本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
为什么 Graph RAG 比传统检索更牛:通往更丰富上下文答案的聪明路子,笔者觉得Graph RAG 绝对是以后RAG的潮流。
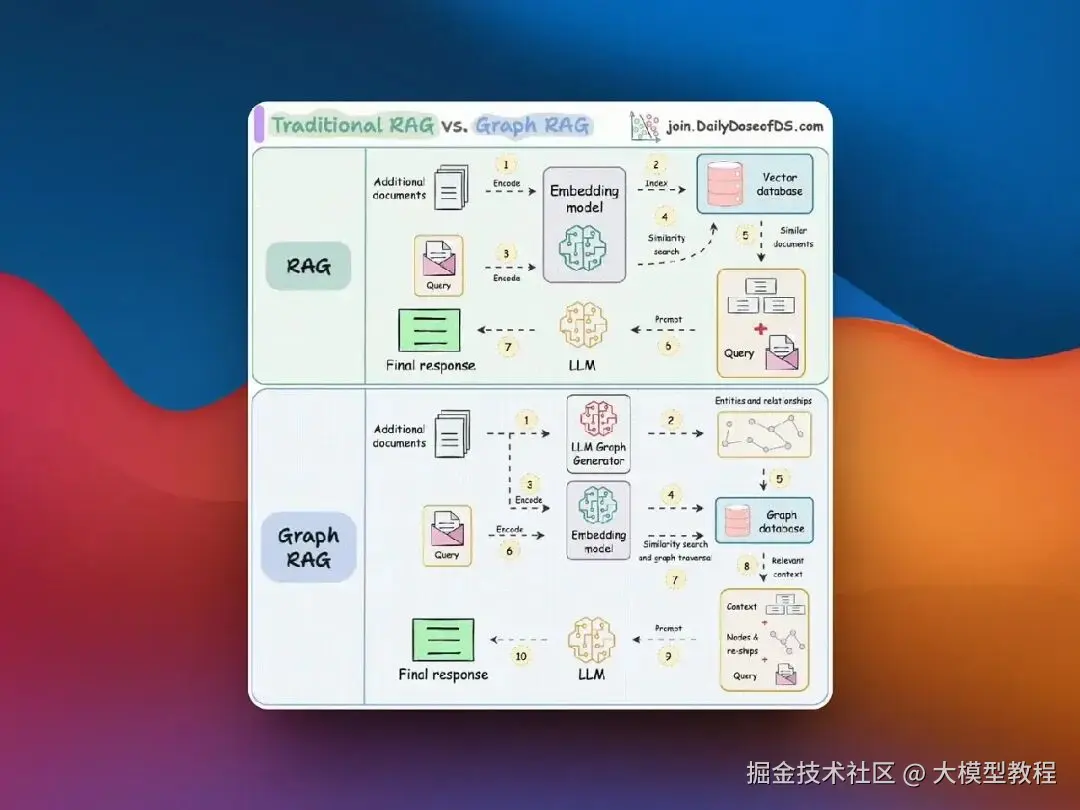
传统 RAG 中 Top-K 检索的局限性
top-k retrieval 在 RAG 里基本不咋管用。
传统 RAG 方法靠挑出"k"个最相关的文本段或片段。这有点用,但如果你想要一个完整、连贯的故事,很快就显得不够用了。
想象一下,你在缩写一本传记,每章讲一个成就。如果你只挑最相关的几个,就会漏掉关键信息。
这就给你一个不完整的画面,生成的答案可能缺了重要的上下文或成就之间的联系。
来源:来自 x.com/akshay_pachaar
欢迎体验 Graph RAG:理解上下文的聪明方式
Graph RAG 一点也不传统。
它不是直接用最高的 k 个部分,而是基于源文本构建一个相互关联的 graph,展示关键人物和他们的联系。
举个例子,如果你总结一个人的生平,Graph RAG 会建一个完整的 graph,里面的人(假设叫 P)跟所有成就都连起来。这个过程的厉害之处在于,它能通过识别和保持信息之间的关系,呈现完整的画面,这些关系在其他方式里可能会丢掉。
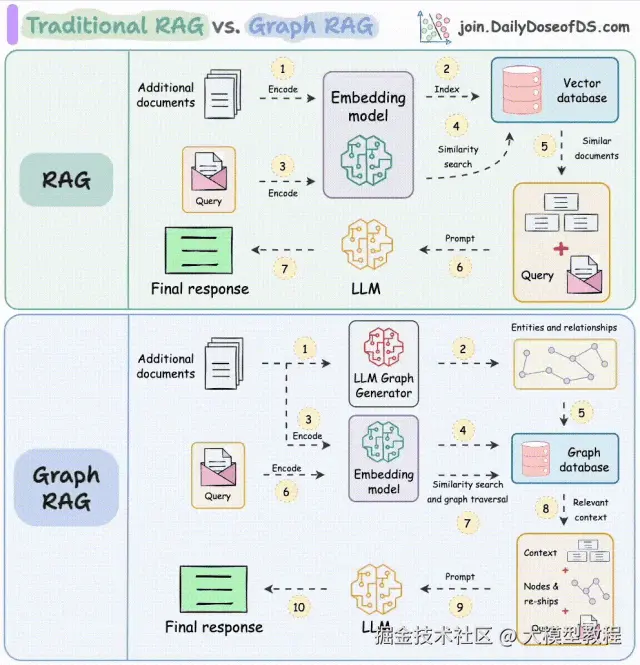
来源:来自 x.com/akshay_pachaar
Graph 构建
收集实体和它们的关系 Graph RAG 的关键步骤是从文档里建一个 graph。通常用一个 LLM(大型语言模型)读文本,找出重要的东西,比如人、地点或成就,然后标注它们怎么关联。
在我们的传记例子中,graph 以人(P)为中心,所有的成就像周围的点一样辐射出去。也就是说,即使有些信息不是最核心的,也会被加到 graph 里。因此,系统能捕捉完整的上下文,为构建最终总结打下更扎实的基础。
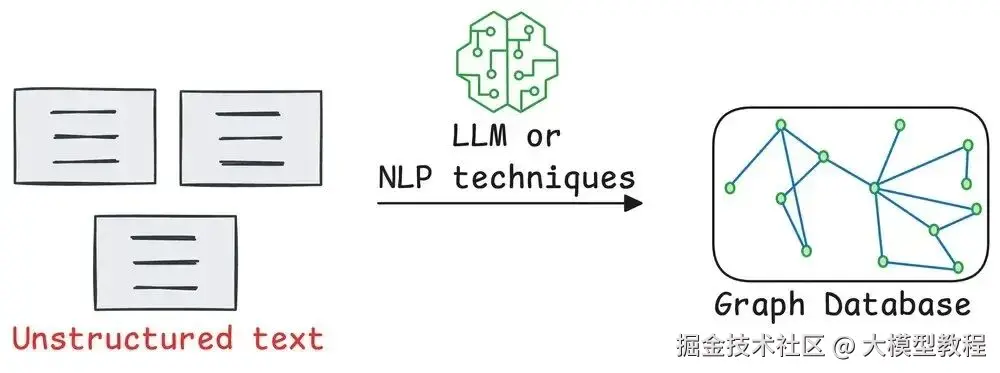
来源:来自 x.com/akshay_pachaar
Graph 遍历
获取完整的上下文 graph 建好后,系统会进行 graph traversal。它从核心主体(P)开始,遍历单跳关系,也就是单个成就。
在这个过程中,系统一次性收集所有相关的上下文。Naive RAG 可能会在 top 结果处截断,但 Graph RAG 确保所有相关信息都被考虑。
结果就是一个覆盖主体生活关键事实的摘要,什么都没漏。
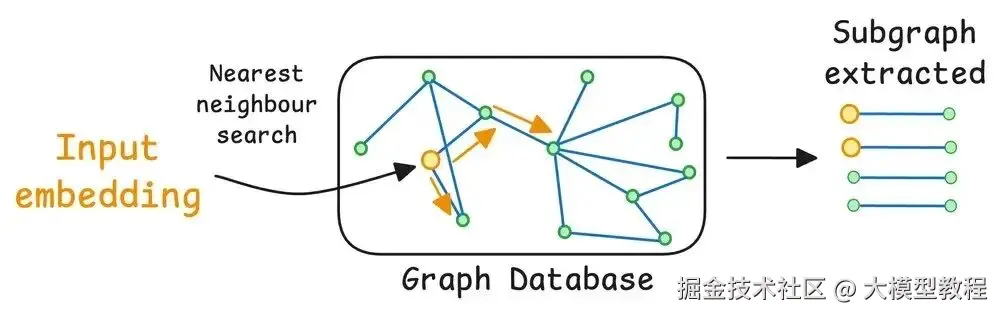
来源:来自 x.com/akshay_pachaar
基于 Graph 的数据检索提升思考能力
Graph RAG 不仅能获取更多信息,还以 LLMs 更容易理解的形式呈现信息。大型语言模型天生就擅长处理关联和结构化的信息。
通过以 graph 形式呈现信息,系统让模型能清楚看到联系,生成更好、更完整的答案。
这种结构化的形式帮助模型关联一个人生活中的事件或任何复杂故事,降低漏掉关键细节的可能性,输出完整且有意义的答案。
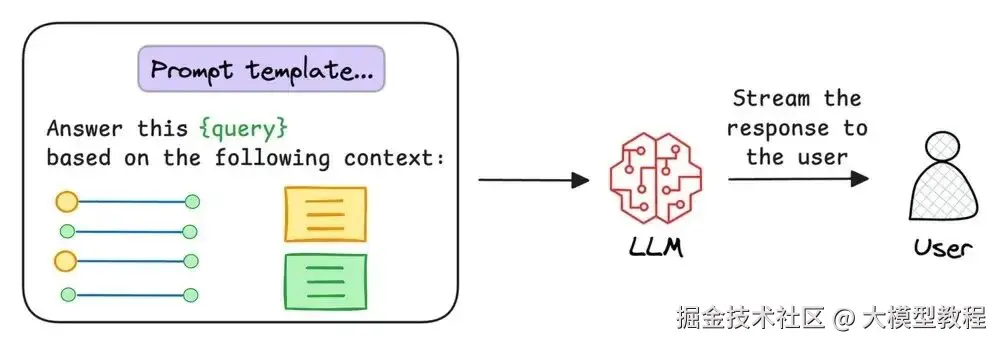
来源:来自 x.com/akshay_pachaar
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。