Kubernetes相关工具介绍对比如下
Kubernetes 已成为编排容器化应用的事实标准。随着组织越来越多地采用云原生架构,确保可观测性、安全性、策略实施、渐进式交付和自动扩展,就像确保飞船在发射进入广阔的生产环境之前拥有足够的燃料、氧气和备用计划一样重要。
随着多云和混合云环境的兴起,Kubernetes 的可观测性和控制机制必须像变色龙一样适应性强,像你最喜欢的 meme 股票一样可扩展,并且像真正的 DevOps 专家一样与技术无关。无论你是在 AWS、Azure、GCP 还是本地 Kubernetes 集群上管理工作负载,拥有强大的工具生态系统都不是一种奢侈,而是监控应用、实施安全策略、自动化部署和优化性能的生存工具包。
在本文中,我们将深入探讨一些最强大的Kubernetes 原生工具,它们将可观测性、安全性和自动化从令人望而生畏的挑战转变为强大的推动力。我们将探索以下工具:
-
追踪与可观测性:Jaeger、Prometheus、Thanos、Grafana Loki
-
策略实施:OPA、Kyverno
-
渐进式交付:Flagger、Argo Rollouts
-
安全与监控:Falco、Tetragon、Datadog Kubernetes Agent
-
自动扩展:Keda
-
网络与服务网格:Istio、Linkerd
-
部署验证与 SLO 监控:Keptn
准备好你的 Kubernetes 控制面板,调整监控仪表盘,让我们一起探索 Kubernetes 可观测性和可靠性的狂野、美妙又有时古怪的世界!
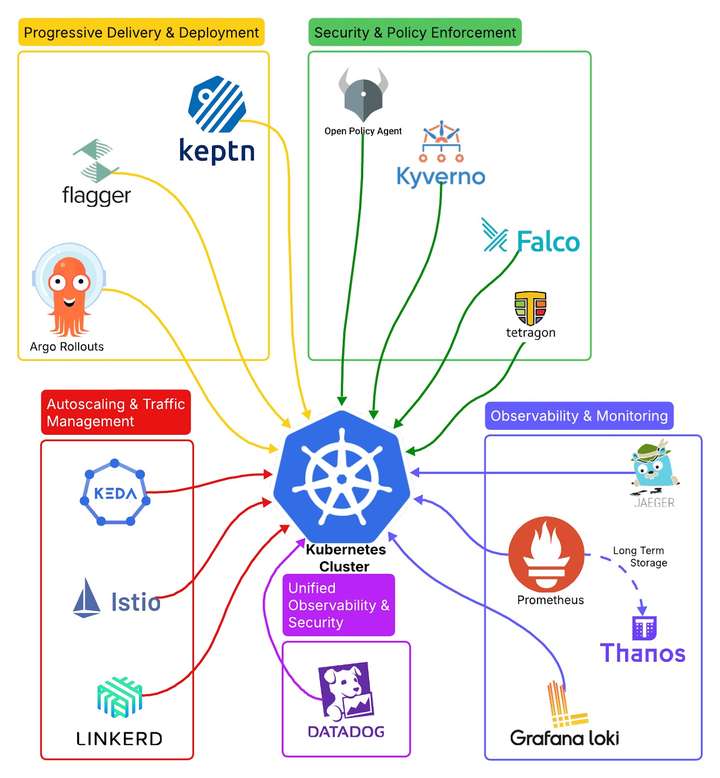
用于可观测性、安全性、部署和扩缩容的 Kubernetes 工具
该图展示了 Kubernetes 在可观测性、安全性、部署和扩展方面的关键工具。每个类别突出了如 Prometheus、OPA、Flagger 和 Keda 等工具,以提升可靠性和性能。
为什么这些工具在多云 Kubernetes 世界中至关重要
Kubernetes 是一个高度动态的系统,管理着数千个微服务,根据需求扩展资源,并在不同云提供商之间协调部署。Kubernetes 的复杂性需要一个全面的可观测性和控制策略,以确保应用健康、安全性和合规性。
可观测性:理解系统行为
没有适当的监控和追踪,识别瓶颈、调试问题和优化性能将变得困难。Jaeger、Prometheus、Thanos 和 Grafana Loki 等工具为分布式应用提供了完整的可见性,确保每个微服务交互都被追踪、记录和分析。
策略实施:增强安全性与合规性
随着 Kubernetes 集群的增长,管理安全策略和治理变得至关重要。OPA 和 Kyverno 等工具允许组织实施细粒度的策略,确保只有合规的配置和访问控制被部署到集群中。
渐进式交付:降低部署风险
现代 DevOps 和 GitOps 实践依赖于安全、增量式的发布。Flagger 和 Argo Rollouts 自动化金丝雀部署、蓝绿发布和 A/B 测试,确保新版本的应用在无停机或重大中断的情况下推出。
安全与监控:实时检测威胁
Kubernetes 工作负载是动态的,因此安全性是一个持续的过程。Falco、Tetragon 和 Datadog Kubernetes Agent 监控运行时行为,检测异常,并通过提供对容器和节点级别活动的深度可见性来防止安全漏洞。
自动扩展:优化资源利用率
Kubernetes 提供了内置的 Horizontal Pod Autoscaling (HPA),但许多工作负载需要基于事件的扩展,而不仅仅是 CPU 和内存阈值。Keda 支持基于实时事件(如队列长度、消息代理和自定义业务指标)的扩展。
网络与服务网格:管理微服务通信
在大规模微服务架构中,网络流量管理至关重要。Istio 和 Linkerd 提供服务网格功能,确保微服务之间的通信安全、可靠且可观测,同时优化网络性能。
部署验证与 SLO 监控:确保可靠发布
Keptn 自动化部署验证,确保应用在发布到生产环境之前满足服务级别目标 (SLO)。这有助于在云原生环境中保持稳定性和提高可靠性。
关键工具对比
虽然每个工具都有其独特用途,但某些功能存在重叠。以下是一些关键工具的对比:
| 类别 | 工具 1 | 工具 2 | 主要区别 |
|---|---|---|---|
| 追踪与可观测性 | Jaeger | Tracestore | Jaeger 在追踪领域广泛采用,而 Tracestore 是一个新兴替代方案。 |
| 策略实施 | OPA | Kyverno | OPA 使用 Rego,而 Kyverno 提供基于 Kubernetes 原生 CRD 的策略。 |
| 渐进式交付 | Flagger | Argo Rollouts | Flagger 与服务网格集成良好,Argo Rollouts 则针对 GitOps 工作流优化。 |
| 安全监控 | Falco | Tetragon | Falco 专注于运行时安全警报,而 Tetragon 扩展了基于 eBPF 的监控。 |
| 网络与服务网格 | Istio | Linkerd | Istio 提供更高级的功能但复杂,Linkerd 更简单轻量。 |
一、追踪与可观测性
- 使用 Jaeger 实现追踪与可观测性
什么是 Jaeger?
Jaeger 是一个开源的分布式追踪系统,旨在帮助 Kubernetes 用户监控和排查微服务架构中的事务。最初由 Uber 开发,它已成为端到端请求追踪的广泛采用方案。
为什么在 Kubernetes 中使用 Jaeger?
-
分布式追踪:提供跨多个微服务的请求流可见性。
-
性能瓶颈检测:帮助识别慢速服务交互和依赖关系。
-
根因分析:支持调试延迟问题和故障。
-
无缝集成:与 Prometheus、OpenTelemetry 和 Grafana 良好协作。
-
多云就绪:可部署在 AWS、Azure 和 GCP 的 Kubernetes 集群上,实现全球可观测性。
对比:Jaeger vs. Tracestore
| 特性 | Jaeger | Tracestore |
|---|---|---|
| 采用情况 | 在 Kubernetes 环境中广泛采用 | 新兴解决方案 |
| 开源 | 是 | 可用信息有限 |
| 集成 | 支持 OpenTelemetry、Prometheus 和 Grafana | 集成支持较少 |
| 用例 | 分布式追踪、根因分析 | 类似用例但验证较少 |
Jaeger 是大多数 Kubernetes 用户的首选,因为它拥有成熟的生态系统、活跃的社区和强大的集成能力。
Jaeger 在多云环境中的应用
Jaeger 可以通过以下方式部署在多集群和多云环境中:
-
将 Jaeger 部署为 Kubernetes 服务,追踪跨微服务的事务。
-
使用 OpenTelemetry 进行追踪,并将追踪数据发送到 Jaeger 进行分析。
-
将追踪数据存储在分布式存储解决方案(如 Elasticsearch 或 Cassandra)中以实现可扩展性。
-
与 Grafana 集成,将追踪数据与 Kubernetes 指标一起可视化。
简而言之,Jaeger 是现代云原生架构中可观测性和调试的必备工具。无论是在本地还是跨多个云提供商的 Kubernetes 工作负载中运行,它都为分布式追踪和性能监控提供了强大的解决方案。
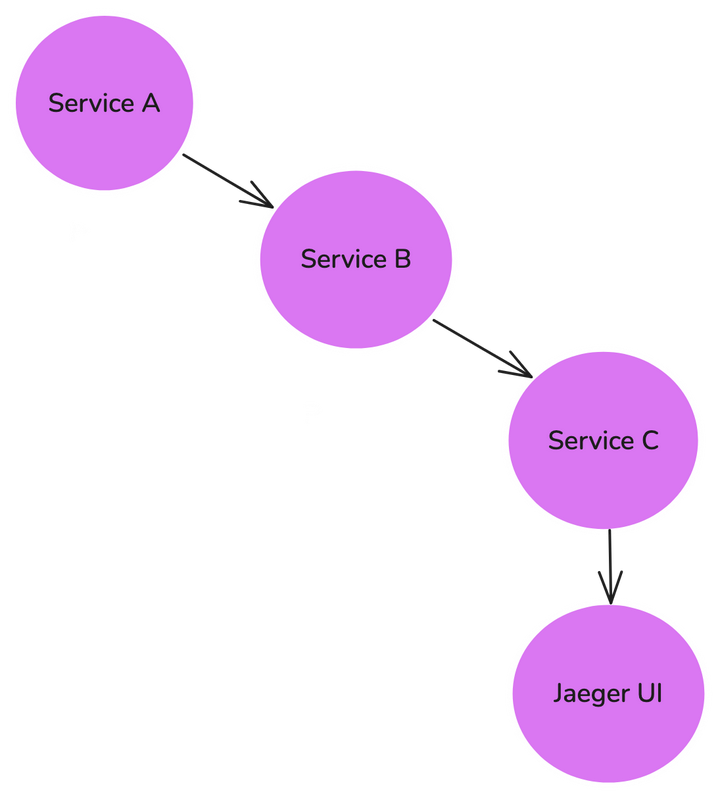
Jaeger tracing the flow of requests across multiple services
该图展示了 Jaeger 如何追踪跨多个服务(如 Service A → Service B → Service C)的请求流。Jaeger UI 可视化追踪数据,帮助开发者分析微服务架构中的延迟问题、瓶颈和请求路径。
- 使用 Prometheus 实现可观测性
什么是 Prometheus?
Prometheus 是一个开源的监控和告警工具包,专为云原生环境设计。作为云原生计算基金会 (CNCF) 的一部分,它已成为 Kubernetes 的默认监控解决方案,因其可靠性、可扩展性和与容器化应用的深度集成而闻名。
为什么在 Kubernetes 中使用 Prometheus?
-
时间序列监控:以时间序列格式捕获指标,支持历史分析。
-
强大的查询语言 (PromQL):允许用户高效地过滤、聚合和分析指标。
-
可扩展性:能够处理大型 Kubernetes 集群中的海量工作负载。
-
多云部署:可部署在 AWS、Azure 和 GCP 的 Kubernetes 集群上,实现统一的可观测性。
-
与 Grafana 集成:提供实时仪表盘和可视化。
-
告警机制:与 Alertmanager 协作,通知团队关键问题。
Prometheus 在 Kubernetes 中的工作原理
Prometheus 从 Kubernetes 集群中的多个来源抓取指标,包括:
-
Kubernetes API Server:获取节点和 Pod 指标。
-
应用端点:暴露 Prometheus 格式的指标。
-
Node Exporters:提供主机级系统指标。
-
自定义指标导出器:提供应用特定的洞察。
Prometheus 在多云环境中的应用
Prometheus 通过以下方式支持多云可观测性:
-
在每个集群部署 Prometheus 实例,收集和存储本地指标。
-
使用 Thanos 或 Cortex 进行长期存储,支持跨多个集群的集中查询。
-
与 Grafana 集成,在单一仪表盘中可视化来自不同云提供商的数据。
-
利用 Alertmanager,根据云特定策略动态路由告警。
简而言之,Prometheus 是 Kubernetes 的首选监控解决方案,为容器化工作负载提供了强大的可观测性。当与 Grafana、Thanos 和 Alertmanager 结合使用时,它形成了一个全面的监控堆栈,适用于单集群和多云环境。
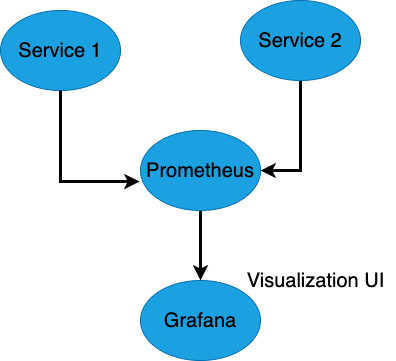
Prometheus scrapes metrics from multiple services
该图展示了 Prometheus 如何从多个服务(如 Service 1 和 Service 2)抓取指标,并将收集的数据发送到 Grafana 进行可视化。Grafana 作为用户界面,在仪表盘中显示指标,用于实时监控和告警。
- 使用 Thanos 实现长期指标存储
什么是 Thanos?
Thanos 是一个开源系统,旨在通过提供长期指标存储、高可用性和跨多集群的联合查询来扩展 Prometheus 的能力。它确保监控数据长期保留,同时支持对分布式 Prometheus 实例的集中查询。
为什么在 Kubernetes 中使用 Thanos?
-
长期存储:永久保留 Prometheus 指标,克服本地存储限制。
-
高可用性:即使 Prometheus 实例故障,也能持续访问指标。
-
多云和多集群支持:支持跨 AWS、Azure 和 GCP 的 Kubernetes 集群进行联合监控。
-
查询联合:将多个 Prometheus 实例的数据聚合为单一视图。
-
经济高效的存储:支持 Amazon S3、Google Cloud Storage 和 Azure Blob Storage 等对象存储后端。
Thanos 如何与 Prometheus 协作
Thanos 通过以下组件扩展 Prometheus:
-
Sidecar:附加到 Prometheus 实例,将数据上传到对象存储。
-
Store Gateway:支持查询跨集群的存储指标。
-
Querier:提供统一的 API,跨多个 Prometheus 部署运行查询。
-
Compactor:优化和去重历史数据。
对比:Prometheus vs. Thanos
| 特性 | Prometheus | Thanos |
|---|---|---|
| 数据保留 | 有限(基于本地存储) | 在对象存储中长期保留 |
| 高可用性 | 无内置冗余 | 通过全局查询实现高可用性 |
| 多集群支持 | 单集群专注 | 多集群可观测性 |
| 查询联合 | 不支持 | 支持跨集群查询 |
简而言之,Thanos 是运行多集群和多云 Kubernetes 环境的组织对 Prometheus 的必备补充。它提供了可扩展性、可用性和长期存储,确保监控数据永不丢失,并在分布式系统中保持可访问性。
- 使用 Grafana Loki 实现日志聚合与可观测性
什么是 Grafana Loki?
Grafana Loki 是一个专为 Kubernetes 环境设计的日志聚合系统。与传统的日志管理解决方案不同,Loki 不会索引日志内容,因此具有高度可扩展性和成本效益。它与 Prometheus 和 Grafana 无缝集成,使用户能够将日志与指标关联,以便更好地排查问题。
为什么在 Kubernetes 中使用 Grafana Loki?
-
轻量高效:无需全文索引,降低了存储和处理成本。
-
可扩展性:能够处理跨多个 Kubernetes 集群的高日志量。
-
多云就绪:可部署在 AWS、Azure 和 GCP 上,支持集中式日志聚合。
-
与 Prometheus 无缝集成:允许将日志与 Prometheus 指标关联。
-
强大的查询语言 (LogQL):支持高效的日志过滤和分析。
Grafana Loki 在 Kubernetes 中的工作原理
Loki 从多个来源摄取日志,包括:
-
Promtail:一个轻量级日志代理,从 Kubernetes Pod 收集日志。
-
Fluentd/Fluent Bit:用于将日志转发到 Loki 的替代日志收集器。
-
Grafana 仪表盘:将日志与 Prometheus 指标一起可视化,实现深度可观测性。
对比:Grafana Loki vs. 传统日志管理系统
| 特性 | Grafana Loki | 传统日志系统 (ELK, Splunk) |
|---|---|---|
| 索引 | 仅索引标签(轻量级) | 全文索引(资源密集型) |
| 可扩展性 | 针对大规模集群优化 | 需要大量存储和 CPU |
| 成本 | 由于最小化索引,成本更低 | 由于索引开销,成本较高 |
| 集成 | 原生支持 Prometheus 和 Grafana | 需要额外集成 |
| 查询 | 使用 LogQL 进行高效过滤 | 使用全文搜索和查询 |
简而言之,Grafana Loki 是一个强大且轻量级的日志聚合工具,为 Kubernetes 环境提供了可扩展且经济高效的日志管理。通过与 Grafana 和 Prometheus 集成,它实现了全栈可观测性,使团队能够快速诊断问题并提高系统可靠性。
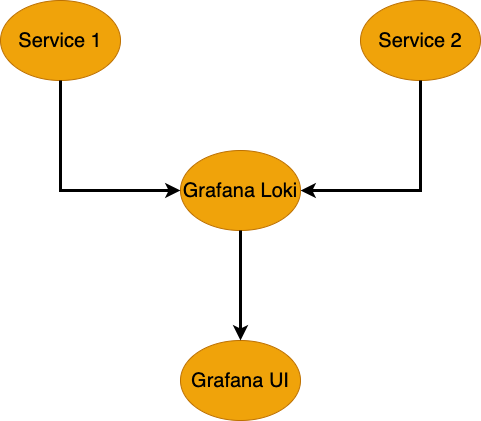
Grafana Loki collecting logs from multiple services
该图展示了 Grafana Loki 如何从多个服务(如 Service 1 和 Service 2)收集日志并将其转发到 Grafana 进行可视化。Loki 高效存储日志,而 Grafana 提供了一个直观的界面,用于分析和排查日志问题。
二. 使用 OPA 和 Kyverno 实现策略实施
什么是 OPA?
Open Policy Agent (OPA) 是一个开源的策略引擎,为 Kubernetes 工作负载提供细粒度的访问控制和治理。OPA 允许用户使用 Rego(一种声明式查询语言)定义策略,以在 Kubernetes 资源中实施规则。
为什么在 Kubernetes 中使用 OPA?
-
细粒度策略实施:在集群的各个级别实施严格的访问控制。
-
动态准入控制:在资源部署前评估和实施策略。
-
可审计性与合规性:确保 Kubernetes 配置符合合规框架。
-
与 CI/CD 流水线集成:在部署前验证 Kubernetes 清单。
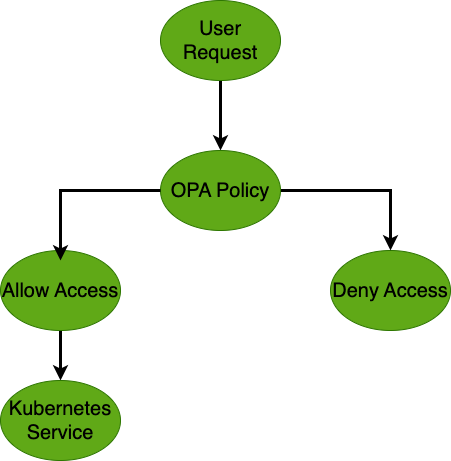
OPA handles incoming user requests by evaluating security policies
该图展示了 OPA 如何通过评估安全策略来处理传入的用户请求。请求根据这些策略被允许或拒绝。允许的请求继续到 Kubernetes 服务,确保安全的访问控制。
什么是 Kyverno?
Kyverno 是一个 Kubernetes 原生的策略管理工具,使用 Kubernetes 自定义资源定义 (CRD) 实施安全和治理规则。与需要学习 Rego 的 OPA 不同,Kyverno 允许用户使用熟悉的 Kubernetes YAML 定义策略。
为什么在 Kubernetes 中使用 Kyverno?
-
Kubernetes 原生:使用 CRD 而非单独的策略语言。
-
策略定义简单:允许管理员使用标准 Kubernetes 配置编写策略。
-
变更与验证:可以动态修改资源配置。
-
简化治理:实施安全和合规的最佳实践。
对比:OPA vs. Kyverno
| 特性 | OPA | Kyverno |
|---|---|---|
| 策略语言 | 使用 Rego(自定义查询语言) | 使用 Kubernetes 原生 YAML |
| 集成 | 支持 Kubernetes 和外部应用 | 主要用于 Kubernetes 工作负载 |
| 变更支持 | 无内置变更支持 | 支持修改配置 |
| 易用性 | 需要学习 Rego | 对 Kubernetes 管理员更简单 |
OPA 和 Kyverno 在多云环境中的应用
OPA 和 Kyverno 帮助在不同云平台部署的 Kubernetes 集群中保持一致策略:
-
OPA:适用于策略实施扩展到 Kubernetes 之外(如 API、CI/CD 流水线)的多云场景。
-
Kyverno:适合跨 AWS、Azure 和 GCP 集群的纯 Kubernetes 策略管理。
-
全局策略同步:确保所有集群遵循相同的安全和治理策略。
简而言之,OPA 和 Kyverno 都为 Kubernetes 环境提供了强大的策略实施能力,但选择取决于治理需求的复杂性。OPA 适用于跨系统的企业级策略,而 Kyverno 简化了 Kubernetes 原生的策略实施。
三. 使用 Flagger 和 Argo Rollouts 实现渐进式交付
什么是 Flagger?
Flagger 是一个渐进式交付工具,专为 Kubernetes 中的自动化金丝雀部署、蓝绿部署和 A/B 测试设计。它与 Istio、Linkerd 和 Consul 等服务网格集成,根据实时指标在不同应用版本之间动态切换流量。
为什么在 Kubernetes 中使用 Flagger?
-
自动化金丝雀部署:根据性能逐步将流量切换到新版本。
-
流量管理:与服务网格协作,动态控制路由。
-
自动化回滚:检测故障并回滚到稳定版本。
-
基于指标的决策:使用 Prometheus、Datadog 或其他可观测性工具确定发布的稳定性。
-
多云就绪:可部署在 AWS、Azure 和 GCP 的 Kubernetes 集群上。
什么是 Argo Rollouts?
Argo Rollouts 是一个 Kubernetes 控制器,用于实现渐进式交付策略,包括蓝绿部署、金丝雀发布和实验。它是 Argo 生态系统的一部分,非常适合基于 GitOps 的工作流。
为什么在 Kubernetes 中使用 Argo Rollouts?
-
GitOps 友好:与 Argo CD 无缝集成,实现声明式部署。
-
高级流量控制:与 Ingress 控制器和服务网格协作,动态切换流量。
-
功能丰富的金丝雀部署:支持细粒度控制的渐进式发布。
-
自动化分析与升级:根据关键性能指标 (KPI) 评估新版本后再全面发布。
-
多云部署:支持跨不同云提供商的全局应用发布。
对比:Flagger vs. Argo Rollouts
| 特性 | Flagger | Argo Rollouts |
|---|---|---|
| 集成 | 与服务网格(Istio、Linkerd)协作 | 与 Ingress 控制器、Argo CD 协作 |
| 部署策略 | 金丝雀、蓝绿、A/B 测试 | 金丝雀、蓝绿、实验 |
| 流量控制 | 使用服务网格进行流量切换 | 使用 Ingress 控制器和服务网格 |
| 回滚 | 基于指标的自动化回滚 | 基于分析的自动化回滚 |
| 最佳适用场景 | 基于服务网格的渐进式交付 | GitOps 工作流和功能标记 |
Flagger 和 Argo Rollouts 在多云环境中的应用
这两个工具通过确保跨 Kubernetes 集群的安全、渐进式发布来增强多云部署:
-
Flagger:在服务网格环境中表现最佳,支持跨云提供商的基于流量的渐进式部署。
-
Argo Rollouts:适合 GitOps 驱动的流水线,实现跨多云集群的声明式、策略驱动的发布。
简而言之,Flagger 和 Argo Rollouts 都提供了渐进式交付机制,确保 Kubernetes 中的安全、自动化和数据驱动的部署。选择取决于基础设施设置(服务网格 vs. Ingress 控制器)和工作流偏好(标准 Kubernetes vs. GitOps)。
四. 使用 Falco、Tetragon 和 Datadog Kubernetes Agent 实现安全与监控
什么是 Falco?
Falco 是一个开源的运行时安全工具,用于检测 Kubernetes 集群中的异常活动。它利用 Linux 内核系统调用来实时识别可疑行为。
为什么在 Kubernetes 中使用 Falco?
-
运行时威胁检测:基于内核级事件识别安全威胁。
-
合规性实施:通过监控意外系统活动确保最佳实践。
-
灵活的规则引擎:允许用户定义自定义安全策略。
-
多云就绪:支持 AWS、Azure 和 GCP 的 Kubernetes 集群。

Falco's role in monitoring Kubernetes nodes for suspicious activities
该图展示了 Falco 如何监控 Kubernetes 节点中的可疑活动。当 Falco 检测到意外行为时,会生成警报以便立即采取行动,确保 Kubernetes 环境中的运行时安全。
什么是 Tetragon?
Tetragon 是一个基于 eBPF 的安全可观测性工具,提供对 Kubernetes 中进程执行、网络活动和权限提升的深度可见性。
为什么在 Kubernetes 中使用 Tetragon?
-
高性能安全监控:使用 eBPF,开销最小。
-
进程级可观测性:追踪容器执行和系统交互。
-
实时策略实施:动态阻止恶意活动。
-
零信任环境理想选择:通过深度运行时洞察增强安全态势。
什么是 Datadog Kubernetes Agent?
Datadog Kubernetes Agent 是一个全栈监控解决方案,提供跨指标、日志和追踪的实时可观测性,并与 Kubernetes 环境无缝集成。
为什么使用 Datadog Kubernetes Agent?
-
统一可观测性:将指标、日志和追踪整合到单一平台。
-
安全监控:检测安全事件并与合规框架集成。
-
多云部署:支持 AWS、Azure 和 GCP 集群。
-
AI 驱动的告警:使用机器学习识别异常并预防事件。
对比:Falco vs. Tetragon vs. Datadog Kubernetes Agent
| 特性 | Falco | Tetragon | Datadog Kubernetes Agent |
|---|---|---|---|
| 监控重点 | 运行时安全警报 | 深度的进程级安全洞察 | 全栈可观测性和安全 |
| 技术 | 使用内核系统调用 | 使用 eBPF 实现实时洞察 | 基于代理的监控 |
| 异常检测 | 检测基于规则的安全事件 | 检测系统行为异常 | AI 驱动的异常检测 |
| 最佳适用场景 | 运行时安全和合规 | 深度取证安全分析 | 全面监控和安全 |
这些工具在多云环境中的应用
-
Falco:实时监控跨云环境的 Kubernetes 工作负载。
-
Tetragon:提供低延迟的安全洞察,适合大规模、多云 Kubernetes 部署。
-
Datadog Kubernetes Agent:为跨 AWS、Azure 和 GCP 的 Kubernetes 集群提供统一的安全和可观测性。
简而言之,这些工具在保护和监控 Kubernetes 工作负载方面各有所长。Falco 擅长实时异常检测,Tetragon 提供深度的安全可观测性,而 Datadog Kubernetes Agent 则是一个全面的监控解决方案。
五. 使用 Keda 实现自动扩展
什么是 Keda?
Kubernetes Event-Driven Autoscaling (Keda) 是一个开源的自动扩展器,使 Kubernetes 工作负载能够基于事件驱动的指标进行扩展。与传统的 Horizontal Pod Autoscaling (HPA) 不同(主要依赖 CPU 和内存使用情况),Keda 可以基于自定义指标(如队列长度、数据库连接和外部事件源)扩展应用。
为什么在 Kubernetes 中使用 Keda?
-
事件驱动扩展:支持基于外部事件源(Kafka、RabbitMQ、Prometheus 等)的扩展。
-
高效资源利用:在需求低时减少运行的 Pod 数量,降低成本。
-
多云支持:支持 AWS、Azure 和 GCP 的 Kubernetes 集群。
-
与现有 HPA 协作:扩展 Kubernetes 内置的 Horizontal Pod Autoscaler。
-
灵活的指标源:可以基于日志、消息或数据库触发器扩展应用。
Keda 在 Kubernetes 中的工作原理
Keda 由两个主要组件组成:
-
Scaler:监控外部事件源(如 Azure Service Bus、Kafka、AWS SQS),确定是否需要扩展。
-
Metrics Adapter:将基于事件的指标传递给 Kubernetes 的 HPA 以触发 Pod 扩展。
对比:Keda vs. 传统 HPA
| 特性 | 传统 HPA | Keda |
|---|---|---|
| 扩展触发条件 | CPU 和内存使用情况 | 外部事件(队列、消息、数据库等) |
| 事件驱动 | 否 | 是 |
| 自定义指标 | 支持有限 | 通过外部扩展器广泛支持 |
| 最佳适用场景 | CPU/内存密集型工作负载 | 事件驱动应用 |
Keda 在多云环境中的应用
-
AWS:基于 SQS 队列深度或 DynamoDB 负载扩展应用。
-
Azure:支持 Azure Event Hub、Service Bus 和 Functions。
-
GCP:与 Pub/Sub 集成,实现事件驱动扩展。
-
混合/多云:通过与 Prometheus、RabbitMQ 和 Redis 集成,支持跨云提供商扩展。
简而言之,Keda 是一个强大的自动扩展解决方案,扩展了 Kubernetes 的能力,使其不再局限于基于 CPU 和内存的扩展。它特别适用于微服务和事件驱动应用,是优化多云 Kubernetes 环境中工作负载的关键工具。
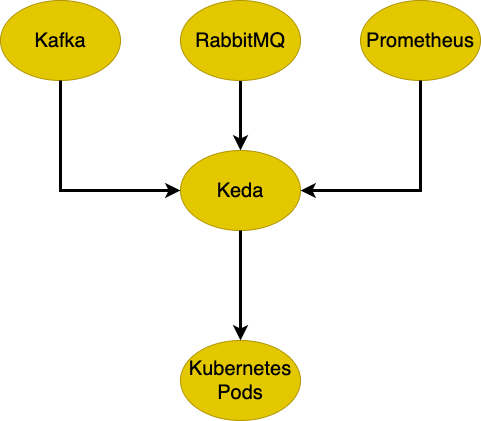
how Keda scales Kubernetes pods dynamically based on external event sources
该图展示了 Keda 如何基于外部事件源(如 Kafka、RabbitMQ 或 Prometheus)动态扩展 Kubernetes Pod。当检测到事件触发时,Keda 相应地扩展集群中的 Pod 以应对增加的负载。
六. 使用 Istio 和 Linkerd 实现网络与服务网格
什么是 Istio?
Istio 是一个强大的服务网格,为 Kubernetes 中的微服务提供流量管理、安全性和可观测性。它抽象了服务之间的网络通信,并通过负载均衡、安全策略和追踪增强了可靠性。
为什么在 Kubernetes 中使用 Istio?
-
流量管理:实现细粒度的流量路由控制,包括金丝雀部署和重试。
-
安全与认证:通过双向 TLS (mTLS) 加密实施零信任安全。
-
可观测性:与 Prometheus、Jaeger 和 Grafana 集成,实现深度监控。
-
多云和混合支持:支持 AWS、Azure 和 GCP 的 Kubernetes 集群。
-
服务发现与负载均衡:自动发现服务并高效平衡流量。
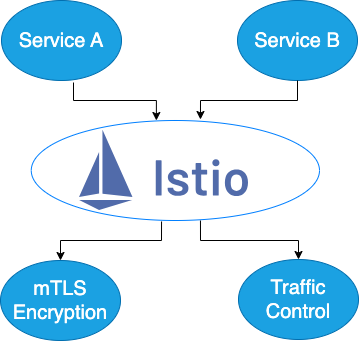
how Istio controls traffic flow between services
该图展示了 Istio 如何控制服务(如 Service A 和 Service B)之间的流量流。Istio 通过 mTLS 加密实现安全通信,并提供流量控制能力来管理 Kubernetes 集群内的服务间交互。
什么是 Linkerd?
Linkerd 是一个轻量级的服务网格,设计上比 Istio 更简单、更快,同时提供基本的网络功能。它为微服务提供自动加密、服务发现和可观测性。
为什么在 Kubernetes 中使用 Linkerd?
-
轻量简单:比 Istio 更易于部署和维护。
-
自动 mTLS:默认提供加密的服务间通信。
-
低资源消耗:比 Istio 占用更少的系统资源。
-
Kubernetes 原生集成:使用 Kubernetes 构造简化管理。
-
可靠快速:优化性能,开销最小。
对比:Istio vs. Linkerd
| 特性 | Istio | Linkerd |
|---|---|---|
| 复杂性 | 更高复杂性,更多功能 | 更简单,易于部署 |
| 安全性 | 高级安全(mTLS、RBAC) | 轻量级 mTLS 加密 |
| 可观测性 | 深度集成追踪和监控工具 | 基本的日志和指标支持 |
| 性能 | 资源密集型 | 轻量级,优化速度 |
| 最佳适用场景 | 大规模企业部署 | 需要简单服务网格的团队 |
Istio 和 Linkerd 在多云环境中的应用
-
Istio:适合需要高级安全、路由和可观测性的企业级多云 Kubernetes 集群。
-
Linkerd:适合在混合云环境中部署轻量级服务网格,其中简单性和性能是关键。
简而言之,Istio 和 Linkerd 都是优秀的服务网格解决方案,但选择取决于组织需求。Istio 适用于功能丰富、企业级的网络需求,而 Linkerd 适合需要简单、轻量级解决方案且具备强大安全性和可观测性的团队。
七. 使用 Keptn 实现部署验证与 SLO 监控
什么是 Keptn?
Keptn 是一个开源的控制平面,用于自动化 Kubernetes 中的部署验证、服务级别目标 (SLO) 监控和事件修复。它帮助组织确保应用在部署前后满足预定义的可靠性标准。
为什么在 Kubernetes 中使用 Keptn?
-
自动化质量门:在全面发布前根据 SLO 验证部署。
-
持续可观测性:使用 Prometheus、Dynatrace 等工具监控应用健康状态。
-
自愈能力:检测性能下降并触发修复工作流。
-
多云就绪:支持 AWS、Azure 和 GCP 的 Kubernetes 集群。
-
事件驱动工作流:使用云原生事件触发自动化响应。
Keptn 在 Kubernetes 中的工作原理
Keptn 与 Kubernetes 集成,提供自动化部署验证和持续性能监控:
-
质量门:确保应用在部署前满足可靠性阈值。
-
服务级别指标 (SLI):监控关键性能指标(延迟、错误率、吞吐量)。
-
SLO 评估:将 SLI 与预定义目标对比,确定部署成功与否。
-
修复操作:如果服务质量下降,触发回滚或扩展操作。
对比:Keptn vs. 传统监控工具
| 特性 | Keptn | 传统监控(如 Prometheus) |
|---|---|---|
| 基于 SLO 的验证 | 是 | 否 |
| 自动化回滚 | 是 | 需要手动干预 |
| 事件驱动操作 | 是 | 否 |
| 修复工作流 | 是 | 否 |
| 多云支持 | 是 | 是 |
Keptn 在多云环境中的应用
-
AWS:与 AWS Lambda、EKS 和 CloudWatch 集成,实现自动化修复。
-
Azure:与 Azure Monitor 和 AKS 集成,实现 SLO 驱动的验证。
-
GCP:支持 GKE 和 Stackdriver,实现持续监控。
-
混合云:支持跨多个 Kubernetes 集群的统一服务验证。
简而言之,Keptn 是 Kubernetes 部署的革命性工具,实现了基于 SLO 的验证、自愈和持续可靠性监控。通过自动化部署验证和事件响应,Keptn 确保应用在多云 Kubernetes 环境中满足性能和可用性标准。
结论
Kubernetes 的可观测性和可靠性对于确保多云和混合云环境中无缝的应用性能至关重要。本文讨论的工具------Jaeger、Prometheus、Thanos、Grafana Loki、OPA、Kyverno、Flagger、Argo Rollouts、Falco、Tetragon、Datadog Kubernetes Agent、Keda、Istio、Linkerd 和 Keptn------帮助组织优化监控、安全性、部署自动化和自动扩展。
通过将这些工具集成到你的 Kubernetes 策略中,可以实现增强的可见性、自动化策略实施、安全部署和高效扩展,确保在任何云环境中都能平稳运行。