一、存储
(一)存储类型
1、按 "数据访问方式" 划分
(1)块存储(Block Storage)
-
核心特点:以 "固定大小的块(如 512 字节、4KB)" 为单位存储数据,通过 "块设备接口(如 SCSI、iSCSI)" 与主机交互,主机操作系统将其视为 "本地硬盘"(如 /dev/sda),需格式化后才能使用(如创建 ext4、NTFS 文件系统)。
-
优势:性能高(低延迟、高 IOPS),适合随机读写(如数据库、虚拟机磁盘),支持直接寻址(通过块地址定位数据)。
-
劣势:不具备原生文件语义(如文件名、目录结构),需依赖文件系统或数据库管理数据组织。
-
典型应用:操作系统磁盘、数据库存储(MySQL、Oracle)、虚拟机卷(OpenStack Cinder、AWS EBS)。
(2)文件存储(File Storage)
-
核心特点:以 "文件和目录" 为单位组织数据,通过 "文件系统接口(如 NFS、CIFS/SMB)" 提供访问,支持文件级别的权限控制(如读 / 写 / 执行权限)和元数据(如创建时间、所有者)。
-
优势:易用性高(符合用户对文件的直观认知),支持多主机共享访问(如多台服务器挂载同一文件系统),适合顺序读写和共享场景。
-
劣势:性能低于块存储(需经过文件系统层解析路径),不适合高 IOPS 需求场景。
-
典型应用:用户文档共享、日志存储、应用程序代码仓库(OpenStack Manila、NAS 存储设备)。
(3)对象存储(Object Storage)
对象存储是一种以 "对象(Object)" 为基本存储单元,通过REST API(HTTP/HTTPS) 实现数据读写的存储模式。
它摒弃了传统文件系统的层级目录结构,采用 "扁平无层级" 的组织方式,所有数据直接关联到唯一标识符,无需依赖文件系统即可实现跨网络访问。
① 对象(Object):数据的 "原子单元"
每个对象是存储的最小单位,包含三部分核心要素:
-
数据本身:任意类型的非结构化数据(如图片、视频、文档、备份文件等);
-
元数据(Metadata):描述对象属性的键值对,包括系统默认属性(如大小、创建时间、格式)和自定义属性(如 "owner: Alice""project: X"),用于快速筛选和管理;
-
唯一标识符(Key):在 "桶" 内唯一标识对象的字符串(类似 "文件名"),可包含 "/" 符号(如 "2023/logs/server1.log")模拟路径,但本质仍是平面对象,不构成实际目录层级。
② 桶(Bucket):对象的 "逻辑容器"
-
桶是对象的顶层逻辑容器,用于对对象进行粗粒度分类(如 "用户图片""备份数据"),所有桶处于同一逻辑层级,不支持嵌套(无 "子桶" 概念);
-
每个桶有全局唯一名称,可配置访问权限、存储类型(如标准存储、归档存储)等规则,作用于桶内所有对象;
-
对象通过 "桶名 + Key" 实现全局唯一定位(如https://bucket-name.object-storage.com/object-key),替代传统文件系统的 "路径 + 文件名"。
**③ 核心特性:**扁平结构与访问模式
**扁平无层级的组织方式:**所有对象直接存储在桶中,无目录树(文件夹)嵌套关系,彻底摆脱层级依赖:
-
优势:避免传统树形结构中 "路径遍历" 的效率损耗,即使数据量达 PB 级甚至 EB 级,仍可通过 "桶名 + Key" 直接定位对象(类似哈希表查找,时间复杂度 O (1));
-
兼容性:通过 Key 中的 "/" 符号模拟层级展示(如前端工具将 "images/2023/photo.jpg" 显示为 "images→2023→photo.jpg"),但底层仍为平面存储,不占用额外资源。
**基于 REST API 的访问模式:**数据读写完全通过 HTTP/HTTPS 协议的 API 接口实现(如 GET 获取对象、PUT 上传对象),无需挂载文件系统,支持跨网络、跨平台访问:
-
优势:简化多终端、跨地域的数据交互(如移动端、服务器、云平台均可通过 API 操作);
-
特点:不支持随机读写(修改数据需重新上传整个对象),适合一次性写入、多次读取的场景。
④ 对象存储是非结构化数据的理想载体,典型场景包括:
-
媒体文件存储(图片、视频、音频);
-
数据备份与归档(系统备份、日志归档);
-
静态网站托管(HTML、CSS、JS 文件);
-
云计算与大数据存储(OpenStack Swift、AWS S3、阿里云 OSS 等云对象存储服务)。
⑤ 优劣势分析
优势:
- 无限扩展:架构支持线性扩容,可轻松应对 PB 级甚至 EB 级数据增长(如添加节点即可扩展存储池);
- 高容错性:通过多副本存储或纠删码技术保障数据可靠性(如 3 副本存储可容忍 2 个节点故障);
- 灵活管理:自定义元数据支持高效筛选(如按 "创建时间""所属项目" 查询对象),简化海量数据分类;
- 跨域访问:基于 HTTP 协议,天然支持跨地域、跨网络访问(如全球分布式部署的对象存储)。
劣势:
- 不支持随机读写:修改数据需重新上传整个对象,不适合频繁更新的场景(如数据库);
延迟较高:API 调用和网络传输带来的延迟高于块存储,不适合低延迟需求场景(如实时交易); - 不适合结构化数据:缺乏文件系统的事务性和一致性支持,难以适配结构化数据库(如 MySQL)。
2、按 "存储介质" 划分
存储介质的物理特性直接影响存储的读写速度、容量、寿命和成本,常见介质包括:
1. 机械硬盘(HDD,Hard Disk Drive)
-
原理:通过磁头在旋转的磁盘片上读写数据,依赖机械运动。
-
特点:容量大(TB 级,如 18TB)、成本低,但速度慢(顺序读写约 100-200MB/s)、延迟高(10-20ms)、抗震性差,适合大容量、低性能需求的冷数据存储(如归档、备份)。
2. 固态硬盘(SSD,Solid State Drive)
-
原理:基于 NAND 闪存芯片存储数据,无机械部件,靠电子信号读写。
-
特点:速度快(顺序读写 500MB/s-3GB/s,随机读写 IOPS 可达数万)、延迟低(0.1-1ms)、抗震性好,但容量相对小(最大数十 TB)、成本高、有写入寿命限制(擦写次数)。
-
细分类型:
-
SATA SSD:接口兼容性好,性能中等(适合个人 PC、普通服务器);
-
NVMe SSD:基于 PCIe 通道,性能极致(适合数据库、AI 训练等高性能场景)。
-
3. 其他新兴介质
-
存储级内存(SCM,Storage-Class Memory):如 Intel Optane,兼具内存的速度和硬盘的持久性,延迟接近 DRAM(微秒级),但成本极高,用于核心业务加速。
-
磁带存储:容量超大(单磁带可达数十 TB)、成本极低,但读写速度极慢(分钟级),仅用于离线归档(如企业数据长期备份)。
3、按 "部署模式" 划分
(1)本地存储(Local Storage)
-
特点:存储介质直接部署在主机内部(如服务器内置 HDD/SSD),仅能被本机访问。
-
优势:性能高(无网络延迟)、部署简单;
-
劣势:容量有限、无法共享、单点故障风险高(主机故障则数据不可用)。
-
应用:个人电脑硬盘、服务器本地系统盘。
(2)集中式存储(Centralized Storage)
-
特点:存储资源集中部署在独立的存储阵列(如 SAN、NAS 设备),通过网络(FC、iSCSI、NFS)为多台主机提供共享访问。
-
优势:易于管理、支持高可用(多控制器冗余);
-
劣势:扩展成本高(受限于阵列硬件)、存在性能瓶颈(集中式架构)。
-
应用:企业级 SAN(块存储)、NAS(文件存储)。
(3)分布式存储(Distributed Storage)
-
特点:将多台普通服务器的本地存储资源通过软件整合成一个统一的存储池,数据分散存储在多个节点,通过分布式协议(如 Ceph、GlusterFS)实现协同访问。
-
优势:线性扩展(增加节点即可扩容)、高容错(多副本存储)、成本低(基于通用服务器);
-
劣势:架构复杂、依赖网络性能(节点间数据同步)。
-
应用:云计算场景(OpenStack Cinder/Swift 底层常用 Ceph)、超大规模数据中心。
(二)存储设备
存储设备的核心作用是为业务服务器提供更充足的存储空间、更高的 IO 性能以及共享存储能力,以满足不同业务场景的需求
// 解释:存储设备能把多块硬盘的容量 "拼起来",还能随时加硬盘扩容,满足业务不断产生的海量数据存储需求;存储设备通过用更快的硬件(如高速 SSD)、多设备并行处理数据,让数据读写速度大幅提升;存储设备能通过网络让多台服务器共享同一批数据(比如办公文档共享、多台服务器共用一个数据库),还能在服务器故障时快速切换数据,保证业务不中断。
1、根据工作方式,存储设备主要分为三类
- DAS 直接附加存储
- NAS 网络附加存储
- SAN 存储区域网络
(1)DAS 直接附加存储
DAS 通过数据总线直接将存储设备接入到服务器主板,是一种简单直接的存储连接方式。
磁盘类型:机械硬盘、SSD
磁盘接口:SATA,SAS、NVME
特点:DAS 属于服务器专属存储,无法直接被其他服务器共享,这导致其扩展性较差,受限于服务器接口的数量,因此更适用于个人 PC、单台服务器等小型场景。
(2)NAS 存储
NAS 基于文件系统级别实现共享,支持 nfs 和 cifs 协议来共享存储空间。
- **nfs协议:**适用于 Linux、Unix系统
- **cifs协议:**适用于 Windows
实现方式:
① 使用专用存储设备,核心是 "硬件 + 预装系统" 一体化,无需用户从零配置,典型代表是群晖(Synology)、威联通(QNAP)的家用 NAS,或华为、戴尔的企业级存储阵列。
② 使用普通服务器上安装开源 Linux 发行版,再通过配置软件实现 NAS 功能。
具体流程:
本质是存储端先完成文件系统构建,再通过标准化协议将 "已格式化的存储空间" 开放给网络中的客户端访问。
① 存储端:先格式化创建文件系统。NAS 设备内置独立的操作系统,首次使用时,需先对其内置 / 外接的硬盘进行格式化,创建通用的文件系统。 ------ 文件系统能定义文件的物理存储结构,让 NAS 能像电脑硬盘一样 "管理文件",而非仅提供裸磁盘空间。
② 存储端:将文件系统挂载到 NAS 本地,再配置共享规则。格式化后的文件系统会被挂载到 NAS 的本地目录,随后 NAS 通过系统设置,将该挂载目录配置为 "共享目录",并指定共享权限.
③ 客户端:通过 NFS/CIFS 协议,跨网络访问共享目录。不同系统的客户端(Linux/Unix、Windows)通过对应的协议 "连接 NAS 的共享目录"。
特点:作为一种专用存储服务器,NAS 设备自身配备了 CPU、内存和操作系统,通过以太网接入网络,用户可以通过网络路径(如 \IP\ 共享名或 /mnt/nfs)访问存储内容,非常适合企业文档共享、媒体存储等文件共享场景。
补充:文件系统类型
① 单机文件系统(本地存储专用,NAS 存储端底层依赖)
单机文件系统仅用于单台设备本地存储,负责管理本地硬盘的空间分配、文件结构与读写逻辑,是 NAS 设备 "先格式化、再共享" 的基础(NAS 需先将本地硬盘格式化为单机文件系统,才能构建文件结构)。
-
Linux 系统专用:
-
XFS:支持超大容量(单文件系统最大 8EB)、高 IO 性能,适合存储高清视频、日志等大文件,中小型 NAS 常用;
-
Ext4:稳定性强、兼容性好,支持文件权限控制(如读 / 写 / 执行权限),是 Linux 及 NAS 系统(如群晖、威联通)的默认格式之一。
-
-
Windows 系统专用 / 兼容:
-
NTFS(注:原文 "nyfs" 为笔误,正确为 NTFS):支持文件权限、压缩、加密,适配 Windows 环境,若 NAS 优先对接 Windows 客户端(如办公文档共享),可格式化为 NTFS;
-
FAT32:兼容性极强(支持 Windows、Linux、手机等多设备),但单文件最大仅 4GB、总容量最大 2TB,仅适合小文件存储(如 U 盘、移动硬盘)。
-
② 网络文件系统(跨设备共享专用,NAS 核心共享协议)
网络文件系统是多设备通过网络共享文件的 "通信规则",NAS 正是通过这类协议,将本地已格式化的存储空间开放给其他设备访问,实现 "文件级共享"。
-
NFS(Network File System,网络文件系统):主要适配 Linux/Unix 系统,客户端(如 Linux 服务器)可通过 NFS 将 NAS 的共享目录 "挂载到本地路径",访问时如同操作本地文件夹,适合 Linux 环境下的文件协同(如服务器日志共享)。
-
CIFS/SMB(Common Internet File System/Server Message Block,通用互联网文件系统) :主要适配 Windows 系统,客户端(如 Windows 电脑)可通过 "\NAS IP\ 共享名"(如
\\192.168.1.100\office-doc)直接访问共享目录,也兼容 Linux、macOS,是跨系统文件共享的常用协议(如办公场景多人共享文档)。
③ 集群文件系统(多存储节点协同,大规模场景专用)
集群文件系统是多台存储设备(节点)组成 "存储集群" 后,共同管理数据的文件系统,核心是解决 "大规模存储下的容量扩展、性能叠加、数据冗余" 问题,常见于企业级大规模存储场景。
-
特点:多存储节点统一对外提供存储空间,客户端访问时 "看不到单个节点",仅感知到一个 "超大容量存储池";支持动态扩展(新增节点即可扩容)、数据分布式存储(避免单点故障);
-
常见类型:GlusterFS(开源,适合中小规模集群)、CephFS(开源,兼容对象存储、块存储,企业级常用)、GPFS(IBM 商用,高性能集群场景)。
④ 其他常见文件系统
除上述三类外,还有适配特定需求的文件系统,部分场景下也可能与 NAS 或存储设备关联:
-
日志型文件系统:如 Btrfs(可用于 NAS),支持 "快照备份""数据校验",能快速恢复误删文件、检测数据损坏,适合对数据安全性要求高的场景(如企业文档备份);
-
对象存储文件系统:如 S3FS(兼容 Amazon S3 协议),将对象存储(如阿里云 OSS、腾讯云 COS)模拟为本地文件系统,适合需要对接云存储的场景(如 NAS 与云存储协同备份);
-
移动设备文件系统:如 exFAT,解决 FAT32 单文件 4GB 限制(支持单文件最大 16EB),兼容 Windows、macOS、手机,适合移动硬盘、相机存储卡(NAS 若需读取外接移动设备,需支持该格式)。
补充:文件的存储结构
① 物理存储结构
**//**文件数据在存储设备(如硬盘的磁道)上的真实存储布局
-
连续存储:文件的所有数据块,连续存放在存储设备的一块连续完整的物理空间,文件系统通过记录'起始地址'和'总长度'来定位整个文件
-
离散存储:文件的数据拆成多个独立的数据块,分散存在存储设备的空闲区域。
-
链接分配:文件数据块分散存储,每个数据块通过 "指针" 指向后续块(形成链式结构),文件系统只需记录 "第一个块的地址"。
-
索引分配:文件数据块分散存储,但文件系统为每个文件创建 "索引块",集中记录所有数据块的物理地址
-
② 逻辑存储结构
**//**文件数据在 "用户或应用程序眼中" 的组织形式。本质是数据的逻辑排列,和磁盘上的物理位置无关。
-
流式结构:文件数据就是 "一长串字节",没有固定格式。程序读写时,只能从开头到结尾按顺序处理;程序也可通过 "偏移量" 随机访问,只是没有天然数据单元。
-
记录式结构:通过 "固定格式 + 元信息",程序能通过计算偏移量或索引直接访问目标记录
-
按偏移量计算:因记录格式固定(长度统一),可直接通过 "起始地址 +(N-1)× 单条记录长度" 定位第 N 条记录,无需顺序遍历;
-
按关键字索引:若文件包含 "关键字段"(如数据库表的主键),可通过建立索引表(记录 "关键字 - 记录位置" 映射),快速找到目标记录(类似字典通过部首查字)。
-
(3)SAN 存储
SAN 基于块级别的共享, "块" 是存储的最小数据单元。
SAN 的核心逻辑是存储端只负责 "提供裸块空间",不提前构建文件系统------ 所有与 "文件管理" 相关的操作(分区、格式化、创建文件系统)都交给客户端完成。
**工作流程:**存储端共享裸块设备,客户端连接存储后会映射出 sdx 形式的虚拟硬盘,客户端对该虚拟硬盘进行分区、格式化后即可挂载使用。以最常见的 IP SAN(iSCSI 协议)为例:
(1)存储端:配置并共享 "裸块设备"
① 创建块存储资源。存储端先将本地物理硬盘划分为 "逻辑块设备",这部分空间是 "未格式化、无文件系统" 的裸块;
② 配置共享规则。通过 SAN 管理工具(如 Openfiler WebUI),为裸块设备绑定唯一标识(IQN,如 iqn.2024-10.com.example:san-disk1),并指定访问协议(IP SAN 用 iSCSI、FC SAN 用 FC 协议);
③ 开放网络访问。设置允许访问的客户端范围(如限定客户端 IP 为 192.168.1.0/24),并配置认证(如 CHAP 用户名密码),防止未授权设备接入。
(2)客户端:发现并映射 "虚拟硬盘"
客户端需通过对应协议,将存储端的裸块设备 "映射为本地可见的虚拟硬盘":
① 安装协议客户端工具。IP SAN 需安装 iSCSI 客户端(如 Linux 装 iscsi-initiator-utils、Windows 启用 "iSCSI 发起程序");
② 发现存储端共享块。客户端通过协议发送 "发现请求"(如 Linux 执行 iscsiadm -m discovery -t st -p 192.168.1.100:3260),找到存储端的 IQN 对应的裸块设备;
③ 建立连接并映射。客户端通过认证后(输入 CHAP 用户名密码),与存储端建立稳定连接,此时裸块设备会被映射为客户端的 "虚拟硬盘"(如 Linux 下的 /dev/sdb、Windows 磁盘管理中的 "未分配磁盘")。
(3)客户端:分区、格式化并挂载使用
映射后的虚拟硬盘与客户端本地硬盘完全等效,需按 "本地硬盘" 配置后才能存储数据:
① 分区。客户端对虚拟硬盘进行分区,划分出 "可使用的逻辑分区"(如 /dev/sdb1);
② 格式化。为分区创建文件系统;
③ 挂载使用。将格式化后的分区挂载到客户端的目录,之后客户端即可在该目录 / 盘符下读写文件,所有数据实际存储在 SAN 存储端的裸块设备中。
**类型:**IP SAN、FC SAN
特点:
- IP SAN 基于 TCP/IP 网络,使用 iSCSI 协议,成本低、部署灵活;
- FC SAN 基于光纤通道网络,使用光纤通道协议(FC Protocol)**,**需专用光纤交换机和 HBA 卡,速度快(通常 16Gbps 以上)、延迟低,适合高性能场景(如数据库、虚拟化);
| 维度 | IP SAN(iSCSI) | FC SAN(光纤通道) |
|---|---|---|
| 底层网络 | 通用以太网(复用现有) | 专用光纤通道网络(需新建) |
| 核心硬件 | 普通网卡、以太网交换机 | FC HBA 卡、FC 交换机、光纤线缆 |
| 成本 | 低(复用现有设备,硬件便宜) | 高(专用硬件贵,部署成本高) |
- 块级共享意味着客户端可直接对存储进行分区、格式化,相当于本地硬盘的扩展。
SAN和NAS的区别:
-
SAN 的路径:客户端→ 协议(iSCSI/FC)→ SAN 存储的裸块设备 → 后端硬盘。客户端格式化虚拟硬盘后,读写数据时只需通过 iSCSI/FC 协议,直接向 SAN 存储发送 "块级指令"(如 "写数据到第 100-102 号块"),SAN 收到指令后直接操作硬盘块 ------没有任何 "文件系统解析" 的中间步骤,数据从客户端到硬盘的 "跳转次数最少"。
-
NAS 的路径:客户端 → 协议(NFS/CIFS)→ NAS 设备的文件系统 → NAS 后端硬盘。客户端发送的是 "文件级指令"(如 "创建 test.txt"),NAS 必须先通过自身的文件系统解析 "这个文件对应哪些块",再操作硬盘 ------ 多了 "NAS 文件系统解析" 这一步,会产生毫秒级的延迟(对高频读写场景影响显著)。
-
SAN 是 "客户端 - 存储端" 的块级直连 ,整个数据读写过程几乎没有 "多余环节",而 NAS 因多了 "文件系统中间层",会产生额外损耗。
|---------|-----------------|---------------------------|
| 维度 | NAS | SAN |
| 共享级别 | 文件级(基于文件系统) | 块级(裸设备) |
| 协议 | NFS、CIFS/SMB | iSCSI(IP SAN)、FC(FC SAN) |
| 网络依赖 | 以太网 | 以太网(IP SAN)/ 光纤通道(FC SAN) |
| 适用场景 | 文件共享(文档、媒体) | 高性能存储(数据库、虚拟化) |
| 客户端访问方式 | 网络路径(如/mnt/nfs) | 本地磁盘(如/dev/sdb) |
二、linux系统配置nfs存储
1、环境描述
- 192.168.140.10 业务服务器
- 192.168.140.11 nfs存储
2、nfs存储端配置
(1)提供存储空间
bash
[root@nas ~] df -hT
# Filesystem Type Size Used Avail Use% Mounted on
# /dev/sdb xfs 20G 33M 20G 1% /data(2)安装存储端软件
bash
[root@nas ~] yum install -y nfs-utils rpcbind(3)编辑exports文件,共享存储
**配置文件语法:**文件系统 客户端地址(权限)
- 单个地址192.168.1.1
- 网段 192.168.1.0/24
- 所有地址 *
权限:
- 只读 ro
- 读写 rw
bash
[root@nas ~] cat /etc/exports
/data 192.168.140.10(rw)
[root@nas ~] chmod o+w /data/注意:
- /etc/exports中的 rw 权限是NFS 服务层面的 "访问控制"允许客户端发起写请求;
- 服务端共享目录的写权限(o+w,对映射用户开放)确保写请求能在服务端文件系统中执行。
(4)启动nfs服务
bash
[root@nas ~] systemctl enable --now nfs-server
[root@nas ~] systemctl enable nfs-server3、业务服务器挂载使用存储
(1)安装nfs-utils软件
bash
# 下载,让系统识别nfs文件系统
[root@yewu ~] yum install -y nfs-utils (2)编辑fstab,挂载存储
bash
# 创建挂载点
[root@yewu ~] mkdir -p /db/log
# 挂载
# nfs服务器地址:nfs共享文件系统 挂载点 nfs defaults 0 0
[root@yewu ~]# tail -n 1 /etc/fstab
192.168.140.11:/data /db/log nfs defaults 0 0
[root@yewu ~] mount -a
bash
[root@yewu ~] df -hT | grep nfs
# 192.168.140.11:/data nfs4 20G 33M 20G 1% /db/log(3)测试数据读写
bash
[root@yewu ~] touch /db/log/{1..10}
[root@yewu ~] ls /db/log/
# 1 10 2 3 4 5 6 7 8 9三、配置 SAN 存储(基于 iSCSI)
1、前提:
①创建 Openfiler 虚拟机并安装系统
- 安装时需确保虚拟机网络配置正确(建议使用桥接或仅主机模式,保证与业务服务器互通)
- 分配足够的磁盘空间用于创建 RAID 设备(如添加多块虚拟磁盘作为 RAID 成员)。
② 访问 openfiler webUI
- 浏览器输入https://Openfiler_IP:446,用用户名openfiler、密码password登录
2、存储设备配置
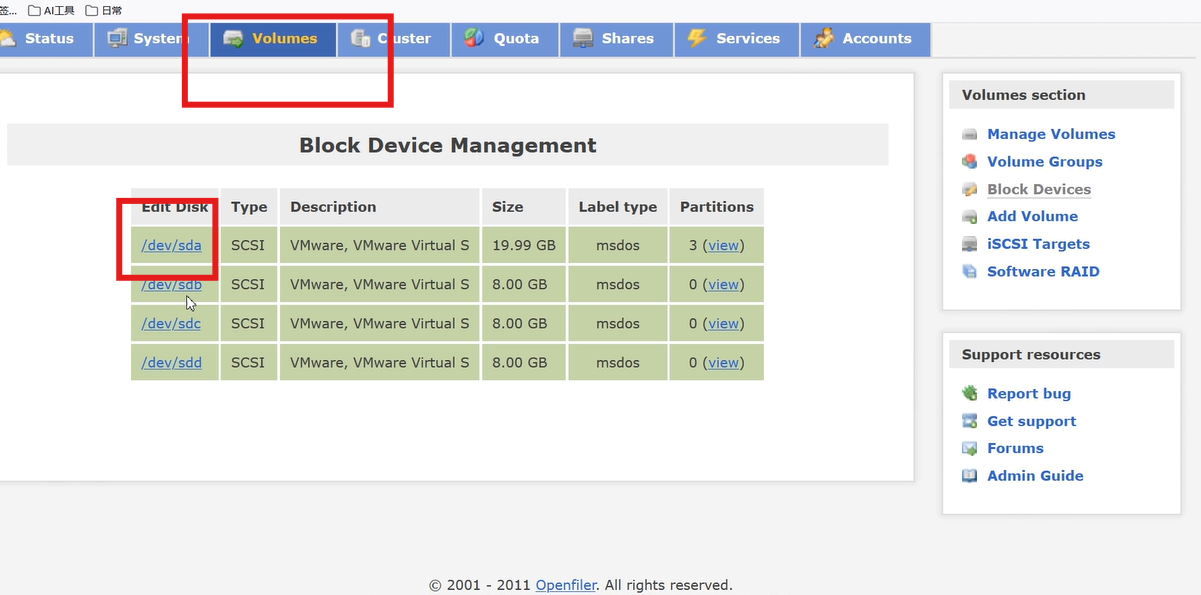
(1)创建 RAID 设备
- 进入Block Devices,查看识别到的物理磁盘(如/dev/sdb、/dev/sdc)。
- 选择未分区的磁盘,点击磁盘名进入配置页。
- 在Partition Type中选择 RAID array member,点击Create。
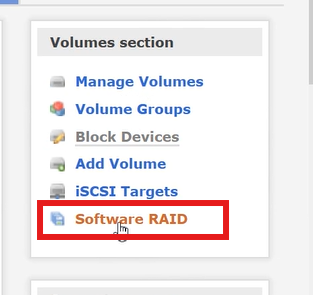
- 进入Software RAID标签页:
- 创建新RAID
- 填写 RAID 名称(如md0),选择 RAID 级别(如 RAID1/5,根据磁盘数量选择)
- 勾选需要加入 RAID 的物理磁盘,点击Create
- 等待 RAID 同步完成(状态变为active)

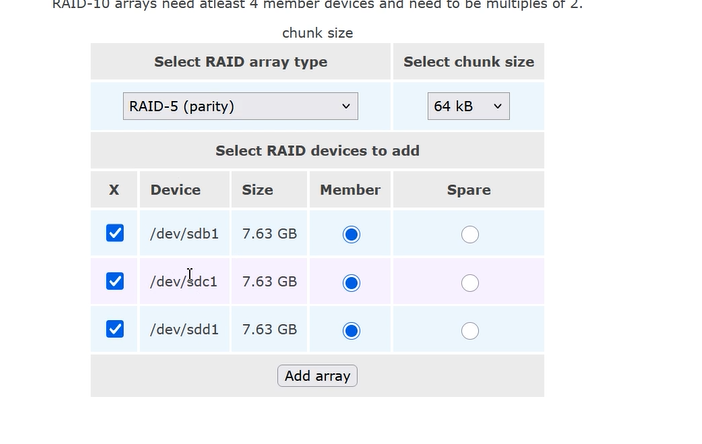
(2)创建卷组(VG)
- 进入Volume Groups标签页。
- 创建卷组
- Volume Group Name:填写卷组名(如vg_iscsi)
- Physical Volumes:勾选已激活的物理磁盘或 RAID 设备(如/dev/md0或/dev/sdb1)
- 点击Add volume group,卷组创建完成(状态为active)
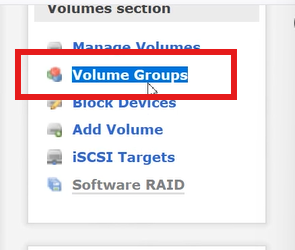
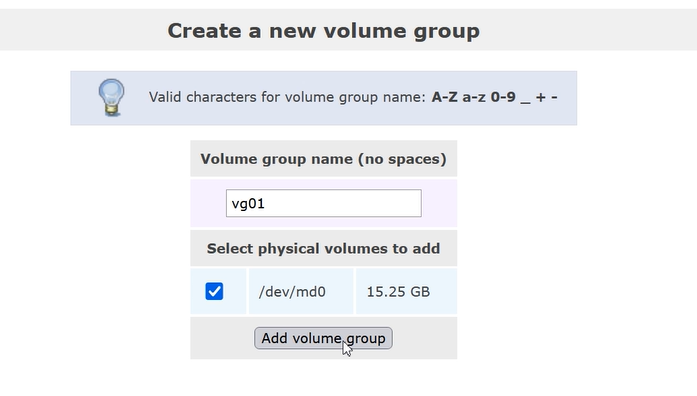
(3)创建逻辑卷(LV)
- 进入Logical Volumes标签页,选择刚创建的卷组(如vg_iscsi)。
- 创建逻辑卷:
- Logical Volume Name:填写逻辑卷名(如lv_iscsi01)
- Size:设置逻辑卷大小(如10G,不超过卷组总容量)
- Volume Type:选择block(块设备,用于 iSCSI)
- 点击Create,逻辑卷创建完成(会显示为/dev/vg_iscsi/lv_iscsi01)
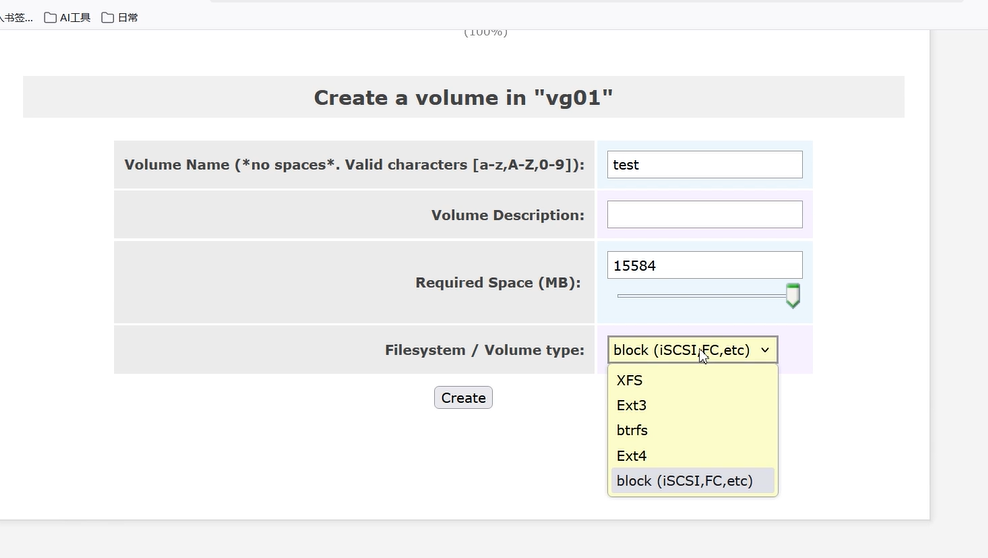
3、iSCSI 服务与共享配置
(1)开启 iSCSI Target服务
- 进入Services标签页。
- 找到iSCSI Target和iSCSI Initiator服务,点击右侧Start启动服务,并勾选Enable设置开机自启(确保服务状态为Running)。
-
iSCSI Target:是 "存储端服务",作用是将 Openfiler 的逻辑卷(块设备)共享出去,作为 "iSCSI 目标设备" 供客户端连接。没有它,客户端无法发现或访问共享的存储资源,是必须开启的核心服务。
-
iSCSI Initiator:是 "客户端服务",作用是让本地设备(此处指 Openfiler 服务器本身)作为客户端去连接其他设备的 iSCSI Target(比如连接另一台存储服务器的共享)。
(2)配置 iSCSI Target服务
① 创建iSCSI Target
进入Volumes → Targets标签页,点击Add创建 Target
- Target Name:按规范填写(如iqn.2024-10.com.openfiler:target01)
- IQN 名称格式: iqn.yyyy-mm. 反域名:自定义名称,其他默认,点击Create。
② 绑定逻辑卷到 Target
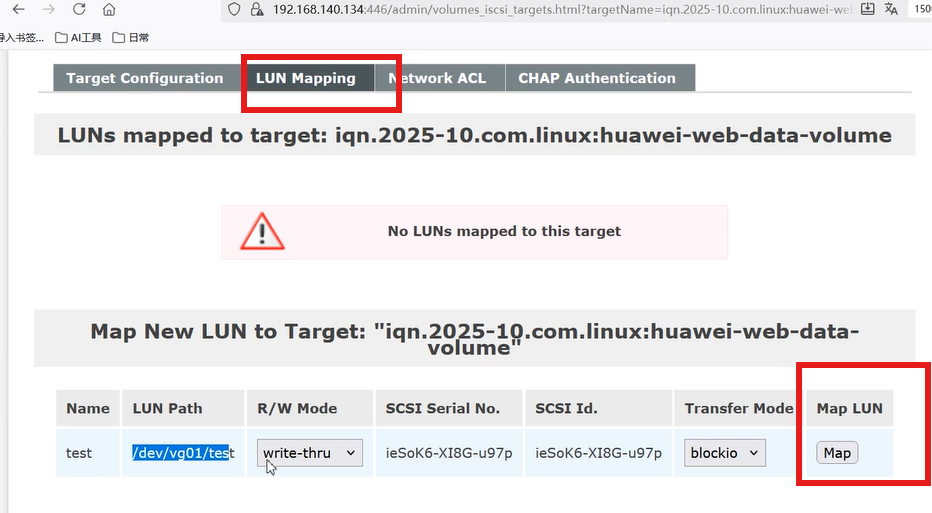
-
在刚创建的 Target 下,找到LUN Mapping标签,点击Add
-
选择创建的逻辑卷(如/dev/vg_iscsi/lv_iscsi01)
-
点击Map,完成 LUN(逻辑单元号)映射。
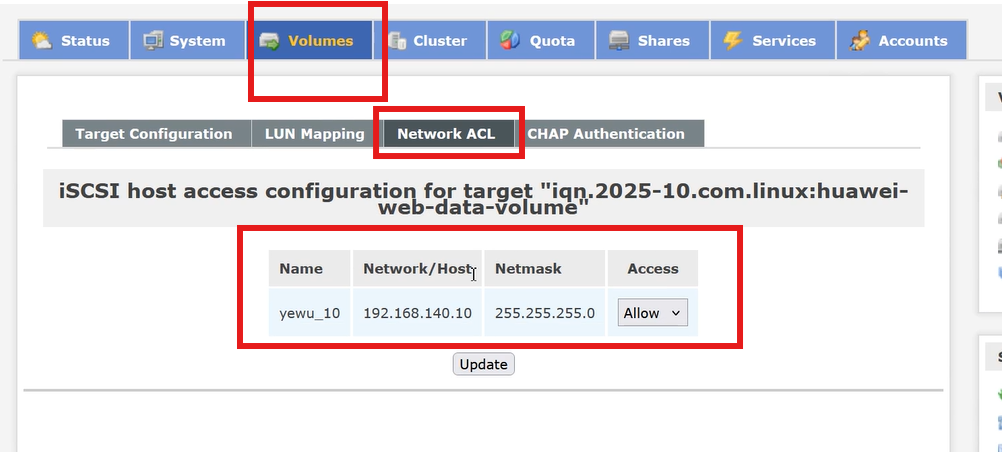
③ 配置客户端访问权限
-
进入Network ACL标签
-
填写客户端的 iSCSI initiator 名称(客户端需先安装iscsi-initiator-utils,通过cat /etc/iscsi/initiatorname.iscsi获取),或留空允许所有客户端(测试用)
-
在 Target 对应的Access列选择Allow
-
点击Update。
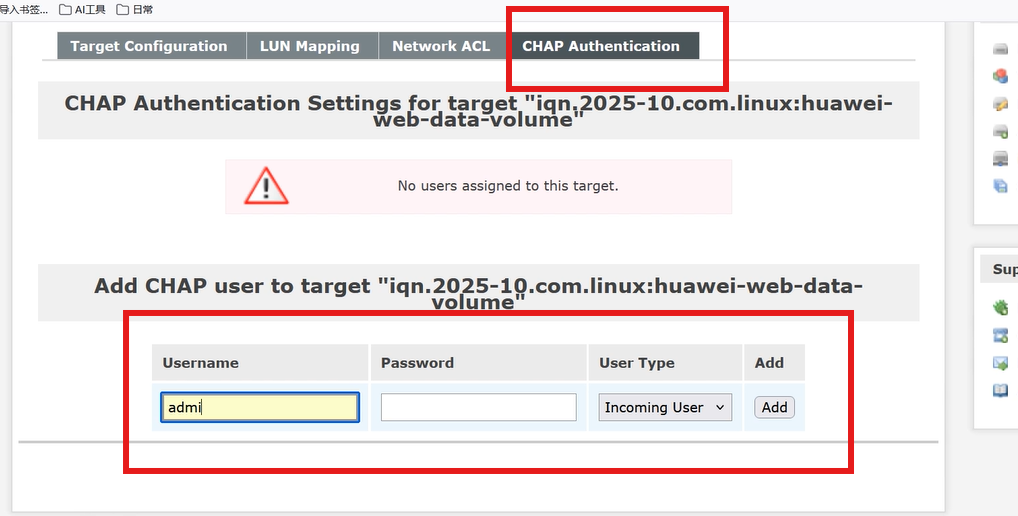
④ 设置CHAP认证
4、网络连通性配置
- 存储端:通过systemd-networkd或网络配置工具,设置静态 IP(如 192.168.140.11),开放 iSCSI 端口(3260),确保与业务服务器网络互通;

// 配置和管理 SAN 相关的网络环境,确保存储设备(如 iSCSI Target)与业务服务器(iSCSI Initiator)之间的网络连通性
- 客户端 :配置静态 IP(如 192.168.140.10),安装
iscsi-initiator-utils,确保能 ping 通存储端 IP。
(1) 安装客户端软件
bash
[root@master_haproxy ~] yum install -y iscsi-initiator-utils(2)编辑 iscsid.conf 配置文件,指定认证的用户
bash
[root@master_haproxy ~] vim /etc/iscsi/iscsid.conf
node.session.auth.authmethod = CHAP
node.session.auth.username = martin
node.session.auth.password = redhat(3)探索存储
bash
[root@master_haproxy ~] iscsiadm -m discovery -t st -p 192.168.140.128:3260
# iscsiadm: No portals found
首次探求存储时,存储端会生成拒绝所有客户端的文件,在存储端 /etc/initiators.deny 文件中删除拒绝所有条目,重新探索
bash
[root@master_haproxy ~]# iscsiadm -m discovery -t st -p 192.168.140.128:3260
# -p 存储的ip
192.168.140.128:3260,1 iqn.2024-06.com.linux:jf3-jg7-hw-db
(4)连接使用存储
bash
[root@master_haproxy ~] iscsiadm -m node -T iqn.2024-06.com.linux:jf3-jg7-hw-db -p 192.168.140.128:3260 -l
# Logging in to [iface: default, target: iqn.2024-06.com.linux:jf3-jg7-hw-db, portal: 192.168.140.128,3260] (multiple)
# Login to [iface: default, target: iqn.2024-06.com.linux:jf3-jg7-hw-db, portal: 192.168.140.128,3260] successful.
[root@master_haproxy ~] lsblk
# NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
# sda 8:0 0 20G 0 disk
# ├─sda1 8:1 0 500M 0 part /boot
# └─sda2 8:2 0 19.5G 0 part
# ├─centos-root 253:0 0 17.5G 0 lvm /
# └─centos-swap 253:1 0 2G 0 lvm [SWAP]
# sdb 8:16 0 9.5G 0 disk
# sr0 11:0 1 9.5G 0 rom
mkfs -t xfs /dev/sdb
mkdir /test1
[root@master_haproxy ~] blkid /dev/sdb
# /dev/sdb: UUID="d0765ec9-e93f-4998-ac05-27377e491409" TYPE="xfs"
[root@master_haproxy ~] vim /etc/fstab
UUID="d0765ec9-e93f-4998-ac05-27377e491409" /test1 xfs defaults,_netdev 0 0
[root@master_haproxy ~] mount -a
[root@master_haproxy ~] df -hT
# /dev/sdb xfs 9.5G 33M 9.5G 1% /test1
[root@master_haproxy ~]# touch /test1/{1..10}
[root@master_haproxy ~]# ls /test1/
1 10 2 3 4 5 6 7 8 9
补充 fstab 挂载参数说明:_netdev参数用于确保网络启动后再挂载存储,避免开机时因网络未就绪导致挂载失败,对网络存储(如 iSCSI、NFS)是必需参数。
windows连接的话