第一部分:Assistants API 架构的核心基石------状态的抽象
引言:为何(深入)理解一个"已弃用"的 API 仍然至重要?
OpenAI 已宣布 Assistants API 将被 Responses API 所取代,并计划于 2026 年 8 月 26 日关停 1。然而,正如许多开发者所观察到的,该 API 的架构范式在行业中的重要性不减反增 3。
Assistants API 的真正价值不在于其具体的端点,而在于它首次为构建**"有状态" (Stateful)、 "工具赋能" (Tool-enabled)** 且**"可持久化" (Persistent)** 的 AI 代理(Agent)定义了一套强大的核心架构蓝图。它解决了构建复杂 AI 代理的最大痛点:状态管理。因此,深入理解这个 API,就是理解现代 AI 代理的设计哲学与工程实践。
核心对象模型:解构五个关键概念
Assistants API 的全部功能构建在五个核心对象之上,它们共同定义了 AI 代理的配置、记忆、内容和执行 4。
-
Assistant (大脑与蓝图)
- Assistant 是 AI 代理的配置或**"蓝图"** 4。它是一个持久化对象,定义了代理的行为和能力。其关键配置包括:
model:指定使用的模型,例如 gpt-4。instructions:类似于 Chat Completions 中的系统提示,用于指导 Assistant 的个性、目标和响应方式 4。tools:一个列表,声明 Assistant 可以访问的能力,最多 128 个。这包括 OpenAI 的内建工具(如code_interpreter和file_search)以及用于调用外部 API 的function_calling4。tool_resources:为上述工具提供所需的资源,例如为file_search关联一个vector_store_id4。
-
Thread (记忆与状态)
- Thread 代表一个**"对话会话"**的容器 4。这是 Assistant 和用户之间交互的状态。Thread 的核心功能是存储 Messages。开发者只需向 Thread 添加新消息,而无需在每次请求中重新发送冗长的历史记录 4。
-
Message (内容)
- Message 是对话中的一个基本单元。它不仅仅是文本,一个 Message 对象可以包含文本、图像(通过文件上传
purpose='vision'或使用外部 URL)以及作为attachments的文件(供code_interpreter或file_search使用)4。
- Message 是对话中的一个基本单元。它不仅仅是文本,一个 Message 对象可以包含文本、图像(通过文件上传
-
Run (执行与引擎)
- Run 是**"执行引擎"** 4。当需要 Assistant(大脑)响应 Thread(记忆)中的内容时,开发者会创建一个 Run。Run 是一个一次性的异步进程,它会读取 Thread 中的所有 Messages,调用模型和必要的工具,然后将 Assistant 的响应(一个或多个新的 Message)添加回同一个 Thread 中 4。
-
Run Step (日志与透明度)
- Run Step 是一个**"日志"**对象。由于 Run 是一个复杂的异步过程(可能涉及多次模型调用和工具使用),Run Step 提供了该过程的详细轨迹,例如工具调用的具体步骤或消息创建的详情,便于调试和监控 4。
架构深度分析:解耦与抽象
Assistants API 的架构设计中体现了两个核心的工程思想:
真正的创新:"状态抽象"
标准的 Chat Completions API 是无状态的。开发者必须在客户端(自己的服务器)上实现所有复杂的状态管理逻辑:手动存储对话历史、处理上下文窗口截断、维护用户会话数据。
Assistants API 引入的 Thread 对象 4 将所有这些复杂性转移到了服务端。开发者只需
client.beta.threads.messages.create(...),API 会自动处理消息的持久化存储、上下文管理,甚至包括智能截断(使用auto或last_messages策略 4)。Thread 是 Assistants API 的核心价值主张,它将构建有状态 AI 应用的门槛从"架构级"难题降至"API 调用"级别。
架构模式:"配置"与"状态"与"执行"的精妙解耦该 API 的设计在 Assistant、Thread 和 Run 之间实现了完美的"关注点分离":
- Assistant 4 是配置(可重用的大脑蓝图)。
- Thread 4 是状态(每个用户独立的对话记忆)。
- Run 4 是执行(一次性的计算进程)。
这种解耦带来了极高的灵活性和可扩展性。例如,一个 Assistant(例如"通用客服助手")可以同时服务于数千个独立的 Threads(每个用户一个 Thread)。开发者甚至可以在创建 Run 时,临时覆盖 Assistant 的部分配置(如
model或instructions4),从而在不修改"蓝图"的情况下实现动态的行为调整。这是一种强大的多租户架构模式。
第二部分:Run 的生命周期------管理异步"黑盒"
Run 是一个异步过程。开发者启动它,然后必须轮询(Poll)或通过事件流等待其完成。理解 Run 的生命周期状态是与 API 交互的核心 4。
深入理解 Run Lifecycle
Run 对象在其生命周期中会经历多种状态 4:
- queued (排队中) :Run 被创建后,或在
requires_action状态完成后被重新提交时,会进入此状态。它正在等待执行,通常会立即转入in_progress。 - in_progress (进行中):Assistant 正在积极地"思考"或使用工具(如 Code Interpreter)。此时,可以通过查询 Run Steps 来查看其详细进展 4。
- completed (已完成):Run 成功执行。此时,Assistant 的响应(新的 Message)已被添加回 Thread 中。
- expired (已过期) :Run 超时。这最常发生在
requires_action状态下,客户端(即您的应用程序)未能在expires_at时间戳(通常约为 10 分钟)内提交所需的工具输出(tool_outputs)4。 - cancelling (正在取消) :客户端已请求取消一个
in_progress的 Run。
关键状态:requires_action 的工作流
requires_action 是 Run 生命周期中最关键的状态,它也是 Function Calling 工具得以实现的核心机制 4。
- 发生时机 :当模型(LLM)在
in_progress状态中决定它需要调用您在 Assistant 中定义的外部函数时,Run 会暂停 4。 - API 响应 :Run 对象的状态变为
requires_action。其required_action字段将包含一个tool_calls列表,其中包含了模型要求调用的所有函数 5。
客户端的责任 (The Handshake):
- 解析 (Parse) :您的应用程序必须轮询 Run 状态。一旦发现
requires_action,就需要立即解析tool_calls列表,提取出每个调用的tool_call_id、函数名 (function.name) 和 JSON 格式的参数 (function.arguments) 5。- 执行 (Execute):在您自己的服务器上(客户端)运行这些函数。这可能意味着查询您的数据库、调用第三方天气 API 或执行任何本地代码。
- 提交 (Submit) :将所有函数的输出(
output)收集起来,连同它们各自对应的tool_call_id,通过client.beta.threads.runs.submit_tool_outputs()API 调回给 Run 2。后续 :一旦提交了
tool_outputs,Run 的状态会变回queued,然后是in_progress,Assistant 会接收这些函数的真实返回结果,并利用这些信息完成最终的响应 4。
requires_action 的机制分析
requires_action 状态不仅仅是一个 API 状态,它是一种**"控制反转" (Inversion of Control)** 模式,是 Assistant 从"文本生成器"转变为"AI 代理"的"握手"机制。
没有这个机制,LLM 只能谈论行动(例如,"我建议您去查询一下天气")。而 requires_action 4 是一个正式的、阻塞式的"状态握手"。Run 进程会主动暂停 4,将执行的控制权交还给客户端,并明确要求 2, 4 客户端去执行现实世界的任务。
Run 的 expired 状态 4 进一步强化了这种"合约":Assistant(大脑)发出了指令,如果客户端(手脚)在 10 分钟内没有响应(提交 tool_outputs),"大脑"就会放弃这个 Run。
表 1:Run 生命周期状态速查表
| 状态 (Status) | 定义 | 客户端/服务器操作 |
|---|---|---|
| queued | 已创建,等待执行。 | 等待。 |
| in_progress | 正在使用模型或工具。 | (可选) 轮询 Run Steps 查看进度 4。 |
| completed | 成功执行。 | 从 Thread 中检索新消息。 |
| requires_action | 关键状态。等待客户端执行函数。 | 必须 :解析 tool_calls,执行函数,并 submit_tool_outputs 2。 |
| expired | 超时。 | 检查:是否忘记在 expires_at 4 之前提交 tool_outputs? |
| cancelling | 正在取消。 | 等待。 |
第三部分:三大核心工具深度解析 (Tools Deep-Dive)
Assistant 的"智能"不仅来自模型,更来自其强大的工具集。官方文档(S_B系列)在这些工具的内部机制上相对高阶 7,但结合补充研究(S_S系列),我们可以揭示其精确的工作原理。
1. Code Interpreter (沙盒中的数据科学家)
- 官方描述 4:一个可以"写入和运行 Python 代码,处理文件和多样化数据"的工具。
- 工作机制 8:它在一个**"沙盒执行环境"** (Sandboxed Execution Environment) 中运行 Python 代码。
- 沙盒的持久性 8:
- 这不是一个无状态的 FaaS(函数即服务)。Code Interpreter 会创建**"会话" (Sessions)**。每个会话默认激活 1 小时,若无操作,则空闲超时时间为 30 分钟 8。
- 核心能力:"迭代" 8:
- Assistant 的真正能力在于,当它编写的代码运行失败时,它可以在同一个会话中**"迭代" (iterate)** 8。它会读取 Python 的错误堆栈(Error Stack Trace),理解问题(例如,
FileNotFoundError或EncodingError),然后修改自己的代码并重新运行,直到成功。
- Assistant 的真正能力在于,当它编写的代码运行失败时,它可以在同一个会话中**"迭代" (iterate)** 8。它会读取 Python 的错误堆栈(Error Stack Trace),理解问题(例如,
- 文件处理(输入) 4:
- 文件可以通过多种方式提供给沙盒:在创建 Assistant 时通过
tool_resources4 关联,在创建 Thread 时通过tool_resources关联,或在创建 Message 时作为attachments附加 4。它支持多种文件类型,包括 CSV, JSON, PDF, DOCX, XLSX, 图像等 8。
- 文件可以通过多种方式提供给沙盒:在创建 Assistant 时通过
- 文件处理(输出) 4:
- Assistant 可以在沙盒中生成文件(例如,图表 *.png,处理后的 *.csv)8。这些文件不会自动下载,而是作为 Message content 中的注解 (annotations) 返回 4。
- file_path 注解 :当 Code Interpreter 生成数据文件时,Message 的文本中会包含一个沙盒路径(例如
sandbox:/mnt/data/file.csv),并附带一个file_path注解,其中包含一个可用于下载的file_id4。 - image_file 对象 :如果生成的是图像,Message content 数组中会直接包含
image_file对象及其file_id8。 - 下载 :客户端必须解析这些
file_id,并使用client.files.content(file_id)API 来获取文件的原始字节流 11。
- 沙盒的持久性 8:
Code Interpreter 的真正魔力在于其"有状态的沙盒会话"。如果它是一个无状态的执行环境,每次运行失败都意味着从头再来。而 8 和 8 证实了其会话的持久性。这种"迭代"能力 8 使其成为一个"微型代理循环"(micro-agent-loop),使其能够独立解决"具有挑战性的...数据分析问题",而不仅仅是执行简单的脚本。
2. Function Calling (连接外部世界的桥梁)
- 官方描述 7:允许 Assistant "使用您自己的自定义函数与您的应用程序交互"。
- 工作机制 2:
- 第 1 步:定义 (Define)
在创建 Assistant 或 Run 时,在tools参数中提供一个符合 JSON Schema 规范的函数定义 2。这个定义是 Assistant 和您的代码之间的"API 合约"。例如,定义一个get_weather函数,它接受一个必需的字符串参数location12。 - 第 2 步:触发 (Trigger) ->
requires_action
当用户提问(例如,"上海的天气如何?")时,模型会智能匹配到这个工具,并暂停执行,使 Run 进入requires_action状态 4。 - 第 3 步:执行 (Execute) & 提交 (Submit)
如第二部分所述,客户端(您的服务器)获取tool_calls5,执行本地代码(例如def get_weather(location):...),然后调用client.beta.threads.runs.submit_tool_outputs()2 提交结果(例如{"temperature": "28C"})。 - 第 4 步:完成 (Complete)
Assistant 收到工具输出("28C"),Run 恢复,模型基于此真实数据生成最终的自然语言响应(例如,"上海目前的天气是 28C。")。
- 第 1 步:定义 (Define)
Function Calling 的核心价值在于**"强制的结构化"。LLM 本质上是"模糊的"、非结构化的文本生成器。而您的本地代码(例如数据库查询)是"严格的"、结构化的。2 和 12 中展示的
parameters(JSON Schema) 就是连接这两者的桥梁。模型必须将其"意图"(想知道上海的天气)转换为一个 严格遵守该 Schema** 的 JSON 对象({"location": "Shanghai, CN"})。
requires_action状态 4 是一个保证,保证模型已经成功地将其"模糊"的意图转换为了您的代码可以安全(类型安全)执行的、机器可读的"API 合约"。
3. File Search (RAG) (内建的检索增强生成)
-
官方描述 7:一个"处理和搜索文件"的 RAG (Retrieval-Augmented Generation) 工具。
-
演进 13:这是 v2 API 相对于 v1 的最大升级。在 v1 中,这被称为
retrieval13。在 v2 中,file_search和 Vector Store 的概念取而代之,带来了 500 倍的容量提升------v2 最多可处理 10,000 个文件 14。 -
核心对象:Vector Store 15
- File Search 的能力依赖于 Vector Store 对象。Vector Store 是一个"可搜索文件的容器" 15。
-
工作机制(自动化的 RAG 管线)15
- 第 1 步:创建 :客户端创建一个 Vector Store(
client.vector_stores.create)16。 - 第 2 步:添加文件 :将已上传的
file_ids添加到 Vector Store 中 16。 - 第 3 步:自动化处理(黑盒) :一旦添加,API 会自动在后台对文件进行 17:
- 解析 (Parses):提取文本。
- 分块 (Chunks):将文本分割成块。
- 嵌入 (Embeds):创建向量嵌入。
- 索引 (Stores):存入向量数据库。
- 第 4 步:关联 :将
vector_store_id附加到 Assistant 的tool_resources17。 - 第 5 步:检索(智能 RAG) :当 Run 启动时,
file_search工具不仅仅是进行简单的向量相似性搜索。它会自动 17:- 重写用户查询以优化搜索。
- 分解复杂查询为多个并行搜索。
- 执行混合搜索(关键字 + 语义)。
- 对结果进行重新排序 (Reranks) 以挑选最相关的部分。
- 第 1 步:创建 :客户端创建一个 Vector Store(
-
高级配置 15:
- 最初,这个 RAG 管线是完全的"黑盒" 19。后来,OpenAI 开放了对
chunking_strategy(分块策略)的控制 15。现在,开发者可以自定义分块策略 (chunking_strategy),例如max_chunk_size_tokens(默认 800)和chunk_overlap_tokens(默认 400)15。
- 最初,这个 RAG 管线是完全的"黑盒" 19。后来,OpenAI 开放了对
-
局限性 21:
- 这种抽象也带来了代价。File Search 不支持元数据过滤(例如,按文件名或"年份 <= 2010"进行过滤)21。此外,当文件过多时(例如 100+ 个 PDF),如果默认分块策略不佳,语义搜索可能会变得"混乱"并"掷骰子" 22。
File Search 的价值在于它将极其复杂的 RAG 管线(分块、嵌入、索引、混合搜索、重排序)抽象为了几个简单的 API 调用 17。它是一个**"RAG 即服务"**(RAG-as-a-Service)的黑盒,为开发者提供了 RAG 80% 的好处,而只需 10% 的工作量。
然而,这种抽象是以**"控制力"为代价的**。21 中提到的无法进行元数据过滤,以及 22 中提到的大规模文件混淆问题,都完美地展示了 Assistants API 的核心设计权衡:用"控制力"换取"便利性" 。OpenAI 后来添加
chunking_strategy20 的举动表明,他们意识到了这个"黑盒"太"黑",并开始被迫逐步向开发者交还控制权。
第四部分:高级实现------流式响应 (Streaming)
v2 版本的关键功能之一是流式处理 (Streaming),它能显著提高"感知响应速度",使用户体验更自然 14。
实现流式处理
在 Python SDK 中,实现流式处理需要使用一个自定义的 EventHandler 类 2。
EventHandler 详解 2
- 第 1 步:继承 :创建一个类,继承自
openai.AssistantEventHandler。 - 第 2 步:覆盖
on_event:这是核心。您的处理器需要捕获并响应不同的事件。最常见的事件是thread.message.delta(用于接收文本流)和最关键的thread.run.requires_action(用于在流中处理工具调用)。 - 第 3 步:在流中处理
requires_action2
当on_event捕获到requires_action事件时 2,您的处理器(例如handle_requires_action方法)会被调用。此时,您(客户端)必须在流式处理期间同步执行本地函数 2。 - 第 4 步:在流中提交输出 2
您不能使用常规的submit_tool_outputs,因为那会破坏流。您必须使用专用的流式助手,例如 Python SDK 中的client.beta.threads.runs.submit_tool_outputs_stream()2。
流式代理循环的工程挑战
流式传输纯文本 (Text-Out) 很简单,但流式传输代理执行 (Agent-Loop) 则极其复杂。想象一下这个流程:文本流 -> 暂停 -> 客户端执行代码 (可能耗时 5 秒) -> 恢复 -> 文本流。
EventHandler 2 就是为了管理这个**"暂停/恢复"的逻辑。on_event 捕获 requires_action 是"暂停"的信号,而 submit_tool_outputs_stream 2 则是"恢复"的信号。这些助手绝非"语法糖",它们是关键的基础设施,用于处理在单个、不间断的流式会话中无缝地"进出" (round-trip)** 客户端代码的复杂工程问题。
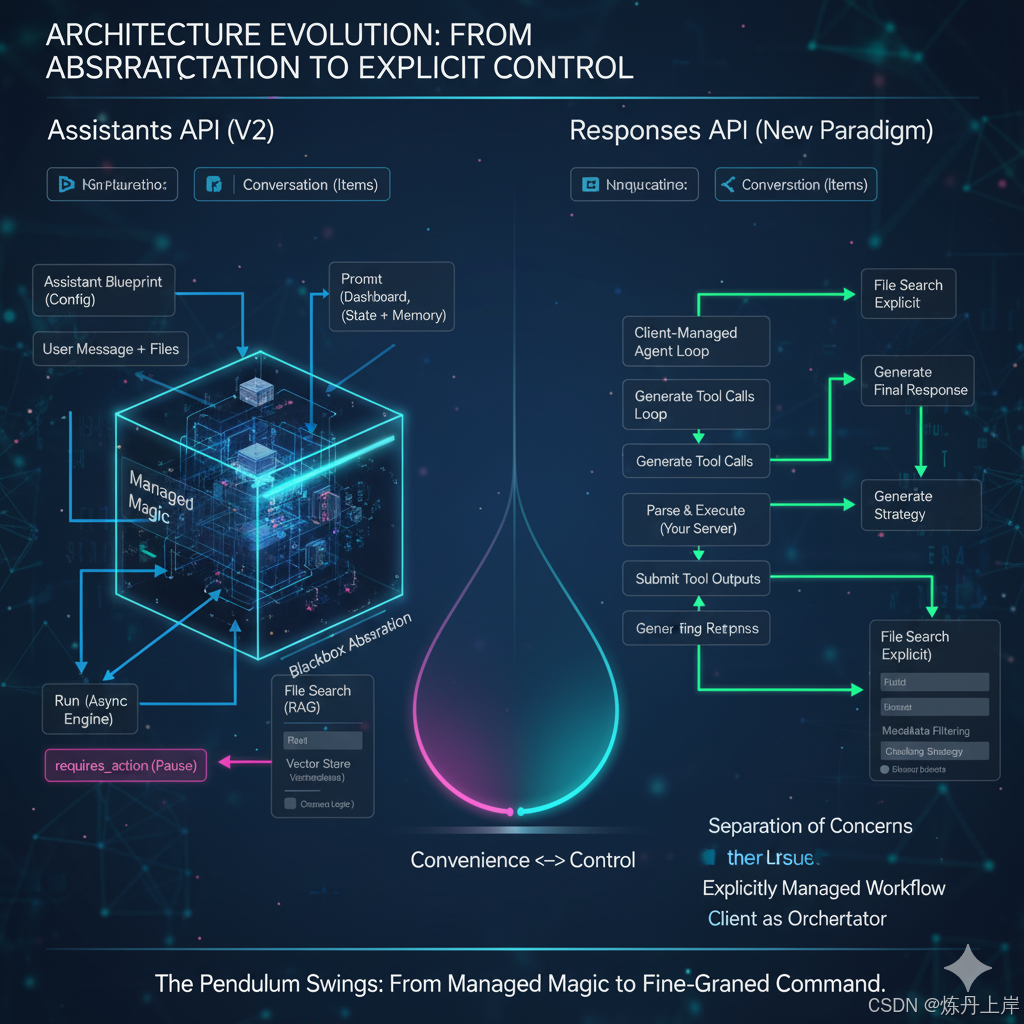
第五部分:架构的演进与未来:迁移路径分析
在分析文档时,一个核心的困惑点来自于 API 的迁移路径。实际上,这里存在两个独立的迁移,它们在时间上重叠,造成了极大的混乱 1。
阶段一:v1 -> v2 迁移 3
- 时间点:v1 已于 2024 年底被强制弃用 3。
- 关键变更 (RAG) :
- v1:使用
retrieval工具和file_ids列表 13。 - v2:使用
file_search工具和 Vector Store 对象 13。
- v1:使用
- 关键变更(能力) :
- v2 引入了流式处理 (Streaming) 14。
- v2 将 RAG 文件容量提升了 500 倍 14。
阶段二:Assistants API (v2) -> Responses API 迁移 1
这是当前正在发生的、更具战略意义的迁移。
- 时间点:Assistants API (v2) 已被弃用 (deprecated),将于 2026 年 8 月 26 日关停 1。
- 新的设计哲学:Responses API 1。
- 核心理念:从"黑盒抽象"转向**"分离关注点" (Separation of concerns)** 和**"显式管理" (explicitly managed)** 1。
- 核心概念映射 1:
- Assistant (API 创建) -> Prompt (在仪表板 (dashboard) 中创建,支持版本控制)。
- Thread (仅消息) -> Conversation (存储更通用的 Items,不仅是 Messages)。
- Run (异步"黑盒") -> Response (工具循环 (Tool call loops) 由客户端显式管理)。
- Run Step -> Item。
架构演进的"钟摆效应"
从 v1 到 Responses API 的演进,完美展示了 API 设计哲学中"便利性"与"控制力"的"钟摆回摆"。
- 阶段 1 (Assistants v1/v2) :OpenAI 提供了极致的便利性和抽象("黑盒")。Run 和 File Search 自动处理所有事情(状态管理、RAG 管线、工具循环)。
- 问题:开发者很快就达到了这个"黑盒"的边界。他们需要更多的控制力(例如 21 中渴望的元数据过滤,或 22 中对 RAG 混乱的抱怨)。
- 阶段 2 (Responses API):OpenAI 做出了回应。Responses API 1 明确将"工具循环"交还给客户端,将"配置"(Prompt)与"执行"(Response)分离。
这是 API 设计中一个经典的"钟摆效应"。Assistants API 是"托管魔法"(managed magic)的顶峰,而 Responses API 则是为了满足高级开发者对"显式控制"(explicit control)的需求,而将钟摆摆回。
表 2:架构演进对比
| 概念 | Assistants API (v1) | Assistants API (v2) | Responses API (新范式) |
|---|---|---|---|
| 状态 | 2024年底弃用 23 | 已弃用 (2026年关停) 1 | 当前推荐的 API 1 |
| 配置 | Assistant (API 创建) | Assistant (API 创建) | Prompt (Dashboard 创建, 可版本化) 1 |
| 对话 | Thread (仅消息) | Thread (仅消息) | Conversation (存储 Items) 1 |
| 执行 | Run (异步"黑盒") | Run (异步"黑盒") | Response (客户端显式管理工具循环) 1 |
| 检索 | retrieval (工具) 13 |
file_search (工具) 13 |
File Search (工具) 3 |
| 知识库 | file_ids 列表 13 |
Vector Store 对象 13 | (集成于 File Search) |
| 流处理 | 不支持 | 支持 14 | 支持 |
第六部分:结论------Assistants API 的遗产
Assistants API (v2) 是 AI 代理开发史上的一个重要里程碑。它将"状态管理"、"RAG"和"工具使用"这三大支柱封装在了一个(最终被证明是过于简单的)"黑盒"抽象中。
我们今天深入解构的(Thread, Run, requires_action, Vector Store)概念,并不仅仅是 OpenAI 的 API 端点。它们是构建任何(无论是开源、自研还是其他厂商)复杂 AI 代理所需的核心设计模式。
Responses API 1 的出现,标志着行业(由 OpenAI 引领)的成熟。它认识到,真正的"智能"来自于"便利的抽象"和"精细的控制"之间的平衡。通过深入理解 Assistants API 的"便利"及其"局限",开发者现在已做好充分准备,去驾驭 Responses API 所提供的"控制力"。