代码部分(**可以看作 "演示了「训练好权重后」,注意力机制捕捉上下文语义、生成输出的核心逻辑" 。)**
python
import torch.nn as nn
import torch
class SelfAttention(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v):
super().__init__()
self.d_out_kq = d_out_kq
self.W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_value = nn.Parameter(torch.rand(d_in, d_out_v))
def forward(self, x):
keys = x @ self.W_key
queries = x @ self.W_query
values = x @ self.W_value
attn_scores = queries @ keys.T # unnormalized attention weights
attn_weights = torch.softmax(
attn_scores / self.d_out_kq ** 0.5, dim=-1
)
context_vec = attn_weights @ values
return context_vec
class MultiHeadAttentionWrapper(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v, num_heads):
super().__init__()
self.heads = nn.ModuleList(
[SelfAttention(d_in, d_out_kq, d_out_v)
for _ in range(num_heads)]
)
def forward(self, x):
return torch.cat([head(x) for head in self.heads], dim=-1)
#分词处理
sentence = 'Life is short, eat dessert first'
dc = {s:i for i,s
# 索引的字典
in enumerate(sorted(sentence.replace(',', '').split()))}
print(dc)
#{'Life': 0, 'dessert': 1, 'eat': 2, 'first': 3, 'is': 4, 'short': 5}
#把句子转成索引张量
sentence_int = torch.tensor(
[dc[s] for s in sentence.replace(',', '').split()]
)
#tensor([0, 4, 5, 2, 1, 3])
print(sentence_int)
vocab_size = 50_000
torch.manual_seed(123)#固定随机种子,保证结果可复现
embed = torch.nn.Embedding(vocab_size, 3)# 嵌入层:词汇表大小5万,每个词嵌入3维
embedded_sentence = embed(sentence_int).detach()# detach()剥离计算图(避免求导)
print(embedded_sentence)
#tensor([[ 0.3374, -0.1778, -0.3035],
# [ 0.1794, 1.8951, 0.4954],
# [ 0.2692, -0.0770, -1.0205],
# [-0.2196, -0.3792, 0.7671],
# [-0.5880, 0.3486, 0.6603],
# [-1.1925, 0.6984, -1.4097]])
print(embedded_sentence.shape)
#torch.Size([6, 3])
torch.manual_seed(123)
# reduce d_out_v from 4 to 1, because we have 4 heads
d_in, d_out_kq, d_out_v = 3, 2, 4
# sa = SelfAttention(d_in, d_out_kq, d_out_v)
# print(sa(embedded_sentence))
mha = MultiHeadAttentionWrapper(
d_in, d_out_kq, d_out_v, num_heads=4
)
context_vecs = mha(embedded_sentence)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)一、单头自注意力的局限(为什么需要多头?)
之前的SelfAttention类实现的是单头自注意力:
- 输入词嵌入(6×3)→ 用一组固定的 W_query/W_key/W_value 投射成一套 Q/K/V → 计算出一套注意力权重 → 输出 1 组上下文向量(6×4);
- 核心问题:单头只能捕捉 "一种维度的语义关联"(比如只能关注 "主谓宾" 关系,或只能关注 "修饰关系"),但自然语言中词的关联是多维度的(比如 "猫" 既和 "吃" 是主谓关系,又和 "鱼" 是动宾的关联对象)。
而多头注意力 的核心就是:用多组独立的 Q/K/V(多个 "头"),从不同角度捕捉词与词的语义关联,最后把结果拼接,得到更全面的上下文信息。
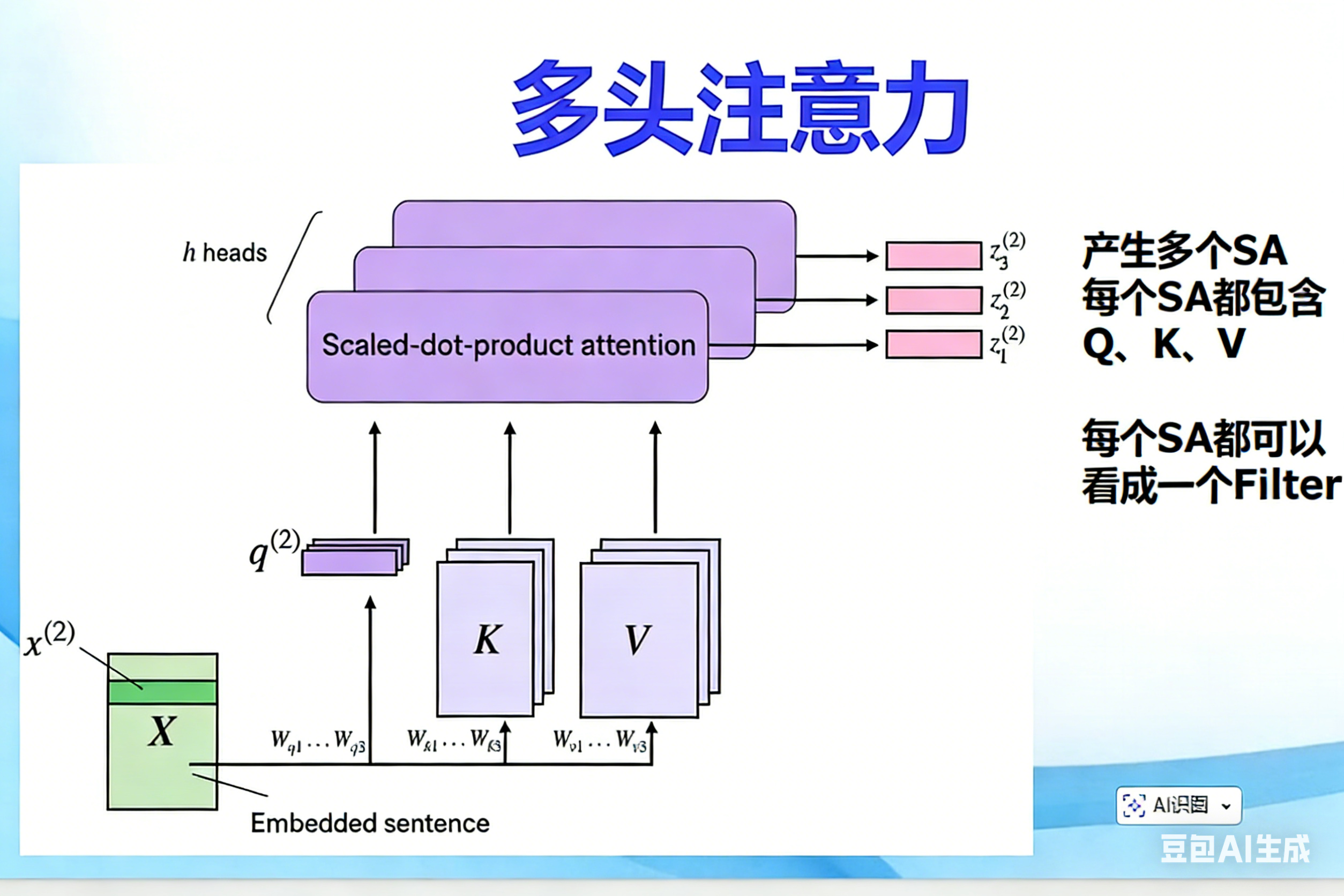
二、逐行解析多头注意力核心类:MultiHeadAttentionWrapper
-
__init__方法:nn.ModuleList:PyTorch 专门存放多个 Module 的容器(和普通 list 的区别:会被 PyTorch 识别为模型参数,训练时自动更新其中的权重);num_heads=4:创建 4 个独立的SelfAttention实例(4 个头),每个头有自己专属的 W_query/W_key/W_value(初始化时随机,训练时独立更新)。
-
forward方法:- 每个头独立处理输入
x(词嵌入向量 6×3),输出各自的上下文向量(每个头输出都是 6×4,和单头一致); torch.cat(..., dim=-1):在最后一维(特征维度) 拼接结果(保留 "词的数量(6)",只拼接特征)。
- 每个头独立处理输入
python
class MultiHeadAttentionWrapper(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v, num_heads):
super().__init__()
# 核心1:创建num_heads个独立的SelfAttention实例(每个头都是独立的单头注意力)
self.heads = nn.ModuleList(
[SelfAttention(d_in, d_out_kq, d_out_v)
for _ in range(num_heads)]
)
def forward(self, x):
# 核心2:让每个头独立处理输入x,得到各自的上下文向量
head_outputs = [head(x) for head in self.heads]
# 核心3:在最后一维(特征维度)拼接所有头的输出
return torch.cat(head_outputs, dim=-1)
python
def forward(self, x):
# 1. 每个头独立处理完整输入x(6×3的词嵌入),得到各自的输出
# 比如num_heads=4时,会生成4个结果:[6×4, 6×4, 6×4, 6×4]
head_outputs = [head(x) for head in self.heads]
# 2. 拼接:在最后一维(特征维度,dim=-1)拼接,不是拼接"词"
# 6×4 + 6×4 + 6×4 + 6×4 → 6×16(词数还是6,特征维度从4→16)
return torch.cat(head_outputs, dim=-1)