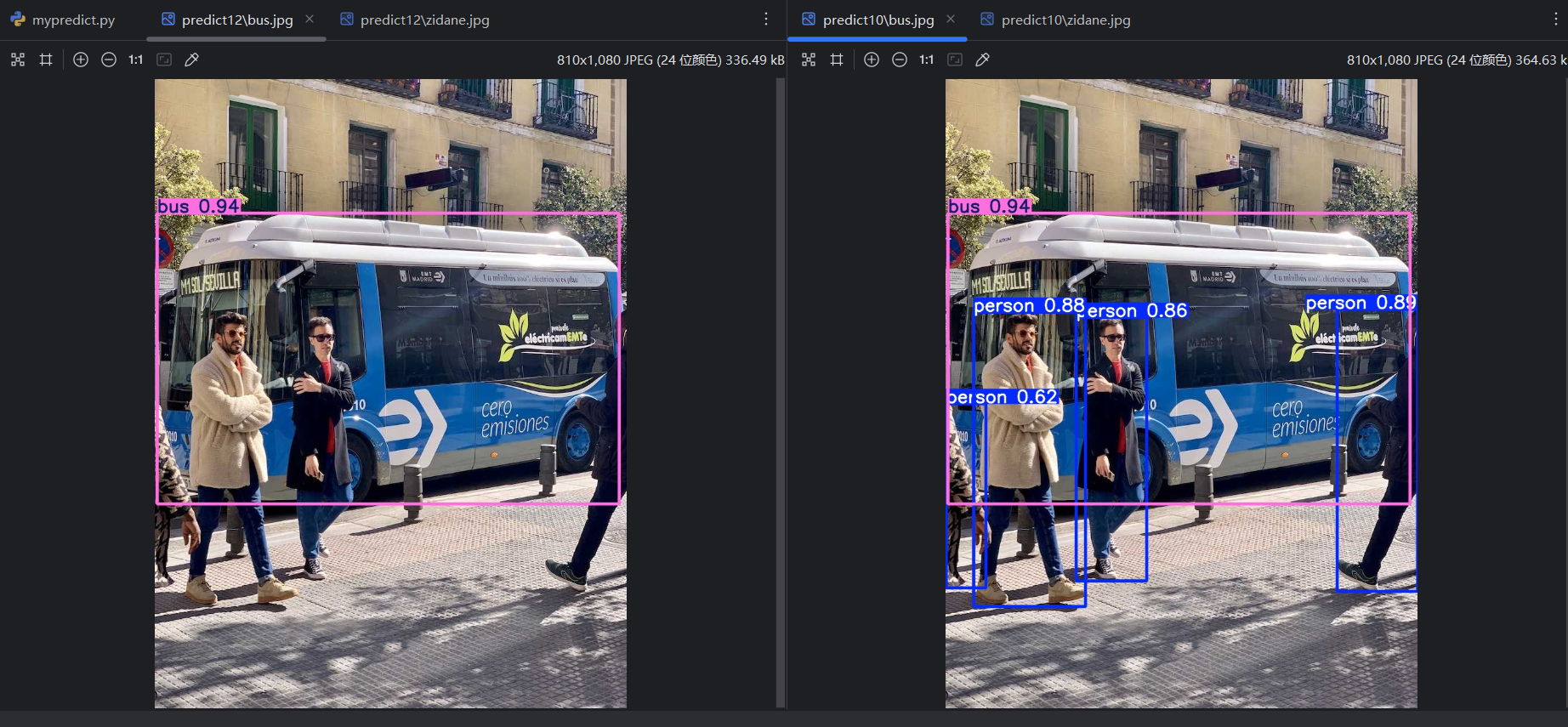
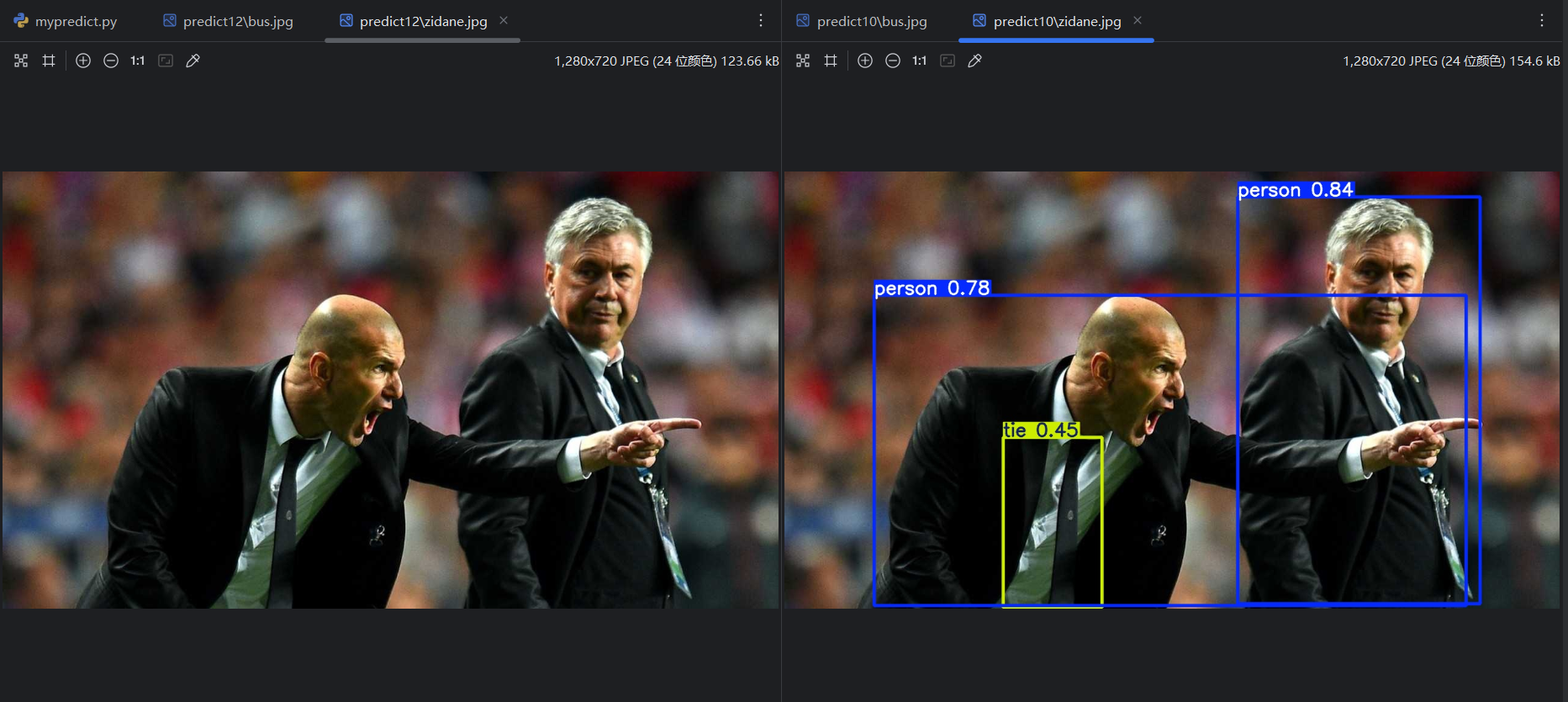
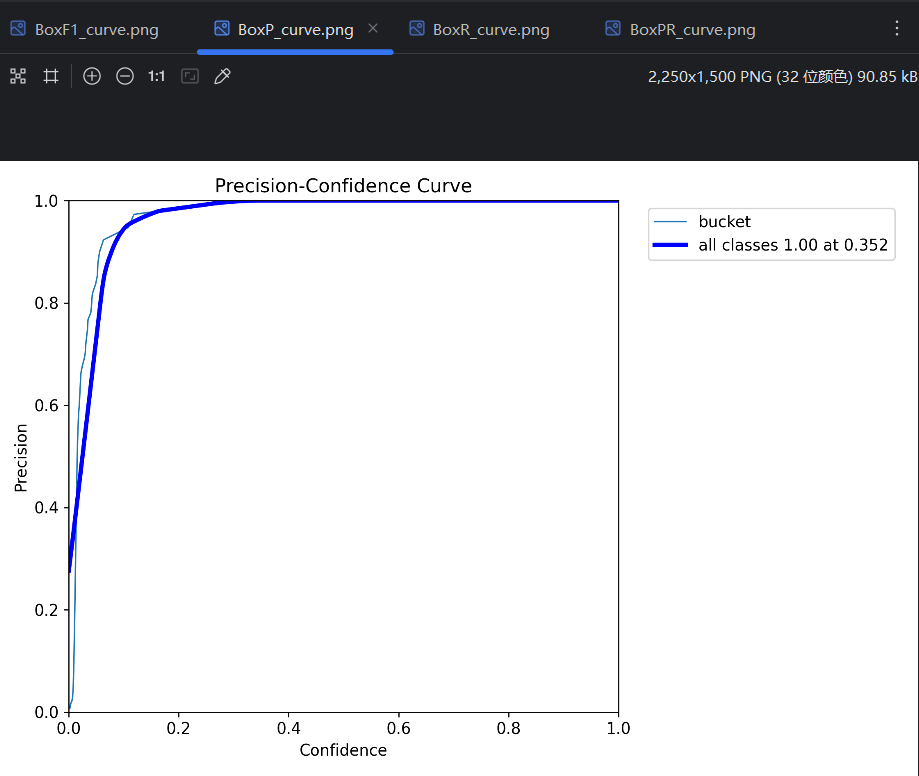
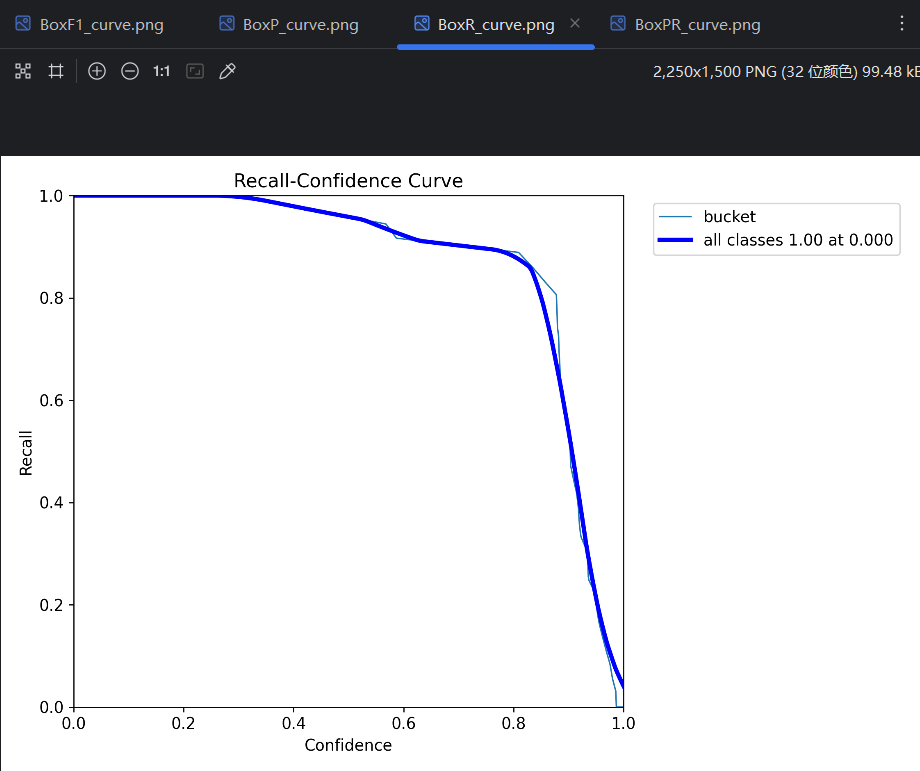
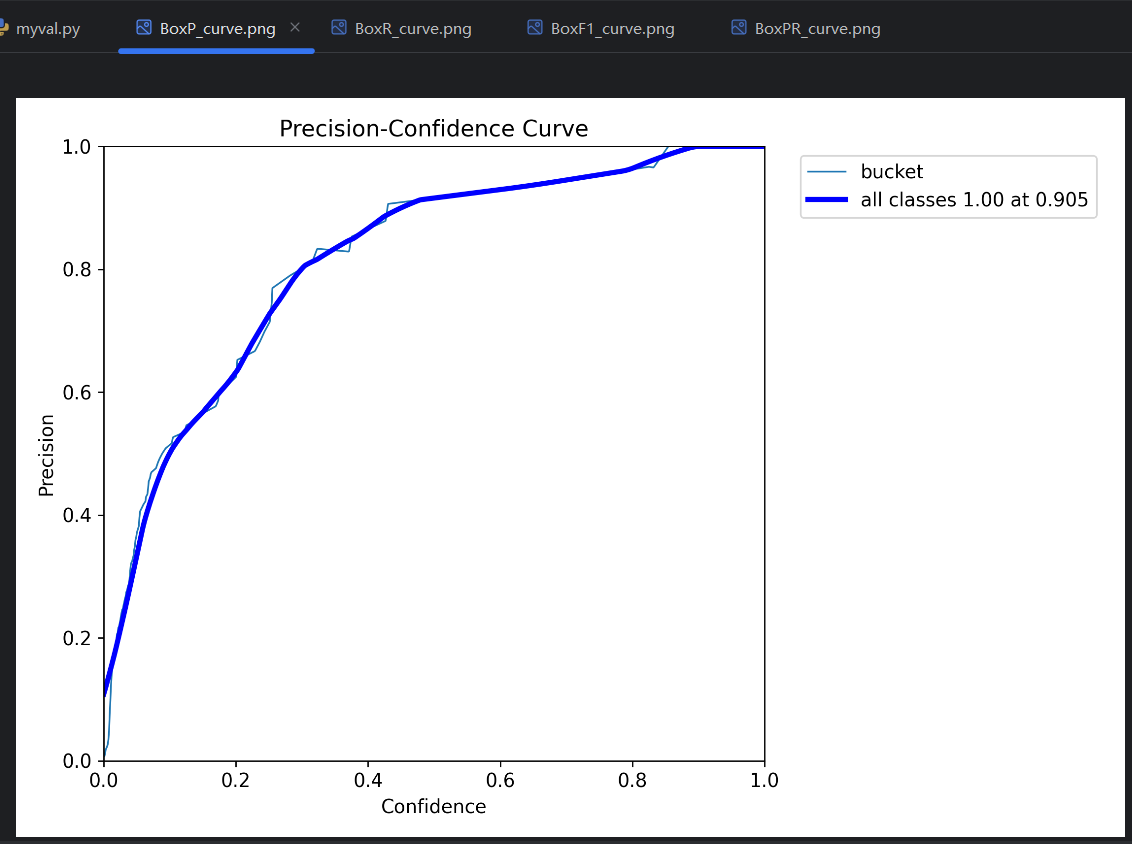
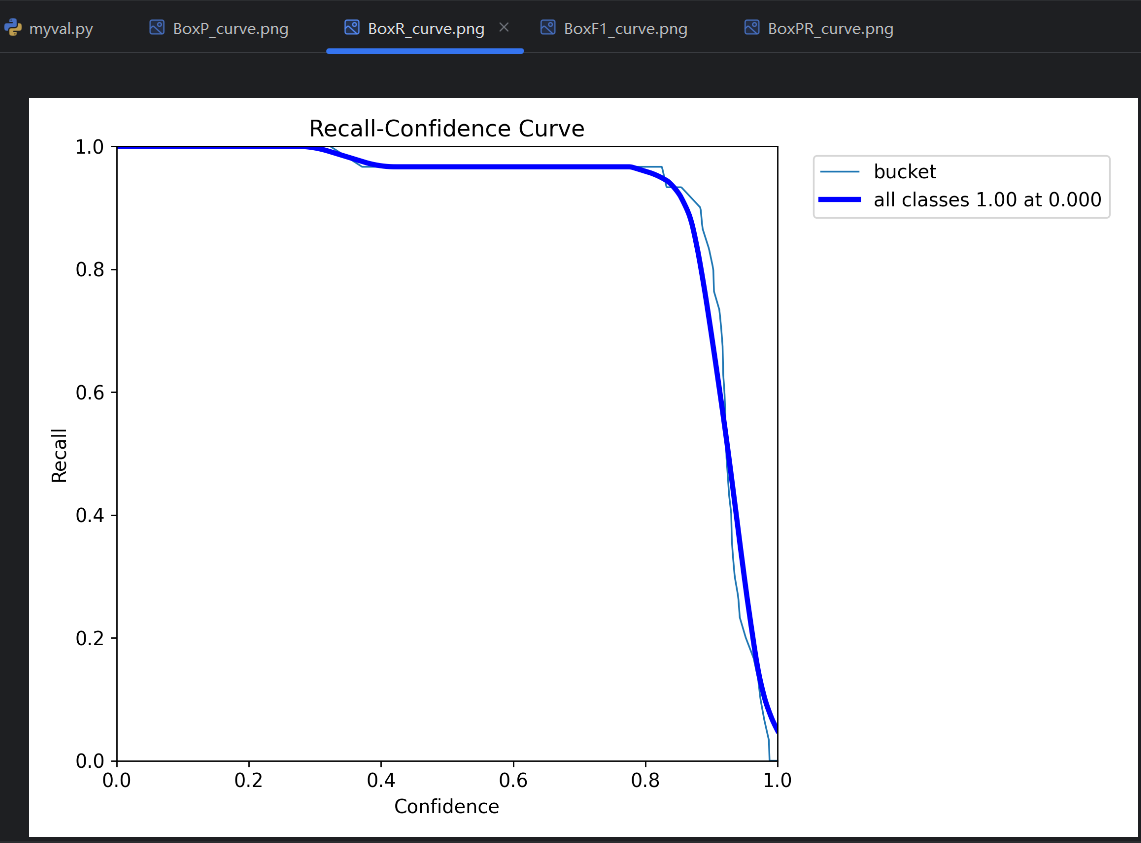
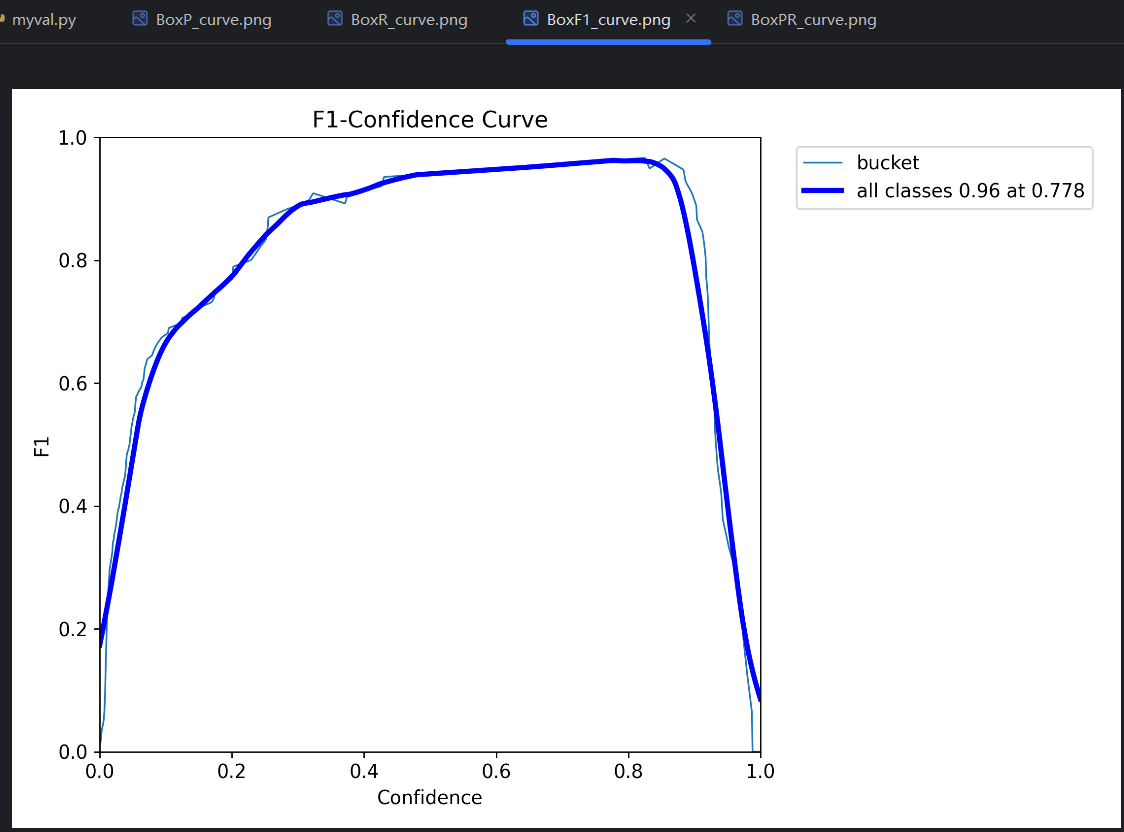
=》conf 越高,预测结果数量越少。所以conf的设置会影响预测评价指标。对一个单独的预测类型,变化的conf会有变化的预测评价指标,所以可以得到P曲线、R曲线和F1曲线。把每个类型的曲线进行平均,平均后的曲线就是这个模型的P曲线、R曲线和F1曲线。
图片来源:https://www.bilibili.com/video/BV1D74JzdEjd?t=1070.3
曲线与横轴围成的面积越接近1,表示模型预测效果越好;
曲线与横轴围成的面积越接近0,表示模型预测效果越差。
打开训练结果,可以查看到这三个曲线图:
P曲线:
R曲线:
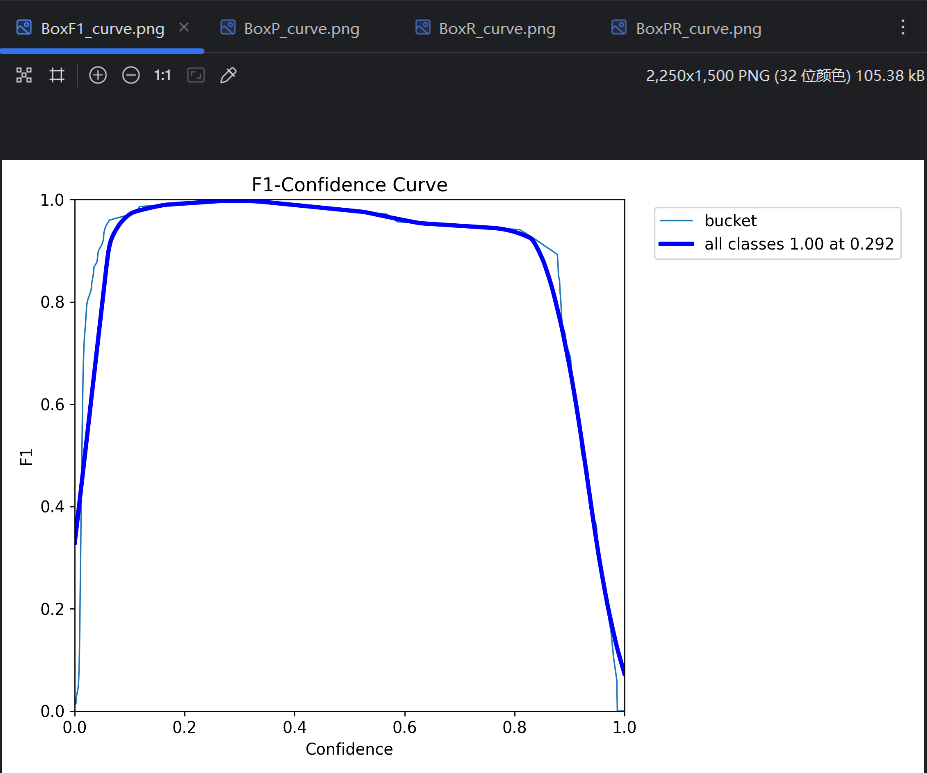
F1曲线:
如何设置conf:
conf不能太低,不然会导致精确率太低;conf不能太高,不然会导致召回率太低,出现很多漏报。一般以F1曲线 最高点处的conf值为设置值,对应的P、R和F1简单理解为模型的P、R和F1。训练的时候,每一轮的P、R就是这样得到的。
随着每一轮训练更新,P、R也会不断更新。正常情况下,P、R会随着训练越来越高,直到稳定在一个位置附近。
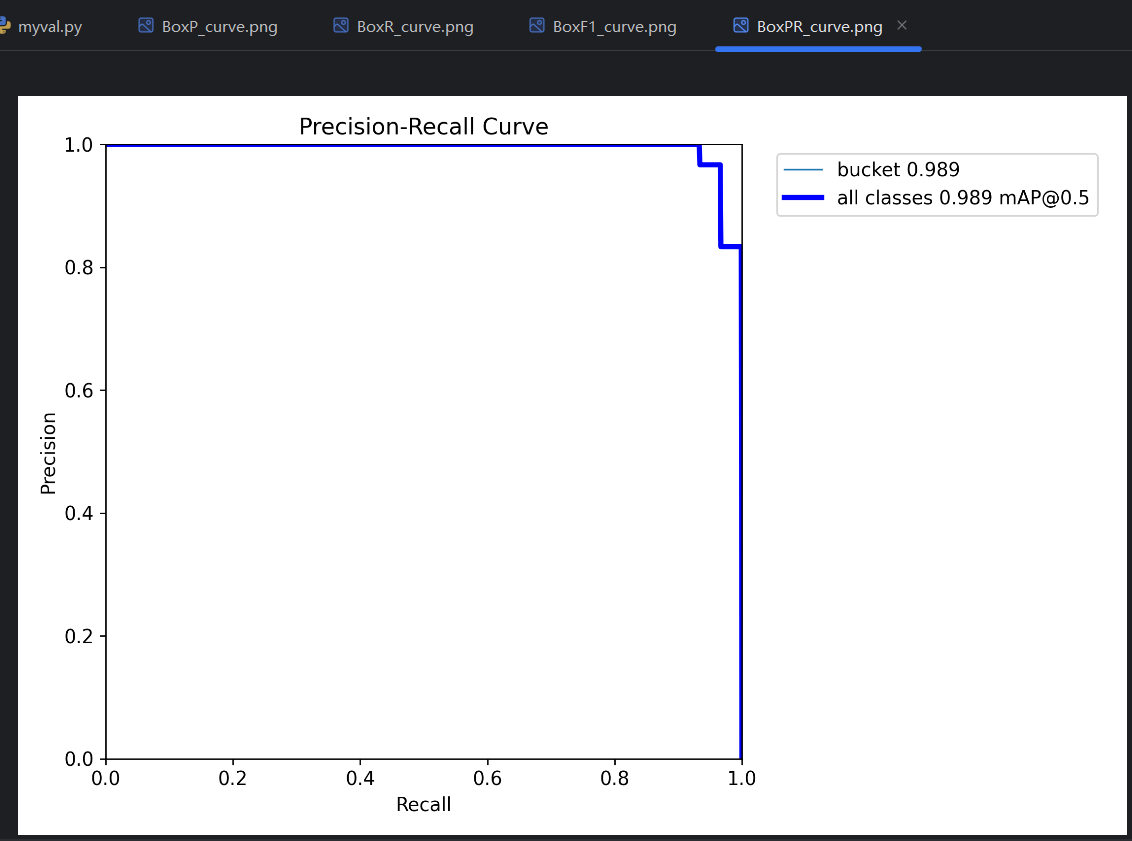
(3)PR曲线:mAP50, mAP50-95
通过P曲线和R曲线可以获得一个PR曲线。一个conf对应一个P和一个R,把P作为纵坐标,把R作为横坐标,conf一确定就能在坐标轴里找到一个点,随着conf变化能得到很多点,这些点连起来就能获得PR曲线。
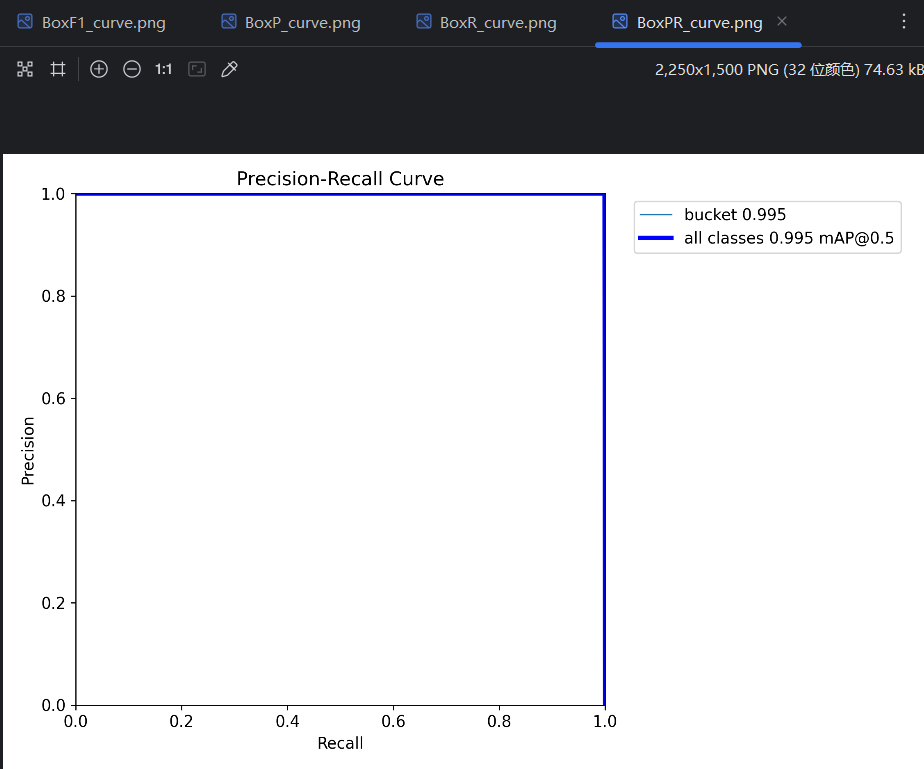
PR曲线指标:
- AP :平均精度(Average Precision),PR曲线 线下的面积是0-1的小数,这个面积就叫AP。比如图中bucket类型的PR曲线的线下面积是0.995,就可以说模型在bucket类型上的AP是0.995。
- mAP:平均平均精度(mean Average Precision),所有类型的PR曲线的平均一下就得到了mAP。因为只有bucket一种类型,图中的mAP也是是0.995。
PR曲线很饱满靠外,AP的值就会越接近1,模型在该类型的预测效果就越好。但实际上,PR曲线是否饱满靠外,AP是否大,取决于P曲线和R曲线交点的高度;P曲线和R曲线在高处只有短暂交会,只要交点够高,依然能取得较大的AP值,但P曲线和R曲线整体不一定效果都好,这时候conf的选择就很严苛才能取得很好的预测结果。
mAP50-95:
每个IoU阈值都对应一个mAP,IoU阈值越高,对应mAP就越低。因为预测正确的标准更高了,预测分数就下降了。将预测分数平均一下就得到了目前最复杂的一个评价指标,mAP50-95。
IoU阈值=0.50 ------> mAP50=0.72
IoU阈值=0.55 ------> (.txt标签) mAP55=0.65
IoU阈值=0.60 ------> 一 【模型】 预 真 mAP60=0.58
. ------> 组 ---------> 测 实 ---------> . ------> mAP50-95
. ------> 图 全部推理 结 结 筛选 . 平均
. ------> 片 果 果 对比 .
IoU阈值=0.90 ------> mAP90=0.35
IoU阈值=0.95 ------> mAP95=0.32
最常用的是mAP50和mAP50-95。
至此,已学习了验证了四个评价指标:P, R, mAP50, mAP50-95。训练的时候,每一轮验证都可以看到这四个指标:
(4)手动验证预测效果
python
from ultralytics import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
if __name__ == '__main__':
model = YOLO(r"D:\deeplearning\ultralytics-8.3.163\results\yolo11n\weights\best.pt")
model.val(split="val")best.pt模型中已保存数据集的位置,所以不需要另外加data说明数据集位置。
点击运行:
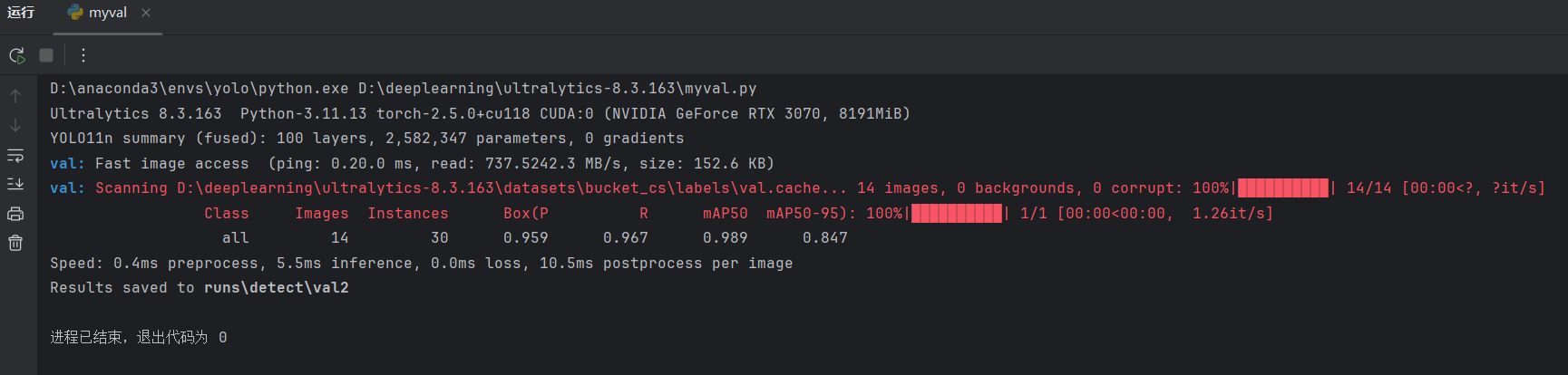
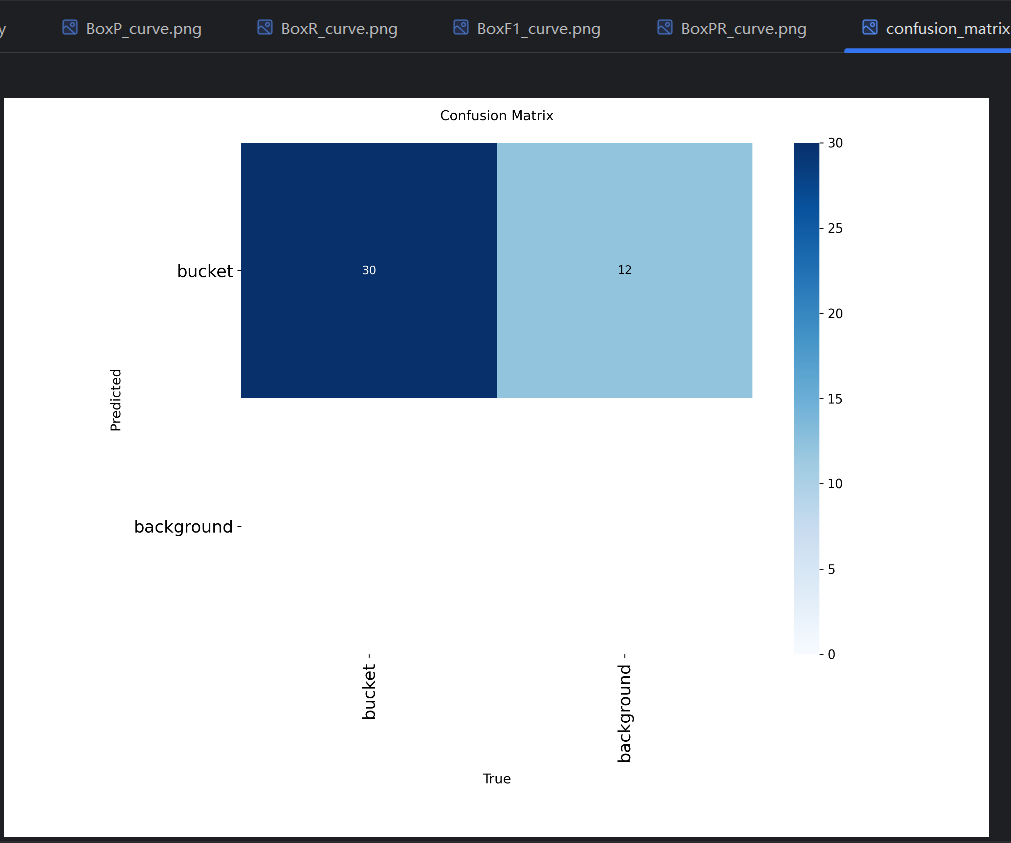
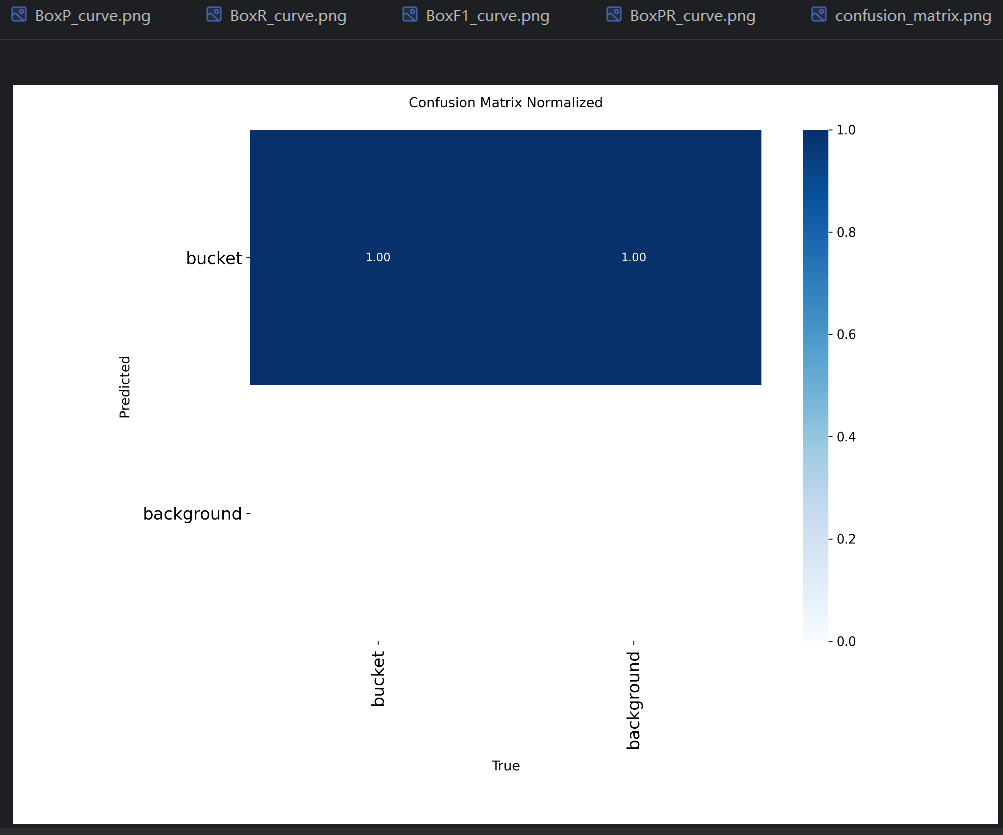
说明一共验证了14张图片,共有30个真实目标。可以查看验证结果:
以及两个混淆矩阵。混淆矩阵反映出区分不同预测类型的能力,这里只有一种类型,所以没用到:
部分预测效果图,分真实结果和预测结果:
真实结果:

预测结果:

同样,可以把验证集改为测试集:
python
model.val(split="test")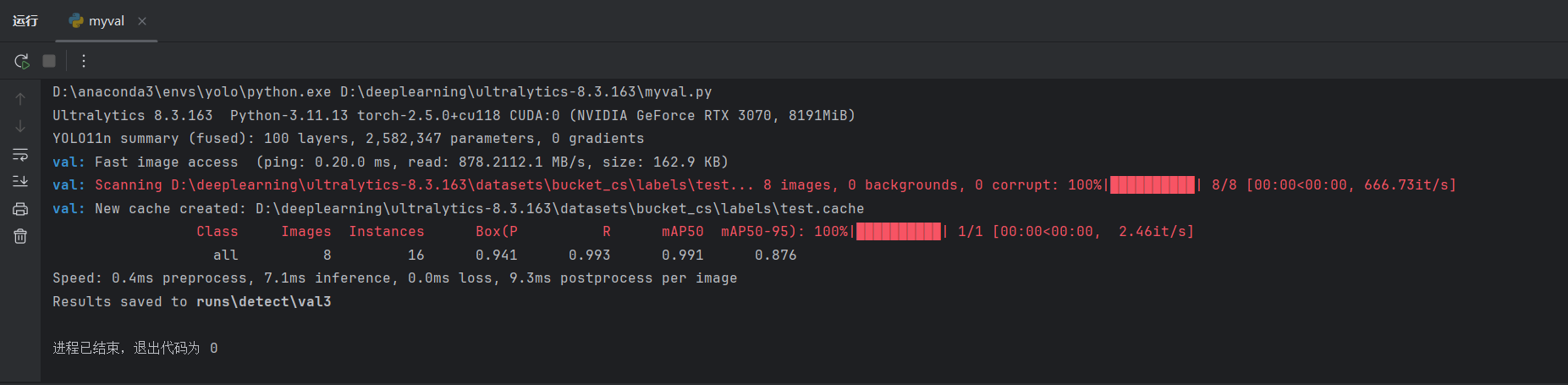
可以观察测试集的指标。
对比三个集(训练、验证、测试)的指标,可以发现一般训练集的指标最好,其他两个更差点。