什么是RAG?
RAG(Retrieval-Augmented Generation 检索增强生成),是一种结合信息检索技术和AI内容生成的混合架构,解决大模型知识时效性限制和幻觉问题,我们可以先简单的称其为知识库
简单来说,可以将RAG比作AI的一个课本,让AI在回答问题之前先去课本查询一些有理有据的只是,确保回答是基于真实资料而非想象
从技术角度来看,RAG在大语言模型生成回答之前,会先从外部的知识库中检索相关信息,然后将检索到的内容作为额外的上下文提供给模型,引导其生成更准确、更相关的回答
通过RAG技术改造后,AI就能准确回答关于特定内容的问题(在知识库检索到的内容),提供更新、更准确的建议,架构如下图:
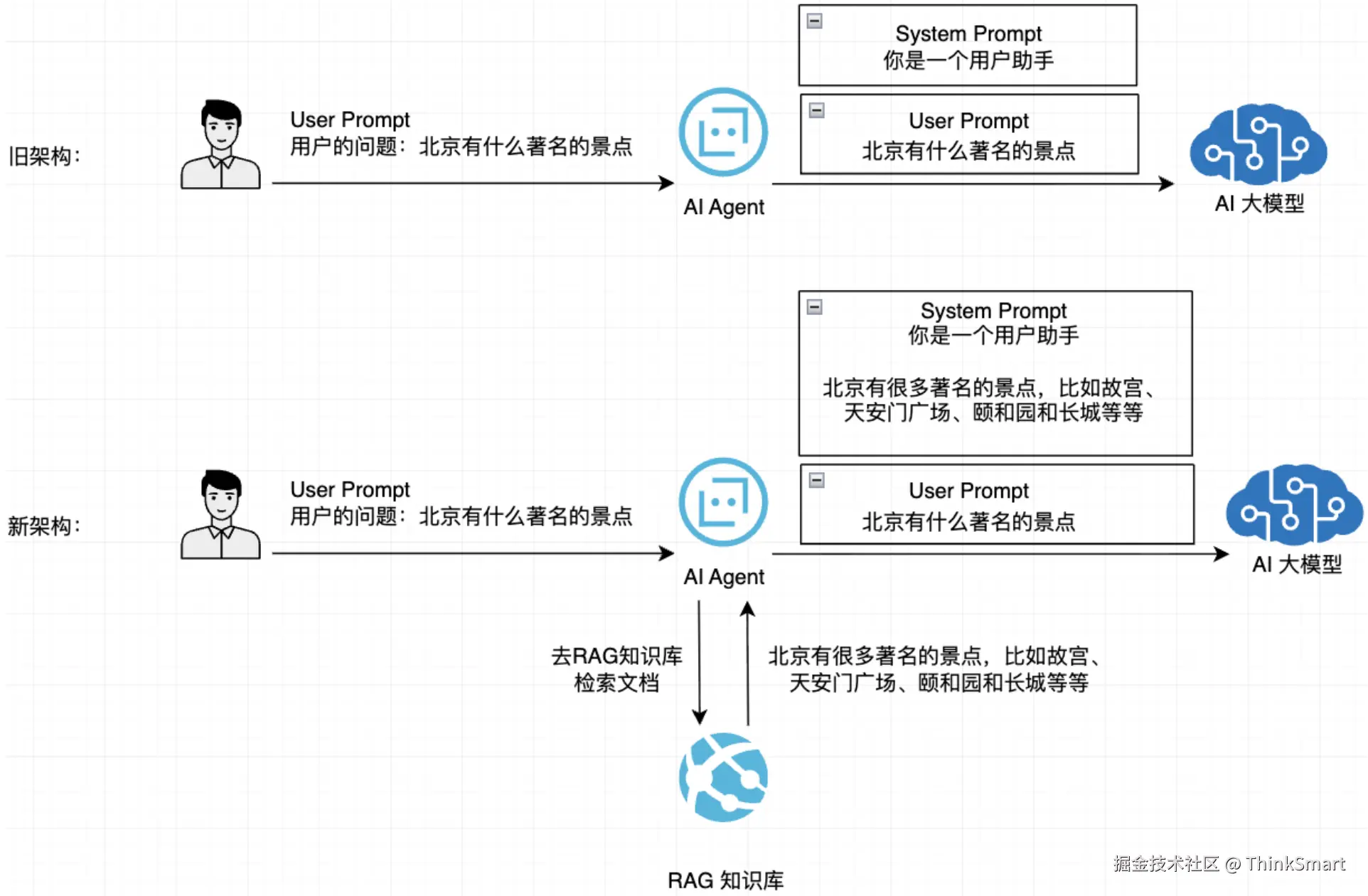
对比一下传统AI大模型和接入RAG知识库的AI大模型的区别:
| 特性 | 传统大语言模型 | RAG增强模型 |
|---|---|---|
| 知识时效性 | 受训练数据截止日期的限制 | 可从知识库中获取最新的数据信息 |
| 领域专业性 | 泛化知识,专业深度有限 | 可接入专业领域知识 |
| 响应准确性 | 可能产生 "幻觉" | 基于检索的事实依据 |
| 可控性 | 依赖原始训练 | 可通过知识库定制输出 |
| 资源消耗 | 高(需要对大模型参数调整) | 模型可更小,结合外部知识 |
什么是大模型幻觉
大模型幻觉简单来说就是,会生成内容违背公认的真实信息、生成的内容自相矛盾、生成的内容是虚构的等等场景
举个例子: 提问:"2025 年全球果蔬种植行业的市场规模是多少?"
- 模型错误输出:"2025 年全球果蔬种植行业市场规模达 5.8 万亿美元,较 2024 年增长 23%,其中中国市场占比 35%,主要驱动力是阳台种植需求激增。"
- 事实纠正:2024 年全球农业总市场规模约 3 万亿美元,果蔬种植仅为其中一部分,5.8 万亿美元的数据远超合理范围,且 "23% 增长率" 无任何权威机构预测支持。
RAG的工作流程
RAG技术的实现主要包含以下4个核心步骤,让我们分步来学习:
- 文档收集和切割
- 向量转换和存储
- 文档过滤和检索
- 查询增强和关联
文档收集和切割
文档收集:从ing各种来源(网页、PDF、数据库等)收集原始文档
文档预处理:清洗、标准化文本格式
文档切割:将长文档分割成适当大小的片段
- 基于固定大小(如1024个Token)
- 基于语义边界(如段落、章节、大小标题)

举个例子,假设我有一篇文档,内容如下:
北京是中国的首都,有着悠久的历史和丰富的文化。北京有很多著名的景点,比如故宫、天安门广场、颐和园和长城。故宫是明清两代皇帝居住的地方,非常宏伟壮观。颐和园是一座皇家园林,风景优美。长城是中国古代伟大的建筑之一,吸引着世界各地的游客。
基于固定长度切割
为了方便检索,我们将这段文字按照句子拆分 (文本分块),形成一个个知识块
- 北京是中国的首都,有着悠久的历史和丰富的文化。
- 北京有很多著名的景点,比如故宫、天安门广场、颐和园和长城。
- 故宫是明清两代皇帝居住的地方,非常宏伟壮观。
- 颐和园是一座皇家园林,风景优美。
- 长城是中国古代伟大的建筑之一,吸引着世界各地的游客。
这些句子可以看作是一个小型的知识库,由所有的小知识库,构成一整个大的RAG知识库。
基于语义切割
-
北京是中国的首都,有着悠久的历史和丰富的文化。北京有很多著名的景点,比如故宫、天安门广场、颐和园和长城。
-
故宫是明清两代皇帝居住的地方,非常宏伟壮观。颐和园是一座皇家园林,风景优美。长城是中国古代伟大的建筑之一,吸引着世界各地的游客。
两个知识块分别表达了"北京概况"和"主要景点介绍",具有清晰的主题边界。
元数据标注
我们还可以给文档添加丰富的结构化信息,俗称元信息、形成多维索引,便于后续向量化处理和精准检索
txt
北京是中国的首都,有着悠久的历史和丰富的文化。北京有很多著名的景点,比如故宫、天安门广场、颐和园和长城。故宫是明清两代皇帝居住的地方,非常宏伟壮观。颐和园是一座皇家园林,风景优美。长城是中国古代伟大的建筑之一,吸引着世界各地的游客。以这段文本为例子,假设这是一个文档的内容,你会给这个文档打上一个什么标签呢?
第一时间想到的是:城市介绍、著名景点、历史文化等等这类的标签,那在检索文档的时候,也可以通过这些条件去where检索
这个元数据的标注可以人为进行,也可以把文档交给大模型,让大模型帮你生成对应的元数据标注信息
向量转换和存储
向量转换:使用Embedding模型将文本块转换为高维向量表示,可以捕获到文本的语义特征
向量存储:将生成的向量和对应的文本存入向量数据库中,支持高效的相似性搜索
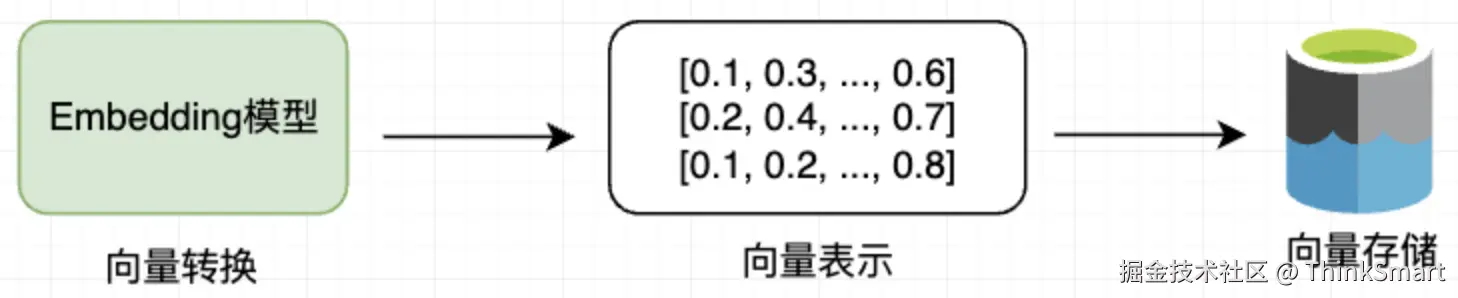
Embedding概念图解
Embedding是指将高维离散数据(如文字、图片)转换为低维连续向量的过程
这些向量能在数学空间中表示原始数据的语义特征,使计算机能够理解数据间的相似性
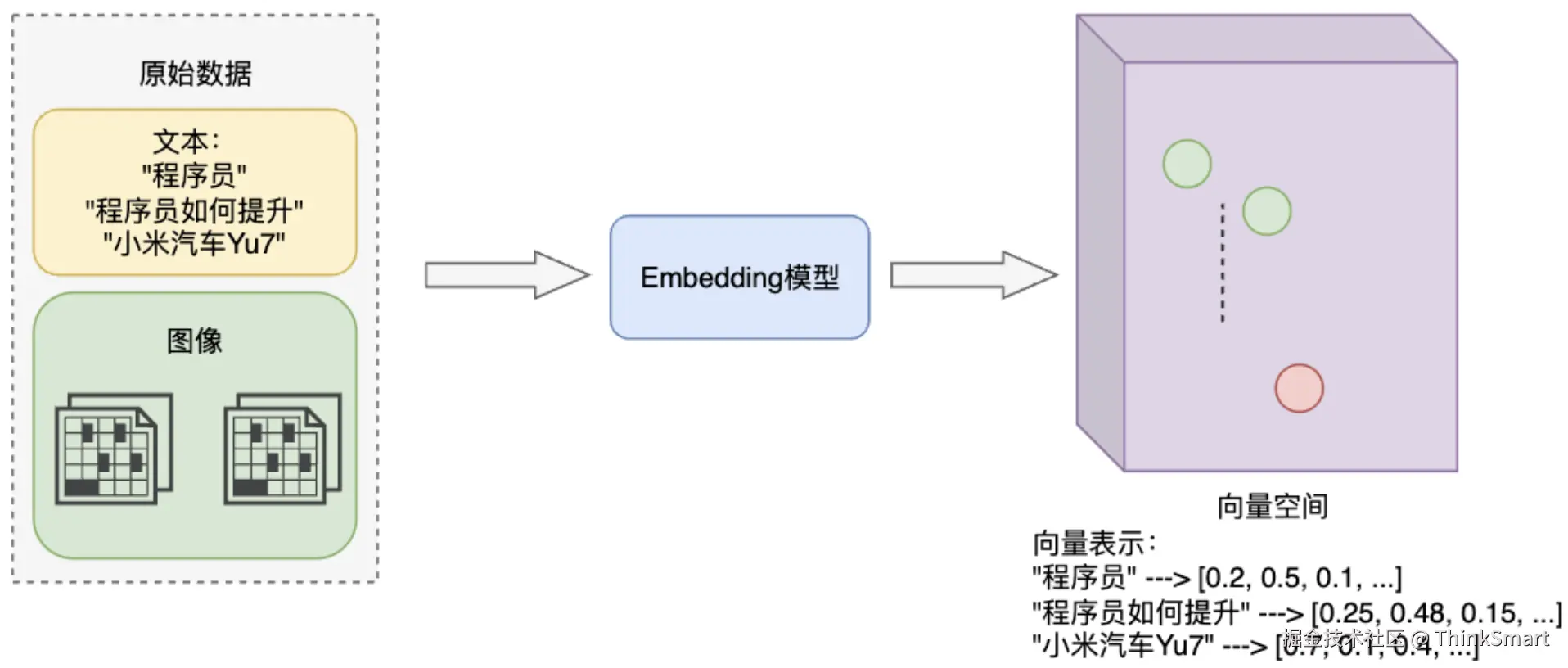
举例子,"程序员"和"程序员如何提升"的Embedding向量在空间中比较接近,而"程序员"和"小米汽车Yu7"则相距较远
语义相近的词语,在向量空间中距离较近,语义差别较大的,在向量空间中距离较远
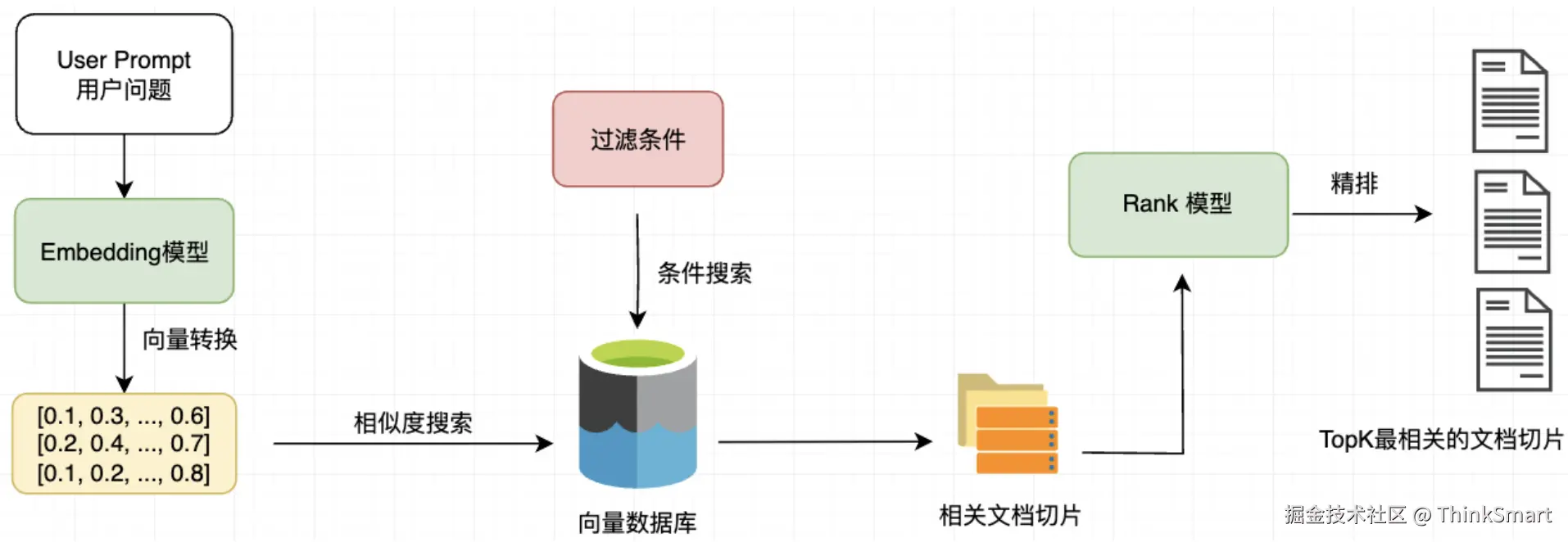
文档过滤和检索
查询处理:将用户的问题也转换为向量来表示
过滤机制:给予元数据、关键词或自定义规则进行过滤
相似度检索:在向量数据库中查找与问题向量最相似的文档块,常用的相似度搜索算法有余弦相似度、欧氏距离等
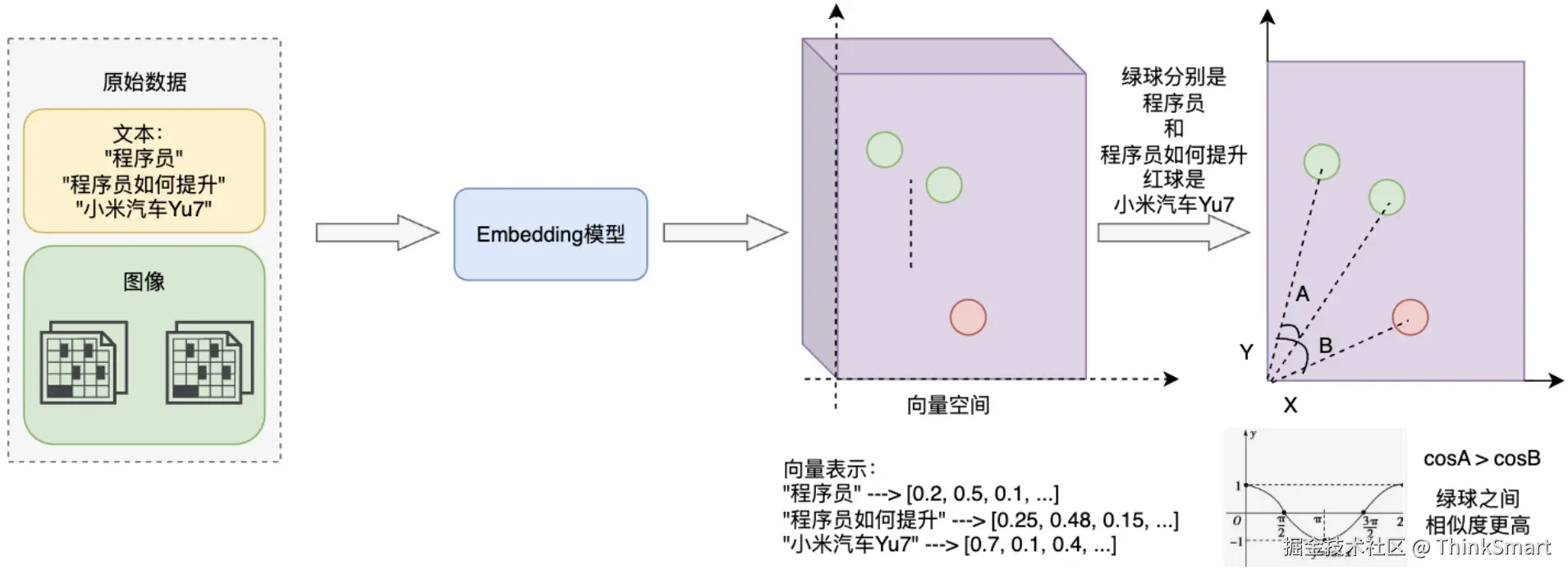
相似度搜索算法 - 余弦相似度
将数据抽象为n 维向量 ,余弦相似度通过计算两个向量之间夹角的余弦值
判断它们的 "语义是否相近"------ 夹角越小,余弦值越接近 1,向量方向越相似,语义越相近;
夹角越大,余弦值越接近 - 1,方向越相反,语义差别越大
cosθ=∥A∥×∥B∥A⋅B=∑i=1nai2 ×∑i=1nbi2 ∑i=1naibi
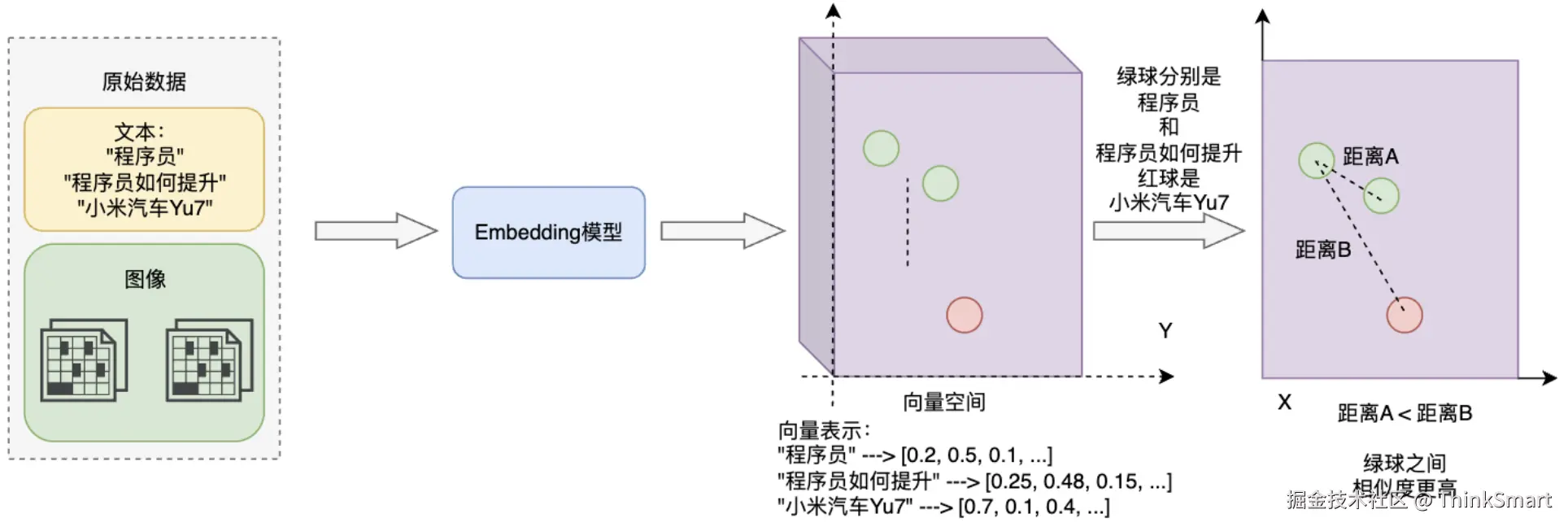
相似度搜索算法 - 欧氏距离
同样将数据抽象为 n 维向量,欧氏距离是两个向量在n 维空间中 "直线距离" 的长度,即两点间的距离。
距离越小,说明两个向量在空间中的位置越近,数值上的相似性越高;距离越大,位置越远,相似性越低。
d(A,B)=i=1∑n(ai−bi)2
检索增强 - 查询转换与扩展
在预检索这个阶段,会通过查询转换和扩展等方法对其进行优化,输出增强的用户查询
假设用户问题是:"故宫",我们会对用户的这个问题做扩展成 "故宫的历史、建筑风格、开放时间"
假设用户的问题是:"故宫以前是谁住的?",我们会对用户的这个问题进行重述成 "明清时期皇帝住在哪里?"
检索增强 - 上下文增强检索
有可能我们检索出来的单个文档知识块可能信息不完整,导致检索结果不够准确或生成回答的时候缺乏上下文支持
我们在检索过程中,除了返回最匹配的知识块,还要同时返回其前后相邻的知识块,以提供更丰富的上下文信息
举个例子,用户提问:"故宫有什么特点?"
假设我们有如下三个知识块:
- 北京是中国的首都,有着悠久的历史和丰富的文化。北京有很多著名的景点,比如故宫、天安门广场、颐和园和长城。
- 故宫是明清两代皇帝居住的地方,非常宏伟壮观。
- 颐和园是一座皇家园林,风景优美。长城是中国古代伟大的建筑之一,吸引着世界各地的游客。
如果根据用户的查询关键词做筛选,最匹配的是知识块2,但是发送给AI大模型的是知识块1、2、3
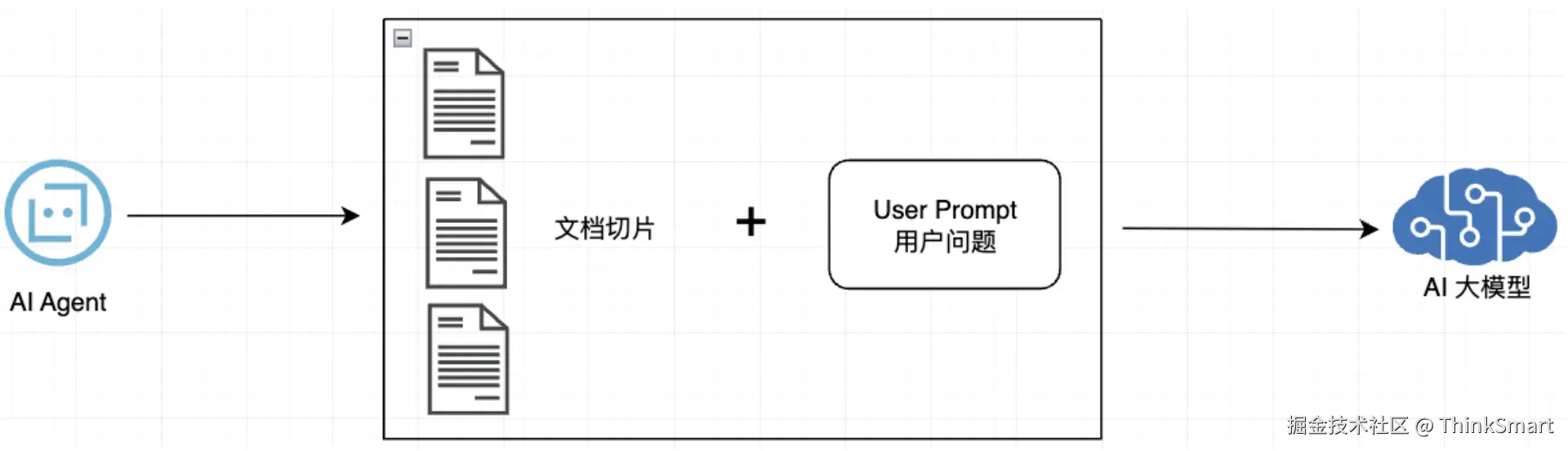
查询增强和关联
上下文组装:将检索到的多个文档块组装成连贯上下文
RAG的检索策略
当我们想要检索某些我们想要检索的文档的时候,我们会考虑到什么检索方式呢?
-
向量检索
上文我们提到的是向量检索 ,向量检索能够通过理解语义,捕捉文本见的概念关联,但对关键词的敏感度不够,即无法精确匹配
如当你搜索"2025年怎么学习编程"时向量检索可能会返回与编程相关的术语解释,而不是准确锁定2025年变成学习路线
-
全文检索
比如MySQL可以做全文检索、Elasticsearch可以通过倒排索引做全文检索,但这种方式不理解语义,难以处理同义词或概念性查询
就像你问 "怎么学习Java",全文检索可能不会返回只提到 "怎么学习编程",而没有明确提到Java的文档
-
知识图谱检索
知识图谱的检索方式可以发现实体间隐含的关系,适合回答复杂问题,但构建成本过高
那么我们的检索策略到底该如何选择呢?
其实,就像我们查询资料时会尝试不同的方法一样,单一的检索方法往往难以满足复杂的需求,那么就采取混合检索策略
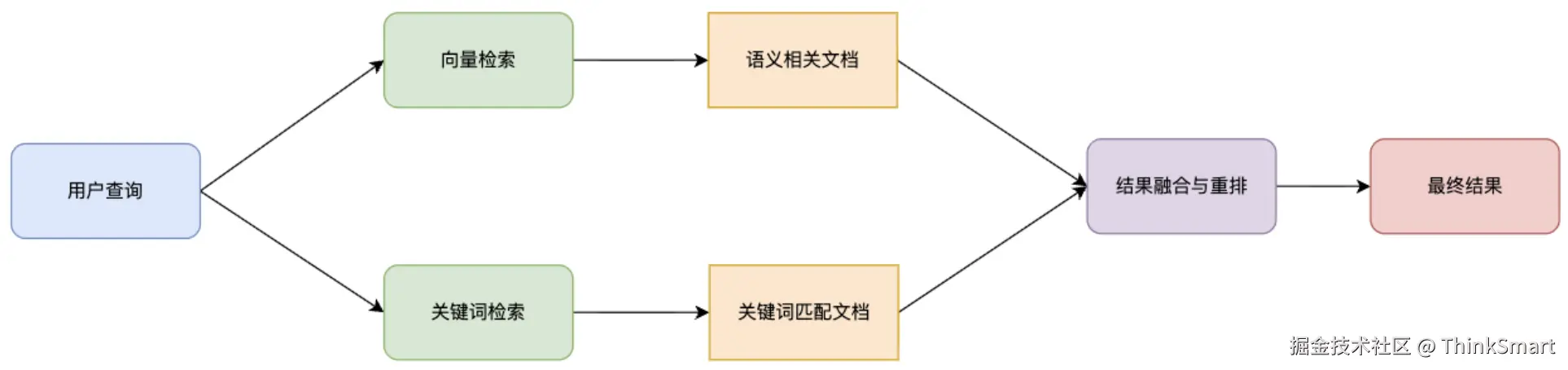
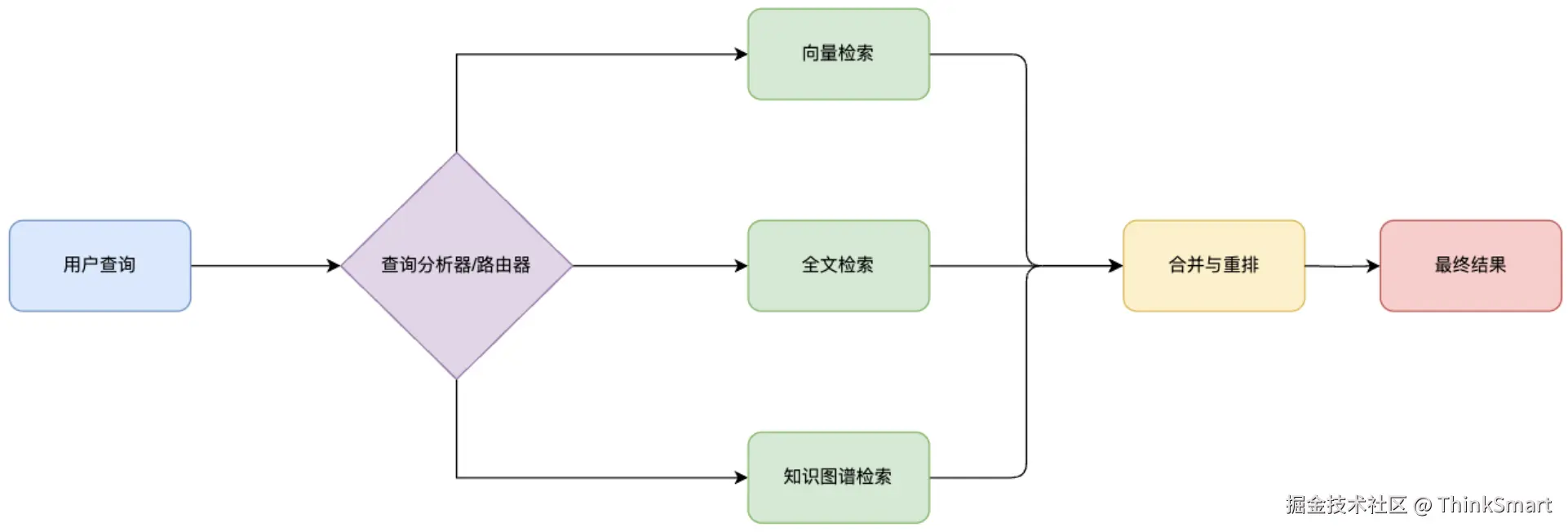
混合检索策略 - 并行混合检索
同时使用多种检索方法获取结果,然后使用重排模型融合多种来源结果,就像你通过大量的方式获取了文档,但需要进一步过滤
混合检索策略 - 级联混合检索
层层筛选,先使用一种方法进行广泛召回,在用另一种方法精确过滤
比如先使用向量检索获取语义相似的文档,再用关键词过滤,最后用元数据、标签等方式进一步筛选过滤,缩小范围

混合检索策略 - 动态混合检索
动态混合检索就像路由器,能够根据查询的类型,自动的选择最合适的检索方法,更加智能
举个例子,对于"谁是张三"这样的人物查询,可能更偏向于使用知识图谱检索,而处理"如何学习Java"这类教学问题,更适合向量检索配合全文检索的方式进行检索,这样的方式让系统能更像人类一样智能的选择最佳的信息获取渠道
RAG进阶架构
随着技术的发展和演进,传统的"检索 - 生成"架构可能无法满足更复杂、要求质量更高的需求,因此让我们简单了解几种创新的RAG架构
这里我们只是简单了解一下有哪些架构,如果要深入学习,还是要在网上搜索相关论文进行学习。
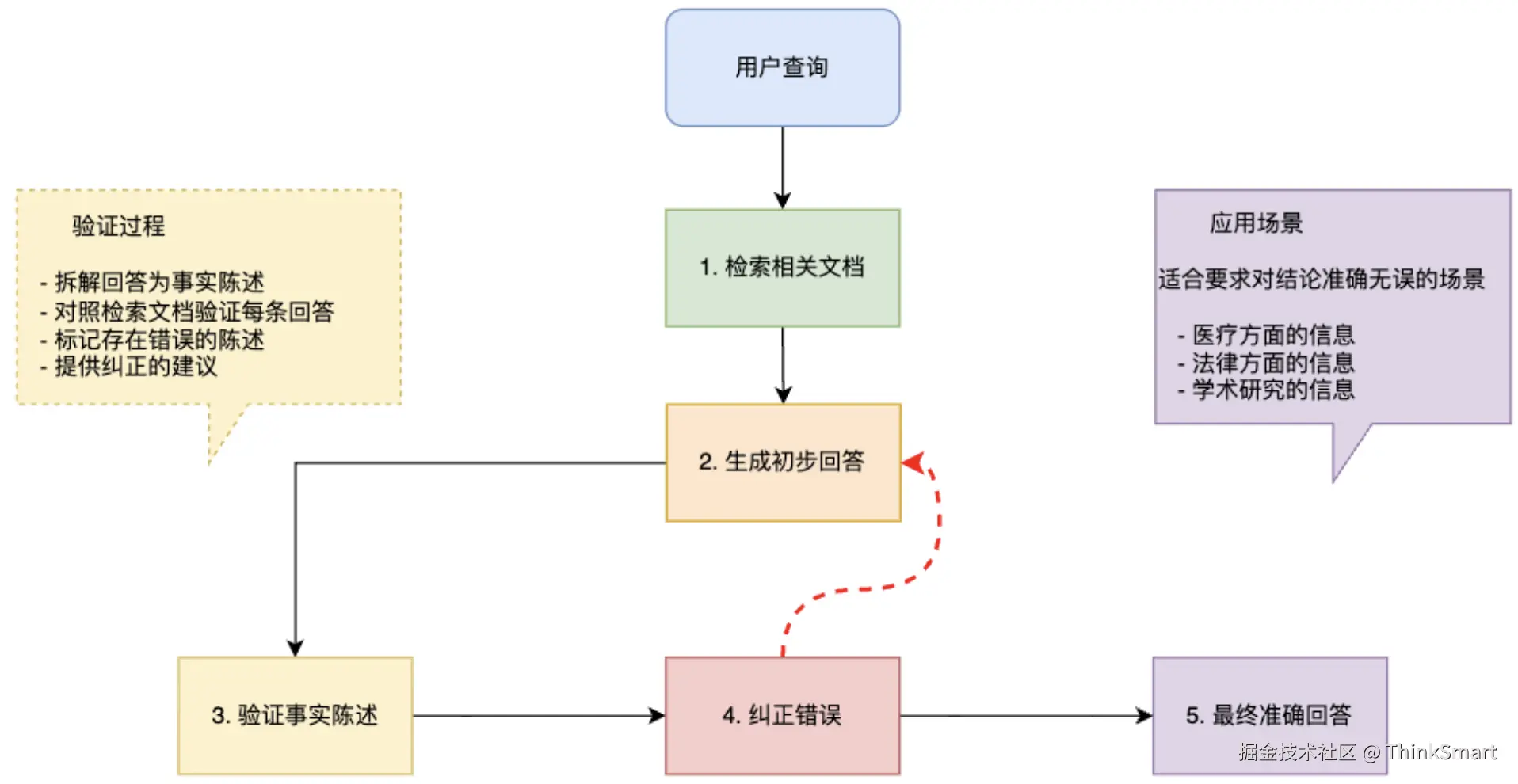
自纠错RAG
针对模型可能误解或错误使用检索信息的问题,提高回答的准确性
在网上有刷到过一个游戏视频,多个人在一排的房间,每个人是在不同的房间,从左往右开始游戏,给第一个人看要猜的物品,但不能说这个物品是什么,类似你画我猜,从左往右的开始描述,最后一个人要回答出答案,在这个过程中,总会有错误的描述参杂在里面,会有玩家不小心添加了一些自己的理解或听错了细节,自纠错RAG就是为了解决这种问题而设计的。
自纠错RAG采用 "检索 - 生成 - 验证 - 纠正" 的闭环流程:先检索文档,生成初步回答,然后验证回答中的每个事实陈述,发现错误就立即纠正并重新生成,这种循环确保了最终回答的高度准确性
自省式RAG
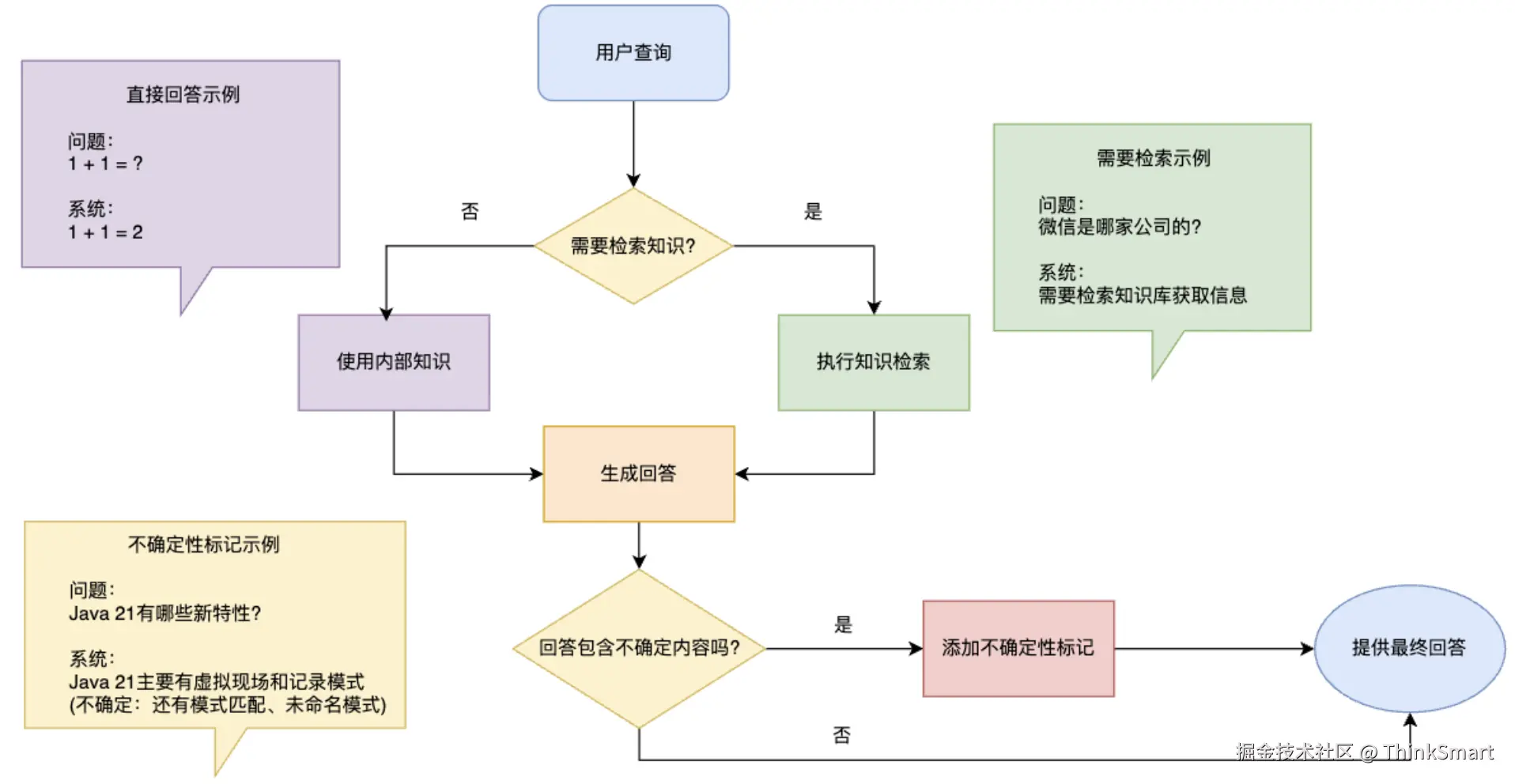
针对 "并非所有问题都需要检索" 的问题,让回答更自然并且提高系统效率
比如用户提问 "1+1=几" 这样的基础问题,模型完全可以直接回答,无需额外检索,自省式RAG让模型学会判断,什么时候需要查资料、什么时候可以直接回答,当收到用户提问时,自省式模型会在内心思考:"这个问题我知道答案吗?需要查询更多信息吗?我的回答包含任何不确定的内容吗?",这种自我反思的机制使回答更自然,也在一定程度上提高了系统的效率
检索式RAG
提供了一种结构化的解决方案,特别适合可拆分的复杂问题,就像解决一个动态规划问题,先把大问题拆解成多个小问题分别解决再整合
举个例子,对于 "介绍微信的社交板块、搜索板块、电商板块" 这样的多方面问题,检索式RAG会分别检索关于3个板块的信息
这样的设计,能够提高长篇叙述的连贯性和准确性,克服单次检索的上下文长度限制
