标题:Back to Newton's Laws: Learning Vision-based Agile Flight via Differentiable Physics
作者:Yuang Zhang†, Yu Hu†, Yunlong Song†, Danping Zou∗, Weiyao Lin∗
单位:上海交通大学
发表:2024(arXiv:2407.10648v2)
论文链接:https://arxiv.org/pdf/2407.10648v2
视频演示链接:https://youtu.be/LKg9hJqc2cc
关键词:视觉化飞行,空中机器人,可微物理,群体导航,无里程计飞行,高速避障,低成本硬件部署
一、研究背景与领域痛点
1.1 无人机导航的核心需求与挑战
现代空中机器人需在动态、未知环境中执行复杂任务,从森林搜救、电力巡检到物资配送,均要求其在有限传感与计算资源下实现高速、稳健的自主导航。然而,现有方法在鲁棒性、灵活性与可扩展性上存在明显短板:
- 高动态场景适配难:高速飞行时(如超过 10 m/s),传统定位与地图构建易出现帧间特征匹配失效,导致状态估计漂移。
- 多智能体协作成本高:现有群体导航多依赖通信或集中式规划,在无信号、高干扰环境(如深山、废墟)中难以部署。
- 硬件与计算门槛高:主流方案依赖 GPU 或高精度传感器(如 UWB 定位),硬件成本常超过 400 美元,限制大规模应用。
1.2 现有方法的局限性
当前无人机导航技术主要分为两类,均存在难以克服的缺陷:
(1)传统映射规划方法
这类方法将导航拆解为定位→建图→规划→控制四个串联步骤,典型代表如 Ego-Planner、Fast-Planner。
- 优势:在低速、结构化环境中(如实验室)精度高,已应用于火星探测、森林巡检等场景。
- 缺陷:
- ** latency 累积 **:串联流程导致端到端延迟高,高速飞行时(>5 m/s)易因 "感知 - 决策 - 控制" 脱节引发碰撞。
- 计算成本高:建图(如 ESDF 地图)与定位(如 VIO)占用大量 CPU/GPU 资源,Ego-v2 系统中定位模块的 CPU 占用甚至超过其他模块总和。
- 动态环境适配差:地图更新速度无法跟上障碍物运动(如突然出现的行人、摆动的树枝),易出现规划失效。
(2)基于学习的方法
这类方法通过数据驱动学习端到端策略,主要分为强化学习(RL)与模仿学习(IL):
- 强化学习 :如基于 PPO 的无人机竞速方法,通过大量轨迹采样优化策略。
- 缺陷:样本效率极低,需数十万次仿真迭代,且对复杂视觉输入(如深度图)的处理能力弱。
- 模仿学习 :如 Agile 方法,通过专家轨迹(如最优控制器生成)训练模型,直接映射深度图到控制指令。
- 缺陷:
- 泛化性差:依赖专家演示的质量与覆盖度,在未训练过的环境(如从森林切换到城市)中成功率骤降。
- 灵活性低:专家策略针对特定任务设计(如固定速度避障),无法自适应调整速度或应对群体协作需求。
- 硬件依赖:需 GPU 加速推理,硬件成本高,难以部署在微型无人机上。
- 缺陷:
1.3 研究核心突破点
本文提出 "可微物理驱动的端到端学习" 范式,核心思路是:不将物理模型视为 "黑盒",而是通过可微仿真将牛顿力学规律融入策略优化,直接从视觉输入(深度图)输出控制指令。这一范式解决了三大关键问题:
- 效率:利用物理梯度实现一阶优化,样本效率比 RL 高 10 倍,训练时间从数天缩短至小时级。
- 泛化性:基于简单点质量模型与抽象障碍物训练,却能零样本迁移到真实森林、城市环境。
- 低成本:策略可在 21 美元的 ARM 电脑(Mango Pi)上实时运行,硬件成本仅为现有方案的 5%。
二、核心方法:可微物理与端到端策略设计
核心架构围绕 "可微物理仿真→物理驱动损失函数→时序梯度衰减→轻量化网络" 四个模块展开,实现从视觉感知到控制输出的端到端优化。
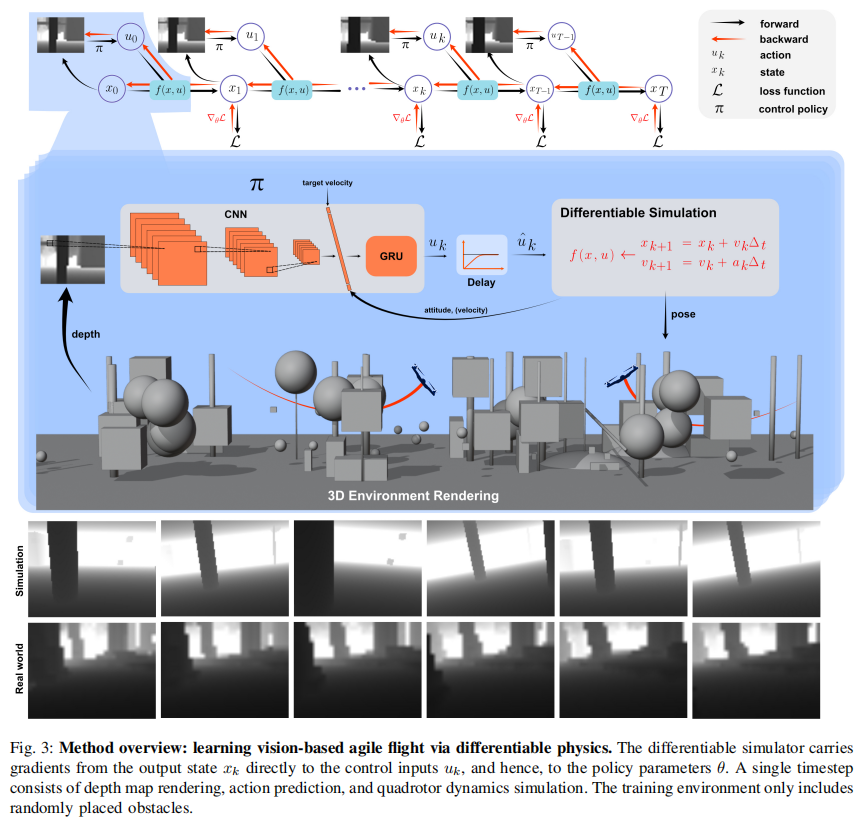
2.1 问题建模:导航即优化问题
首先将无人机导航抽象为离散时间动态系统优化问题,定义关键变量与目标:
- 状态空间 :
,其中
- 控制输入 :
- 观测输入 :
- 策略模型 :神经网络
- 优化目标 :最小化总损失
2.2 可微物理仿真:连接物理与学习的核心
传统仿真(如 MuJoCo、Flightmare)仅能输出状态轨迹,无法计算梯度;而可微仿真可直接将损失梯度从输出状态 反向传播至控制输入
,进而更新策略参数
。这是本文方法的核心创新。
(1)简化物理模型:点质量模型
为平衡仿真效率与真实性,论文未采用复杂的四旋翼刚体模型,而是用点质量模型近似无人机动力学:
-
速度更新(梯形积分):
-
位置更新(匀加速运动):
-
关键设计理由:
- 高效梯度计算 :点质量模型的雅可比矩阵(
- 鲁棒泛化:忽略复杂的姿态动力学细节(如电机延迟、陀螺效应),反而降低仿真与现实的 "域 gap",实现零样本迁移。
- 硬件适配:简单模型的推理速度快,可在低性能 ARM 芯片上实时运行(15 FPS 以上)。
- 高效梯度计算 :点质量模型的雅可比矩阵(
(2)真实物理效应建模
为提升仿真真实性,论文补充了两项关键物理效应:
- 飞行控制器延迟 :四旋翼的电机响应存在延迟(约 1/15 s),论文用指数移动平均建模:
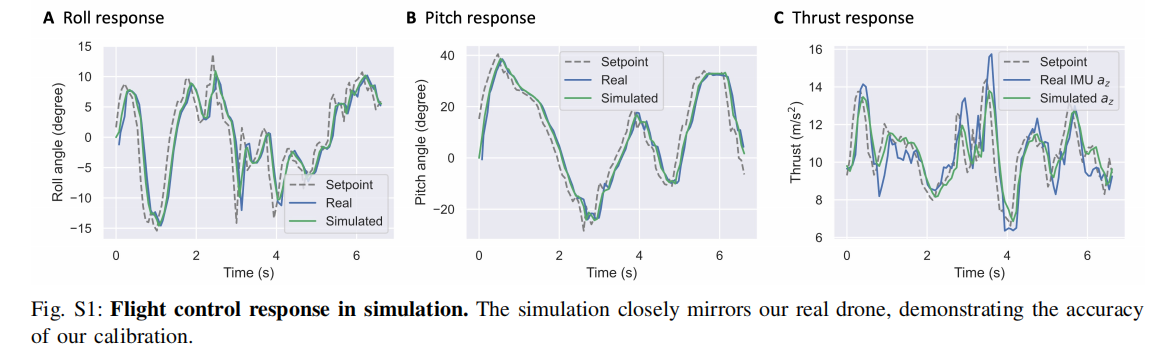
注:(A)滚转响应、(B)俯仰响应、(C)推力响应:仿真曲线与真实无人机响应高度吻合,验证延迟模型的准确性。
2. 空气阻力 :高速飞行时(>9 m/s)空气阻力不可忽略,论文用二次阻力模型:其中
(二次项系数)与
(一次项系数)通过网格搜索校准,确保仿真速度与真实飞行误差 < 0.5 m/s(如图 S2)。
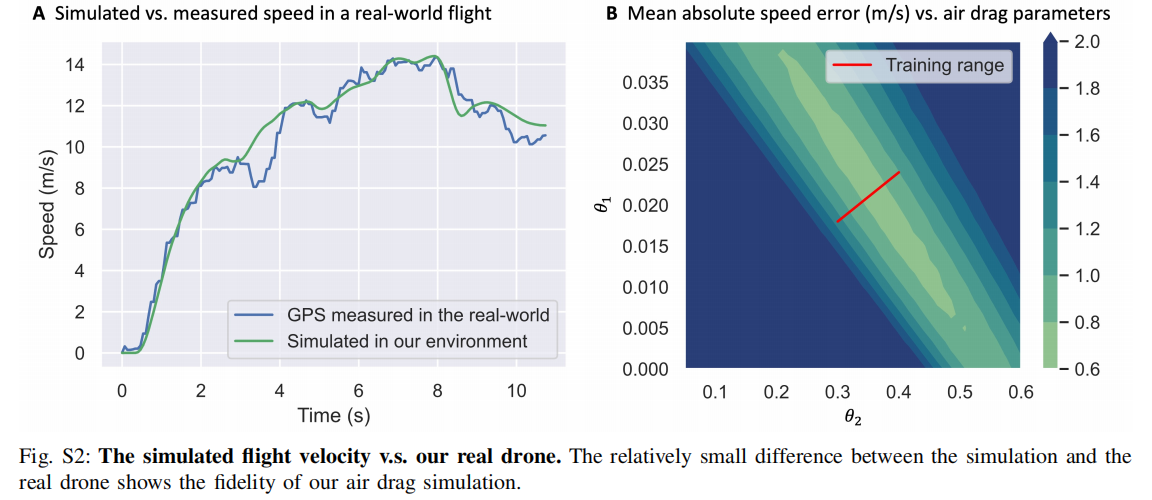
注:(A)仿真速度与真实 GPS 速度对比;(B)不同阻力参数下的速度误差,红色区域为训练时采用的参数范围,确保鲁棒性。
2.3 物理驱动损失函数:引导策略学习
损失函数设计直接决定策略的行为偏好,论文提出由四部分组成的物理驱动损失,无需人工设计协作奖励或任务特定权重:
(1)速度跟踪损失
确保无人机在避障的同时,跟踪目标速度(由当前位置与目标位置的方向决定):其中
是 2 秒滑动窗口内的平均速度,避免瞬时速度波动导致的控制震荡;
是目标速度(大小不超过预设最大值,如 20 m/s)。
(2)避障损失
基于无人机与障碍物的最近距离 和接近速度
(沿障碍物方向的速度分量),设计分段惩罚:
- 关键逻辑:
- 当无人机远离障碍物(
- 当无人机接近障碍物(
- 参数设置:
- 当无人机远离障碍物(
(3)控制平滑损失
避免控制指令剧烈波动导致无人机失稳:
- 加速度平滑:
- 加加速度(Jerk)平滑:
(4)总损失加权
最终损失为四部分的加权和,兼顾速度、安全与控制稳定性:参数设置:
,
(优先保证避障安全),
,
(弱平滑约束,避免过度保守)。
2.4 时序梯度衰减:解决梯度爆炸问题
可微仿真的核心挑战是梯度爆炸:当梯度沿时间步反向传播时,远距离未来帧的梯度会累积放大(如 10 步后梯度可能扩大 10 倍),导致优化不稳定(如图 4A、B)。
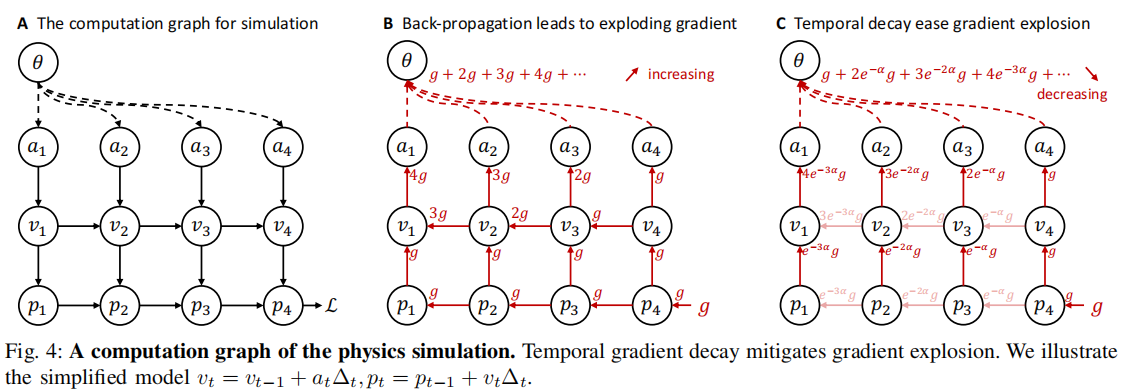
注:(A)仿真计算图:状态沿时间步传递;(B)无衰减时梯度累积(),导致爆炸;(C)有衰减时梯度逐步减小(
),优化稳定。
(1)问题本质
无人机的感知范围有限(深度相机有效距离约 5-10 m),但未衰减的梯度会强制模型 "预测并避开" 10 秒后才会遇到的障碍物 ------ 这既超出感知能力,又引入不必要的优化噪声。
(2)解决方案:指数梯度衰减
在反向传播时,对状态转移的雅可比矩阵乘以指数衰减因子 ,其中
(衰减率),
(时间步)。修改后的策略梯度为:
- 效果 :
- 梯度随时间步呈指数衰减,10 步后梯度幅度降低至初始值的 30% 以下,避免爆炸。
- 强制模型聚焦 "近未来"(1-2 秒内)的障碍物,与深度相机的感知范围对齐(如图 4C、S3)。
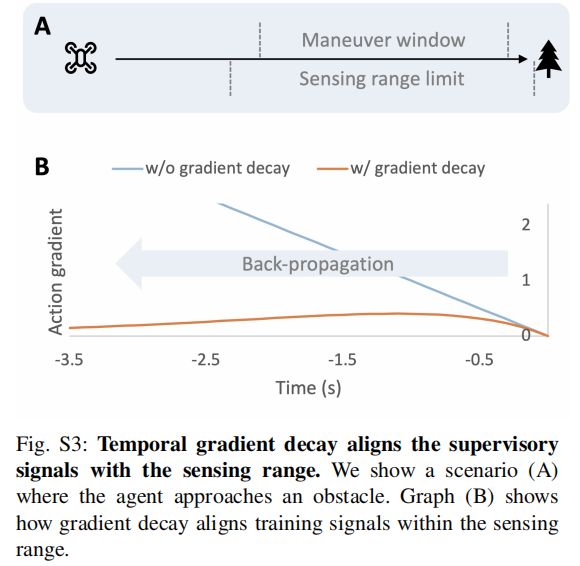
注:(A)无人机接近障碍物的场景,感知范围(虚线)约 5 m;(B)无衰减梯度(蓝色)持续增大,超出感知范围;有衰减梯度(橙色)先升后降,与感知范围匹配。
2.5 轻量化网络架构:适配低成本硬件
为在 21 美元的 Mango Pi(1.5GHz A53 CPU,1GB RAM)上实时运行,论文设计了卷积循环神经网络(CRNN),兼顾特征提取与时序记忆:
(1)输入处理
- 深度图:将 640×480 原始深度图反转(障碍物区域为高值)后下采样至 16×12,减少计算量。
- 辅助信息:将目标速度、姿态角线性投影为 192 维特征,与图像特征拼接(可选加入速度估计,用于无里程计场景)。
(2)网络结构
- 卷积层:3 层轻量级 CNN(滤波器数量 32→64→128,核大小 2→3→3),步长 1,LeakyReLU 激活,提取深度图中的障碍物特征。
- 全连接层:将 CNN 输出展平后投影为 192 维特征,与辅助信息特征拼接。
- GRU 层:1 层 GRU(隐藏层维度 192),建模时序依赖(如障碍物运动趋势、无人机历史速度)。
- 输出层 :全连接层输出两个结果 ------ 期望推力加速度
- 推理效率:单帧推理时间约 6.7 ms(15 FPS),CPU 占用率 < 30%,远低于模仿学习方法(如 Agile 需 20 ms/GPU)。
2.6 硬件系统:低成本、高敏捷性
论文设计的四旋翼硬件总重仅 365 g,成本控制在 200 美元以内(核心计算模块仅 21 美元),具体配置如下:
- 机架与动力:Roma 3 英寸机架,GEMFAN 3 英寸螺旋桨,1606 3750KV 电机,推力重量比 3.6(支持高速机动)。
- 飞行控制:Aocoda F7mini 飞控(定制 BetaFlight 固件),HAKRC 4in1 电调(支持高速电机响应)。
- 感知模块:Intel RealSense D435i 深度相机(15 FPS,有效距离 0.1-10 m)。
- 计算模块:Mango Pi 微型电脑(Cortex-A53 CPU,30×65×6 mm,11 g),集成在机身中层,形成 "3 层飞行塔" 结构(飞控→计算模块→相机)。
三、实验验证:性能与泛化性全面评估
论文通过真实环境测试 与仿真基准对比,从高速飞行、群体导航、无里程计飞行、硬件效率四个维度验证方法的优越性。实验设置与核心结果如下:
3.1 实验基础设置
- 数据集与仿真环境 :
- 训练集:自定义 CUDA 仿真环境,含平面、立方体、球体、圆柱体四种抽象障碍物,随机生成位置与尺寸,64 个环境并行训练。
- 测试集:
- 真实环境: dense 森林、城市公园、室内动态场景(含摆动门、移动障碍物)。
- 仿真环境:Flightmare、AirSim,与 Ego-v2(传统方法)、Agile(模仿学习)、PPO(强化学习)对比。
- 评价指标 :
- 成功率:无碰撞到达目标区域(半径 1.2-5 m)的试验比例。
- 飞行速度:GPS(室外)或动捕系统(室内)测量的平均速度与峰值速度。
- 推理时间:单帧从输入到控制输出的耗时(硬件:Mango Pi/A100 GPU)。
3.2 关键实验结果
实验 1:复杂动态环境下的高速飞行
任务:无人机在真实森林、城市公园中,以 4-20 m/s 的目标速度避障,同时应对动态障碍物(如摆动的树枝、移动的轮子、关闭的门)。
结果(如图 5):

- 成功率:在静态环境中(如森林、城市),目标速度 20 m/s 时成功率仍达 90%;动态环境中(如移动障碍物),成功率保持 80% 以上。
- 飞行速度:森林中峰值速度达 20 m/s,是现有模仿学习方法(Agile,10 m/s)的 2 倍。
- 泛化性:训练时仅用抽象障碍物,却能零样本迁移到真实场景,未见过的动态障碍物(如突然摆动的门)也能成功避开。
实验 2:无通信的群体自组织导航
任务:6 架无人机分为两组,从狭窄门的两侧出发,交换位置且无碰撞,不依赖任何通信或集中式规划(如图 6)。
结果:
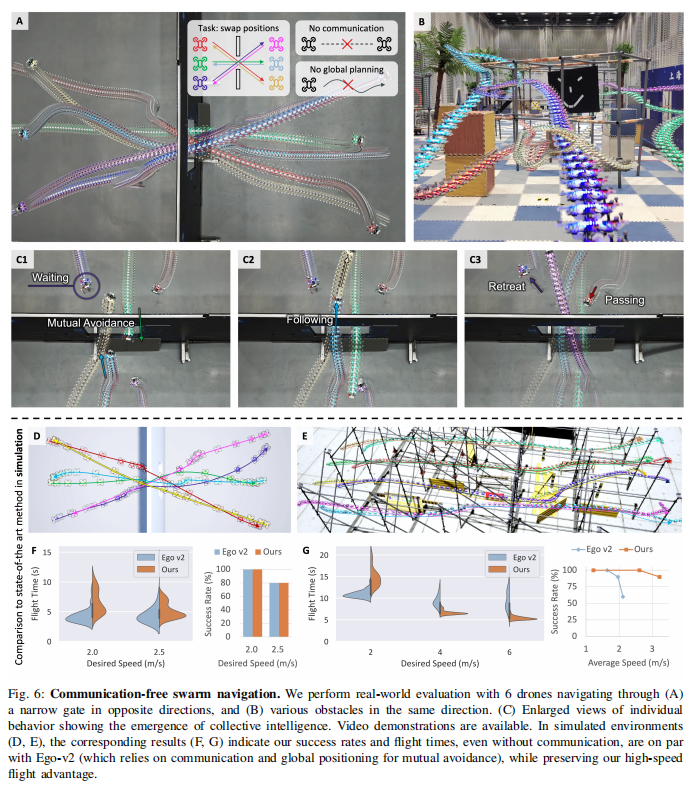
-
成功率:10 次试验全部成功,无人机自主实现 "等待 - 跟随 - 避让" 的自组织行为(如图 6C):
- 等待:当门被占用时,后到达的无人机悬停等待。
- 跟随:形成单队列依次通过门,避免拥堵。
- 避让:对向飞行时,主动后退给对方让路。
-
与传统方法对比:与依赖 UWB 通信的 Ego-v2 相比,成功率(100% vs 95%)与任务完成时间(25 s vs 28 s)相当,但无需通信与全局定位。
-
关键发现:群体协作行为并非人工设计,而是通过最小化个体避障损失自然涌现 ------ 无人机将其他无人机视为移动障碍物,通过避障损失实现自发协调。
实验 3:无里程计(Odometry-free)飞行
任务:移除外部定位输入(如 VICON、VIO),仅用深度图与姿态角,测试无人机在 4-10 m/s 目标速度下的避障能力(如图 7)。
结果:
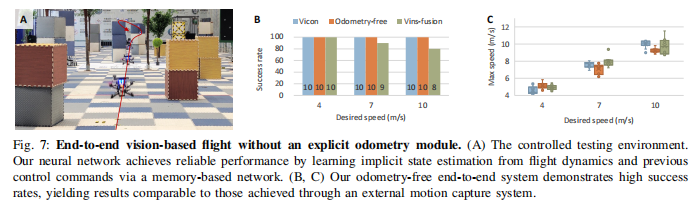
-
成功率:无里程计的无人机与使用 VICON 动捕的无人机成功率持平(90% 以上),远高于依赖 VIO 的无人机(60%,高速时 VIO 漂移导致碰撞)。
-
速度稳定性:平均速度与目标速度偏差 < 0.5 m/s,证明 GRU 网络能通过历史控制与视觉信息隐式估计速度。
-
意义:首次实现无需独立里程计模块的高速视觉导航,解决了传统方法中 VIO 高速失效的痛点,同时降低硬件成本(省去 VIO 传感器)。
实验 4:与主流方法的基准对比
任务:在仿真环境(Flightmare/AirSim)中,与传统方法(Ego-v2)、模仿学习(Agile)、强化学习(PPO)对比成功率、收敛速度与样本效率。
结果(如图 8):
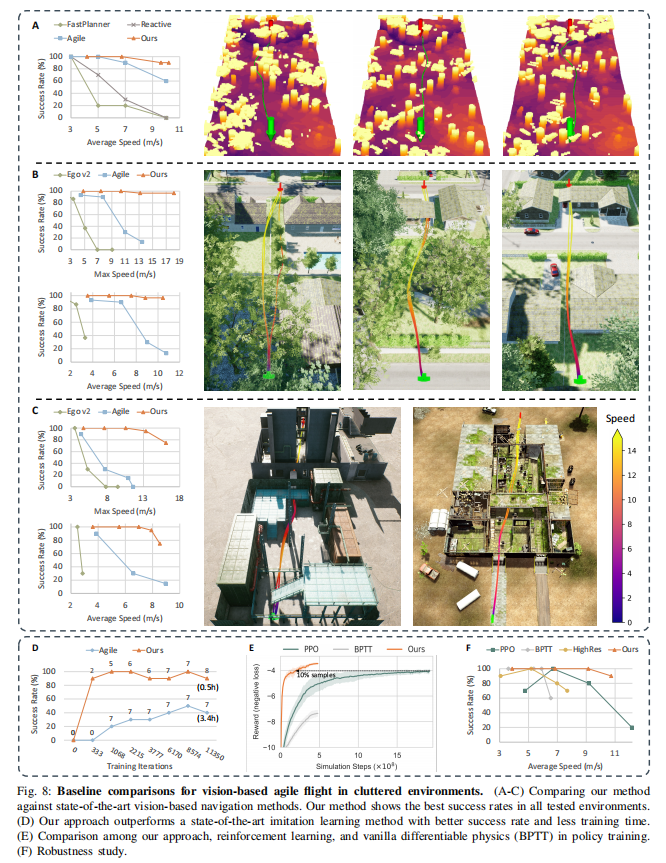
- 成功率:目标速度 20 m/s 时,本文方法成功率 90%,Ego-v2 为 10%,Agile 为 40%,PPO 为 30%(如图 8A-C、F)。
- 收敛速度:训练 1k 迭代时,本文方法成功率达 100%,Agile 仅 20%(如图 8D)。
- 样本效率:达到最大奖励所需样本量仅为 PPO 的 10%(如图 8E),因可微物理的一阶梯度比 RL 的零阶估计更高效。
- 硬件效率:Mango Pi 上推理时间 6.7 ms,Agile 需 GPU(20 ms),Ego-v2 需 CPU(50 ms)。
3.3 消融实验:关键组件的必要性
论文通过消融实验验证核心设计的作用:
(1)时序梯度衰减的影响
- 无衰减(BPTT):训练不稳定,目标速度 10 m/s 时成功率仅 40%,远低于有衰减的 90%。
- 结论:梯度衰减是避免优化爆炸、保证高速飞行稳定性的关键。
(2)输入分辨率的影响
- 高分辨率(128×96):训练时成功率高,但测试时因真实深度图噪声,成功率降至 70%(过拟合)。
- 低分辨率(16×12):训练时成功率略低,但测试时鲁棒性强,成功率保持 90%。
- 结论:低分辨率输入能缩小仿真与现实的 "感知 gap",提升泛化性。
(3)物理模型简化的影响
- 刚体模型(复杂):梯度计算耗时增加 3 倍,训练时间从 4 天增至 12 天,且仿真与现实 gap 更大,成功率降至 75%。
- 点质量模型(简单):训练高效,成功率 90%。
- 结论:简单物理模型反而能更好地平衡效率与泛化性,无需追求高保真仿真。
3.4 方法局限性
尽管性能优异,本文方法仍存在两点不足:
- 极端遮挡鲁棒性:当无人机快速运动导致大面积遮挡(如旋转时机身挡住相机),深度图缺失关键区域,可能出现 "幻觉" 避障(如误判空白区域为障碍物)。
- 长距离导航精度:无里程计场景下,长期飞行(>100 m)会因速度估计累积误差,导致目标位置偏移(误差约 5-10%)。
四、总结与未来方向
4.1 核心贡献
- 范式创新:提出 "可微物理驱动学习" 范式,将牛顿力学与深度学习结合,解决了传统方法 latency 高、学习方法样本效率低的问题。
- 性能突破 :
- 速度:真实森林中 20 m/s 高速飞行,是现有方案的 2 倍。
- 群体:无通信自组织导航,实现 "等待 - 避让" 自发行为。
- 泛化:零样本从仿真迁移到真实场景,动态障碍物适应能力强。
- 工程价值 :
- 低成本:21 美元计算模块,硬件成本仅为现有方案的 5%。
- 低依赖:无需 GPS/VIO/ 通信,适用于无基础设施的极端环境。
4.2 未来研究方向
- 多模态感知融合:加入视觉惯性数据(IMU),提升极端遮挡场景下的鲁棒性。
- 任务自适应策略:扩展损失函数,支持更复杂任务(如目标跟踪、编队飞行)。
- 更大规模群体:探索 10 架以上无人机的协作,优化群体行为的效率(如减少等待时间)。
- 能量优化:在损失函数中加入能耗项,延长无人机续航时间(尤其适用于巡检、搜救任务)。