
丹尼尔:蛋兄,问个问题呗。RAG 里的文档应该怎么切割比较好呢?按固定的字符数或词数?按句?按段落?加个重叠窗口?感觉这些都太简单粗暴,容易把相关的内容给拆散了
蛋先生:恩,你说得对。这些方法一刀切,确实没办法考虑上下文的语义关系。现在大模型越来越强大,完全可以借助它们的能力,比如 LumberChunker
丹尼尔:LumberChunker?
蛋先生:这个名字起得非常有意思。"Lumber"是指经过精细加工的木材。这个方法就像一位经验丰富的木匠,不是简单地用锯子乱砍,而是根据木材的纹理和特性,将文档切割成结构合理、大小适中的块。每一块都能保留完整的语义,同时又不会超出大模型的处理能力
丹尼尔:哇塞,听起来很酷,具体是怎么切的呢?
蛋先生:我们直接来走一遍切块流程,相信聪明的你一下就懂了
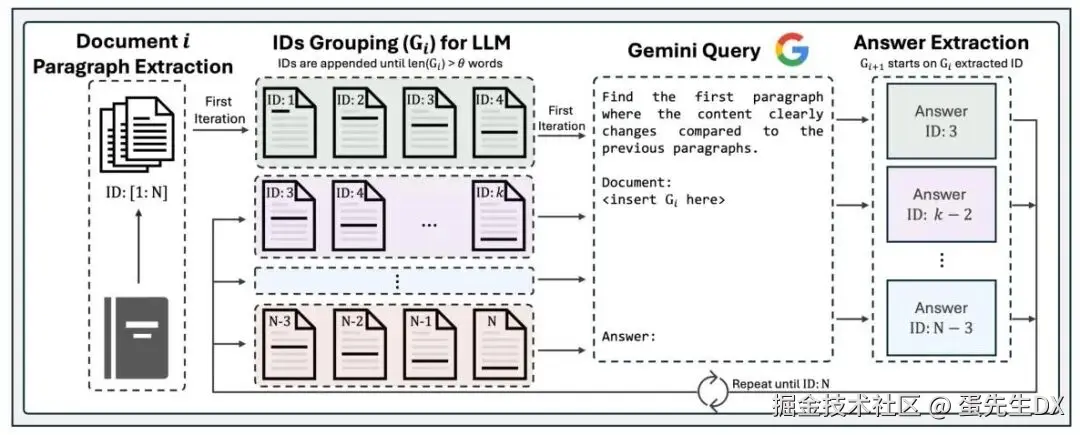
LumberChunker 的切块流程
✎ 第一步,自然拆分
蛋先生:咱们先把文章按自然段落拆开,比如用空行或缩进作为分界。这样切出来的就是人类写作时天然的语义单位了
丹尼尔:明白,就是先把原文分成几段
✎ 第二步,初步分组
蛋先生:接着我们来给每个段落计算 token 数,并设定一个上限阀值,比如 550 tokens。从第一个段落开始往后加,假设第 1、2、3 段加起来小于 550,但再加上第 4 段就超过阈值,那就先把第 1 ~ 3 段打包成一组
丹尼尔:哦?就是以长度上限作为分组的依据吗?
蛋先生:是的,这个 token 数阈值主要是考虑了模型输入长度的限制,同时将它作为分组的依据,一举两得
丹尼尔:妙啊!
✎ 第三步,找语义断裂点
蛋先生:最后我们把刚才那一组(第 1 ~ 3 段)送进大模型,让它判断:
bash
# 提示语简单示例
"从哪个段落开始,内容跟第一个段落关系不大了?"模型会返回一个索引数字,比如:
diff
-1 表示这几个段落语义连贯,全相关
2 表示从第 2 段之后,主题开始变化丹尼尔:如果是 -1 呢?
蛋先生:那就说明第 1 ~ 3 段语义一致,比如都是在讲"人工智能基础、机器学习、深度学习",那它们就组成一个完整的语义块。然后我们继续拿第 4 段当新起点
丹尼尔:哦,那如果模型输出为 2 呢?
蛋先生:那就表示第 1、2 段关系紧密,第 3 段开始语义发生变化。于是我们就可以把 1、2 段作为一个语义块生成 embedding,第 3 段作为新一组的开头
✎ 第四步,循环以上流程
丹尼尔:然后呢?
蛋先生:我们在上面的流程处理后,拿到了新的起点段落,然后重复以上流程,直到所有段落都被处理完毕
丹尼尔:哎呦不错哦,又简单又有效,这样看上去每个相关的块基本都可以在一起,不会被硬拆开
蛋先生:没错,有了高质量的分块,RAG 系统在检索相关信息时会更准确,因为每个块都是语义完整的单元,不会因为分块不当导致信息丢失或混乱
丹尼尔:看来 LumberChunker 确实是个智能的"木匠",切得恰到好处啊!
写在最后
若已看完上述对话,可通过下图进一步加深对 LumberChunker 的理解
"亲们,都到这了,要不,点赞或收藏或关注支持下我呗 o( ̄▽ ̄)d"