标题 :FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis
作者 :Feng Liang*, Bichen Wu†, Jialiang Wang, Licheng Yu, Kunpeng Li, Yinan Zhao, Ishan Misra, Jia-Bin Huang, Peizhao Zhang, Peter Vajda, Diana Marculescu
单位 :德克萨斯大学奥斯汀分校,Meta GenAI
发表 :CVPR 2024
论文链接 :https://arxiv.org/pdf/2312.17681
项目链接:https://jeff-liangf.github.io/projects/flowvid/代码链接 :GitHub - Jeff-LiangF/FlowVid(很遗憾,代码没有过审,模型参数拿不到,代码需要向作者团队发送请求邮件获取)
关键词:视频生成,视频编辑,扩散模型,不完美光流,时间一致性,可控生成
核心思想 :FlowVid提出了一种新颖的视频到视频(V2V)合成框架,它不将光流作为硬性约束,而是作为软性条件,巧妙地结合空间控制(如深度图)来修正光流估计中的不完美,从而在保持高效的同时,生成高质量、时间上高度一致的编辑视频。
一、研究背景与挑战
1.1 领域发展现状
扩散模型已彻底改变图像到图像(I2I)合成领域,基于预训练文本到图像扩散模型,研究者开发出 Prompt-to-prompt、Instruct-pix2pix、ControlNet 等一系列高效 I2I 工具,能精准响应文本指令,甚至支持深度图、边缘图等空间条件控制。
然而,当技术向视频领域延伸时,却面临巨大阻碍。视频相比图像多了时间维度,由于文本指令存在歧义,单帧按提示修改的方式有无数种可能,直接将 I2I 模型逐帧应用于视频,会导致严重的像素闪烁问题,无法满足实际需求。
1.2 现有 V2V 方法的局限
为解决时间一致性问题,现有方法主要分为两类,但均存在明显缺陷:
- 时空注意力扩展法:这类方法将图像模型的空间注意力升级为时空注意力,让帧与帧之间建立关联,如 Tune-A-Video、TokenFlow 等。但它们仅通过注意力模块隐式保留视频运动信息,无法完全保证时序一致性,且模型复杂度高,生成效率低。
- 光流硬约束法:另一类方法利用光流获取帧间像素对应关系,将其作为硬约束指导生成,例如 Rerender 用估计光流生成遮挡掩码进行补绘,CoDeF 用光流引导生成规范图像。但光流估计依赖预训练模型,在复杂运动场景下易出现误差,硬约束会导致这些误差被放大,最终生成结果失真。
正是基于上述痛点,FlowVid 提出了 "联合空间 - 时间条件" 的解决方案,旨在平衡光流的时序价值与处理光流缺陷的需求。
二、核心方法:FlowVid 架构与原理
FlowVid 的核心思路是:不将光流作为必须严格遵守的硬约束,而是将其与空间条件结合作为软参考,通过 "编辑首帧 + 传播修改" 的流程,实现高效、一致的 V2V 合成。整体架构分为模型扩展 、联合条件训练 、生成流程三个关键部分。
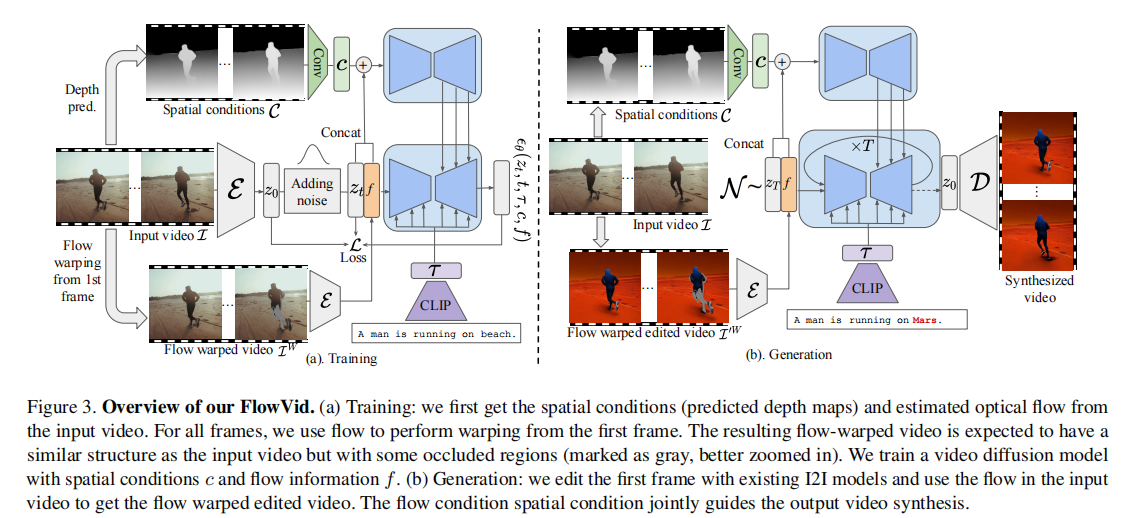
2.1 模型扩展:将图像 U-Net 适配视频
FlowVid 基于 latent diffusion model(LDM)构建,首先对图像 U-Net 进行改造,使其能处理视频的时间维度,具体改造包括两点:
- 卷积层与注意力层升级:将 U-Net 中的 2D 卷积层替换为伪 3D 卷积层,同时在 transformer 模块中新增时间自注意力层,并将原有的空间自注意力层升级为时空自注意力层。
- 时空注意力计算逻辑 :对于第 i 帧,其时空注意力的查询(Q)来自当前帧的 latent 特征,而键(K)和值(V)则来自首帧和前一帧的 latent 特征,公式如下:
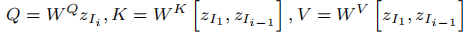 ,其中,
,其中,、
此外,模型还保留了 ControlNet 分支处理空间条件,但仅对主 U-Net 进行上述扩展,ControlNet 的输出会融入主 U-Net 中,兼顾效率与控制能力。
2.2 联合条件训练:处理光流缺陷的关键
传统光流方法的痛点在于 "硬约束",FlowVid 则通过 "空间条件 + 时间光流条件" 的联合训练,将光流作为软参考,具体流程如下:
- 光流计算与帧扭曲 :对于输入视频的首帧
- 多条件融合 :将扭曲帧序列
 (所有帧均为原首帧)编码为 latent 特征,再将遮挡掩码 O 调整为与 latent 尺寸匹配的格式。最终,将光流特征
(所有帧均为原首帧)编码为 latent 特征,再将遮挡掩码 O 调整为与 latent 尺寸匹配的格式。最终,将光流特征 - 损失函数设计 :在 ControlNet 损失函数基础上,加入光流等时间条件,最终损失函数为:
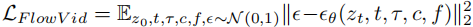 ,其中,
,其中,
特别地,论文通过实验验证了两个关键设计:采用 v-parameterization 而非传统的 ε-parameterization,避免帧间颜色偏移;加入首帧特征和遮挡掩码,进一步提升纹理一致性和遮挡区域处理能力。
2.3 生成流程:编辑 - 传播与 autoregressive 扩展
FlowVid 的生成过程分为 "首帧编辑" 和 "修改传播" 两步,同时支持 autoregressive 生成以扩展视频长度:
- 首帧编辑 :利用现有 I2I 模型(如 ControlNet、Instruct-pix2pix),根据目标文本提示修改输入视频的首帧,得到编辑后的首帧
- 修改传播 :使用输入视频的光流和遮挡掩码,对编辑后首帧
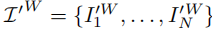 。将
。将 - Autoregressive 长视频生成 :当需要生成超过单批次长度的视频时,将前一批次的最后一帧作为下一批次的 "首帧",重复上述传播过程。为解决多次传播导致的 "画面发灰" 问题,论文提出颜色校准方法 ------ 将每帧的均值和方差调整为与初始编辑首帧
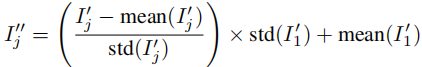 ,校准效果如图 4 所示,未校准的结果随批次增加逐渐发灰,而校准后能保持颜色一致性。
,校准效果如图 4 所示,未校准的结果随批次增加逐渐发灰,而校准后能保持颜色一致性。

注:(a)无校准:从第 1 批次到第 13 批次,生成结果逐渐发灰;(b)有校准:自回归生成过程中颜色保持稳定。
三、实验验证:性能与效果全面评估
论文通过定性对比、定量用户研究、消融实验等多种方式,全面验证 FlowVid 的性能,实验设置与核心结果如下:
3.1 实验设置
- 数据集:训练集采用 10 万条 ShutterStock 真实视频,测试集包含 25 条 DAVIS 目标中心视频(115 个提示)和 50 条 ShutterStock 视频(200 个提示)。
- 模型配置:输入帧、空间条件、扭曲帧分辨率均为 512×512,训练时每批次采样 16 帧,使用 8 张 A100-80G GPU 训练 10 万轮,耗时 4 天。生成时采用 20 步 DDIM 采样,分类器 - free 引导尺度为 7.5,使用 RIFE 模型进行帧插值以提升帧率。
- 对比方法:选取当前主流 V2V 方法,包括 CoDeF(光流硬约束)、Rerender(光流遮挡补绘)、TokenFlow(时空注意力),以及直接逐帧应用 ControlNet 的基线方法。
3.2 定性结果(Qualitative Results):视觉效果优势
从图 5 的定性结果可以看出,FlowVid 在 "提示对齐" 和 "时序一致性" 上均表现最优:
- 逐帧编辑(Per-frame):即使使用相同的随机种子,也会出现明显的闪烁(如衣服、毛发)。
- CoDeF:在大运动场景下(如划船、老虎行走)会产生严重的模糊。
- Rerender:难以捕捉大运动(如船桨的移动),且颜色容易与背景混合。
- TokenFlow:有时无法充分遵循提示(如未能将人变成海盗),或出现结构错误(如老虎只有两条腿),导致闪烁。
- FlowVid (Ours):在编辑能力和整体视频质量上均表现出色,生成的视频既符合文本提示,又保持了良好的时间一致性。

注:(a)提示:"一个海盗在湖上划船";(b)提示:"一幅老虎行走的油画"。
3.3 定量结果(Quantitative Results):用户偏好与效率
3.3.1 用户研究
邀请了 5 名参与者对 4 种方法的生成结果进行盲评,评估维度包括时序一致性和文本对齐,结果如表 1 所示:
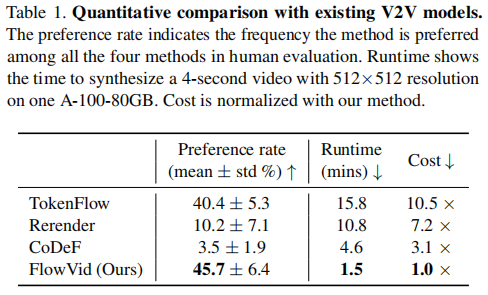
FlowVid 的偏好率远超其他方法,而 CoDeF 因大运动场景下画面模糊、Rerender 因颜色偏移、TokenFlow 因提示遵循度低,偏好率均较低。
3.3.2 生成效率
在生成效率上,FlowVid 优势显著:生成 4 秒(30 FPS,120 帧)512×512 视频仅需 1.5 分钟,是 CoDeF 的 3.1 倍、Rerender 的 7.2 倍、TokenFlow 的 10.5 倍。效率优势源于两点:
- 批量处理:FlowVid 支持 16 帧批量生成,而 Rerender 需逐帧处理。
- 无需预优化:CoDeF 需为每个视频训练规范图像模型,TokenFlow 需 500 步 DDIM 反转,FlowVid 无额外预处理步骤。
3.4 消融研究(Ablation Study)
论文通过消融实验验证了各条件组件的作用,实验设置 4 类条件:(I)空间控制(深度图 / 边缘图)、(II)光流扭曲视频、(III)光流遮挡掩码、(IV)首帧特征,对比不同组合的 "胜率"(即该组合生成结果优于全条件 FlowVid 的比例),结果如图 6 所示。

- 仅使用空间控制(✓ × × ×):效果最差,仅有9%的胜率。
- 空间控制 + 扭曲视频(✓ ✓ × ×):效果显著提升(38%)。
- 再加入遮挡掩码(✓ ✓ ✓ ×):效果进一步提升至42%。
- 完整模型(✓ ✓ ✓ ✓):结合所有四种条件(空间控制、扭曲视频、遮挡掩码、首帧重复),达到最佳性能,证明了所有设计的必要性。
此外,消融实验还验证了空间条件类型的影响:Canny 边缘图适合风格迁移(保留细节),深度图适合目标替换(提供更大编辑灵活性),如图 7 所示;同时证明 v-parameterization 能避免 ε-parameterization 导致的颜色偏移问题,如图 8 所示。

注:(a)输入帧;(b)空间条件(Canny 边缘图 vs 深度图);(c)风格迁移(边缘图保留熊猫嘴部细节);(d)目标替换(深度图生成更自然的考拉)。

注:(a)ε-parameterization:出现非自然的全局颜色偏移;(b)v-parameterization:颜色正常,无偏移。
3.5 局限性
FlowVid 仍存在两点不足:
- 首帧依赖:若编辑后的首帧与原首帧结构不对齐(如将大象后腿误标为鼻子),错误会传播至后续所有帧,如图 9(a)所示。
- 大遮挡处理:当相机或目标快速运动导致大面积遮挡时,模型对空白区域的补绘可能出现 "幻觉"(如将芭蕾舞演员的后脑勺误绘为正面),如图 9(b)所示。

注:(a)首帧结构错位:编辑首帧将大象后腿误判为鼻子,后续帧延续错误;(b)大遮挡:芭蕾舞演员快速转头导致大面积遮挡,模型误将后脑勺绘为正面。
四、总结与展望
4.1 核心贡献
FlowVid 在 V2V 合成领域的贡献主要体现在三个方面:
- 创新的光流处理方式:首次将光流作为 "软参考" 而非 "硬约束",通过联合空间 - 时间条件,有效处理光流估计的不完美问题,兼顾时序一致性与生成质量。
- 灵活高效的架构:"编辑首帧 + 传播修改" 的流程复用现有 I2I 工具,降低开发成本;批量生成与 autoregressive 扩展结合,兼顾效率与长视频生成能力。
- 全面的性能优势:在用户偏好率(45.7%)和生成效率(比 TokenFlow 快 10.5 倍)上均远超现有方法,且支持风格迁移、目标替换、局部编辑等多种应用场景。
4.2 未来方向
基于 FlowVid 的局限性,未来可从两方面优化:
- 首帧对齐优化:结合图像分割、关键点检测等技术,自动校验编辑首帧与原首帧的结构一致性,避免错误传播。
- 大遮挡补绘增强:引入视频上下文预测(如基于前几帧运动轨迹预测遮挡区域内容),或结合多模态输入(如文本提示细化遮挡区域描述),减少 "幻觉" 现象。
FlowVid 的出现,为 V2V 合成提供了 "高效、灵活、高质量" 的新范式,其对光流缺陷的处理思路,也为其他依赖光流的视频生成任务(如视频修复、视频风格迁移)提供了重要参考。